文章目录
- Redis缓存结构详解
- 前言
- Redis 缓存架构
- redis 和db数据一致性
- 先写db还是写redis
- 如果是先写db,再删除缓存呢?
- 延迟双删
- 简单的缓存,并发不高,没啥流量
- 简单的缓存,并发高,但是存在redis和 Db 双写不一致,读写并发不一致问题
- 解决方案 1
- 解决方案 2
- 解决方案 3
- 读写锁
- 缓存构建
- 解决方案 1 加分布式锁
- 解决方案 2 dcl 双重校验
- 解决方案 3 定时器兜底
- 双重校验以及防止大流量从缓存构建
- 多级缓存
- 缓存穿透
- 方案 1
- 方案 2
- 缓存雪崩
Redis缓存结构详解
前言
一般开发中我们都会使用 Redis 作缓存,提高查询效率,但 Redis 缓存在使用时还会有很多问题,如,缓存穿透,击穿,雪崩等。
一般对于不同的业务我们使用不同的缓存结构。
-
1、对于并发几率很小的数据(如个人维度的订单数据、用户数据等),这种几乎不用考虑这个问题,很少会发生 缓存不一致,可以给缓存数据加上过期时间,每隔一段时间触发读的主动更新即可。
-
2、就算并发很高,如果业务上能容忍短时间的缓存数据不一致(如商品名称,商品分类菜单等),缓存加上过期 时间依然可以解决大部分业务对于缓存的要求。
-
3、如果不能容忍缓存数据不一致,可以通过加分布式读写锁保证并发读写或写写的时候按顺序排好队,读读的 时候相当于无锁。
-
4、也可以用阿里开源的canal通过监听数据库的binlog日志及时的去修改缓存,但是引入了新的中间件,增加 了系统的复杂度。
Redis 缓存架构
首先,我们在开发中经常这么写,先从 redis 查询,redis没有再从db查,一般都是这么写的,但是不同业务对数据一致性和实时性要求很高,一些业务又不需要特别强的一致性,有一些又需要强一致性,对此我们再使用 Redis 做缓存时候需要针对不同业务提供不同的缓存架构。
这里逐步对数据一致性和性能以及并发问题,用 Redis 做为缓存,针对不同业务模型使用 Redis逐级递增。
redis 和db数据一致性
先写db还是写redis
先更新redis还是先更新db,无论更新那个都存在问题。
1 双写不一致
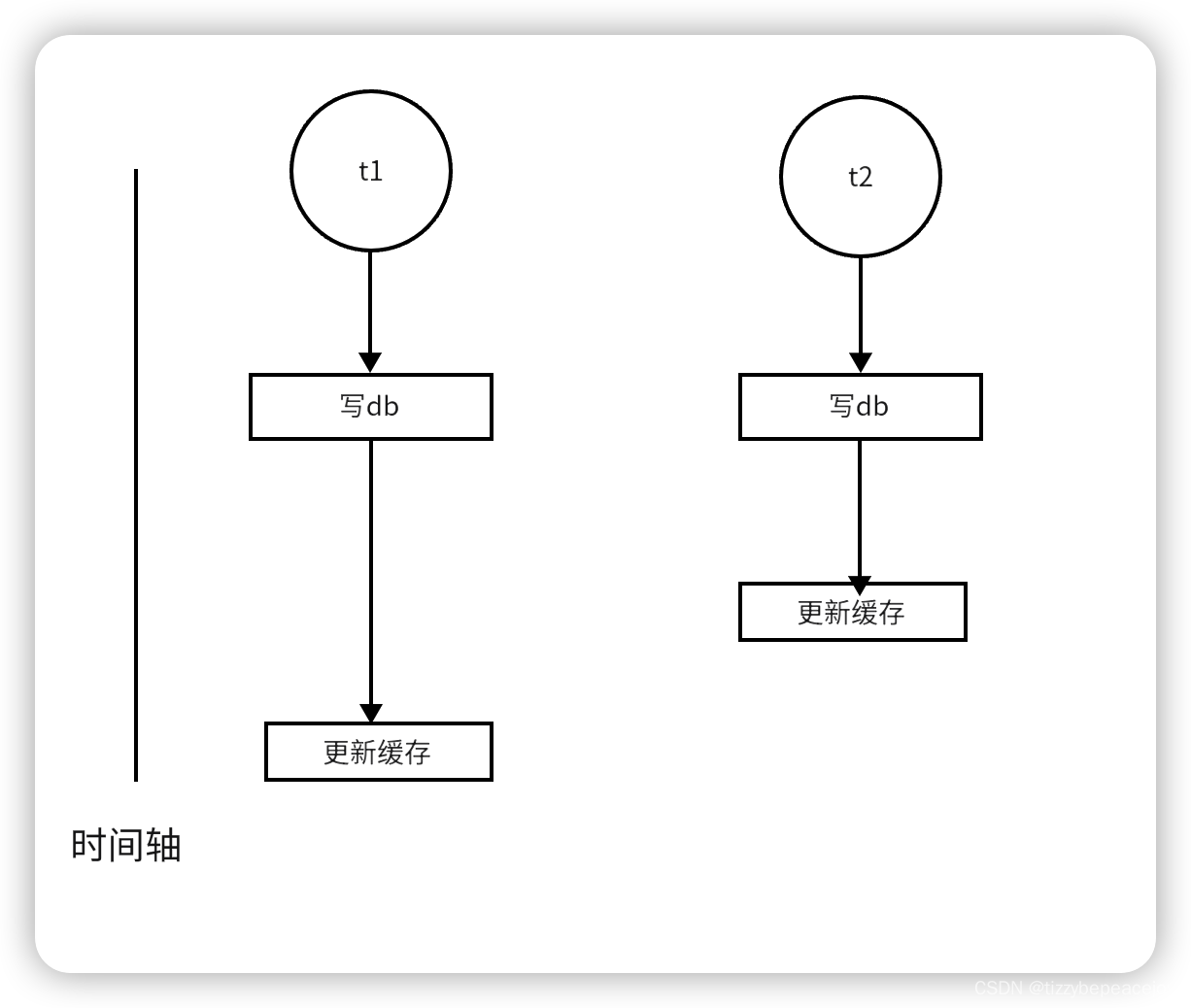
线程 1 写数据稍微慢点,中间有线程 2 更新成功,此时线程 1 再更新成功,对于线程 2 来说缓存还是旧数据,同理先更新reids再db也是一样的。
如果是先写db,再删除缓存呢?
读写并发不一致问题
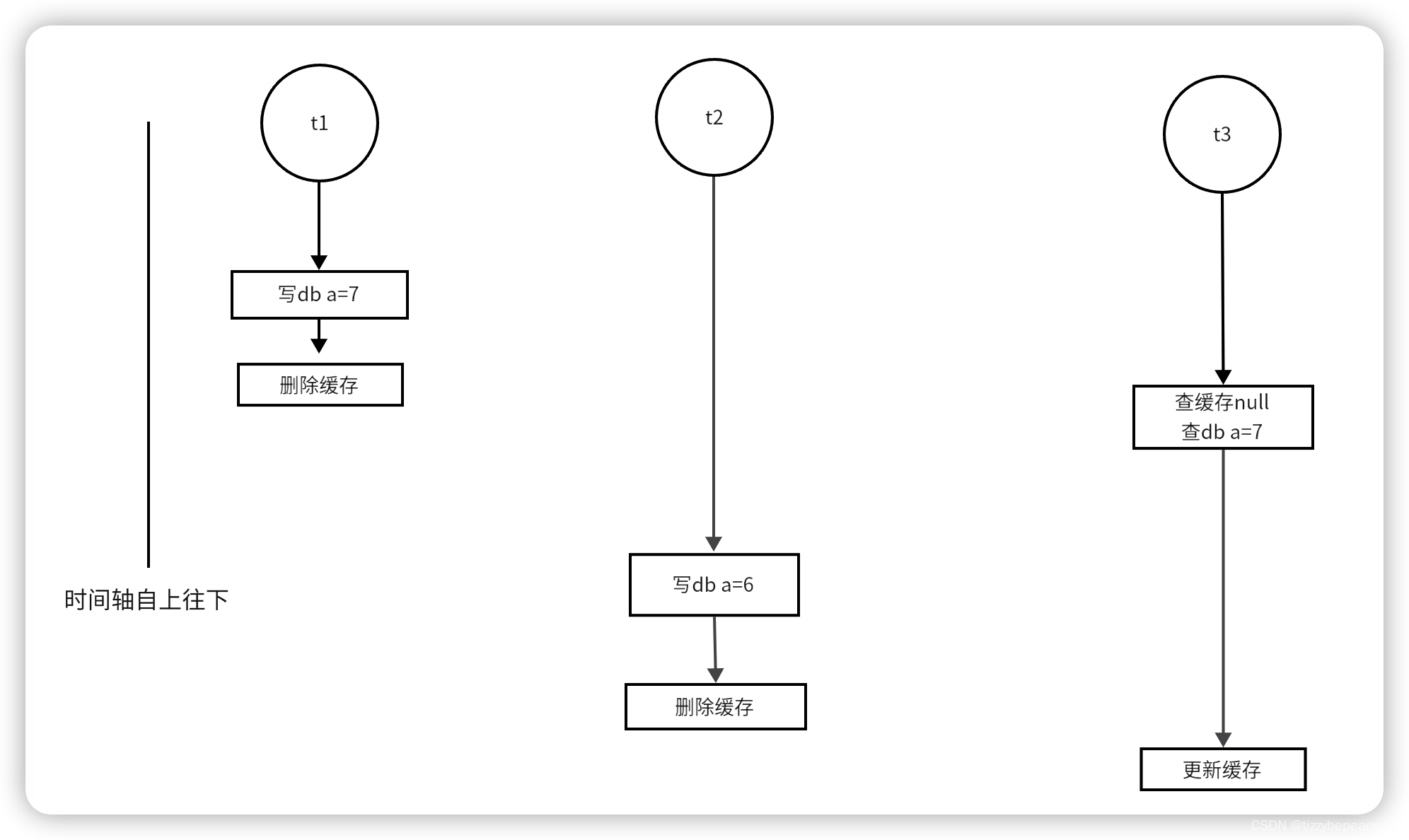
t1 更新 a=7提交成功,删除缓存,t2更新a=6删除db,此时 t2 还没提交事务,t3查缓存a=7 ,此时t2在t3更新缓存之前更新成功同时也删除缓存,t3最后更新了缓存。缓存数据还是7 相比t2操作就是脏数据了。
那该如何更新缓存呢?
延迟双删
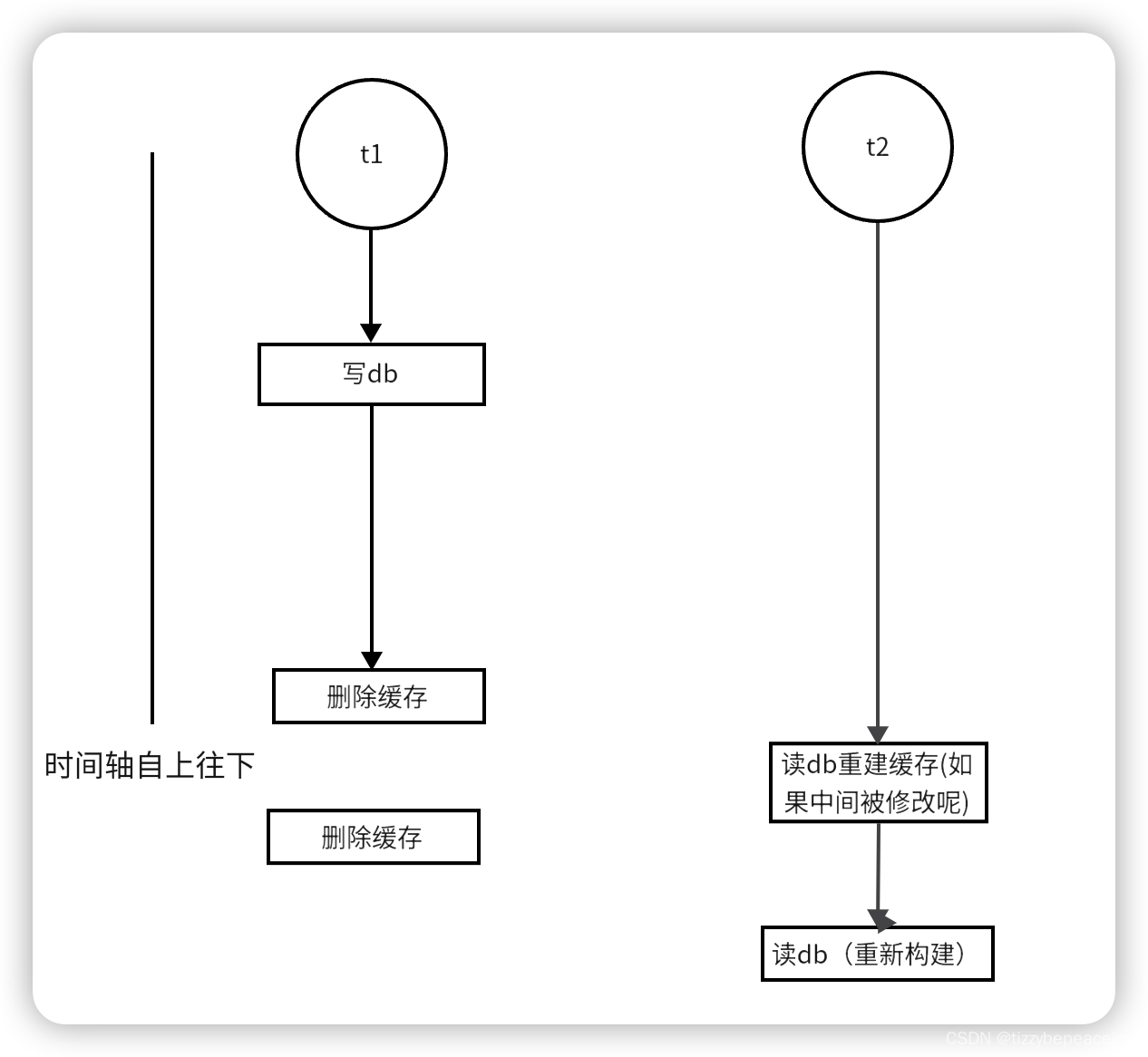
延迟双删,先更新db,再删除缓存,隔几秒再删除缓存,但是这中间几秒如果有别的节点可能又接着改库了,所以更新缓存貌似没啥意义,删除就好了,最大程度保证缓存和数据库数据一致。
中间这几秒数据不一致,之后重建缓存,尽可能保证数据源一致,但是这几秒的业务逻辑是有问题的。
- Bin log更新缓存
利用bin log mq 异步重试更新
但是一般来说具体的业务使用不同的方案,很少有哪种方法是完美的,都是各种因素综合考虑下来认为相对较优的解。
简单的缓存,并发不高,没啥流量
首先简单的缓存,并发不高,没啥流量,代码如下:
更新放缓存
@Transactionalpublic Product update(Product product) {Product productResult = productDao.update(product);redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), JSON.toJSONString(productResult),genProductCacheTimeout(), TimeUnit.SECONDS);return productResult;}
也不怎么关心缓存是否更新成功,本来业务就没啥流量,更不怎么去关心数据一致性问题。
//从缓存读public Product get1(Long productId) throws InterruptedException {Product product = null;String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;String productStr = redisUtil.get(productCacheKey);if (!StringUtils.isEmpty(productStr)) {if (EMPTY_CACHE.equals(productStr)) {return null;}product = JSON.parseObject(productStr, Product.class);}product = productDao.create(product);if (product == null) {return null;}//更新缓存redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + product.getId(), JSON.toJSONString(product),genProductCacheTimeout(), TimeUnit.SECONDS);return product;}如果流量稍微大点或者间接性有请求,不想从db读,尽量从redis读取,可以将时间设置久点,也可以每次进来就续期,延长缓存时间。
从缓存读 并且 读延期
//从缓存读 并且 读延期public Product get2(Long productId) throws InterruptedException {Product product = null;String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;String productStr = redisUtil.get(productCacheKey);if (!StringUtils.isEmpty(productStr)) {if (EMPTY_CACHE.equals(productStr)) {// //读延期redisUtil.expire(productCacheKey, genEmptyCacheTimeout(), TimeUnit.SECONDS);return new Product();}product = JSON.parseObject(productStr, Product.class);redisUtil.expire(productCacheKey, genProductCacheTimeout(), TimeUnit.SECONDS); //读延期}return product;}
简单的缓存,并发高,但是存在redis和 Db 双写不一致,读写并发不一致问题
如果对实时性要求不高,直接设置缓存时间即可
如果对实时性要求高:
- 1 如果稍微对实时性要求比较高,可以允许短时间内的不一致,设置缓存时间(设置短一点即可)
- 2 延迟双删策略,读的时候从新加载,短时间内读的旧数据.可以接受
- 3 一点也不能接受,加分布式锁,强一致性
- 4 binlog订阅 ,mq 更新
解决方案 1
缓存设置时间
public Product get1(Long productId) throws InterruptedException {Product product = null;String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;String productStr = redisUtil.get(productCacheKey);if (!StringUtils.isEmpty(productStr)) {if (EMPTY_CACHE.equals(productStr)) {// //读延期redisUtil.expire(productCacheKey, genEmptyCacheTimeout(), TimeUnit.SECONDS);return new Product();}product = JSON.parseObject(productStr, Product.class);redisUtil.expire(productCacheKey, genProductCacheTimeout(), TimeUnit.SECONDS); //读延期}return product;}
解决方案 2
延迟双删策略,读的时候从新加载,短时间内读的旧数据.可以接受
更新修改缓存
@Transactionalpublic Product update2(Product product) {Product productResult = productDao.update(product);//这里先删除redisUtil.del(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId());//ToDo 延迟几秒后可以再删除一次 防止删除失败或者另一个线程进来也操作更新数据//这里用线程异步模拟删除new Thread(()->{try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}redisUtil.del(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId());}).start();return productResult;}
读数据和上面一致
public Product get2(Long productId) throws InterruptedException {Product product = null;String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;String productStr = redisUtil.get(productCacheKey);if (!StringUtils.isEmpty(productStr)) {if (EMPTY_CACHE.equals(productStr)) {// //读延期redisUtil.expire(productCacheKey, genEmptyCacheTimeout(), TimeUnit.SECONDS);return null;}product = JSON.parseObject(productStr, Product.class);redisUtil.expire(productCacheKey, genProductCacheTimeout(), TimeUnit.SECONDS); //读延期}product = productDao.create(product);if (product == null) {// //读延期redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productId, EMPTY_CACHE, genProductCacheTimeout(), TimeUnit.SECONDS);return null;}redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + product.getId(), JSON.toJSONString(product),genProductCacheTimeout(), TimeUnit.SECONDS);return product;}
解决方案 3
加分布式锁,强一致性
这里分布式锁不考虑使用哪个,不在本文讨论,具体查redis分布式锁
这里我用的是redisson 分布式锁
更新缓存
//todo 这里应该先加锁,再开事务@Transactionalpublic Product update3(Product product) {RLock lock = redisson.getLock("product:" + product.getId());//加锁尽量加时间//lock.lock();lock.lock(5,TimeUnit.SECONDS);Product productResult;try {productResult = productDao.update(product);redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), JSON.toJSONString(productResult),genProductCacheTimeout(), TimeUnit.SECONDS);}finally {lock.unlock();}return productResult;}
加分布式锁,并发过程中还是会读到旧数据,读写不互斥
多个线程下,有一个更新缓存,其他的并行读取的还是旧数据。
当然你也可以给读加锁,但是读性能就下降了。没必要。对此需要使用读写锁
public Product get3(Long productId) throws InterruptedException {Product product = null;String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;String productStr = redisUtil.get(productCacheKey);if (!StringUtils.isEmpty(productStr)) {if (EMPTY_CACHE.equals(productStr)) {// //读延期redisUtil.expire(productCacheKey, genEmptyCacheTimeout(), TimeUnit.SECONDS);return null;}product = JSON.parseObject(productStr, Product.class);redisUtil.expire(productCacheKey, genProductCacheTimeout(), TimeUnit.SECONDS); //读延期}product = productDao.create(product);if (product == null) {// //读延期redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productId, EMPTY_CACHE, genProductCacheTimeout(), TimeUnit.SECONDS);return null;}redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + product.getId(), JSON.toJSONString(product),genProductCacheTimeout(), TimeUnit.SECONDS);return product;}
读写锁
加分布式锁,强一致性,读写锁互斥,写操作读阻塞,防止并发读旧数据。
//todo 应该先加锁,再开事务@Transactionalpublic Product update3_1(Product product) {RReadWriteLock lock = redisson.getReadWriteLock("product:" + product.getId());//加锁RLock rLock = lock.writeLock();rLock.lock(5,TimeUnit.SECONDS);Product productResult;try {productResult = productDao.update(product);redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), JSON.toJSONString(productResult),genProductCacheTimeout(), TimeUnit.SECONDS);}finally {rLock.unlock();}return productResult;}
读取数据
此时,更新数据的时候,其他读线程会阻塞,直到更新成功,读读不回互斥,读读根本就没有数据变化,也就不存在竞争条件了。
读写锁请参考aqs里的java读写锁,原理是一样的,只不过redis redisson基于分布式封装了一个分布式场景的
public Product get3_1(Long productId) throws InterruptedException {RReadWriteLock lock = redisson.getReadWriteLock("product:" + productId);//加锁RLock rLock = lock.readLock();Product product = null;rLock.lock(5,TimeUnit.SECONDS);try {String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;String productStr = redisUtil.get(productCacheKey);if (!StringUtils.isEmpty(productStr)) {if (EMPTY_CACHE.equals(productStr)) {// //读延期redisUtil.expire(productCacheKey, genEmptyCacheTimeout(), TimeUnit.SECONDS);return null;}product = JSON.parseObject(productStr, Product.class);redisUtil.expire(productCacheKey, genProductCacheTimeout(), TimeUnit.SECONDS); //读延期}product = productDao.create(product);if (product == null) {// //读延期redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productId, EMPTY_CACHE, genProductCacheTimeout(), TimeUnit.SECONDS);return null;}redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + product.getId(), JSON.toJSONString(product),genProductCacheTimeout(), TimeUnit.SECONDS);}finally {rLock.unlock();}return product;}缓存构建
以上缓存,前提是缓存里有数据,不会访问缓存,如果说某一瞬间,缓存里数据都没有或者某个商品没有缓存,瞬时进来大量的流量,直接缓存击穿,并发高大量线程同时查询db,严重可能会直接打满db,造成后端服务出故障。
对于这种问题,我们需要防止出现此类问题,尽量让少部分线程打到db,或者让少部分线程去 Db查然后构建到redis里。
解决办法:
- 1 加分布式锁
- 2 dcl 双重校验
- 3 定时器兜底
解决方案 1 加分布式锁
防止大流量进来从db构建缓存,但是没有解决缓存不一致问题,双写问题,以及并发读写问题不一致问题(这里不考虑,需要请看上面实例哦)
public Product get0(Long productId) throws InterruptedException {Product product = null;product = getProductFromRedis(productId, product);if (product == null) return null;RLock lock = redisson.getLock(RedisKeyPrefixConst.PRODUCT_CACHE + productId);lock.lock(5, TimeUnit.SECONDS);try {product = productDao.create(product);if (product == null) {// //读延期redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productId, EMPTY_CACHE, genProductCacheTimeout(), TimeUnit.SECONDS);return null;}redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + product.getId(), JSON.toJSONString(product),genProductCacheTimeout(), TimeUnit.SECONDS);} finally {lock.unlock();}return product;}解决方案 2 dcl 双重校验
但加个分布式锁,确实是能解决,但是并发高的情况下,还是会有很多线程先去查redis,缓存没查到,会加锁,再排队走db。这把锁感觉没加似的,这个有没很像我们单例模式哪里?对此可以参考dcl 单例模式哪里去解决,在锁里再去判断一下,后面就不会再走db了。
//dcl 双重校验 防止大流量从db构建缓存public Product get1(Long productId) throws InterruptedException {Product product = null;product = getProductFromRedis(productId, product);if (product == null) return null;RLock lock = redisson.getLock(RedisKeyPrefixConst.PRODUCT_CACHE + productId);lock.lock(5, TimeUnit.SECONDS);//dcl 校验从缓存里获取product = getProductFromRedis(productId, product);if (product == null) return null;try {product = productDao.create(product);if (product == null) {// //读延期redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productId, EMPTY_CACHE, genProductCacheTimeout(), TimeUnit.SECONDS);return null;}redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + product.getId(), JSON.toJSONString(product),genProductCacheTimeout(), TimeUnit.SECONDS);} finally {lock.unlock();}return product;}但目前很多线程这里排队等待,之后还是会走加锁这个逻辑。
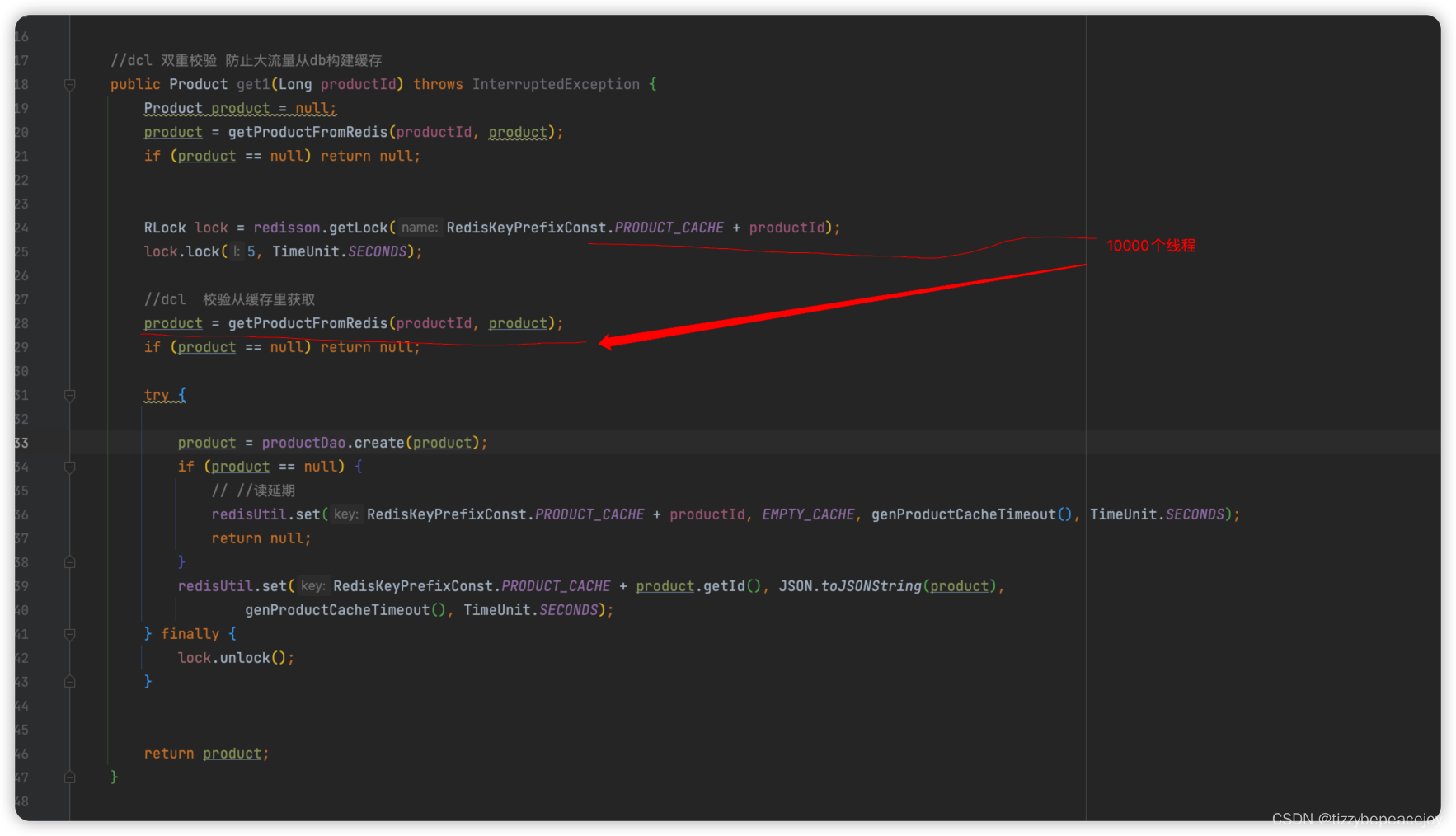
1w 个线程在这里lock,然后串行,这得多慢。
解决这种办法,我们可以让试着获取锁,没获取到就从缓存里查,只要有一个线程构建成功,之后根本就不需要加锁了,直接从缓存查就 Ok…
lock.tryLock(5, TimeUnit.SECONDS);
尝试获取锁,其实也会存在问题,如果都没获取到,还是会走db查询,但这种也不大可能,大概不会出现这种问题,除非db特别拉胯,一个线程拿到锁,构建缓存构建半天…
加锁和尝试加锁都有一些优点和缺点,这种问题出现的概率一般不大,具体问题具体对待,没有哪一种方案是特别完美的。
解决方案 3 定时器兜底
有些业务缓存场景查询,可以用定时器去查结果然后缓存到redis里
有那么一段时间缓存里可能没预热数据,也可以用定时器去定时job跑数据,存redis里。
双重校验以及防止大流量从缓存构建
上面单独防止大流量从缓存构建 , 读写锁数据强一致性
组合起来就是既能强一致性又能防止大流量从db构建缓存
读缓存
public Product get2(Long productId) throws InterruptedException {Product product = null;product = getProductFromRedis(productId, product);if (product == null) return null;RLock lock = redisson.getLock(RedisKeyPrefixConst.PRODUCT_CACHE + productId);lock.lock(5, TimeUnit.SECONDS);try {//dcl 校验从缓存里获取product = getProductFromRedis(productId, product);if (product == null) return null;RReadWriteLock readWriteLock = redisson.getReadWriteLock(RedisKeyPrefixConst.PRODUCT_CACHE + productId);RLock readLock = readWriteLock.readLock();readLock.lock(5,TimeUnit.SECONDS);try {product = productDao.create(product);if (product == null) {// //读延期redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productId, EMPTY_CACHE, genProductCacheTimeout(), TimeUnit.SECONDS);return null;}redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + product.getId(), JSON.toJSONString(product),genProductCacheTimeout(), TimeUnit.SECONDS);}finally {readLock.unlock();}} finally {lock.unlock();}return product;}更新缓存
public Product update2(Product product) {Product productResult;RReadWriteLock readWriteLock = redisson.getReadWriteLock(RedisKeyPrefixConst.PRODUCT_CACHE + product.getId());RLock writeLock = readWriteLock.writeLock();writeLock.lock(5, TimeUnit.SECONDS);try {productResult = productDao.update(product);redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), JSON.toJSONString(productResult),genProductCacheTimeout(), TimeUnit.SECONDS);} finally {writeLock.unlock();}return productResult;}
多级缓存
我们都知道单台 redis 节点 可以抗10w 并发,像一些场景,某个直播带货,一个冷门商品,突然爆火了,瞬时 几千万流量进来,redis根本扛不住,如果我们将数据缓存到jvm里呢?
设置jvm本地缓存,以及及时更新本地缓存(用mq或者 bin log订阅,会有一点点延迟,可以接受),如果再扛不住,扩容和限流…
//ToDo 这里用map 模拟, 应该用淘汰策略的jvm本地缓存框架,如spring cache , Guava Cachepublic static final Map<String,Object> LOCAL_CACHE = new ConcurrentHashMap<>();
构建缓存
public Product create3(Product product) {Product productResult;RReadWriteLock readWriteLock = redisson.getReadWriteLock(RedisKeyPrefixConst.PRODUCT_CACHE + product.getId());RLock writeLock = readWriteLock.writeLock();writeLock.lock(5, TimeUnit.SECONDS);try {productResult = productDao.create(product);redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), JSON.toJSONString(productResult),genProductCacheTimeout(), TimeUnit.SECONDS);LOCAL_CACHE.put(RedisKeyPrefixConst.PRODUCT_CACHE + product.getId(),product);} finally {writeLock.unlock();}return productResult;}
读取缓存
public Product get3(Long productId) throws InterruptedException {Product product = null;product = getProductFromRedisAndLoclCache(productId, product);if (product == null) return null;RLock lock = redisson.getLock(RedisKeyPrefixConst.PRODUCT_CACHE + productId);lock.lock(5, TimeUnit.SECONDS);//dcl 校验从缓存里获取product = getProductFromRedisAndLoclCache(productId, product);if (product == null) return null;try {RReadWriteLock readWriteLock = redisson.getReadWriteLock(RedisKeyPrefixConst.PRODUCT_CACHE + productId);RLock readLock = readWriteLock.readLock();readLock.lock(5,TimeUnit.SECONDS);try {product = productDao.create(product);if (product == null) {// //读延期redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productId, EMPTY_CACHE, genProductCacheTimeout(), TimeUnit.SECONDS);LOCAL_CACHE.put(RedisKeyPrefixConst.PRODUCT_CACHE + productId,product);return null;}redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + product.getId(), JSON.toJSONString(product),genProductCacheTimeout(), TimeUnit.SECONDS);LOCAL_CACHE.put(RedisKeyPrefixConst.PRODUCT_CACHE + productId,product);}finally {readLock.unlock();}} finally {lock.unlock();}return product;}// 从redis里获取数据 和本地缓存里获取private Product getProductFromRedisAndLoclCache(Long productId, Product product) {String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;//从jvm本地缓存虎丘Object o = LOCAL_CACHE.get(productCacheKey);if (o != null) {return (Product) o;}String productStr = redisUtil.get(productCacheKey);if (!StringUtils.isEmpty(productStr)) {if (EMPTY_CACHE.equals(productStr)) {// //读延期redisUtil.expire(productCacheKey, genEmptyCacheTimeout(), TimeUnit.SECONDS);return null;}product = JSON.parseObject(productStr, Product.class);redisUtil.expire(productCacheKey, genProductCacheTimeout(), TimeUnit.SECONDS); //读延期}return product;}如果从本地读取缓存,那我们也需要维护本地缓存,本来 db 和redis数据一致性就够麻烦了,再多一层本地缓存,意味着系统复杂性又增加。
维护本地缓存,这里我们可以使用bin log去维护,延迟性不是很高,偶尔有一点点不一致,是可以接受的。
这种缓存需要注意的是
- jvm本地cache 是需要同步更新所有的… 如果有一个没更新成功会产生脏数据,建议使用binl log订阅去更新.
- 这种方案不能解决热点中实时热点的数据,可能需要配合大数据去实时计算监控热点数据…
- 可能过一段时间就不是热点了,需要实施维护,另外jvm缓存空间是有限的,针对这种建议用另外一种针对热点的系统进行维护…
缓存穿透
上面解决了缓存击穿,缓存一致性问题,但是面对恶意攻击,如果说查一些数据我们缓存里没有,redis里也没有,我们的缓存就形同虚设。
缓存穿透是指查询一个根本不存在的数据, 缓存层和存储层都不会命中, 通常出于容错的考虑, 如果从存储 层查不到数据则不写入缓存层。 缓存穿透将导致不存在的数据每次请求都要到存储层去查询, 失去了缓存保护后端存储的意义。 造成缓存穿透的基本原因有两个:
第一, 自身业务代码或者数据出现问题。
第二, 一些恶意攻击、 爬虫等造成大量空命中。
面对(缓存穿透问题) 解决方案
- 1 设置null值
- 2 布隆过滤器
这里不考虑,双写一致,并发读写,大流量缓存构建以及实时性等问题
方案 1
public static final Integer PRODUCT_CACHE_TIMEOUT = 60 * 60 * 24;public static final String EMPTY_CACHE = "{}";//短时间内 null 缓存public Product get0_1(Long productId) throws InterruptedException {Product product = null;String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;String productStr = redisUtil.get(productCacheKey);if (!StringUtils.isEmpty(productStr)) {if (EMPTY_CACHE.equals(productStr)) {// //读延期redisUtil.expire(productCacheKey, genEmptyCacheTimeout(), TimeUnit.SECONDS);return null;}product = JSON.parseObject(productStr, Product.class);redisUtil.expire(productCacheKey, genProductCacheTimeout(), TimeUnit.SECONDS); //读延期}product = productDao.create(product);if (product == null) {// //读延期redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productId, EMPTY_CACHE, genProductCacheTimeout(), TimeUnit.SECONDS);return null;}redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + product.getId(), JSON.toJSONString(product),genProductCacheTimeout(), TimeUnit.SECONDS);return product;}
方案 2
使用布隆过滤器,这里我用伪代码。
public Product get0_2(Long productId) throws InterruptedException {Product product = null;RBloomFilter<Long> bloomFilter = bloomFilter();boolean contains = bloomFilter.contains(productId);if (!contains){//ToDo "非法的商品id 或者 从db查询"product = getProductFromDb(productId, product);if (product == null){throw new RuntimeException("非法字符!");}return product;}String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;String productStr = redisUtil.get(productCacheKey);if (!StringUtils.isEmpty(productStr)) {if (EMPTY_CACHE.equals(productStr)) {// //读延期redisUtil.expire(productCacheKey, genEmptyCacheTimeout(), TimeUnit.SECONDS);return null;}product = JSON.parseObject(productStr, Product.class);redisUtil.expire(productCacheKey, genProductCacheTimeout(), TimeUnit.SECONDS); //读延期}return getProductFromDb(productId, product);}
布隆过滤器点击查看
private RBloomFilter<Long> bloomFilter(){RBloomFilter<Long> bloomFilter = redisson.getBloomFilter("products:type");return bloomFilter;}//todo 布隆过滤器数据初始化,布隆过滤器不能删除数据,必须重新初始化@PostConstructprivate RBloomFilter<Long> init(){RBloomFilter<Long> bloomFilter = bloomFilter();List<Product> products = Arrays.asList(new Product(1L, "iPhone 11"),new Product(2L, "iPhone 11 pro"),new Product(3L, "iPhone 11 pro max"));products.forEach(x-> bloomFilter.add(x.getId()));return bloomFilter;}
缓存雪崩
在使用缓存时,通常会对缓存设置过期时间,一方面目的是保持缓存与数据库数据的一致性,另一方面是减少冷缓存占用过多的内存空间。
但当缓存中大量热点缓存采用了相同的实效时间,就会导致缓存在某一个时刻同时实效,请求全部转发到数据库,从而导致数据库压力骤增,甚至宕机。从而形成一系列的连锁反应,造成系统崩溃等情况。
预防和解决缓存雪崩问题, 可以从以下几个方面进行着手。
-
通常的解决方案是将key的过期时间后面加上一个随机数(比如随机1-5分钟),让key均匀的失效。
-
考虑用队列或者锁的方式,保证缓存单线程写,但这种方案可能会影响并发量。
-
热点数据可以考虑不失效,后台异步更新缓存,适用于不严格要求缓存一致性的场景。
-
双key策略,主key设置过期时间,备key不设置过期时间,当主key失效时,直接返回备key值。
-
构建缓存高可用集群(针对缓存服务故障情况)。比如使用Redis Sentinel或Redis Cluster。
-
当缓存雪崩发生时,服务熔断、限流、降级等措施保障。比如使用Sentinel或Hystrix限流降级组件。