从零开始——单服务应用
单体应用技术选型
- (GitHub、Gitee…)搜索是否有线程的产品
- 用最熟悉的技术,最快的速度上线
- 如果有经费:考虑商业化解决方案
个人小程序怎么做技术选型的
- 搜索是否有快速搭建下程序的软件
- 技术选型
- 后端技术选型
- 用最熟悉的技术,达到最快的开发速度
- MySQL、MyBatis、SoringBoot
- 前端技术选型
- 后端技术选型

应用服务、数据服务分离
- 企业级应用的起步阶段
- 两个目的
- 选择合适的技术实现项目的落地
- 为项目未来的发展方向定好基调

要考虑的问题
- 运行平台的选择
- 选择商业解决方案还是开源解决方案
- 确定项目的研发模式
- 确定具体使用的技术
事半功倍——引入缓存系统
要考虑的问题
- 在哪个位置使用缓存
- 采用什么类型的缓存
- 采用那种缓存模式
- 具体用什么缓存组件
缓存位置
- 客户端缓存
- 浏览器中的缓存
- APP缓存
- 网络中缓存
- 代理服务器缓存
- CDN缓存
- 服务端缓存
如何确定缓存的位置
- 没有性能瓶颈不考虑,那里慢就在那里用缓存
缓存类型
- 内存缓存
- 速度非常快,数据可能会丢失
- 适用于速度要求非常高,容忍数据丢失的场景
- 堆内缓存
- 优点:
- 无需序列化、反序列化
- 性能很好
- 缺点:
- 会对GC造成影响
- 容量受限于堆内存的大小
- 一般为软引用或弱引用存储
- 堆内缓存适用场景
- 存储非常热的数据
- 优点:
- 磁盘缓存
- 性能比内存缓存差,数据不会丢失
- 适用于需要持久化的场景
负载均衡

基于DNS的负载均衡
- 在DNS服务器上为多个地址配置相同的解析记录
- 优点:
- 把负载均衡的工作交给了DNS服务器,减少了网站管理的维护工作
- 技术实现比较灵活、方便、简单易行、成本低
- 适用面广,能适用于大多数TCP/IP应用
- 缺点:
- 一般不能反映服务器当前运行状态
- 某台服务器下线之后,即使修改了DNS记录,要想让记录生效可能需要很长时间
- 保证DNS解析指向的目标地址高可用、地址不会经常修改
- 一般来说,大型网站会用DNS作为一级负载均衡
- DNS指向的IP,对应的并不是一台机器,而是高可用的服务器集群
- dig命令可查询记录
基于反向代理的负载均衡
- 请求经过反向代理,由反向代理组件提供负载均衡算法,计算出一个服务器地址返回
- 代表实现
- NGINX
- HAProxy
- Apache
互联网项目负载均衡器演变的典型过程(经验)
- 项目初期:NGINX
- 中期:结合Keepalived实现NGINX的高可用
- 之后,再搭载LVS或F5,从而扩展多个NGINX
- 如果一个LVS集群顶不住的饿话,会再结合DNS扩展LVS
有状态VS无状态
- 状态:服务器是否要存储用户的登录状态
- 服务器端是否要维护用户的会话
有状态
粘性会话
- 当客户端在一台Web Server上登录后,以后的请求都会绑定到该Web Server实例

- 优缺点
- 无需引入额外组件
- 实现简单
- 存在单点问题:需要额外实现故障转移
- 可能有不均衡问题
会话共享

- 使用session保持会话,多个应用实例存储到一个中央存储中去
- 优缺点
- 需要额外引入组件,即使任意Web应用崩溃依然可用
- 但Session Store一旦崩溃,所有会话都会丢失
会话复制

- Web Server实例之间互相复制会话
- 优缺点
- 无需实现故障转移
- 无需引入额外组件
- 会话复制消耗带宽和内存
无状态
- 服务器端不去记录用户的登录状态:服务器端不再去维护会话
- 用户登录时,办法一个token,这个token一般是加密的
- 之后每个请求都会带上这个token(放在header、URL参数、Cookie中传递)
- 有状态的缺点 = 无状态的优点
- 无状态的缺点:
- 一旦把token颁发给用户,就很难控制它的下线时间

- 一旦把token颁发给用户,就很难控制它的下线时间
有状态 vs 无状态

读写分离

CDN
- 静态文件:效果非常好
- 动态数据:效果不佳
- 动态内容静态化
- 动静分离
CDN组成原理

CDN技术选型要考虑的问题
- 自建 or 商用
- 优先使用商用CDN
- 当商用CDN满足不了业务需求,顶不住的时候,再考虑自建
- 原因:自建很不划算
- 小米、快手、大众点评 => 都是商用CDN
- 如何挑选CDN
- 速度
- 节点数
- 带宽能力
- 节点分布
- 功能
-
加速优化
- DNS优化

-
监控统计
- 实时监控:点击率、命中率、占用流量
- 访问日志监控
-
安全性
- 防盗链
- IP黑白名单
-
- 价格
- 按带宽峰值计费
- 按流量计费
- 速度
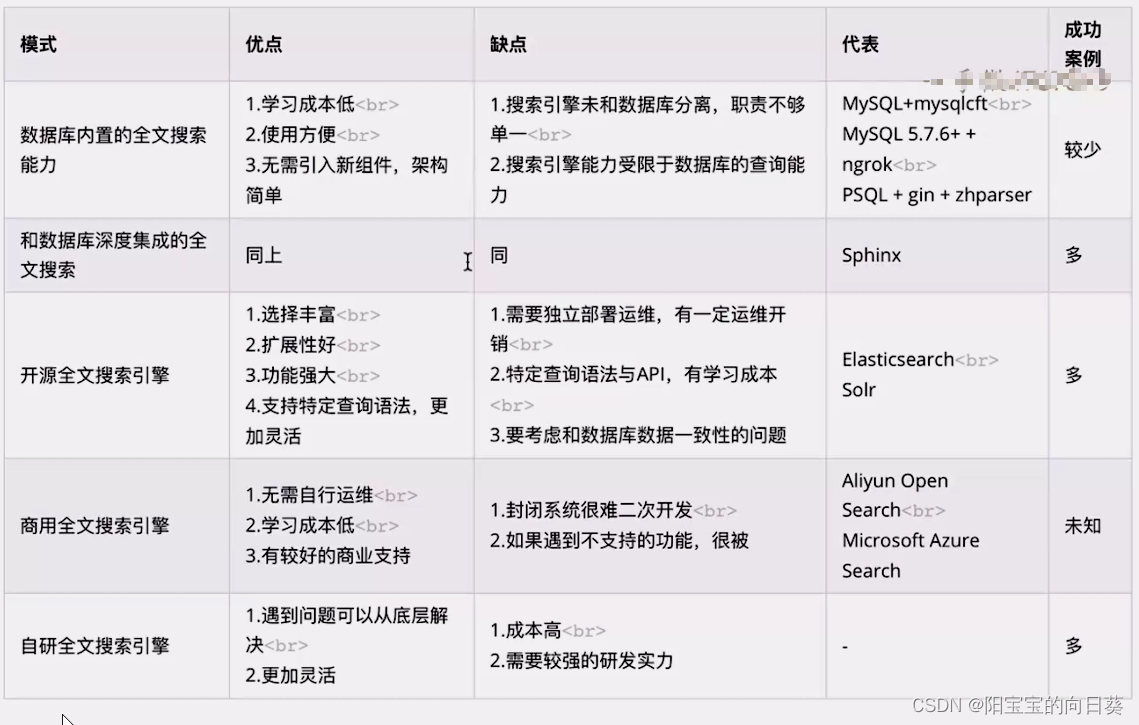
全文检索
- 减轻了数据库的查询压力
- 提升应用性能,提高用户体验
- 实现全文检索的五种路径
- 使用数据库内置的全文搜索能力
- 使用和数据库深度集成的全文搜索
- 使用开源全文所搜引擎
- 使用商用全文搜索引擎
- 自研全文搜索引擎
使用数据库内置的全文搜索能力

- 优点
- 学习成本低
- 方便
- 无需引入新的组件,保持了架构上的简单性
- 缺点
- 搜索引擎没有和数据库分离,数据库的职责不够单一
- 全文搜索的能力受限于数据库的查询能力
- 不建议使用
使用和数据库深度集成的全文搜索
- 代表实现:Sphinx
- 可独立运行
- 可以和MySQL、PostgreSQL深度集成
- 选型建议
- Sphinx在业界非常流行
- 如果看中运维成本,同时对扩展性没有太高要求,可以尝试
- Tips
- Sphinx相对于其他全文搜索引擎来说,功能并不是很强
- 国内文档不多
- 越来越多的企业在从Sphinx往第三种模式迁移
使用开源全文所搜引擎
- 目前最主流的方式
- 选择丰富
- 扩展性非常好
- 缺点
- 需要独立部署搜索引擎
- 需使用搜索引擎特有语法操作搜索引擎
- 既是缺点也有优点,缺点在于有学习成本,好处就是能够支持更加复杂的查询;另外像Elasticsearch之类的搜索引擎既支持DSL,也支持SQL
- 搜索引擎和数据库是独立的两个软件,需要考虑数据一致性
- 借助logstash-input-jdbc之类的插件同步
- 应用写入数据库的同时也写到搜索引擎
- 选型建议:可以放心使用
使用商用全文搜索引擎
- 阿里云Open Search
- 微软的Microsoft Azure Search
- 成功案例不多
- 选型建议
- 商用产品有良好的服务,省事、省心,可以放心使用
- 要考虑商用产品封闭性所带来的影响:例如厂商很难根据你的特殊需求专门定制
自研全文搜索引擎
- 阿里、苏宁、万得资讯、东方财富
- 优点:核心技术在自己手上,有更好的灵活度,遇到问题可以从底层调整与优化
- 缺点:遂团队的技术要求会比较高,成本也非常高