#Paper reading#
DeepInf: Social Influence Prediction with Deep Learning
设计了一个端到端的框架DeepInf,研究用户层面的社会影响力预测。
论文地址:link
Abstract
社交和信息网络活动,如Facebook,Twitter,WeChat,Weibo已经成为我们日常生活中不可缺少的一部分,我们可以很容易地了解到朋友的行为,进而受到他们的影响。因此,对每个用户进行有效的社会影响力预测对于各种应用(如在线推荐和广告)至关重要。传统的社会影响预测方法通常会设计各种手工制作的规则来提取特定于用户和网络的特征。然而,它们的有效性很大程度上依赖于领域专家的知识。因此,通常很难将它们归纳到不同的领域。受deep神经网络最近在广泛的计算应用中取得成功的启发,我们设计了一个端到端的框架DeepInf[^1],以学习用户的潜在特征表示来预测社会影响力。一般来说,DeepInf将用户的局部网络作为图神经网络的输入,以学习其潜在的社会表征。我们设计策略将网络结构和用户特定特征结合到卷积神经网络和注意力网络中。在开放学术图、Twitter、Weibo和Digg(代表不同类型的社交和信息网络)上进行的大量实验表明,所提出的端到端模型DeepInf的性能明显优于传统的基于特征工程的方法,表明了表征学习在社交应用中的有效性。
1.INTRODUCTION
社会影响无处不在,不仅存在于我们的日常生活中,也存在于虚拟的网络空间中。社会影响一词通常指的是一个人的情绪、观点或行为受到他人影响的现象。随着在线和移动社交平台的全球渗透,人们已经见证了社会影响力在各个领域的影响,比如总统选举[7]、广告[3,24]和创新采纳[42]。迄今为止,毫无疑问,社会影响已经成为一种普遍而复杂的力量,推动着我们的社会决策,显然需要方法来描述、理解和量化社会影响的潜在机制和动态。事实上,文献[26,32,42,43]中已经对社会影响预测做了大量工作。例如,Matsubara等人。[32]通过精心设计从经典的“易感感染”(SI)模型扩展而来的微分方程,研究了社会影响的动力学;最近,Li等人。[26]提出了一种结合递归神经网络(RNN)和表征学习来推断级联规模的端到端预测器。所有这些方法的主要目的是预测社会影响的全局或聚合模式,例如在一个时间范围内的级联规模。然而,在许多在线应用中,如广告和推荐,对每个个体的社会影响力进行有效的预测,即用户层面的社会影响力预测是非常关键的。本文主要研究用户层面的社会影响力预测。我们的目的是预测一个用户的动作状态,并给出其邻近邻居的局部结构信息。

图1:社会影响位置预测的激励性示例。我们的目标是预测v的行为状态,假设1)观察到的近邻居的行为状态(黑色和灰色圆圈分别表示“活跃”和“不活跃”),以及2)她嵌入的本地网络。
例如,在图1中,对于中心用户v,如果她的一些朋友(黑圈)购买了一个产品,她将来会购买同样的产品吗?上述问题在实际应用中普遍存在,但其复杂性和非线性经常被观察到,如[2]中的“S形”曲线以及[46]中著名的“结构多样性”。以上观察启发了很多用户级影响预测模型,其中大多数[27,53,54]考虑了复杂的手工制作的特征,这些特征需要对特定领域有广泛的了解,通常很难推广到不同的领域。受最近神经网络在表征学习中的成功启发,我们设计了一种端到端的方法来自动发现社会影响中的隐藏和预测信号。通过将网络嵌入[37]、图卷积[25]和图注意机制[49]构建到一个统一的框架中,我们期望端到端模型能够比传统的特征工程方法获得更好的性能。具体地说,我们提出了一个基于深度学习的框架DeepInf,将影响动态和网络结构都表示为一个潜在空间。为了预测一个userv的动作状态,我们首先用restart随机游动对她的本地邻居进行抽样。在获得如图1所示的局部网络之后,我们利用图卷积和注意力技术来学习潜在的预测信号。我们在开放学术图(OAG)、Digg、Twitter和Weibo四个不同领域的社交和信息网络上展示了我们提出的框架的有效性和效率。我们将DeepInf与几种传统方法进行了比较,例如具有手工制作特征的线性模型[54]以及最先进的图形分类模型[34]。实验结果表明,DeepInf模型能显著提高预测性能,为社会和信息网络挖掘任务提供表征学习的前景。
组织本文的其余部分安排如下:第二节阐述社会影响预测问题。第三部分详细介绍了所提出的框架。在第4节和第5节中,我们进行了广泛的实验和案例研究。最后,第六节对相关工作进行了总结,第七节对本课题进行了总结。
2 PROBLEM FORMULATION
在这一部分,我们介绍了必要的定义,然后阐述了预测社会影响的问题。
定义2.1。 r-neighbors和r-ego network设G =(V,E)是一个静态社交网络,其中V表示用户集和E⊆V×V表示关系集。 对于用户v,其r-neighbors被定义为 
鉴于上述定义,我们引入了社会影响局部性,这相当于一种封闭的世界假设:用户的社会决策和行动仅受到网络内近邻的影响,而假设外部来源不存在。

3.MODEL FRAMEWORK
在这一部分中,我们正式提出DeepInf,一个基于深度学习的模型,用于参数化等式1中的概率,并自动检测社会影响的机制和动态。该框架首先采样一个固定大小的子网络作为每个r-ego网络的代理(见第3.1节)。然后将采样的子网络输入具有小批量学习功能的深层神经网络(见第3.2节)。最后,将模型输出与地面真实情况进行比较,以最小化负对数似然损失。
3.1抽样邻近邻居
给定一个用户v,一种直接的方法提取她的r-ego网络Grv是从用户v开始执行广度优先搜索(BFS)。
但是,对于不同的用户,Grv可能有不同的尺寸。同时,由于社交网络的小世界特性,Grv的大小(关于顶点的数量)可能非常大[50]。这种大小不一的数据不适合大多数深度学习模型。为了解决这些问题,我们从v的r-ego网络中抽取一个固定大小的子网络,而不是直接处理r-ego网络。
抽样方法的一个自然选择是执行随机游走和重新启动(RWR)[45]。受[2,46]的启发,人们更容易受到活跃邻居的影响,而不是不活跃的邻居,我们从自我用户v或她的一个活跃邻居随机开始随机行走。接下来,随机游动以与每条边的权重成比例的概率迭代地移动到它的邻域。此外,在每一步中,该行走被赋予一个返回起始节点的概率,即要么是ego用户v,要么是v的活动邻居之一。

3.2 Neural Network Model
通过对每个用户检索到的“Grv”和“Stv”,我们设计了一个有效的神经网络模型,将“Grv”中的结构特性和“Stv”中的动作状态结合起来。
神经网络模型的输出是ego-userv的隐式表示,然后用它来预测她的行为状态st+∆tv。如图2所示该神经网络模型由一个网络嵌入层、一个实例规范化层、一个输入层、几个图卷积层或图注意力层和一个输出层组成。在本节中,我们将逐一介绍这些层并逐步构建模型。

图2:DeepInf的模型框架。(a) 原始输入由一小批B实例组成;每个实例是由n个用户组成的子网,这些用户使用随机游走和重新启动进行抽样,如第3.1节所述。在这个例子中,我们继续关注ego用户v(标记为蓝色)和她的一个活动邻居u(标记为橙色)。(b) 每个嵌入层都映射到一个维用户表示层。对于每个实例,该层根据等式3规范化用户的嵌入xu。在每个实例中嵌入yu的输出具有零均值和单位方差。(d) 将网络嵌入连接在一起的正式输入层,两个虚拟特征(一个表示用户是否活跃,另一个表示用户是否是ego)和其他定制的顶点特征(如表2所示)。(e) GCN或GAT层。avv和 avu分别表示沿自环(v,v)和边(v,u)的注意系数;根据GCN和GAT之间的选择,这些注意系数的值可以在式5和式7之间选择。(f)(g) 比较模型输出与地面真实情况,得到负对数似然损失。在本例中,ego userv最终被激活(标记为黑色)
当然,我们为了让用户更加便捷,我们增加了图片拖拽功能。
嵌入层
随着最近出现的表征学习[5],网络嵌入技术得到了广泛的研究,以发现和编码网络的结构属性到一个低维的潜在空间。更正式地说,网络嵌入学习一个嵌入矩阵X∈RD×| V |,每个列对应于网络G中一个顶点(用户)的表示。在所提出的模型中,我们使用一个预先训练的嵌入层,将用户u映射到她的D维表示xu∈RD,如图2(b)所示。
实例规范化[47]
实例规范化是最近提出的图像样式传输技术[47]。我们在我们的社会影响预测任务中采用了这种技术。如图2(c)所示,对于每个用户u∈Γr v,在从嵌入层检索到她的表示xU后,实例规范化Yu由

这里,µd和σd是均值和方差,而ϵ是数值稳定性的一个小数字。直观地说,这种规范化可以消除实例特定的均值和方差,这鼓励下游模型关注用户在潜在嵌入空间中的相对位置,而不是他们的绝对位置。正如我们将在第5节后面看到的,实例规范化可以帮助避免在培训期间过度拟合。
输入层
如图2(d)所示,输入层为每个用户构造一个特征向量。除了规范化低维嵌入来自上游实例规范化层外,它还考虑了两个二进制变量。第一个变量表示用户的操作状态,另一个变量表示用户是否是ego用户。此外,输入层还覆盖了所有其他定制的顶点特征,如结构特征、内容特征和人口统计特征。
基于GCN[25]的网络编码
图卷积网络(GCN)是一种针对图结构数据的半监督学习算法。GCN模型是由多个GCN层叠加而成的。每个GCN层的输入是一个顶点特征矩阵,H∈Rn×F,其中n是顶点数,F是特征数。


除最后一层的平均运算符之外,我们将每个单头注意力的输出连接起来以聚合。
输出层和损失函数
该层(见图2(f))为每个用户输出一个二维表示,我们将ego用户的表示与实际情况进行比较,然后优化对数似然损失,如等式2所述。
小批量学习
当从r-ego网络采样时,我们强制采样的子网络具有一个固定的大小n。得益于这种同质性,我们可以在这里应用小批量学习来进行有效的训练。如图2(a)所示,在每次迭代中,我们首先随机抽取B实例作为一个小批量。然后我们对我们的模型进行了优化。这种方法比全批学习速度快得多,而且在优化过程中仍然引入了足够多的噪声。
4 实验装置
我们用大量的真实世界数据集进行实验,以定量评估所提出的DeepInf框架。
4.1数据集
我们的实验在四个不同领域的社交网络上进行——OAG、Digg、Twitter和微博。表1列出了这四个数据集的统计数据。

OAGOAG(开放学术图)数据集是通过链接两个大型学术图生成的:Microsoft学术图[15]和AMiner[44]。与[13]中的处理方法类似,我们从数据挖掘、信息检索、机器学习、自然语言处理、计算机视觉和数据库研究社区5中选择了20个热门会议。社会网络被定义为合著者网络,社会行为被定义为引文行为——一位研究人员引用了上述会议上的一篇论文。我们感兴趣的是一个人的引文行为是如何受到她的合作者的影响。
Digg是一个新闻聚合器,它允许人们对网络内容进行投票,也就是说,新闻报道,向上或向下。这个数据集包含了2009年一个月内被提升到Digg首页的故事的数据。对于每个故事,它包含到数据收集时为止投票给这个故事的所有Digg用户的列表以及每个投票的时间戳。选民的友谊纽带也被恢复了。
Twitter数据集是在2012年7月4日宣布发现一种具有难以捉摸的希格斯玻色子特征的新粒子之前、期间和之后,在Twitter上监测传播过程后建立的。社交网络被定义为Twitter友谊网络,社交行为被定义为用户是否转发与“Higgs”相关的tweet。
微博是中国最受欢迎的微博服务。数据集来自[53],可在此处下载。7完整数据集包含2012年9月28日至2012年10月29日期间1776950名用户的定向跟踪网络和推文(发布日志)。社交行为被定义为微博中的转发行为——用户转发(转发)一条帖子(微博)。
数据准备
我们处理上述四个数据集现有工作的实践[53,54]。更具体地说,对于一个用户v在某个时间戳t被影响执行一个社交行为a,我们生成一个正实例。接下来,对于受影响的userv的每个邻居,如果在我们的观察窗口中从未观察到她是活动的,我们将创建一个负实例。我们的目标是区分积极和消极的例子。然而,所获得的数据集在两个方面面临数据不平衡问题。首先是活跃邻居的数量。正如张等人观察到的那样。[54],当自我使用者拥有相对较多的活跃邻居时,结构特征与社会影响区域显著相关。然而,在大多数社会影响的数据集中,活动邻居的数量是不平衡的。例如,在微博中,80%左右的实例只有一个活动邻居,邻居数≥3个的实例仅占8.57%。因此,当我们在这种不平衡的数据集上训练我们的模型时,该模型将被几乎没有活动邻居的观测所控制。为了解决不平衡问题,并显示我们的模型在捕捉局部
结构信息方面的优越性,我们过滤掉具有少数活跃邻域的观测值。特别是,在每个数据集中,我们只考虑ego用户有≥3个活动邻居的实例。第二个问题来自标签不平衡。例如,在微博数据集中,正负实例的比率约为300:1。为了解决这个问题,我们选取了一个更为平衡的数据集,正负比率为3:1。
4.2评估指标
为了定量评估我们的框架,我们使用以下性能指标:预测性能我们根据曲线下面积(AUC)[8]、精度(Prec.)、召回率(Rec.)和F1度量(F1)来评估DeepInf的预测性能。
参数敏感性我们分析了模型中的几个超参数,并测试了不同的超参数选择对预测性能的影响。案例研究我们使用案例研究来进一步证明和解释我们提出的框架的有效性。
4.3比较方法
我们将DeepInf与多个基线进行比较。
Logistic回归(LR)我们使用Logistic回归(LR)来训练一个分类模型。
该模型考虑了三类特征:(1)面向ego用户的顶点特征;(2)面向ego用户的预训练网络嵌入(DeepWalk[36]);(3)手工制作的ego网络特征。表2中列出了我们使用的特性。
支持向量机(SVM)[17]我们还使用线性核的支持向量机(SVM)作为分类模型。该模型使用了与logistic回归(LR)相同的特征。
PSCN[34]当我们将社会影响位置预测建模为一个图分类问题时,我们将我们的框架与最先进的图分类模型PSCN[34]进行了比较。对于每个图,PSCN根据用户定义的排序函数,例如度和中间度中心度来选择sw顶点。然后对每个选定的顶点,按照广度优先的搜索顺序组合其前k近邻。对于每个图,上面的过程构造了一个带有F通道的纵向×k的顶点序列,其中F是每个顶点的特征数。最后,PSCN在其上应用了一维卷积层。

DeepInf及其变体
我们实现了DeepInf的两个变体,分别用DeepInf GCN和DeepInf GAT表示。DeepInfGCN使用图形卷积层作为框架的构建块,即在等式5中设置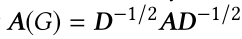
DeepInf GAT使用图形注意力,如公式7所示。然而,DeepInf和PSCN都只接受顶点级特性。由于这一局限性,我们没有在这两个模型中使用ego网络特性。相反,我们希望DeepInf能够自动发现ego网络特征和其他预测信号。
超参数设置与实现细节对于我们的框架DeepInf,我们首先执行随机游走,重启概率为0.8,采样子网的大小设置为50。对于嵌入层,使用DeepWalk对64维网络嵌入进行预训练[36]。然后我们选择使用三层GCN或GAT结构进行DeepInf,第一层和第二层GCN/GAT层都包含128个隐藏单元,而第三层(输出层)包含2个隐藏单元用于二进制预测。特别是对于具有多头图注意力的DeepInf,第一层和第二层都由K=8个注意头组成,每层计算16个隐藏单元(总共8×16=128个隐藏单元)。对于详细的模型配置,我们采用指数线性单位(ELU)[11]作为非线性(公式5中的函数g)。所有参数都用Glorot初始化[18]初始化,并使用Adagrad[16]优化器进行训练,学习率为0.1(Digg数据集为0.05),权重衰减5e−4(Digg数据集为1e−3),丢失率为0.2。我们分别使用75%、12.5%、12.5%的实例进行培训、验证和测试;所有数据集的最小批大小设置为1024个。
对于PSCN,在我们的实验中,我们发现推荐的中间性中心度排序函数并不能很好地预测社会影响力。我们转而使用宽度优先的搜索顺序从自我用户开始作为排名函数。当BFS的顺序不唯一时,我们通过先对活跃用户进行排名来打破联系。我们通过验证选择w=16和k=5,然后应用两个一维卷积层。第一个conv层有16个输出通道,步长为5,内核大小为5。第二个conv层有8个输出通道,步长为1,内核大小为1。第二层的输出然后被送入一个完全连接的层来预测标签。最后,我们允许PSCN和DeepInf在训练数据上运行最多500个周期,并通过在验证集上提前停止损失来选择最佳模型。我们发布了在这项工作中使用的PSCN和DeepInf的代码https://github.com/xptree/DeepInf都是用PyTorch实现的。
5 实验结果
我们比较了表3中四个数据集中所有方法的预测性能,并在表4中列出了相对性能增益,其中增益超过了最近的基线。此外,我们比较了DeepInf的变体,并在表5中列出了结果。我们有一些有趣的观察结果和见解。


(1)如图3所示,DeepInf GAT在AUC和F1方面都取得了显著的优于基线的性能,证明了我们提出的框架的有效性。在OAG和Digg中,DeepInf GAT发现了社会影响局部性的隐藏机制和动态,为我们提供了3.8%的相对性能增益w.r.t.AUC。

(2)对于PSCN,它根据用户定义的排序函数选择一个子集的顶点。如第4节所述,我们建议使用基于BFS顺序的排序函数,而不是使用中间性中心性。这种排序函数可以看作是一种预先定义的图注意机制,在这种机制中,ego用户更关注其活动邻居。PSCN的性能优于LR和SVM等线性预测因子,但其性能不如DeepInf GAT。
(3)一个有趣的观察结果是DeepInf GCN的劣势,如表5所示。以前,我们已经看到了GCN在五月标签分类任务中的成功[25]。然而,在这种应用中,DeepInf-GCN在所有方法中性能最差。我们把它的劣势归结于GCN的同伦假设,相似的顶点比不相似的顶点更容易相互连接。在这样的假设下,对于一个特定的顶点,GCN通过取其邻域表示的未加权平均值来计算其隐藏表示。然而,在我们的应用中,同源性假设可能不成立。通过对邻域进行平均,GCN可以将预测信号与噪声混合。另一方面,正如[2,46]所指出的,活跃邻居比不活跃邻居更重要,这也鼓励我们使用图注意力来区别对待邻居。
(4) 在表3、4和5所示的实验中,我们仍然依赖于几个顶点特征,例如页面排名得分和聚类系数。然而,我们希望避免使用任何手工制作的功能,并使DeepInf成为一个“纯”的端到端学习框架。非常令人惊讶的是,我们仍然可以获得相当的性能(如表6所示),即使我们不考虑任何手工制作的特性,除了预先训练好的网络嵌入。
5.1参数分析
在这一部分中,我们研究了在近邻采样和神经网络模型中,预测性能如何随超参数的变化而变化。除非另有说明,我们对微博数据集进行参数分析。随机游动随机游动的返回概率当对近邻抽样时,随机游动重新启动的返回概率(RWR)控制着被抽样r-ego网络的形状。

图3(a)显示了通过将返回概率从10%变化到90%的预测性能(根据AUC和F1)。随着回归概率的增加,预测性能也略有提高,说明了社会影响的地域性格局。采样网络的大小控制采样r-ego网络的另一个参数是采样网络的大小。图3(b)显示了从10到100的大小变化的预测性能(根据AUC和F1)。当我们选取更多的近邻样本时,我们可以观察到预测性能的缓慢提高。这并不令人惊讶,因为随着采样网络规模的增加,我们获得了更多的信息。
负正比率
如我们在第5.节中所述。在我们的数据集中,正观测和负观测是不平衡的。为了研究这种不平衡如何影响预测性能,我们将正负实例之间的比率从1改为10,并在图3(c)中显示性能。我们可以观察到F1测量值的下降趋势,而AUC评分保持稳定。#我们分析的另一个超参数是用于多头部注意力的头部数量。为了公平比较,我们将隐藏单元的总数固定为128个。我们将头的数目改为1、2、4、8、16、32、64、128,即每个头分别有128、64、32、16、8、4、2、1个隐藏单元。如图3(d)所示,我们可以看到DeepInf从多头机制中获益。然而,随着与每个头部相关联的隐藏单元数目的减少,预测性能降低。实例规范化的效果如第3节所述,我们使用实例规范化(in)层来避免过度拟合,特别是当训练集很小时,例如Digg。图4(a)和图4(b)说明了DeepInf GAT在Digg数据集上的训练损失和测试AUC。我们可以看到,IN显著地避免了过度拟合,使训练过程更加健壮。

5.2关于GAT的讨论和案例研究
除了GAT中使用的基于连接的注意(公式7),我们还尝试了其他流行的注意机制,如[28]中总结的点积注意或双线性注意。然而,这些注意机制的表现不如基于连接的机制。在这一节中,我们介绍GAT[49]的保序性。基于这一特性,我们试图通过案例分析来解释DeepInf GAT的有效性。
观察1.图注意的保序性
假设(i,j),(i,k),(i′,j)和(i′,k)是边或自环,并且ai j,aik,ai′j,ai′k是与它们相关的注意系数。如果ai j>aik,则ai′j>ai′k。
证明。如等式7所述,边缘(或自循环)(i,j)的图形注意系数定义为ai j=softmax(ei j),其中ei j=LeakyReLU(c⊤[W hi | W hj])。如果我们重写c⊤=[p⊤q⊤],我们得到ei j=LeakyReLU(p⊤W hi+q⊤W hj)。由于softmax和LeakyReLU的严格单调性,ai j>aikimplies q⊤W hj>q⊤W hk。再次应用LeakyReLU和softmax的严格单调性,得到ai′j>ai′k。
上述观察结果表明,尽管每个顶点只关注其在GAT(local attention)中的邻域,但注意系数有一个全局排序,仅由q⊤Whj决定。因此,我们可以定义一个分数函数score(j)=q⊤W hj。然后每个顶点根据这个得分函数对其邻域进行关注,得分函数值越高,表示关注系数越高。因此,绘制评分函数的值可以说明网络的“流行区域”或“重要区域”在哪里。此外,多头部注意为K个头部提供了一个多视角机制,我们有K个得分函数,得分K(j)=q⊤kWkhj,K=1,···,K,突出网络的不同区域。为了更好地说明这种机制,我们进行了一些案例研究。如图5所示,我们从Digg数据集(每行对应一个实例)中选择四个实例,从第一个GAT层中选择三个具有代表性的注意头。有趣的是,我们可以观察到不同的注意头所发现的可解释的和异质的模式。例如,如图5所示,第一个注意力集中在ego用户上,而第二个和第三个注意力头分别突出显示活动用户和非活动用户。然而,这个属性不适用于其他注意机制。由于页数限制,我们不在这里讨论。
6. 相关工作
我们的研究与社会影响分析[42]和图形表征学习[22,37]的大量文献密切相关。社会影响分析大多数现有的工作都集中在社会影响建模为一个宏观的社会过程(又名级联),少数研究者探索了另一种用户层面的机制,在实践中考虑了社会影响的局部性。在宏观层面,研究人员对全球社会影响模式感兴趣。这种全局模式包括级联的各个方面及其与最终级联大小的相关性,例如上升和下降模式[32]、外部影响源[33]和整合现象[43]。最近,人们致力于使用深度学习自动检测这些全局模式,例如DeepCas模型[26]将级联预测作为一个序列问题,并用递归神经网络来解决。

图5:案例研究。不同的图形注意力头如何突出网络的不同区域。(a) 从Digg数据集中选择了四个案例。活动用户和非活动用户分别标记为黑色和灰色。用户v是我们感兴趣的自我用户。(b) (c)(d)三名具有代表性的attention heads。
另一类研究集中于社会影响中的用户级机制,即每个用户只受其近邻的影响。这类工作的例子包括成对影响[19,39]、话题层面影响[42]、群体形成[2,38]和结构多样性[14,29,46]。这种用户级模型是许多现实问题和应用程序的基本构建块。例如,在影响最大化问题[24]中,独立级联模型和线性阈值模型都假设了一个成对的影响模型;在社交推荐[30]中,一个关键假设是社会影响现有用户的评分和评论会通过社交互动影响未来客户的决策。
另一个例子是Facebook-Bond等人的一个大规模实地实验。[7] 在2010年美国国会选举期间,结果显示了网络社会影响如何改变线下投票行为。图表示学习表征学习一直是研究界的热点。在图挖掘的背景下,对图表示学习进行了大量的研究。一系列的研究集中在顶点(节点)嵌入,即学习每个顶点的低维潜在因子。例如DeepWalk[36]、LINE[41]、node2vec[20]、metapath2vec[13]、NetMF[37]等。另一类研究关注图的表示,即学习图的子结构的潜在表示,包括图核[40]、深图核[52]和最新方法PSCN[34]。近年来,有人尝试将半监督信息引入图表示学习中。典型的例子包括GCN[25]、GraphSAGE[21]和最先进的GAT模型[49]。
7. 结论
在这项工作中,我们研究了社会影响局部性问题。我们从深度学习的角度来阐述这个问题,并结合最近发展的网络嵌入、图卷积和自我注意技术,提出了一个基于图的学习框架DeepInf。我们在四个社交和信息网络OAG、Digg、Twitter和Weibo上测试了该框架。我们广泛的实验分析表明,DeepInf在预测社会影响区域方面明显优于具有丰富手工工艺特征的基线。本文探讨了网络表征学习在社会影响分析中的潜力,并首次尝试解释社会影响的动态性。提出的DeepInf背后的一般思想可以扩展到许多网络挖掘任务。我们的DeepInf可以有效和高效地总结网络中的一个局域网。这些总结出来的表示可以应用到各种下游应用中,如链路预测、相似性搜索、网络对齐等,因此,我们希望对未来的工作进行探索。另一个令人兴奋的方向是对近邻进行抽样调查。在这项工作中,我们在不考虑任何边信息的情况下执行重新启动随机行走。同时,采样过程与神经网络模型松散耦合。通过利用强化学习,将取样和学习结合在一起也是令人兴奋的。
REFERENCES
[1] Lada A Adamic and Eytan Adar. 2003. Friends and neighbors on the web. Social networks 25, 3 (2003), 211–230.
[2] Lars Backstrom, Dan Huttenlocher, Jon Kleinberg, and Xiangyang Lan. 2006.
Group formation in large social networks: membership, growth, and evolution. In KDD ’06. ACM, 44–54.
[3] Eytan Bakshy, Dean Eckles, Rong Yan, and Itamar Rosenn. 2012. Social influence in social advertising: evidence from field experiments. In EC ’12. ACM, 146–161.
[4] Vladimir Batagelj and Matjaz Zaversnik. 2003. An O(m) algorithm for cores decomposition of networks. arXiv preprint cs/0310049 (2003).
[5] Yoshua Bengio, Aaron Courville, and Pascal Vincent. 2013. Representation learning: A review and new perspectives. IEEE transactions on pattern analysis and machine intelligence 35, 8 (2013), 1798–1828.
[6] Phillip Bonacich. 1987. Power and centrality: A family of measures. American journal of sociology 92, 5 (1987), 1170–1182.
[7] Robert M Bond, Christopher J Fariss, Jason J Jones, Adam DI Kramer, Cameron
Marlow, Jaime E Settle, and James H Fowler. 2012. A 61-million-person experiment in social influence and political mobilization. Nature 489, 7415 (2012),295.
[8] Chris Buckley and Ellen M Voorhees. 2004. Retrieval evaluation with incomplete information. In SIGIR ’04. ACM, 25–32.
[9] Soumen Chakrabati, B Dom, D Gibson, J Kleinberg, S Kumar, P Raghavan, S Rajagopalan, and A Tomkins. 1999. Mining the link structure of the World Wide Web. IEEE Computer 32, 8 (1999), 60–67.
[10] Fan RK Chung. 1997. Spectral graph theory. Number 92. American Mathematical Soc.
[11] Djork-Arné Clevert, Thomas Unterthiner, and Sepp Hochreiter. 2015. Fast and ccurate deep network learning by exponential linear units (elus). arXiv preprint arXiv:1511.07289 (2015).
[12] Manlio De Domenico, Antonio Lima, Paul Mougel, and Mirco Musolesi. 2013.
The anatomy of a scientific rumor. Scientific reports 3 (2013), 2980.
[13] Yuxiao Dong, Nitesh V Chawla, and Ananthram Swami. 2017. metapath2vec: Scalable Representation Learning for Heterogeneous Networks. InKDD ’17. ACM, 135–144.
[14] Yuxiao Dong, Reid A Johnson, Jian Xu, and Nitesh V Chawla. 2017. Structural
Diversity and Homophily: A Study Across More Than One Hundred Big Networks. In KDD ’17. ACM, 807–816.
[15] Yuxiao Dong, Hao Ma, Zhihong Shen, and Kuansan Wang. 2017. A Century of Science: Globalization of Scientific Collaborations, Citations, and Innovations. In KDD ’17. ACM, 1437–1446.
[16] John Duchi, Elad Hazan, and Yoram Singer. 2011. Adaptive subgradient methods for online learning and stochastic optimization. JMLR 12, Jul (2011), 2121–2159.
[17] Rong-En Fan, Kai-Wei Chang, Cho-Jui Hsieh, Xiang-Rui Wang, and Chih-Jen Lin. 2008. LIBLINEAR: A library for large linear classification. JMLR 9, Aug (2008), 1871–1874.
[18] Xavier Glorot and Yoshua Bengio. 2010. Understanding the difficulty of training deep feedforward neural networks. In AISTATS ’10. 249–256.
[19] Amit Goyal, Francesco Bonchi, and Laks VS Lakshmanan. 2010. Learning influence probabilities in social networks. In WSDM ’10. ACM, 241–250.
[20] Aditya Grover and Jure Leskovec. 2016. node2vec: Scalable feature learning for networks. In KDD ’16. ACM, 855–864.
[21] Will Hamilton, Zhitao Ying, and Jure Leskovec. 2017. Inductive representation
learning on large graphs. In NIPS ’17. 1025–1035.
[22] William L Hamilton, Rex Ying, and Jure Leskovec. 2017. Representation Learning on Graphs: Methods and Applications. arXiv preprint arXiv:1709.05584 (2017).
[23] Tad Hogg and Kristina Lerman. 2012. Social dynamics of digg. EPJ Data Science 1, 1 (2012), 5.
[24] David Kempe, Jon Kleinberg, and Éva Tardos. 2003. Maximizing the spread of influence through a social network. In KDD ’03. 137–146.
[25] Thomas N Kipf and Max Welling. 2017. Semi-supervised classification with graph convolutional networks. ICLR ’17 (2017).
[26] Cheng Li, Jiaqi Ma, Xiaoxiao Guo, and Qiaozhu Mei. 2017. DeepCas: An end-to-end predictor of information cascades. In WWW ’17. 577–586.
[27] Huijie Lin, Jia Jia, Jiezhong Qiu, Yongfeng Zhang, Guangyao Shen, Lexing Xie, Jie Tang, Ling Feng, and Tat-Seng Chua. 2017. Detecting stress based on social interactions in social networks. TKDE 29, 9 (2017), 1820–1833.
[28] Minh-Thang Luong, Hieu Pham, and Christopher D Manning. 2015. Effective approaches to attention-based neural machine translation. EMNLP ’15 (2015).
[29] Hao Ma. 2013. An experimental study on implicit social recommendation. In SIGIR ’13. ACM, 73–82.
[30] Hao Ma, Irwin King, and Michael R Lyu. 2009. Learning to recommend with social trust ensemble. In SIGIR ’09. ACM, 203–210.
[31] Andrew L Maas, Awni Y Hannun, and Andrew Y Ng. 2013. Rectifier nonlinearities improve neural network acoustic models. In ICML ’13. 3.
[32] Yasuko Matsubara, Yasushi Sakurai, B Aditya Prakash, Lei Li, and Christos Faloutsos. 2012. Rise and fall patterns of information diffusion: model and implications.
In KDD ’12. 6–14.
[33] Seth A Myers, Chenguang Zhu, and Jure Leskovec. 2012. Information diffusion and external influence in networks. In KDD ’12. ACM, 33–41.
[34] Mathias Niepert, Mohamed Ahmed, and Konstantin Kutzkov. 2016. Learning convolutional neural networks for graphs. In ICML ’16. 2014–2023.
[35] Lawrence Page, Sergey Brin, Rajeev Motwani, and Terry Winograd. 1999. The PageRank citation ranking: Bringing order to the web. Technical Report. Stanford InfoLab.
[36] Bryan Perozzi, Rami Al-Rfou, and Steven Skiena. 2014. Deepwalk: Online learning of social representations. In KDD ’14. ACM, 701–710.
[37] Jiezhong Qiu, Yuxiao Dong, Hao Ma, Jian Li, Kuansan Wang, and Jie Tang. 2018.
Network Embedding as Matrix Factorization: Unifying DeepWalk, LINE, PTE, and node2vec. In WSDM ’18. ACM, 459–467.
[38] Jiezhong Qiu, Yixuan Li, Jie Tang, Zheng Lu, Hao Ye, Bo Chen, Qiang Yang, and John E Hopcroft. 2016. The lifecycle and cascade of wechat social messaging groups. In WWW ’16. 311–320.
[39] Kazumi Saito, Ryohei Nakano, and Masahiro Kimura. 2008. Prediction of information diffusion probabilities for independent cascade model. In KES ’08. Springer, 67–75.
[40] Nino Shervashidze, SVN Vishwanathan, Tobias Petri, Kurt Mehlhorn, and Karsten Borgwardt. 2009. Efficient graphlet kernels for large graph comparison. In AISTATS’ 09. 488–495.
[41] Jian Tang, Meng Qu, Mingzhe Wang, Ming Zhang, Jun Yan, and Qiaozhu Mei. 2015. LINE: Large-scale information network embedding. In WWW ’15. 1067–1077.
[42] Jie Tang, Jimeng Sun, Chi Wang, and Zi Yang. 2009. Social influence analysis in large-scale networks. In KDD ’09. ACM, 807–816.
[43] Jie Tang, Sen Wu, and Jimeng Sun. 2013. Confluence: Conformity influence in large social networks. In KDD ’13. ACM, 347–355.
[44] Jie Tang, Jing Zhang, Limin Yao, Juanzi Li, Li Zhang, and Zhong Su. 2008. Arnetminer: extraction and mining of academic social networks. In KDD ’08. 990–998.
[45] Hanghang Tong, Christos Faloutsos, and Jia-Yu Pan. 2006. Fast Random Walk with Restart and Its Applications. In ICDM ’06. 613–622.
[46] Johan Ugander, Lars Backstrom, Cameron Marlow, and Jon Kleinberg. 2012.
Structural diversity in social contagion. PNAS 109, 16 (2012), 5962–5966.
[47] Dmitry Ulyanov, Vedaldi Andrea, and Victor Lempitsky. 2016. Instance Normalization: The Missing Ingredient for Fast Stylization. arXiv preprint arXiv:1607.08022 (2016).
[48] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In NIPS ’17. 6000–6010.
[49] Petar Velickovic, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Y Bengio. 2018. Graph Attention Networks. ICLR ’18 (2018).
[50] Duncan J Watts and Steven H Strogatz. 1998. Collective dynamics of ’small-world’ networks. nature 393, 6684 (1998), 440–442.
[51] Bing Xu, Naiyan Wang, Tianqi Chen, and Mu Li. 2015. Empirical evaluation of rectified activations in convolutional network. arXiv preprint arXiv:1505.00853 (2015).
[52] Pinar Yanardag and SVN Vishwanathan. 2015. Deep graph kernels. In KDD ’15. 1365–1374.
[53] Jing Zhang, Biao Liu, Jie Tang, Ting Chen, and Juanzi Li. 2013. Social Influence Locality for Modeling Retweeting Behaviors… In IJCAI’ 13.
[54] Jing Zhang, Jie Tang, Juanzi Li, Yang Liu, and Chunxiao Xing. 2015. Who influenced you? predicting retweet via social influence locality. TKDD 9, 3 (2015), 25.




