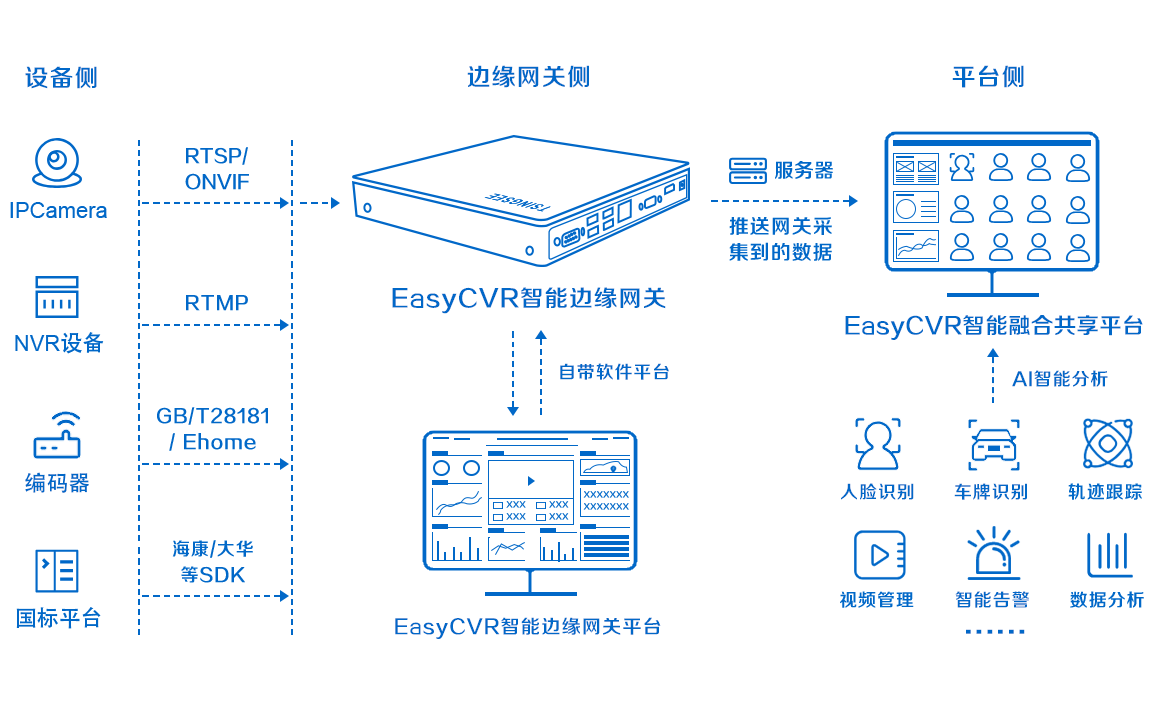
一、项目简介
汽车的日益普及在给人们带来极大便利的同时,也导致了拥堵的交通路况,以及更为频发的交通事故。智能交通技术已成为推动现代技术交通技术发展的重要力量,智能交通不仅能够提供实时的交通路况信息,帮助交通管理者规划管理策略,而且还能优化出行者的出行策略。还可以减轻交通道路的堵塞情况,降低交通事故的发生概率,提高道路运行的安全系数。
本项目分两个模块:
-
一个是基于视频的车辆跟踪及流量统计,是一个可跟踪路面实时车辆通行状况,并逐帧记录不同行车道车流量数目的深度学习项目,在视频中可看出每个车辆的连续帧路径,该项目可拓展性强,可根据企业业务外接计费结算系统、LED显示系统、语音播报系统、供电防雷系统等,
-
另一个是车道线检测项目,是实现自动驾驶的首要任务,广泛应用于自动驾驶厂家,能够根据车载摄像头的输入,对安全驾驶区域进行预判,提醒驾驶员进行安全驾驶,减少交通事故的发生。
该项目的架构图如下所示:
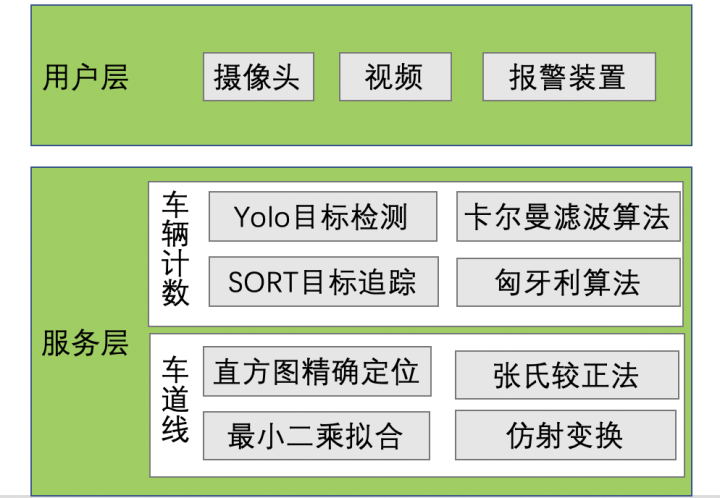
-
用户层:通过摄像头或人工选择视频送入服务层中进行处理,处理完成后可输出经渲染后的视频,或触发报警装置
-
服务层:主要包含两个模块,
-
一是车辆追踪及计数,该模块模块一对输入的视频进行处理,使用yoloV3模型进行目标检测,然后使用SORT进行目标追踪,使用卡尔曼滤波器进行目标位置预测,并利用匈牙利算法对比目标的相似度,完成车辆目标追踪,利用虚拟线圈的思想实现车辆目标的计数,并根据计数完成车道拥堵的判断;
-
另一个是车道线的检测,该模块使用张氏较正法对相机进行较正,利用较正结果对图像去畸变,然后利用边缘与颜色提取车道线,利用仿射变换转换成鸟瞰图,并利用直方图和滑动窗口的算法精确定位车道线,利用最小二乘法进行拟合,实现车道线的检测,并计算车辆偏离车道中心的距离,触发报警装置。
环境安装
该项目中使用的工具包包含以下:
NumPy 是使用 Python 进行科学计算的基础包。
Numba 是一个开源 JIT 编译器,它将 Python 和 NumPy 代码的子集转换为快速机器码。
SciPy 是数学、科学和工程的开源软件。SciPy 库依赖于 NumPy,它提供方便快捷的 N 维数组操作。
h5py 从 Python 读取和写入 HDF5文件。
pandas 用于数据分析、时间序列和统计的强大的数据结构。
opencv-python 用于 Python 的预构建 OpenCV 包。
moviepy 用于进行视频处理的工具包
Filterpy 实现了卡尔曼滤波器和粒子滤波器等
具体版本见requirements文件中。
安装方法:
# 创建虚拟环境 conda create -n dlcv python # 激活虚拟环境 source activate dlcv # 安装对应的工具包 pip install -r requirements.txt
二、算法库
(一)numba
(1)numba介绍
numba是一个用于编译Python数组和数值计算函数的编译器,这个编译器能够大幅提高直接使用Python编写的函数的运算速度。
numba使用LLVM编译器架构将纯Python代码生成优化过的机器码,通过一些添加简单的注解,将面向数组和使用大量数学的python代码优化到与c,c++和Fortran类似的性能,而无需改变Python的解释器。numba的编译方式如下图所示:
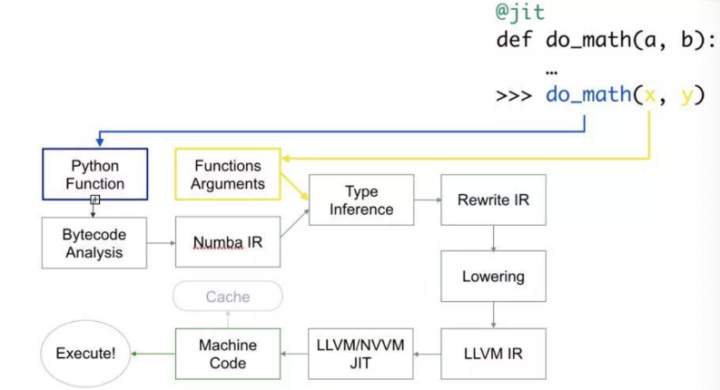
为什么选择numba?
虽然有 cython 和 Pypy 之类的许多其他编译器,选择Numbade 原因很简单,不必离开 python 代码的舒适区,不需要为了获得一些的加速来改变您的代码,我们只需要添加一个装饰器到Python函数中即可完成加速,而且加速效果与cython代码相当。
(2)numba的使用方法
numba对代码进行加速时,给要优化的函数加上@jit优化器即可。使用jit的时候可以让numba来决定什么时候以及怎么做优化。如下简单的例子所示:
from numba import jit @jit def f(x, y): return x + y
这段代码的计算在被调用是第一次执行,numba将在调用期间推断参数类型,然后基于这个信息生成优化后的代码。numba也能够基于输入的类型编译生成特定的代码。例如,对于上面的代码,传入整数和浮点数作为参数将会生成不同的代码:

Numba编译的函数可以调用其他编译函数。 例如:
@jit def hypot(x, y): return math.sqrt(square(x) + square(y))
我们现在看一个例子:
from numba import jit import time @jit def foo(): x = [] for a in range(100000000): x.append(a) def foo_withoutfit(): y = [] for b in range(100000000): y.append(b)
现在我们定义相同的方法,实现的功能也是一样的,一个是利用numba进行加速,一个没有加速,我们看下他们的运行时间:

从结果中可以看出,当我们使用了numba进行加速,速度提升了10倍以上。
(二)imutils
1.imutils功能简介
imutils是在OPenCV基础上的一个封装,达到更为简结的调用OPenCV接口的目的,它可以轻松的实现图像的平移,旋转,缩放,骨架化等一系列的操作。
安装方法:
pip install imutils
在安装前应确认已安装numpy,scipy,matplotlib和opencv。
2.imutils的使用方法
2.1 图像平移
OpenCV中也提供了图像平移的实现,要先计算平移矩阵,然后利用仿射变换实现平移,在imutils中可直接进行图像的平移。
translated = imutils.translate(img,x,y)
参数:
-
img:要移动的图像
-
x:沿x轴方向移动的像素个数
-
y: 沿y轴方向移动的像素个数

2.2 图像缩放
图片的缩放在OPenCV中要注意确保保持宽高比。而在imutils中自动保持原有图片的宽高比,只指定宽度weight和Height即可。
img = cv.imread("lion.jpeg") resized = imutils.resize(img,width=200) print("原图像大小: ", img.shape) print("缩放后大小:",resized.shape) plt.figure(figsize=[10, 10]) plt.subplot(1,2,1) plt.imshow(cv.cvtColor(img, cv.COLOR_BGR2RGB)) plt.title('原图') plt.axis("off") plt.subplot(1,2,2) plt.imshow(cv.cvtColor(resized, cv.COLOR_BGR2RGB)) plt.title('缩放结果') plt.axis("off") plt.show()
下图是对图像进行缩放后的结果:

2.3 图像旋转
在OpenCV中进行旋转时使用的是仿射变换,在这里图像旋转方法是imutils.rotate(),跟2个参数,第一个是图片数据,第二个是旋转的角度,旋转是朝逆时针方向。同时imutils还提供了另一个相似的方法, rotate_round(),它就是按顺时针旋转的。
import cv2 import imutils image = cv2.imread('lion.jpeg') rotated = imutils.rotate(image, 90) rotated_round = imutils.rotate_bound(image, 90) plt.figure(figsize=[10, 10]) plt.subplot(1,3,1) plt.imshow(img[:,:,::-1]) plt.title('原图') plt.axis("off") plt.subplot(1,3,2) plt.imshow(rotated[:,:,::-1]) plt.title('逆时针旋转90度') plt.axis("off") plt.subplot(1,3,3) plt.imshow(rotated_round[:,:,::-1]) plt.title('顺时针旋转90度') plt.axis("off") plt.show()
结果如下:

2.4 骨架提取
骨架提取,是指对图片中的物体进行拓扑骨架(topological skeleton)构建的过程。imutils提供的方法是skeletonize(),第二个参数是结构参数的尺寸(structuring element),相当于是一个粒度,越小需要处理的时间越长。
import cv2 import imutils # 1 图像读取 image = cv2.imread('lion.jpeg') # 2 灰度化 gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 3 骨架提取 skeleton = imutils.skeletonize(gray, size=(3, 3)) # 4 图像展示 plt.figure(figsize=(10,8),dpi=100) plt.subplot(121),plt.imshow(img[:,:,::-1]),plt.title('原图') plt.xticks([]), plt.yticks([]) plt.subplot(122),plt.imshow(skeleton,cmap="gray"),plt.title('骨架提取结果') plt.xticks([]), plt.yticks([]) plt.show()
效果如下:

2.5 Matplotlib显示
在OpenCV的Python绑定中,图像以BGR顺序表示为NumPy数组。使用该cv2.imshow功能时效果很好。但是,如果打算使用Matplotlib,该plt.imshow函数将假定图像按RGB顺序排列。调用cv2.cvtColor解决此问题,也可以使用opencv2matplotlib便捷功能。
img = cv.imread("lion.jpeg") plt.figure() plt.imshow(imutils.opencv2matplotlib(img))
2.5 OPenCV版本的检测
OpenCV 4发布之后,随着主要版本的更新,向后兼容性问题尤为突出。在使用OPenCV时,应检查当前正在使用哪个版本的OpenCV,然后使用适当的函数或方法。在imutils中的is_cv2()、is_cv3()和is_cv4()是可用于自动确定当前环境的OpenCV的版本简单的功能。
print("OPenCV版本: {}".format(cv2.__version__)) print("OPenCV是2.X? {}".format(imutils.is_cv2())) print("OPenCV是3.X? {}".format(imutils.is_cv3())) print("OPenCV是4.X? {}".format(imutils.is_cv4()))
输出是:

(三) cv.dnn
OPenCV自3.3版本开始,加入了对深度学习网络的支持,即DNN模块,它支持主流的深度学习框架生成与到处模型的加载。
1.DNN模块
1.1. 模块简介
OpenCV中的深度学习模块(DNN)只提供了推理功能,不涉及模型的训练,支持多种深度学习框架,比如TensorFlow,Caffe,Torch和Darknet。

OpenCV那为什么要实现深度学习模块?
-
轻量型。DNN模块只实现了推理功能,代码量及编译运行开销远小于其他深度学习模型框架。
-
使用方便。DNN模块提供了内建的CPU和GPU加速,无需依赖第三方库,若项目中之前使用了OpenCV,那么通过DNN模块可以很方便的为原项目添加深度学习的能力。
-
通用性。DNN模块支持多种网络模型格式,用户无需额外的进行网络模型的转换就可以直接使用,支持的网络结构涵盖了常用的目标分类,目标检测和图像分割的类别,如下图所示:

DNN模块支持多种类型网络层,基本涵盖常见的网络运算需求。

也支持多种运算设备(CPU,GPU等)和操作系统(Linux,windows,MacOS等)。
1.2.模块架构
DNN模块的架构如下图所示:
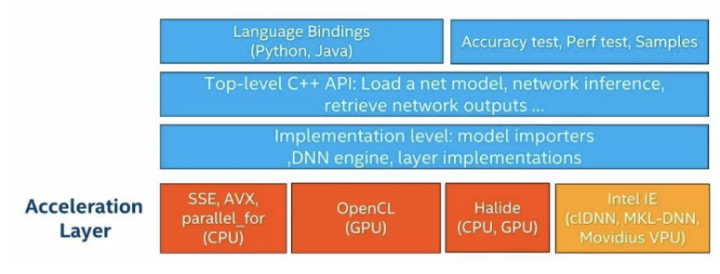
从上往下依次是:
-
第一层:语言绑定层,主要支持Python和Java,还包括准确度测试、性能测试和部分示例程序。
-
第二层:C++的API层,是原生的API,功能主要包括加载网络模型、推理运算以及获取网络的输出等。
-
第三层:实现层,包括模型转换器、DNN引擎以及层实现等。模型转换器将各种网络模型格式转换为DNN模块的内部表示,DNN引擎负责内部网络的组织和优化,层实现指各种层运算的实现过程。
-
第四层:加速层,包括CPU加速、GPU加速、Halide加速和Intel推理引擎加速。CPU加速用到了SSE和AVX指令以及大量的多线程元语,而OpenCL加速是针对GPU进行并行运算的加速。Halide是一个实验性的实现,并且性能一般。Intel推理引擎加速需要安装OpenVINO库,它可以实现在CPU、GPU和VPU上的加速,在GPU上内部会调用clDNN库来做GPU上的加速,在CPU上内部会调用MKL-DNN来做CPU加速,而Movidius主要是在VPU上使用的专用库来进行加速。
除了上述的加速方法外,DNN模块还有网络层面的优化。这种优化优化分两类,一类是层融合,还有一类是内存复用。
-
层融合 层融合通过对网络结构的分析,把多个层合并到一起,从而降低网络复杂度和减少运算量。

如上图所示,卷积层后面的BatchNorm层、Scale层和RelU层都被合并到了卷积层当中。这样一来,四个层运算最终变成了一个层运算。

如上图所示,网络结构将卷积层1和Eltwise Layer和RelU Layer合并成一个卷积层,将卷积层2作为第一个卷积层新增的一个输入。这样一来,原先的四个网络层变成了两个网络层运算。
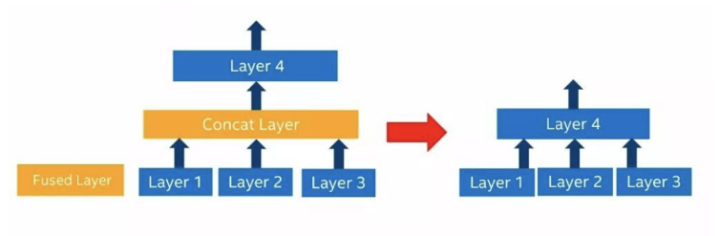
如上图所示,原始的网络结构把三个层的输出通过连接层连接之后输入到后续层,这种情况可以把中间的连接层直接去掉,将三个网络层输出直接接到第四层的输入上面,这种网络结构多出现SSD类型的网络架构当中。
-
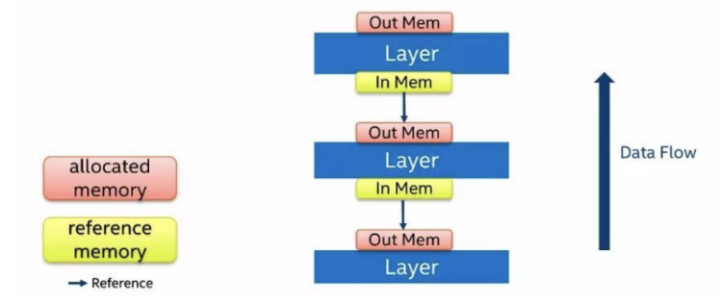
内存复用 深度神经网络运算过程当中会占用非常大量的内存资源,一部分是用来存储权重值,另一部分是用来存储中间层的运算结果。我们考虑到网络运算是一层一层按顺序进行的,因此后面的层可以复用前面的层分配的内存。 下图是一个没有经过优化的内存重用的运行时的存储结构,红色块代表的是分配出来的内存,绿色块代表的是一个引用内存,蓝色箭头代表的是引用方向。数据流是自下而上流动的,层的计算顺序也是自下而上进行运算。每一层都会分配自己的输出内存,这个输出被后续层引用为输入。
对内存复用也有两种方法:
第一种内存复用的方法是输入内存复用。
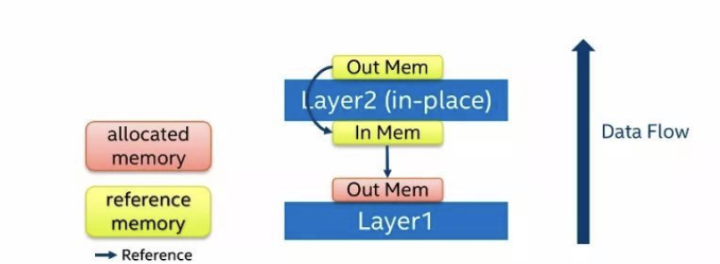
如上图所示,如果我们的层运算是一个in-place模式,那么我们无须为输出分配内存,直接把输出结果写到输入的内存当中即可。in-place模式指的是运算结果可以直接写回到输入而不影响其他位置的运算,如每个像素点做一次Scale的运算。类似于in-place模式的情况,就可以使用输入内存复用的方式。 第二种内存复用的方法是后续层复用前面层的输出。
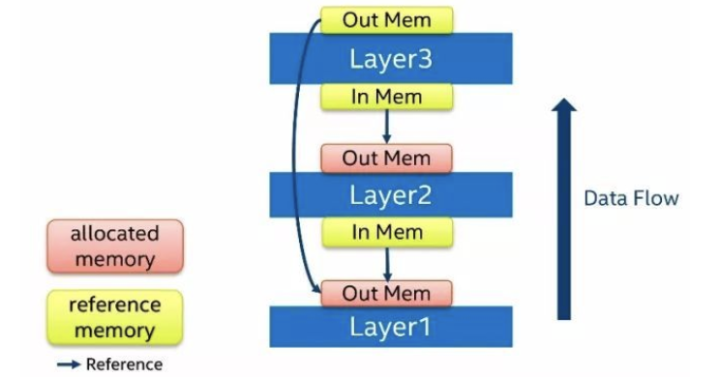
如上图所示,在这个例子中,Layer3在运算时,Layer1和Layer2已经完成了运算。此时,Layer1的输出内存已经空闲下来,因此,Layer3不需要再分配自己的内存,直接引用Layer1的输出内存即可。由于深度神经网络的层数可以非常多,这种复用情景会大量的出现,使用这种复用方式之后,网络运算的内存占用量会下降30%~70%。
2.常用方法简介
DNN模块有很多可直接调用的Python API接口,现将其介绍如下:
2.1.dnn.blobFromImage
作用:根据输入图像,创建维度N(图片的个数),通道数C,高H和宽W次序的blobs
原型:
blobFromImage(image, scalefactor=None, size=None, mean=None, swapRB=None, crop=None, ddepth=None):
参数:
-
image:cv2.imread 读取的图片数据
-
scalefactor: 缩放像素值,如 [0, 255] - [0, 1]
-
size: 输出blob(图像)的尺寸,如 (netInWidth, netInHeight)
-
mean: 从各通道减均值. 如果输入 image 为 BGR 次序,且swapRB=True,则通道次序为 (mean-R, mean-G, mean-B).
-
swapRB: 交换 3 通道图片的第一个和最后一个通道,如 BGR - RGB
-
crop: 图像尺寸 resize 后是否裁剪. 如果crop=True,则,输入图片的尺寸调整resize后,一个边对应与 size 的一个维度,而另一个边的值大于等于 size 的另一个维度;然后从 resize 后的图片中心进行 crop. 如果crop=False,则无需 crop,只需保持图片的长宽比
-
ddepth: 输出 blob 的 Depth. 可选: CV_32F 或 CV_8U
示例:
import cv2 from cv2 import dnn import numpy as np import matplotlib.pyplot as plt img_cv2 = cv2.imread("test.jpeg") print("原图像大小: ", img_cv2.shape) inWidth = 256 inHeight = 256 outBlob1 = cv2.dnn.blobFromImage(img_cv2, scalefactor=1.0 / 255, size=(inWidth, inHeight), mean=(0, 0, 0), swapRB=False, crop=False) print("未裁剪输出: ", outBlob1.shape) outimg1 = np.transpose(outBlob1[0], (1, 2, 0)) outBlob2 = cv2.dnn.blobFromImage(img_cv2, scalefactor=1.0 / 255, size=(inWidth, inHeight), mean=(0, 0, 0), swapRB=False, crop=True) print("裁剪输出: ", outBlob2.shape) outimg2 = np.transpose(outBlob2[0], (1, 2, 0)) plt.figure(figsize=[10, 10]) plt.subplot(1, 3, 1) plt.title('输入图像', fontsize=16) plt.imshow(cv2.cvtColor(img_cv2, cv2.COLOR_BGR2RGB)) plt.axis("off") plt.subplot(1, 3, 2) plt.title('输出图像 - 未裁剪', fontsize=16) plt.imshow(cv2.cvtColor(outimg1, cv2.COLOR_BGR2RGB)) plt.axis("off") plt.subplot(1, 3, 3) plt.title('输出图像 - 裁剪', fontsize=16) plt.imshow(cv2.cvtColor(outimg2, cv2.COLOR_BGR2RGB)) plt.axis("off") plt.show()
输出结果为:

另外一个API与上述API类似,是进行批量图片处理的,其原型如下所示:
blobFromImages(images, scalefactor=None, size=None, mean=None, swapRB=None, crop=None, ddepth=None):
作用:批量处理图片,创建4维的blob,其它参数类似于 dnn.blobFromImage。
2.2.dnn.NMSBoxes
作用:根据给定的检测boxes和对应的scores进行NMS(非极大值抑制)处理
原型:
NMSBoxes(bboxes, scores, score_threshold, nms_threshold, eta=None, top_k=None)
参数:
-
boxes: 待处理的边界框 bounding boxes
-
scores: 对于于待处理边界框的 scores
-
score_threshold: 用于过滤 boxes 的 score 阈值
-
nms_threshold: NMS 用到的阈值
-
indices: NMS 处理后所保留的边界框的索引值
-
eta: 自适应阈值公式中的相关系数:
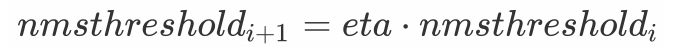
-
top_k: 如果 top_k>0,则保留最多 top_k 个边界框索引值.
2.3. dnn.readNet
作用:加载深度学习网络及其模型参数
原型:
readNet(model, config=None, framework=None)
参数:
-
model: 训练的权重参数的模型二值文件,支持的格式有:*.caffemodel(Caffe)、*.pb(TensorFlow)、*.t7 或 *.net(Torch)、 *.weights(Darknet)、*.bin(DLDT).
-
config: 包含网络配置的文本文件,支持的格式有:*.prototxt (Caffe)、*.pbtxt (TensorFlow)、*.cfg (Darknet)、*.xml (DLDT).
-
framework: 所支持格式的框架名
该函数自动检测训练模型所采用的深度框架,然后调用 readNetFromCaffe、readNetFromTensorflow、readNetFromTorch 或 readNetFromDarknet 中的某个函数完成深度学习网络模型及模型参数的加载。
下面我们看下对应于特定框架的API:
-
Caffe
readNetFromCaffe(prototxt, caffeModel=None)
作用:加载采用Caffe的配置网络和训练的权重参数
-
Darknet
readNetFromDarknet(cfgFile, darknetModel=None)
作用:加载采用Darknet的配置网络和训练的权重参数
Tensorflow
readNetFromTensorflow(model, config=None)
作用:加载采用Tensorflow 的配置网络和训练的权重参数 参数:
-
model: .pb 文件
-
config: .pbtxt 文件
Torch
readNetFromTorch(model, isBinary=None)
作用:加载采用 Torch 的配置网络和训练的权重参数 参数:
-
model: 采用 torch.save()函数保存的文件
ONNX
readNetFromONNX(onnxFile)
作用:加载 .onnx 模型网络配置参数和权重参数
三、车流量检测实现
(一)多目标追踪
1.多目标跟踪分类
多目标跟踪,即MOT(Multi-Object Tracking),也就是在一段视频中同时跟踪多个目标。MOT主要应用在安防监控和自动驾驶等领域中。

多目标跟踪可看做多变量估计问题,即给定一个图像序列,s^{i}_{t}sti表示第 t 帧第 i 个目标的状态,S_t=(s^{1}_{t},s^{2}_{t},...,s^{M}_{t})St=(st1,st2,...,stM)表示第 t 帧所有目标的状态序列,s^{i}_{is:ie}=(s^{i}_{is},...,s^{i}_{ie})sis:iei=(sisi,...,siei)表示第 i 个目标的状态序列,其中i_sis和i_eie分别表示目标 i 出现的第一帧和最后一帧,S_{1:t}=(S_1,S_2,...,S_t)S1:t=(S1,S2,...,St)表示所有目标从第一帧到第t帧的状态序列。这里的状态可以理解为目标对应图像中哪个位置,或者是否存在于此图像中,通过匹配得到对应的观测目标:O_{1:t}=(O_1,O_2,...,O_t)O1:t=(O1,O2,...,Ot)。
1.1 初始化方法
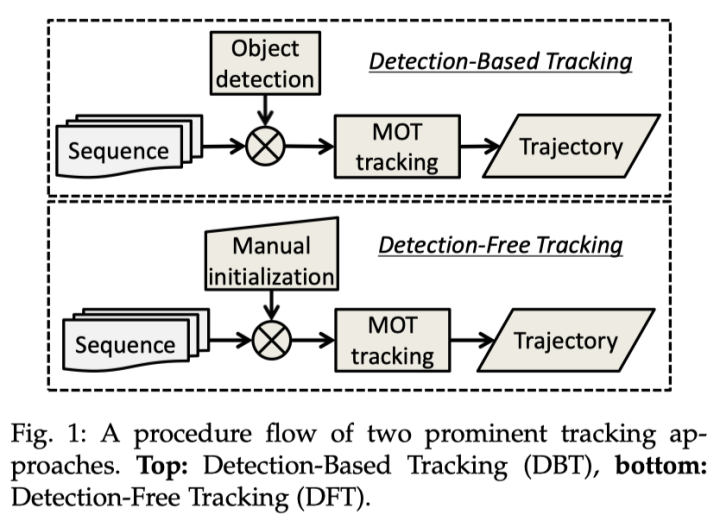
多目标跟踪问题中并不是所有目标都会在第一帧出现,也并不是所有目标都会出现在每一帧。那如何对出现的目标进行初始化,可以作为跟踪算法的分类表针。常见的初始化方法分为两大类,一个是Detection-Based-Tracking(DBT),一个是Detection-Free-Tracking(DFT)。下图比较形象地说明了两类算法的区别。
-
DBT DBT的方式就是典型的tracking-by-detection模式,即先检测目标,然后将目标关联进入跟踪轨迹中。那么就存在两个问题,第一,该跟踪方式非常依赖目标检测器的性能,第二,目标检测的实质是分类和回归,即该跟踪方式只能针对特定的目标类型,如:行人、车辆、动物。DBT则是目前业界研究的主流。
-
DFT DFT是单目标跟踪领域的常用初始化方法,即每当新目标出现时,人为告诉算法新目标的位置,这样做的好处是target free,坏处就是过程比较麻烦,存在过多的交互,所以DBT相对来说更受欢迎。
1.2 处理模式
MOT也存在着不同的处理模式,Online和Offline两大类,其主要区别在于是否用到了后续帧的信息。下图形象解释了Online与Offline跟踪的区别。
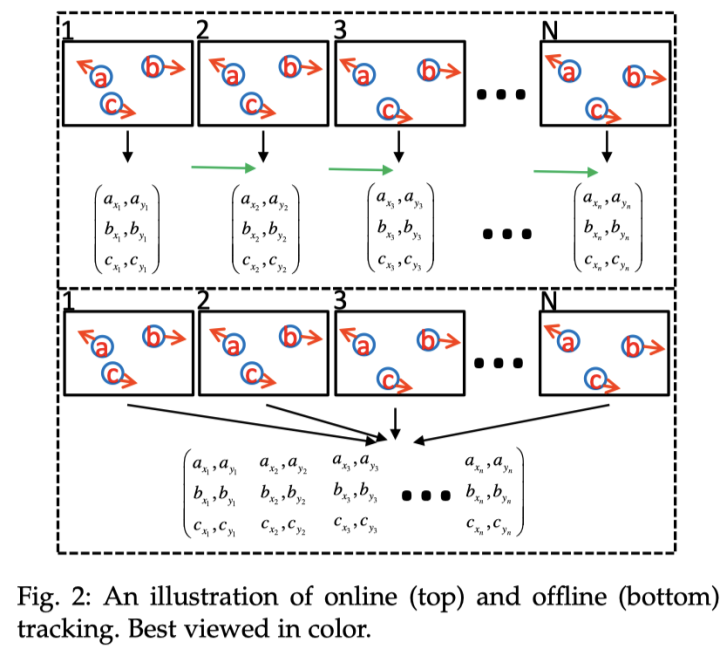
-
Online Tracking Online Tracking是对视频帧逐帧进行处理,当前帧的跟踪仅利用过去的信息。
-
Offline Tracking 不同于Online Tracking,Offline Tracking会利用前后视频帧的信息对当前帧进行目标跟踪,这种方式只适用于视频,如果应用于摄像头,则会有滞后效应,通常采用时间窗方式进行处理,以节省内存和加速。
2.运动模型
为了简化多目标跟踪的难度,我们引入运动模型类简化求解过程,运动模型捕捉目标的动态行为,它估计目标在未来帧中的潜在位置,从而减少搜索空间。在大多数情况下,假设目标在现实中是平缓运动的,那么在图像空间也是如此。对于车辆的运动,大致可分为线性和非线性两种运动:
-
线性运动:线性运动模型是目前最主流的模型,即假设目标的运动属性平稳(速度,加速度,位置);
-
非线性运动:虽然线性运动模型比较常用,但由于存在它解决不了的问题,非线性运动模型随之诞生。它可以使tracklets间运动相似度计算得更加准确。
3.跟踪方法
多目标跟踪中基于神经网络的算法,端到端的算法并不多,主要还在实验室的刷榜阶段,模型复杂,速度慢,追踪结果也不好,我们就不再介绍,主要给大家介绍以下两种主流的算法:
3.1 基于Kalman和KM算法的后端优化算法
该类算法能达到实时性,但依赖于检测算法效果要好,特征区分要好(输出最终结果的好坏依赖于较强的检测算法,而基于卡尔曼加匈牙利匹配的追踪算法作用在于能够输出检测目标的id,其次能保证追踪算法的实时性),这样追踪效果会好,id切换少。代表性的算法是SORT/DeepSORT。
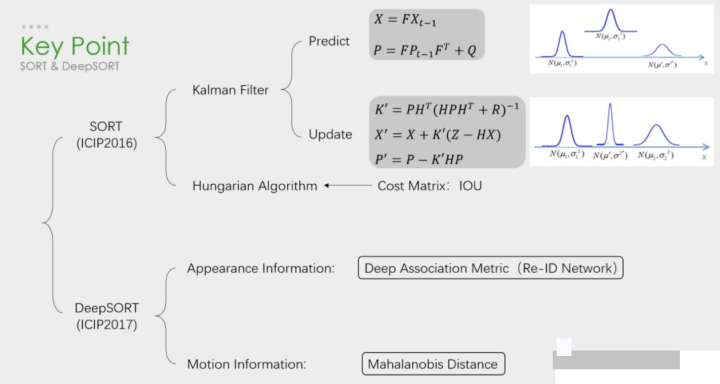
SORT 是一种实用的多目标跟踪算法,引入了线性速度模型与卡尔曼滤波来进行位置预测,在无合适匹配检测框的情况下,使用运动模型来预测物体的位置。匈牙利算法是一种寻找二分图的最大匹配的算法,在多目标跟踪问题中可以简单理解为寻找前后两帧的若干目标的匹配最优解的一种算法。而卡尔曼滤波可以看作是一种运动模型,用来对目标的轨迹进行预测,并且使用确信度较高的跟踪结果进行预测结果的修正。
多目标追踪一般接在目标检测后。在工业界目标检测采用比较多的是yolo检测网络,单阶段式,速度快,精度不差,部署在NV的平台帧率可以达到30fps以上。所以要实现目标检测代码和多目标追踪代码集成的任务,需要先将两者的框架统一。先实现目标检测网络,检测的输出结果主要是将检测框的位置信息输入到多目标追踪算法中。
3.2 基于多线程的单目标跟踪的多目标跟踪算法
这类算法特点是跟踪效果会很好,因为其为每一类物体都单独分配了一个跟踪器。但该算法对目标尺度变化要求较大,参数调试需要合理,同时该算法极耗cpu资源,实时性不高,代表算法是利用KCF进行目标跟踪。
多目标追踪本质上是多个目标同时运动的问题,所以有提出将单目标跟踪器引入到多目标追踪的问题,为每一个目标分配一个跟踪器,然后间接地使用匹配算法来修正那些跟踪失败或新出现的目标。代表性的单目标跟踪算法为核相关滤波算法(KCF),在精度和速度上能够同时达到很高的水平,是当时单目标跟踪最优秀的算法之一,后来的很多单目标跟踪算法都是基于此做的改进。
实际应用过程中会为每个目标分配一个KCF跟踪器并采用多线程的方式来组织这些跟踪器。同时因为实际硬件条件的限制,不可能提供强大的计算力资源,会采用检测器与跟踪器交替进行的跟踪策略。由于检测的帧率不高,使得跟踪的维持效果出现滞后或框飘的现象较为严重,实用性不大。
(二)辅助功能
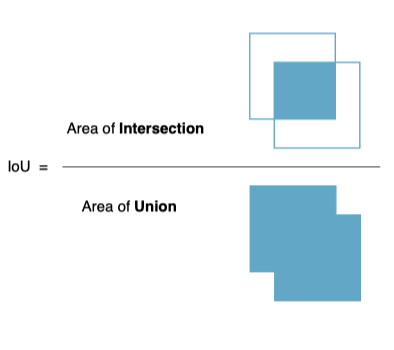
IOU是交并比(Intersection-over-Union)是目标检测中使用的一个概念是产生的候选框(candidate bound)与原标记框(ground truth bound)的交叠率,即它们的交集与并集的比值。最理想情况是完全重叠,即比值为1。在多目标跟踪中,用来判别跟踪框和目标检测框之间的相似度。

1.计算交并比
IoU是两个区域的交除以两个区域的并得出的结果
def iou(bb_test, bb_gt): """ 在两个box间计算IOU :param bb_test: box1 = [x1y1x2y2] :param bb_gt: box2 = [x1y1x2y2] :return: 交并比IOU """ xx1 = np.maximum(bb_test[0], bb_gt[0]) yy1 = np.maximum(bb_test[1], bb_gt[1]) xx2 = np.minimum(bb_test[2], bb_gt[2]) yy2 = np.minimum(bb_test[3], bb_gt[3]) w = np.maximum(0., xx2 - xx1) h = np.maximum(0., yy2 - yy1) wh = w * h o = wh / ((bb_test[2] - bb_test[0]) * (bb_test[3] - bb_test[1]) + (bb_gt[2] - bb_gt[0]) * ( bb_gt[3] - bb_gt[1]) - wh) return o
2.候选框的表示形式
在该项目中候选框有两种表示形式:
-
[x1,y1,x2,y2] 表示左上角坐标和右下角坐标,目标检测的结果以该方式表示
-
[x,y,s,r]表示中心点坐标,s 是面积尺度,r是纵横比,卡尔曼滤波器中进行运动估计是使用该方式。
这两种方式要进行相互的转换。
-
将候选框从坐标形式转换为中心点坐标和面积的形式
def convert_bbox_to_z(bbox): """ 将[x1,y1,x2,y2]形式的检测框转为滤波器的状态表示形式[x,y,s,r]。其中x,y是框的中心坐标,s是面积,尺度,r是宽高比 :param bbox: [x1,y1,x2,y2] 分别是左上角坐标和右下角坐标 :return: [ x, y, s, r ] 4行1列,其中x,y是box中心位置的坐标,s是面积,r是纵横比w/h """ w = bbox[2] - bbox[0] h = bbox[3] - bbox[1] x = bbox[0] + w / 2. y = bbox[1] + h / 2. s = w * h r = w / float(h) return np.array([x, y, s, r]).reshape((4, 1))
-
将候选框从中心面积的形式转换为坐标的形式
def convert_x_to_bbox(x, score=None): """ 将[cx,cy,s,r]的目标框表示转为[x_min,y_min,x_max,y_max]的形式 :param x:[ x, y, s, r ],其中x,y是box中心位置的坐标,s是面积,r :param score: 置信度 :return:[x1,y1,x2,y2],左上角坐标和右下角坐标 """ w = np.sqrt(x[2] * x[3]) h = x[2] / w if score is None: return np.array([x[0] - w / 2., x[1] - h / 2., x[0] + w / 2., x[1] + h / 2.]).reshape((1, 4)) else: return np.array([x[0] - w / 2., x[1] - h / 2., x[0] + w / 2., x[1] + h / 2., score]).reshape((1, 5))
(三)卡尔曼滤波器
1、背景介绍
卡尔曼滤波(Kalman)无论是在单目标还是多目标领域都是很常用的一种算法,我们将卡尔曼滤波看做一种运动模型,用来对目标的位置进行预测,并且利用预测结果对跟踪的目标进行修正,属于自动控制理论中的一种方法。
在对视频中的目标进行跟踪时,当目标运动速度较慢时,很容易将前后两帧的目标进行关联,如下图所示:
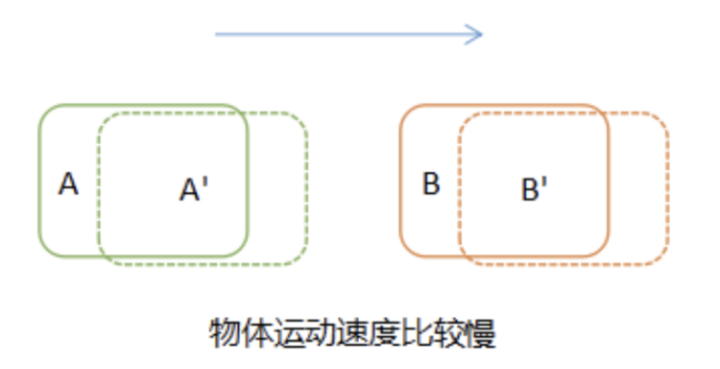
如果目标运动速度比较快,或者进行隔帧检测时,在后续帧中,目标A已运动到前一帧B所在的位置,这时再进行关联就会得到错误的结果,将A‘与B关联在一起。
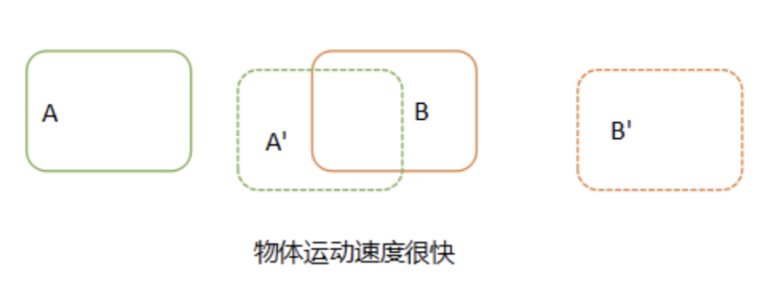
那怎么才能避免这种出现关联误差呢?我们可以在进行目标关联之前,对目标在后续帧中出现的位置进行预测,然后与预测结果进行对比关联,如下图所示:
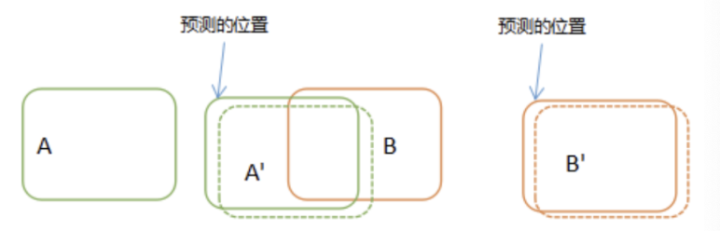
我们在对比关联之前,先预测出A和B在下一帧中的位置,然后再使用实际的检测位置与预测的位置进行对比关联,只要预测足够精确,几乎不会出现由于速度太快而存在的误差。
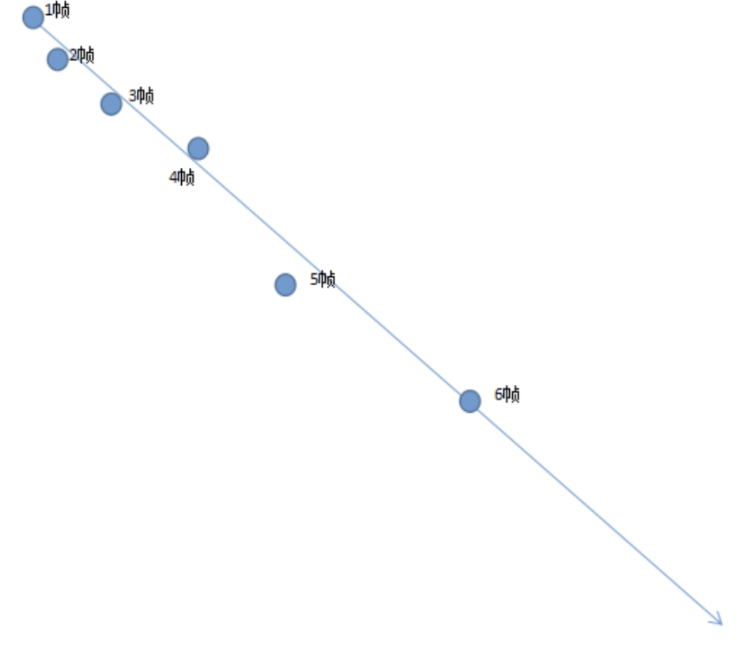
卡尔曼滤波就可以用来预测目标在后续帧中出现的位置,如下图所示,卡尔曼滤波器就可以根据前面五帧数据目标的位置,预测第6帧目标的位置。
卡尔曼滤波器最大的优点是采用递归的方法来解决线性滤波的问题,它只需要当前的测量值和前一个周期的预测值就能够进行状态估计。由于这种递归方法不需要大量的存储空间,每一步的计算量小,计算步骤清晰,非常适合计算机处理,因此卡尔曼滤波受到了普遍的欢迎,在各种领域具有广泛的应用前景。
2.原理介绍
我们假设一个简单的场景,有一辆小车在行驶,它的速度是v,可以通过观测得到它的位置p,也就是说我们可以实时的观测小车的状态。
-
场景描述

虽然我们比较确定小车此时的状态,无论是计算还是检测都会存在一定的误差,所以我们只能认为当前状态是其真实状态的一个最优估计。那么我们不妨认为当前状态服从一个高斯分布,如下图所示:
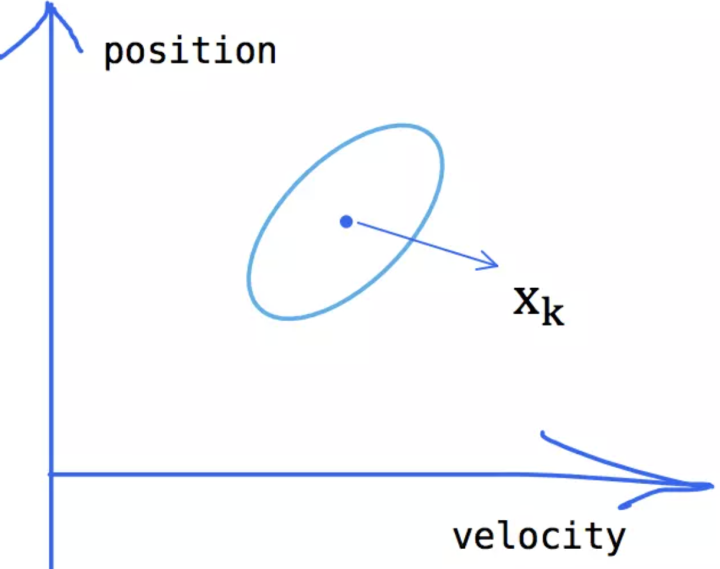




前面我们通过小车的上一个状态,对它的当前状态做了预测,此时我们要考虑对于小车的状态能够观测到什么呢?
小车的当前状态和观测到的数据应该具备某种特定的关系,假设这个关系通过矩阵表示为\mathbf{H}_kHk,如下图所示:

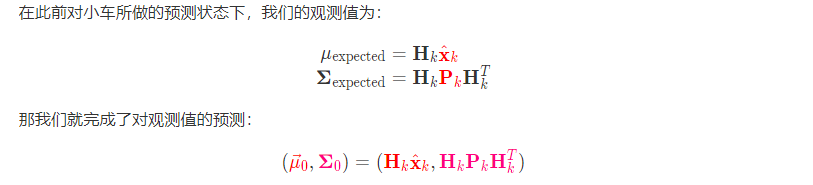
-
实际的观测结果
前面推测小车当前的状态,推测了我们的观测数据,但是现实和理想之间必然是存在差距的,我们预测的观测结果和实际的观测结果可能如下图所示:


卡尔曼滤波需要做的最重要的最核心的事就是融合预测和观测的结果,充分利用两者的不确定性来得到更加准确的估计。通俗来说就是怎么从上面的两个椭圆中来得到中间淡黄色部分的高斯分布,看起来这是预测和观测高斯分布的重合部分,也就是概率比较高的部分。
-
高斯分布的乘积
对于任意两个高斯分布,将二者相乘之后还是高斯分布,我们利用高斯分布的两个特性进行求解,其一是均值处分布函数取极大值,其二是均值处分布曲线的曲率为其二阶导数,我们可以求出:
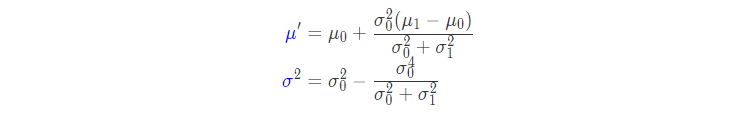
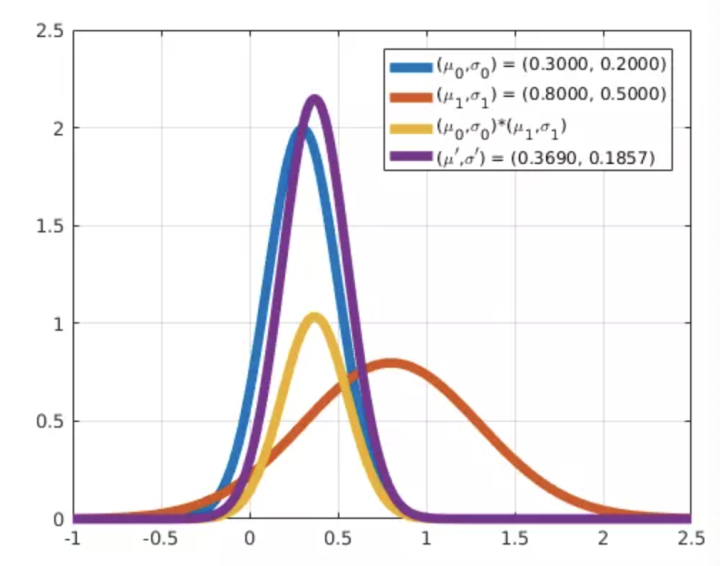
图中蓝色和橙色两个波形的直接乘积是黄色这个波形,紫色是计算了均值和方差的记过,黄色的分布可以通过紫色的波形乘上一个系数得到。
对于高阶的高斯分布:
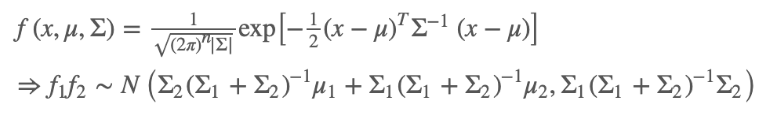



(四)卡尔曼滤波器实践
1.filterpy
FilterPy是一个实现了各种滤波器的Python模块,它实现著名的卡尔曼滤波和粒子滤波器。我们可以直接调用该库完成卡尔曼滤波器实现。其中的主要模块包括:
-
filterpy.kalman 该模块主要实现了各种卡尔曼滤波器,包括常见的线性卡尔曼滤波器,扩展卡尔曼滤波器等。
-
filterpy.common 该模块主要提供支持实现滤波的各种辅助函数,其中计算噪声矩阵的函数,线性方程离散化的函数等。
-
filterpy.stats 该模块提供与滤波相关的统计函数,包括多元高斯算法,对数似然算法,PDF及协方差等。
-
filterpy.monte_carlo 该模块提供了马尔科夫链蒙特卡洛算法,主要用于粒子滤波。
开源代码在:
https://github.com/rlabbe/filterpy/tree/master/filterpy/kalman
我们介绍下卡尔曼滤波器的实现,主要分为预测和更新两个阶段,在进行滤波之前,需要先进行初始化:
-
初始化
预先设定状态变量dim_x和观测变量维度dim_z、协方差矩阵P、运动形式和观测矩阵H等,一般各个协方差矩阵都会初始化为单位矩阵,根据特定的场景需要相应的设置。
def __init__(self, dim_x, dim_z, dim_u = 0, x = None, P = None, Q = None, B = None, F = None, H = None, R = None): """Kalman Filter Refer to http:/github.com/rlabbe/filterpy Method ----------------------------------------- Predict | Update ----------------------------------------- | K = PH^T(HPH^T + R)^-1 x = Fx + Bu | y = z - Hx P = FPF^T + Q | x = x + Ky | P = (1 - KH)P | S = HPH^T + R ----------------------------------------- note: In update unit, here is a more numerically stable way: P = (I-KH)P(I-KH)' + KRK' Parameters ---------- dim_x: int dims of state variables, eg:(x,y,vx,vy)->4 dim_z: int dims of observation variables, eg:(x,y)->2 dim_u: int dims of control variables,eg: a->1 p = p + vt + 0.5at^2 v = v + at =>[p;v] = [1,t;0,1][p;v] + [0.5t^2;t]a """ assert dim_x >= 1, 'dim_x must be 1 or greater' assert dim_z >= 1, 'dim_z must be 1 or greater' assert dim_u >= 0, 'dim_u must be 0 or greater' self.dim_x = dim_x self.dim_z = dim_z self.dim_u = dim_u # initialization # predict self.x = np.zeros((dim_x, 1)) if x is None else x # state self.P = np.eye(dim_x) if P is None else P # uncertainty covariance self.Q = np.eye(dim_x) if Q is None else Q # process uncertainty for prediction self.B = None if B is None else B # control transition matrix self.F = np.eye(dim_x) if F is None else F # state transition matrix # update self.H = np.zeros((dim_z, dim_x)) if H is None else H # Measurement function z=Hx self.R = np.eye(dim_z) if R is None else R # observation uncertainty self._alpha_sq = 1. # fading memory control self.z = np.array([[None] * self.dim_z]).T # observation self.K = np.zeros((dim_x, dim_z)) # kalman gain self.y = np.zeros((dim_z, 1)) # estimation error self.S = np.zeros((dim_z, dim_z)) # system uncertainty, S = HPH^T + R self.SI = np.zeros((dim_z, dim_z)) # inverse system uncertainty, SI = S^-1 self.inv = np.linalg.inv self._mahalanobis = None # Mahalanobis distance of measurement self.latest_state = 'init' # last process name
-
预测阶段
接下来进入预测环节,为了保证通用性,引入了遗忘系数α,其作用在于调节对过往信息的依赖程度,α越大对历史信息的依赖越小:
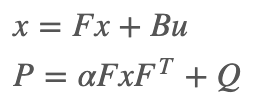
代码如下:
def predict(self, u = None, B = None, F = None, Q = None): """ Predict next state (prior) using the Kalman filter state propagation equations: x = Fx + Bu P = fading_memory*FPF^T + Q Parameters ---------- u : ndarray Optional control vector. If not `None`, it is multiplied by B to create the control input into the system. B : ndarray of (dim_x, dim_z), or None Optional control transition matrix; a value of None will cause the filter to use `self.B`. F : ndarray of (dim_x, dim_x), or None Optional state transition matrix; a value of None will cause the filter to use `self.F`. Q : ndarray of (dim_x, dim_x), scalar, or None Optional process noise matrix; a value of None will cause the filter to use `self.Q`. """ if B is None: B = self.B if F is None: F = self.F if Q is None: Q = self.Q elif np.isscalar(Q): Q = np.eye(self.dim_x) * Q # x = Fx + Bu if B is not None and u is not None: self.x = F @ self.x + B @ u else: self.x = F @ self.x # P = fading_memory*FPF' + Q self.P = self._alpha_sq * (F @ self.P @ F.T) + Q self.latest_state = 'predict'
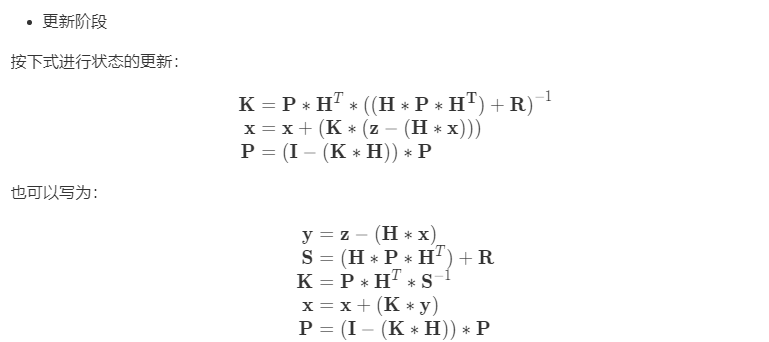
其中,y是测量余量,S是测量余量的协方差矩阵。
在实际应用中会做一些微调,使协方差矩阵为:
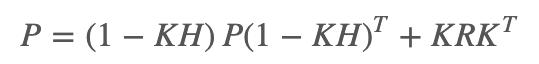
代码如下:
def update(self, z, R = None, H = None): """ Update Process, add a new measurement (z) to the Kalman filter. K = PH^T(HPH^T + R)^-1 y = z - Hx x = x + Ky P = (1 - KH)P or P = (I-KH)P(I-KH)' + KRK' If z is None, nothing is computed. Parameters ---------- z : (dim_z, 1): array_like measurement for this update. z can be a scalar if dim_z is 1, otherwise it must be convertible to a column vector. R : ndarray, scalar, or None Optionally provide R to override the measurement noise for this one call, otherwise self.R will be used. H : ndarray, or None Optionally provide H to override the measurement function for this one call, otherwise self.H will be used. """ if z is None: self.z = np.array([[None] * self.dim_z]).T self.y = np.zeros((self.dim_z, 1)) return z = reshape_z(z, self.dim_z, self.x.ndim) if R is None: R = self.R elif np.isscalar(R): R = np.eye(self.dim_z) * R if H is None: H = self.H if self.latest_state == 'predict': # common subexpression for speed PHT = self.P @ H.T # S = HPH' + R # project system uncertainty into measurement space self.S = H @ PHT + R self.SI = self.inv(self.S) # K = PH'inv(S) # map system uncertainty into kalman gain self.K = PHT @ self.SI # P = (I-KH)P(I-KH)' + KRK' # This is more numerically stable and works for non-optimal K vs # the equation P = (I-KH)P usually seen in the literature. I_KH = np.eye(self.dim_x) - self.K @ H self.P = I_KH @ self.P @ I_KH.T + self.K @ R @ self.K.T # y = z - Hx # error (residual) between measurement and prediction self.y = z - H @ self.x self._mahalanobis = math.sqrt(float(self.y.T @ self.SI @ self.y)) # x = x + Ky # predict new x with residual scaled by the kalman gain self.x = self.x + self.K @ self.y self.latest_state = 'update'
那接下来,我们就是用filterpy中的卡尔曼滤波器方法完成小车位置的预测。
2.小车案例
现在利用卡尔曼滤波对小车的运动状态进行预测。主要流程如下所示:
-
导入相应的工具包
-
小车运动数据生成
-
参数初始化
-
利用卡尔曼滤波进行小车状态预测
-
可视化:观察参数的变化与结果
下面我们看下整个流程实现:
-
导入包
from matplotlib import pyplot as plt import seaborn as sns import numpy as np from filterpy.kalman import KalmanFilter
-
小车运动数据生成
在这里我们假设小车作速度为1的匀速运动
# 生成1000个位置,从1到1000,是小车的实际位置 z = np.linspace(1,1000,1000) # 添加噪声 mu,sigma = 0,1 noise = np.random.normal(mu,sigma,1000) # 小车位置的观测值 z_nosie = z+noise
-
参数初始化
# dim_x 状态向量size,在该例中为[p,v],即位置和速度,size=2 # dim_z 测量向量size,假设小车为匀速,速度为1,测量向量只观测位置,size=1 my_filter = KalmanFilter(dim_x=2, dim_z=1) # 定义卡尔曼滤波中所需的参数 # x 初始状态为[0,0],即初始位置为0,速度为0. # 这个初始值不是非常重要,在利用观测值进行更新迭代后会接近于真实值 my_filter.x = np.array([[0.], [0.]]) # p 协方差矩阵,表示状态向量内位置与速度的相关性 # 假设速度与位置没关系,协方差矩阵为[[1,0],[0,1]] my_filter.P = np.array([[1., 0.], [0., 1.]]) # F 初始的状态转移矩阵,假设为匀速运动模型,可将其设为如下所示 my_filter.F = np.array([[1., 1.], [0., 1.]]) # Q 状态转移协方差矩阵,也就是外界噪声, # 在该例中假设小车匀速,外界干扰小,所以我们对F非常确定,觉得F一定不会出错,所以Q设的很小 my_filter.Q = np.array([[0.0001, 0.], [0., 0.0001]]) # 观测矩阵 Hx = p # 利用观测数据对预测进行更新,观测矩阵的左边一项不能设置成0 my_filter.H = np.array([[1, 0]]) # R 测量噪声,方差为1 my_filter.R = 1
-
卡尔曼滤波进行预测
# 保存卡尔曼滤波过程中的位置和速度 z_new_list = [] v_new_list = [] # 对于每一个观测值,进行一次卡尔曼滤波 for k in range(len(z_nosie)): # 预测过程 my_filter.predict() # 利用观测值进行更新 my_filter.update(z_nosie[k]) # do something with the output x = my_filter.x # 收集卡尔曼滤波后的速度和位置信息 z_new_list.append(x[0][0]) v_new_list.append(x[1][0])
-
可视化
-
预测误差的可视化
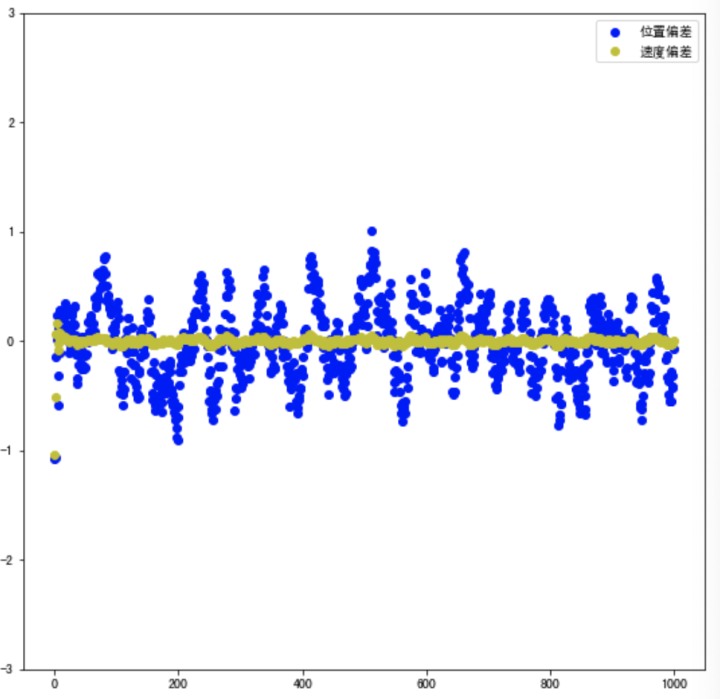
# 位移的偏差 dif_list = [] for k in range(len(z)): dif_list.append(z_new_list[k]-z[k]) # 速度的偏差 v_dif_list = [] for k in range(len(z)): v_dif_list.append(v_new_list[k]-1) plt.figure(figsize=(20,9)) plt.subplot(1,2,1) plt.xlim(-50,1050) plt.ylim(-3.0,3.0) plt.scatter(range(len(z)),dif_list,color ='b',label = "位置偏差") plt.scatter(range(len(z)),v_dif_list,color ='y',label = "速度偏差") plt.legend()
运行结果如下所示:
2.卡尔曼滤波器参数的变化
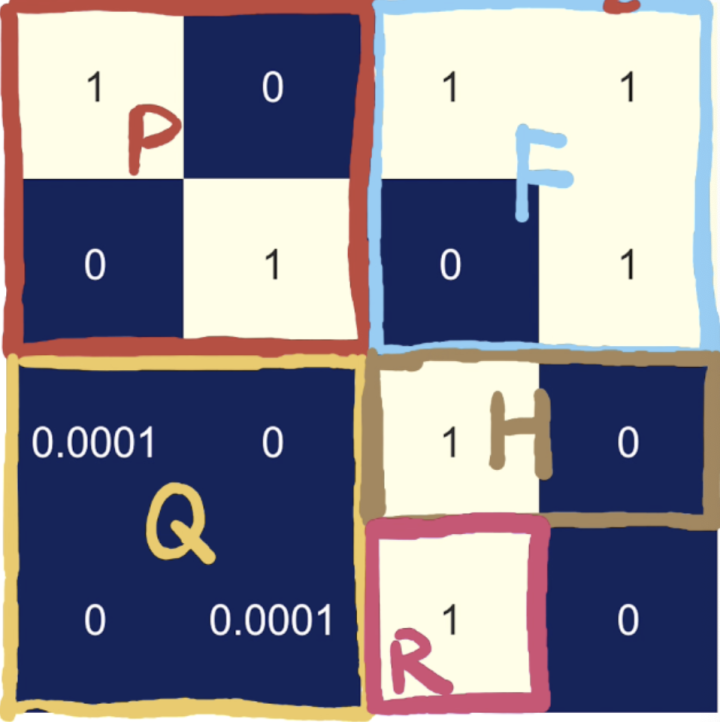
首先定义方法将卡尔曼滤波器的参数堆叠成一个矩阵,右下角补0,我们看一下参数的变化。
# 定义一个方法将卡尔曼滤波器的参数堆叠成一个矩阵,右下角补0 def filter_comb(p, f, q, h, r): a = np.hstack((p, f)) b = np.array([r, 0]) b = np.vstack([h, b]) b = np.hstack((q, b)) a = np.vstack((a, b)) return a
对参数变化进行可视化:
# 保存卡尔曼滤波过程中的位置和速度 z_new_list = [] v_new_list = [] # 对于每一个观测值,进行一次卡尔曼滤波 for k in range(1): # 预测过程 my_filter.predict() # 利用观测值进行更新 my_filter.update(z_nosie[k]) # do something with the output x = my_filter.x c = filter_comb(my_filter.P,my_filter.F,my_filter.Q,my_filter.H,my_filter.R) plt.figure(figsize=(32,18)) sns.set(font_scale=4) #sns.heatmap(c,square=True,annot=True,xticklabels=False,yticklabels==False,cbar=False) sns.heatmap(c,square=True,annot=True,xticklabels=False,yticklabels=False,cbar=False)
对比变换:
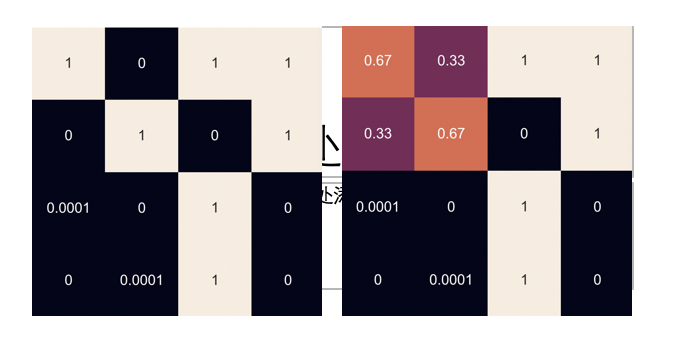
从图中可以看出变化的P,其他的参数F,Q,H,R为变换。另外状态变量x和卡尔曼系数K也是变化的。
3.概率密度函数
为了验证卡尔曼滤波的结果优于测量的结果,绘制预测结果误差和测量误差的概率密度函数:
# 生成概率密度图像 z_noise_list_std = np.std(noise) z_noise_list_avg = np.mean(noise) z_filterd_list_std = np.std(dif_list) import seaborn as sns plt.figure(figsize=(16,9)) ax = sns.kdeplot(noise,shade=True,color="r",label="std=%.3f"%z_noise_list_std) ax = sns.kdeplot(dif_list,shade=True,color="g",label="std=%.3f"%z_filterd_list_std)
结果如下:
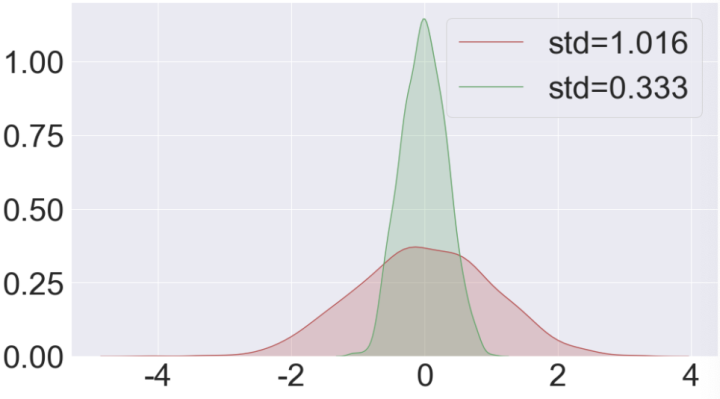
可以看出卡尔曼滤波器预测的结果误差方差更小,优于测试的结果。
(五)目标估计模型-卡尔曼滤波
在这里我们主要完成卡尔曼滤波器进行跟踪的相关内容的实现。
-
初始化:卡尔曼滤波器的状态变量和观测输入
-
更新状态变量
-
根据状态变量预测目标的边界框
-
初始化: 状态量x的设定是一个七维向量:ert_x_to_bbox(self.kf.x)
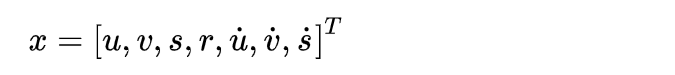
分别表示目标中心位置的x,y坐标,面积s和当前目标框的纵横比,最后三个则是横向,纵向,面积的变化速率,其中速度部分初始化为0,其他根据观测进行输入。
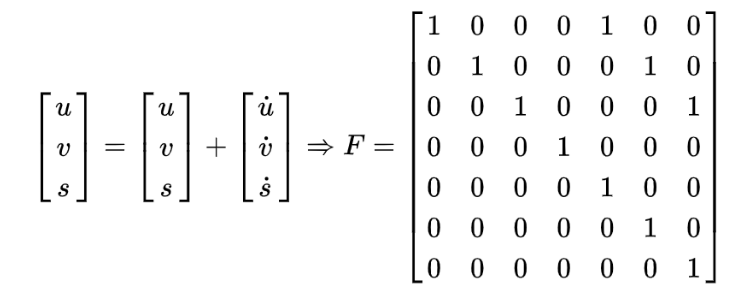
初始化卡尔曼滤波器参数,7个状态变量和4个观测输入,运动形式和转换矩阵的确定都是基于匀速运动模型,状态转移矩阵F根据运动学公式确定:
量测矩阵H是4*7的矩阵,将观测值与状态变量相对应:
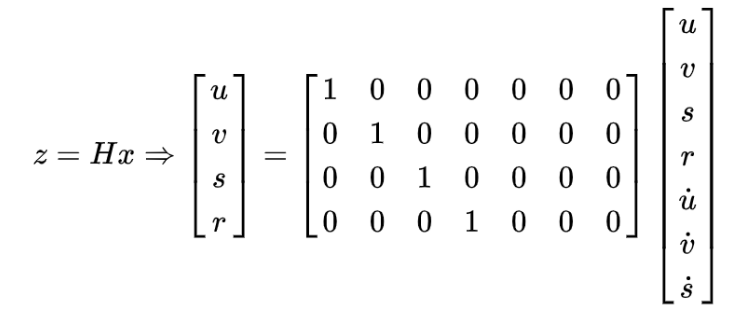
以及相应的协方差参数的设定,根据经验值进行设定。

def __init__(self, bbox): # 定义等速模型 # 内部使用KalmanFilter,7个状态变量和4个观测输入 self.kf = KalmanFilter(dim_x=7, dim_z=4) # F是状态变换模型,为7*7的方阵 self.kf.F = np.array( [[1, 0, 0, 0, 1, 0, 0], [0, 1, 0, 0, 0, 1, 0], [0, 0, 1, 0, 0, 0, 1], [0, 0, 0, 1, 0, 0, 0], [0, 0, 0, 0, 1, 0, 0], [0, 0, 0, 0, 0, 1, 0], [0, 0, 0, 0, 0, 0, 1]]) # H是量测矩阵,是4*7的矩阵 self.kf.H = np.array( [[1, 0, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0], [0, 0, 1, 0, 0, 0, 0], [0, 0, 0, 1, 0, 0, 0]]) # R是测量噪声的协方差,即真实值与测量值差的协方差 self.kf.R[2:, 2:] *= 10. # P是先验估计的协方差 self.kf.P[4:, 4:] *= 1000. # give high uncertainty to the unobservable initial velocities self.kf.P *= 10. # Q是过程激励噪声的协方差 self.kf.Q[-1, -1] *= 0.01 self.kf.Q[4:, 4:] *= 0.01 # 状态估计 self.kf.x[:4] = convert_bbox_to_z(bbox) # 参数的更新 self.time_since_update = 0 self.id = KalmanBoxTracker.count KalmanBoxTracker.count += 1 self.history = [] self.hits = 0 self.hit_streak = 0 self.age = 0
更新状态变量 使用观测到的目标框更新状态变量
def update(self, bbox): # 重置 self.time_since_update = 0 # 清空history self.history = [] # hits计数加1 self.hits += 1 self.hit_streak += 1 # 根据观测结果修改内部状态x self.kf.update(convert_bbox_to_z(bbox))
进行目标框的预测 推进状态变量并返回预测的边界框结果
def predict(self): # 推进状态变量 if (self.kf.x[6] + self.kf.x[2]) <= 0: self.kf.x[6] *= 0.0 # 进行预测 self.kf.predict() # 卡尔曼滤波的次数 self.age += 1 # 若过程中未更新过,将hit_streak置为0 if self.time_since_update > 0: self.hit_streak = 0 self.time_since_update += 1 # 将预测结果追加到history中 self.history.append(convert_x_to_bbox(self.kf.x)) return self.history[-1]
整个代码如下所示:
class KalmanBoxTracker(object): count = 0 def __init__(self, bbox): """ 初始化边界框和跟踪器 :param bbox: """ # 定义等速模型 # 内部使用KalmanFilter,7个状态变量和4个观测输入 self.kf = KalmanFilter(dim_x=7, dim_z=4) self.kf.F = np.array( [[1, 0, 0, 0, 1, 0, 0], [0, 1, 0, 0, 0, 1, 0], [0, 0, 1, 0, 0, 0, 1], [0, 0, 0, 1, 0, 0, 0], [0, 0, 0, 0, 1, 0, 0], [0, 0, 0, 0, 0, 1, 0], [0, 0, 0, 0, 0, 0, 1]]) self.kf.H = np.array( [[1, 0, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0], [0, 0, 1, 0, 0, 0, 0], [0, 0, 0, 1, 0, 0, 0]]) self.kf.R[2:, 2:] *= 10. self.kf.P[4:, 4:] *= 1000. # give high uncertainty to the unobservable initial velocities self.kf.P *= 10. self.kf.Q[-1, -1] *= 0.01 self.kf.Q[4:, 4:] *= 0.01 self.kf.x[:4] = convert_bbox_to_z(bbox) self.time_since_update = 0 self.id = KalmanBoxTracker.count KalmanBoxTracker.count += 1 self.history = [] self.hits = 0 self.hit_streak = 0 self.age = 0 def update(self, bbox): """ 使用观察到的目标框更新状态向量。filterpy.kalman.KalmanFilter.update 会根据观测修改内部状态估计self.kf.x。 重置self.time_since_update,清空self.history。 :param bbox:目标框 :return: """ self.time_since_update = 0 self.history = [] self.hits += 1 self.hit_streak += 1 self.kf.update(convert_bbox_to_z(bbox)) def predict(self): """ 推进状态向量并返回预测的边界框估计。 将预测结果追加到self.history。由于 get_state 直接访问 self.kf.x,所以self.history没有用到 :return: """ if (self.kf.x[6] + self.kf.x[2]) <= 0: self.kf.x[6] *= 0.0 self.kf.predict() self.age += 1 if self.time_since_update > 0: self.hit_streak = 0 self.time_since_update += 1 self.history.append(convert_x_to_bbox(self.kf.x)) return self.history[-1] def get_state(self): """ 返回当前边界框估计值 :return: """ return convert_x_to_bbox(self.kf.x)
(六)匈牙利算法
匈牙利算法(Hungarian Algorithm)与KM算法(Kuhn-Munkres Algorithm)是用来解决多目标跟踪中的数据关联问题,匈牙利算法与KM算法都是为了求解二分图的最大匹配问题。
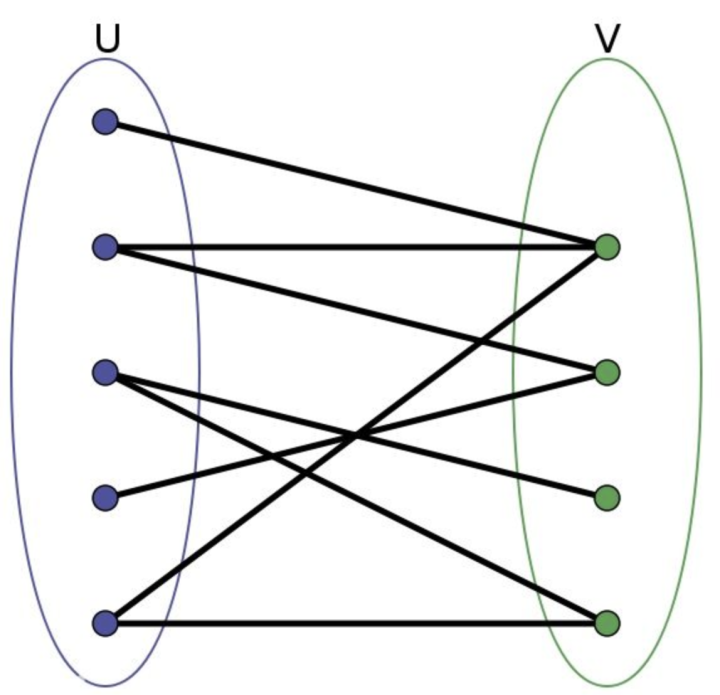
有一种很特别的图,就做二分图,那什么是二分图呢?就是能分成两组,U,V。其中,U上的点不能相互连通,只能连去V中的点,同理,V中的点不能相互连通,只能连去U中的点。这样,就叫做二分图。
可以把二分图理解为视频中连续两帧中的所有检测框,第一帧所有检测框的集合称为U,第二帧所有检测框的集合称为V。同一帧的不同检测框不会为同一个目标,所以不需要互相关联,相邻两帧的检测框需要相互联通,最终将相邻两帧的检测框尽量完美地两两匹配起来。而求解这个问题的最优解就要用到匈牙利算法或者KM算法。
1.匈牙利算法
匈牙利算法是一种在多项式时间内求解任务分配问题的组合优化算法。美国数学家哈罗德·库恩于1955年提出该算法。此算法之所以被称作匈牙利算法,是因为算法很大一部分是基于以前匈牙利数学家Dénes Kőnig和Jenő Egerváry的工作之上创建起来的。
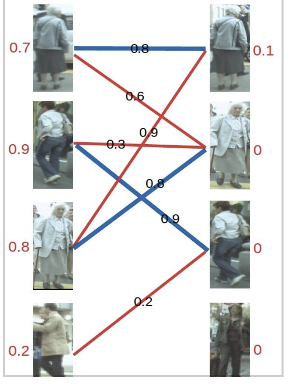
我们以目标跟踪的方法介绍匈牙利算法,以下图为例,假设左边的四张图是我们在第N帧检测到的目标(U),右边四张图是我们在第N+1帧检测到的目标(V)。红线连起来的图,是我们的算法认为是同一行人可能性较大的目标。由于算法并不是绝对理想的,因此并不一定会保证每张图都有一对一的匹配,一对二甚至一对多,再甚至多对多的情况都时有发生。这时我们怎么获得最终的一对一跟踪结果呢?我们来看匈牙利算法是怎么做的。

-
第一步
首先给左1进行匹配,发现第一个与其相连的右1还未匹配,将其配对,连上一条蓝线。

-
第二步
接着匹配左2,发现与其相连的第一个目标右2还未匹配,将其配对

-
第三步
接下来是左3,发现最优先的目标右1已经匹配完成了,怎么办呢?
我们给之前右1的匹配对象左1分配另一个对象。
(黄色表示这条边被临时拆掉)

可以与左1匹配的第二个目标是右2,但右2也已经有了匹配对象,怎么办呢?
我们再给之前右2的匹配对象左2分配另一个对象(注意这个步骤和上面是一样的,这是一个递归的过程)。

此时发现左2还能匹配右3,那么之前的问题迎刃而解了,回溯回去。
左2对右3,左1对右2,左3对右1。

所以第三步最后的结果就是:

-
第四步
最后是左4,很遗憾,按照第三步的节奏我们没法给左4腾出来一个匹配对象,只能放弃对左4的匹配,匈牙利算法流程至此结束。蓝线就是我们最后的匹配结果。至此我们找到了这个二分图的一个最大匹配。最终的结果是我们匹配出了三对目标,由于候选的匹配目标中包含了许多错误的匹配红线(边),所以匹配准确率并不高。可见匈牙利算法对红线连接的准确率要求很高,也就是要求我们运动模型、外观模型等部件必须进行较为精准的预测,或者预设较高的阈值,只将置信度较高的边才送入匈牙利算法进行匹配,这样才能得到较好的结果。
匈牙利算法的流程大家看到了,有一个很明显的问题相信大家也发现了,按这个思路找到的最大匹配往往不是我们心中的最优。匈牙利算法将每个匹配对象的地位视为相同,在这个前提下求解最大匹配。这个和我们研究的多目标跟踪问题有些不合,因为每个匹配对象不可能是同等地位的,总有一个真实目标是我们要找的最佳匹配,而这个真实目标应该拥有更高的权重,在此基础上匹配的结果才能更贴近真实情况。
KM算法就能比较好地解决这个问题,我们下面来看看KM算法。
2.KM算法
KM算法解决的是带权二分图的最优匹配问题。
还是用上面的图来举例子,这次给每条连接关系加入了权重,也就是我们算法中其他模块给出的置信度分值。
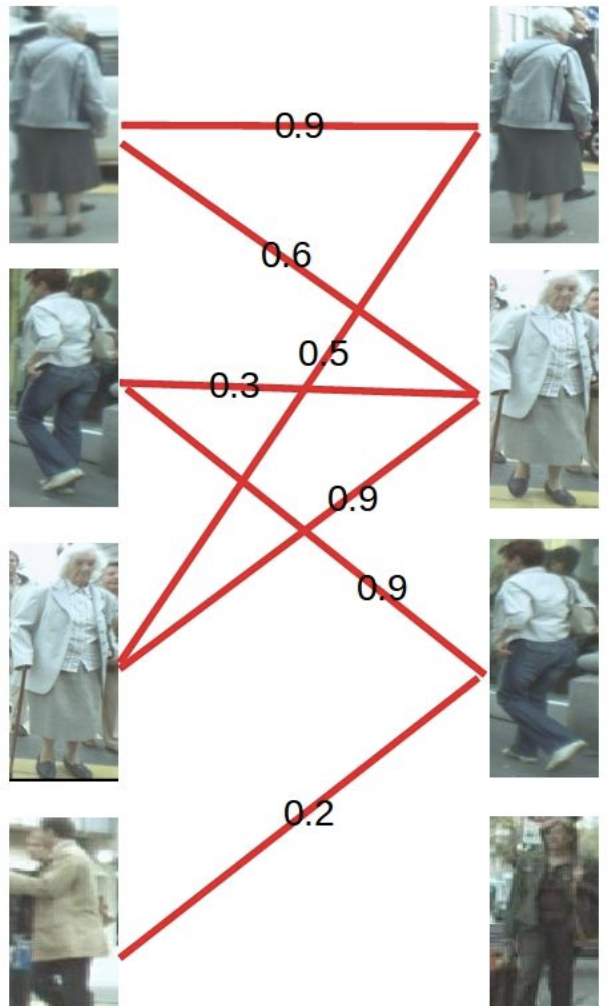
KM算法解决问题的步骤是这样的。
-
第一步
首先对每个顶点赋值,称为顶标,将左边的顶点赋值为与其相连的边的最大权重,右边的顶点赋值为0。
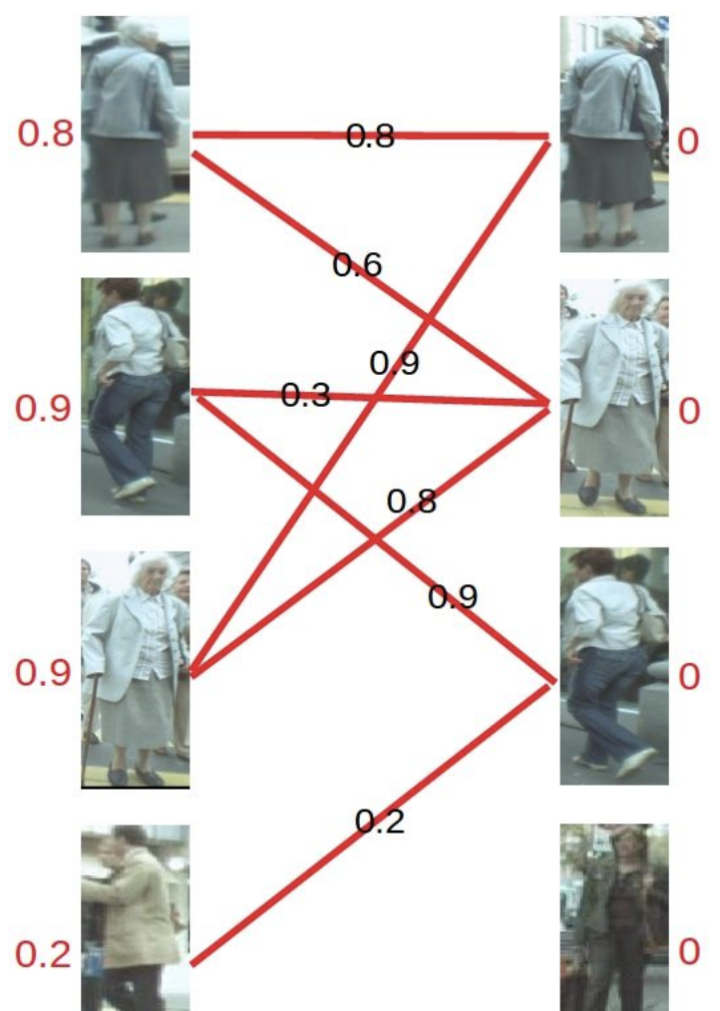
-
第二步:
匹配的原则是只和权重与左边分数(顶标)相同的边进行匹配,若找不到边匹配,对此条路径的所有左边顶点的顶标减d,所有右边顶点的顶标加d。参数d我们在这里取值为0.1。
对于左1,与顶标分值相同的边先标蓝。
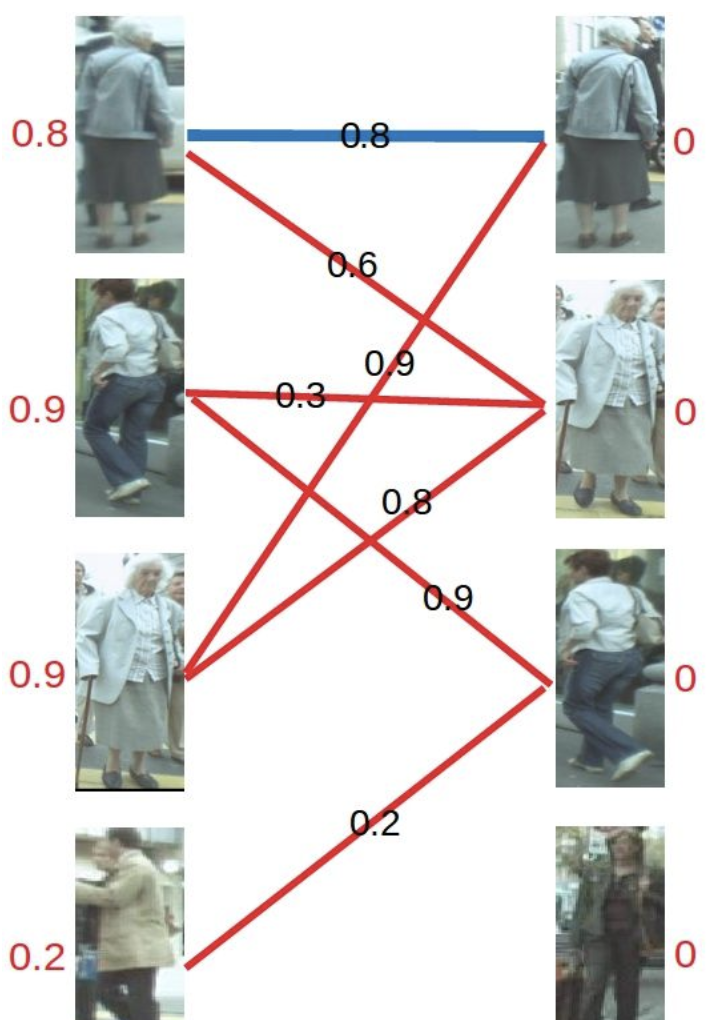
然后是左2,与顶标分值相同的边标
然后是左3,发现与右1已经与左1配对。首先想到让左3更换匹配对象,然而根据匹配原则,只有权值大于等于0.9+0=0.9(左顶标加右顶标)的边能满足要求。于是左3无法换边。那左1能不能换边呢?对于左1来说,只有权值大于等于0.8+0=0.8的边能满足要求,无法换边。此时根据KM算法,应对所有冲突的边的顶点做加减操作,令左边顶点值减0.1,右边顶点值加0.1。结果如下图所示。
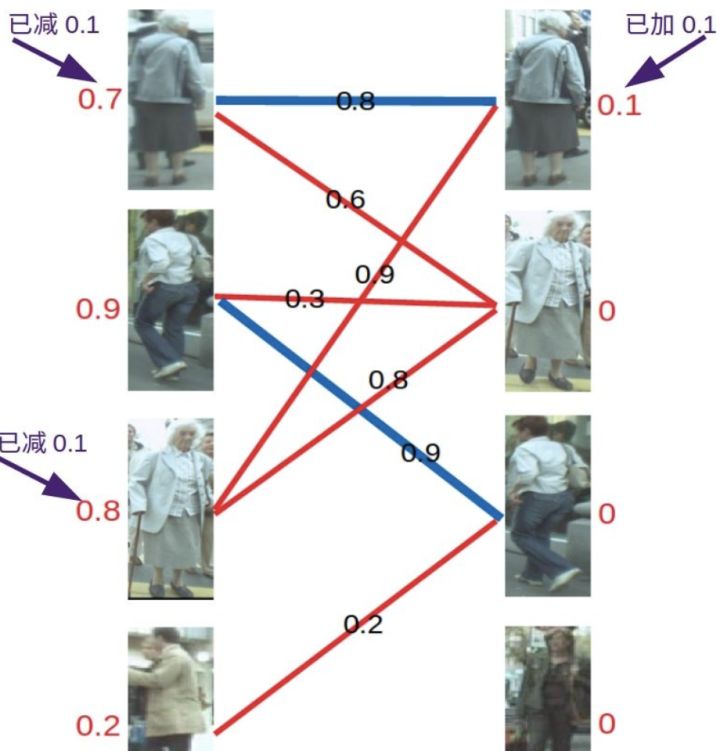
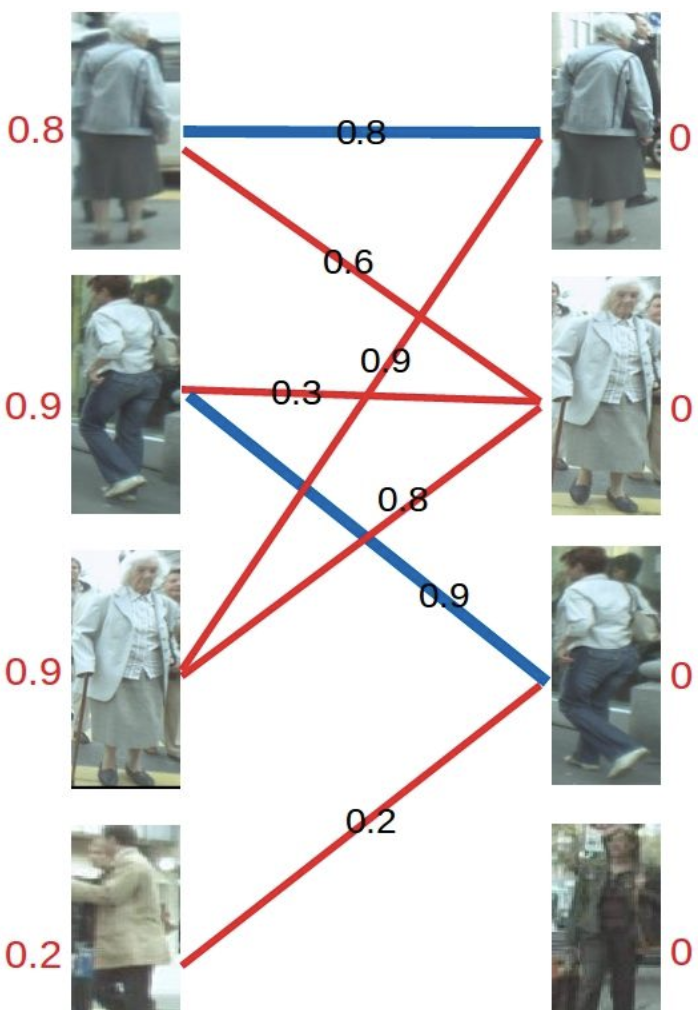
再进行匹配操作,发现左3多了一条可匹配的边,因为此时左3对右2的匹配要求只需权重大于等于0.8+0即可,所以左3与右2匹配
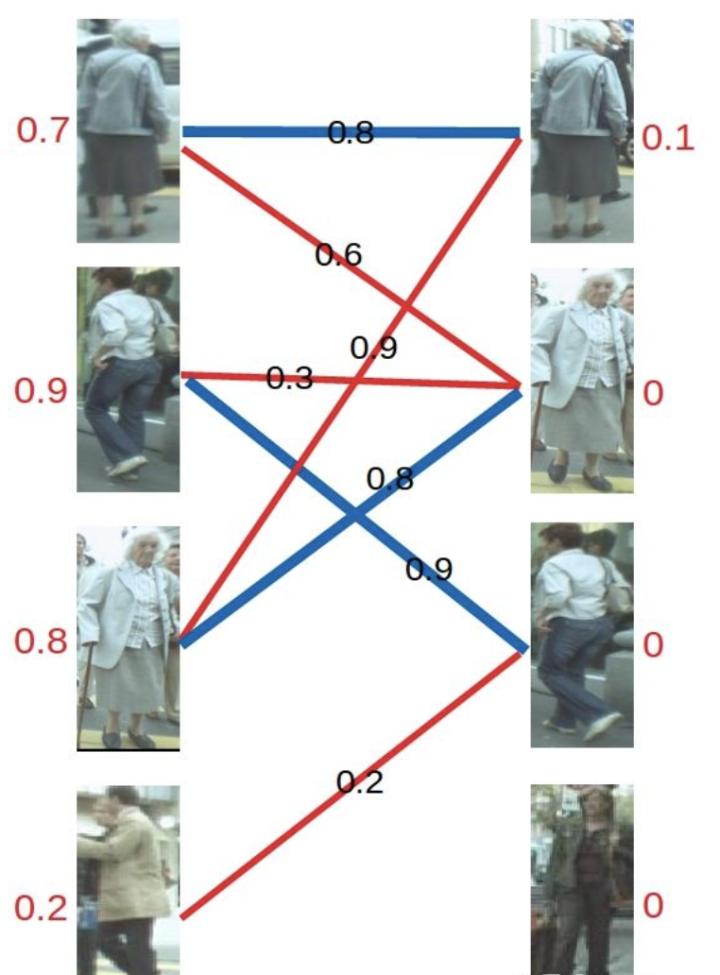
最后进行左4的匹配,由于左4唯一的匹配对象右3已被左2匹配,发生冲突。进行一轮加减d操作,再匹配,左四还是匹配失败。两轮以后左4期望值降为0,放弃匹配左4。
至此KM算法流程结束,三对目标成功匹配,甚至在左三目标预测不够准确的情况下也进行了正确匹配。可见在引入了权重之后,匹配成功率大大提高。。
最后还有一点值得注意,匈牙利算法得到的最大匹配并不是唯一的,预设匹配边、或者匹配顺序不同等,都可能会导致有多种最大匹配情况,所以有一种替代KM算法的想法是,我们只需要用匈牙利算法找到所有的最大匹配,比较每个最大匹配的权重,再选出最大权重的最优匹配即可得到更贴近真实情况的匹配结果。但这种方法时间复杂度较高,会随着目标数越来越多,消耗的时间大大增加,实际使用中并不推荐。
3.匈牙利算法的实现
使用:
scipy.optimize.linear_sum_assignment(cost_matrix)
实现KM算法,其中const_matrix表示代价矩阵。比如第一帧有a,b,c,d四个目标,第二帧图像有p,q,r,s四个目标,其相似度矩阵如下所示:
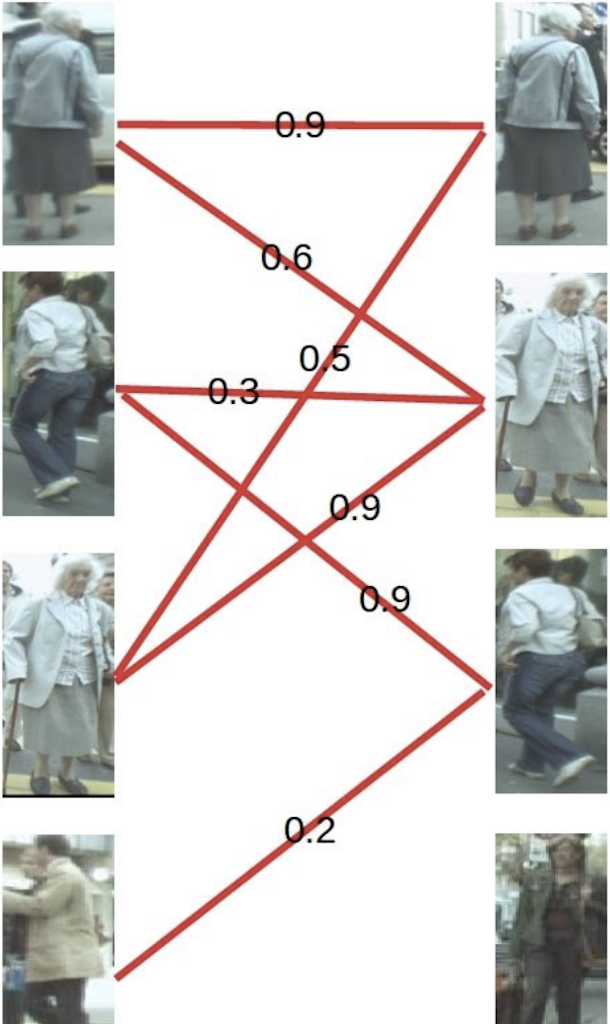
构建相似度矩阵为:
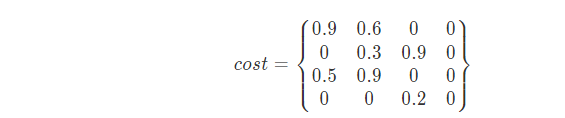
from scipy.optimize import linear_sum_assignment import numpy as np # 代价矩阵 cost =np.array([[0.9,0.6,0,0],[0,0.3,0.9,0],[0.5,0.9,0,0],[0,0,0.2,0]]) # 匹配结果:该方法的目的是代价最小,这里是求最大匹配,所以将cost取负数 row_ind,col_ind=linear_sum_assignment(-cost) #对应的行索引 print("行索引:\n{}".format(row_ind)) #对应行索引的最优指派的列索引 print("列索引:\n{}".format(col_ind)) #提取每个行索引的最优指派列索引所在的元素,形成数组 print("匹配度:\n{}".format(cost[row_ind,col_ind]))
输出结果为:

结果如下图所示:
(七)数据关联
在这里我们对检测框和跟踪框进行匹配,整个流程是遍历检测框和跟踪框,并进行匹配,匹配成功的将其保留,未成功的将其删除。
def associate_detections_to_trackers(detections, trackers, iou_threshold=0.3): """ 将检测框bbox与卡尔曼滤波器的跟踪框进行关联匹配 :param detections:检测框 :param trackers:跟踪框,即跟踪目标 :param iou_threshold:IOU阈值 :return:跟踪成功目标的矩阵:matchs 新增目标的矩阵:unmatched_detections 跟踪失败即离开画面的目标矩阵:unmatched_trackers """ # 跟踪目标数量为0,直接构造结果 if (len(trackers) == 0) or (len(detections) == 0): return np.empty((0, 2), dtype=int), np.arange(len(detections)), np.empty((0, 5), dtype=int) # iou 不支持数组计算。逐个计算两两间的交并比,调用 linear_assignment 进行匹配 iou_matrix = np.zeros((len(detections), len(trackers)), dtype=np.float32) # 遍历目标检测的bbox集合,每个检测框的标识为d for d, det in enumerate(detections): # 遍历跟踪框(卡尔曼滤波器预测)bbox集合,每个跟踪框标识为t for t, trk in enumerate(trackers): iou_matrix[d, t] = iou(det, trk) # 通过匈牙利算法将跟踪框和检测框以[[d,t]...]的二维矩阵的形式存储在match_indices中 result = linear_sum_assignment(-iou_matrix) matched_indices = np.array(list(zip(*result))) # 记录未匹配的检测框及跟踪框 # 未匹配的检测框放入unmatched_detections中,表示有新的目标进入画面,要新增跟踪器跟踪目标 unmatched_detections = [] for d, det in enumerate(detections): if d not in matched_indices[:, 0]: unmatched_detections.append(d) # 未匹配的跟踪框放入unmatched_trackers中,表示目标离开之前的画面,应删除对应的跟踪器 unmatched_trackers = [] for t, trk in enumerate(trackers): if t not in matched_indices[:, 1]: unmatched_trackers.append(t) # 将匹配成功的跟踪框放入matches中 matches = [] for m in matched_indices: # 过滤掉IOU低的匹配,将其放入到unmatched_detections和unmatched_trackers if iou_matrix[m[0], m[1]] < iou_threshold: unmatched_detections.append(m[0]) unmatched_trackers.append(m[1]) # 满足条件的以[[d,t]...]的形式放入matches中 else: matches.append(m.reshape(1, 2)) # 初始化matches,以np.array的形式返回 if len(matches) == 0: matches = np.empty((0, 2), dtype=int) else: matches = np.concatenate(matches, axis=0) return matches, np.array(unmatched_detections), np.array(unmatched_trackers)
(八)SORT/deepSORT
上一节给大家介绍了一下多目标跟踪MOT的一些基础知识。SORT和DeepSORT是多目标跟踪中两个知名度比较高的算法。DeepSORT是原团队对SORT的改进版本。现在来解析一下SORT和DeepSORT的基本思路。
1.SORT
SORT核心是卡尔曼滤波和匈牙利匹配两个算法。流程图如下所示,可以看到整体可以拆分为两个部分,分别是匹配过程和卡尔曼预测加更新过程,都用灰色框标出来了。
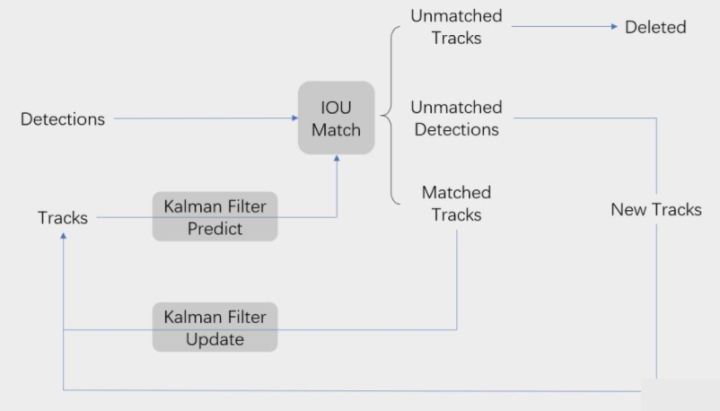
关键步骤:轨迹卡尔曼滤波预测→ 使用匈牙利算法将预测后的tracks和当前帧中的detecions进行匹配(IOU匹配) → 卡尔曼滤波更新
卡尔曼滤波分为两个过程:预测和更新。SORT引入了线性速度模型与卡尔曼滤波来进行位置预测,先进行位置预测然后再进行匹配。运动模型的结果可以用来预测物体的位置。
匈牙利算法解决的是一个分配问题,用IOU距离作为权重(也叫cost矩阵),并且当IOU小于一定数值时,不认为是同一个目标,理论基础是视频中两帧之间物体移动不会过多。在代码中选取的阈值是0.3。scipy库的linear_sum_assignment都实现了这一算法,只需要输入cost_matrix即代价矩阵就能得到最优匹配。
2.DeepSort
DeepSORT是SORT的续作,整体框架没有大改,还是延续了卡尔曼滤波加匈牙利算法的思路,在这个基础上增加了鉴别网络Deep Association Metric。
下图是deepSORT流程图,和SORT基本一样,就多了级联匹配(Matching Cascade)和新轨迹的确认(confirmed)。
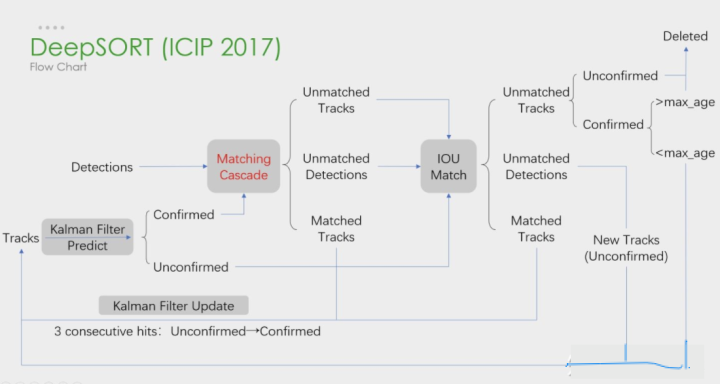
关键步骤:轨迹卡尔曼滤波预测→ 使用匈牙利算法将预测后的tracks和当前帧中的detecions进行匹配(级联匹配和IOU匹配) → 卡尔曼滤波更新
级联匹配流程图如下所示:

其中上半部分就是相似度估计,也就是算这个分配问题的代价函数。下半部分依旧使用匈牙利算法进行检测框和跟踪框的匹配。
(九)多目标追踪实现
在这里我们主要实现了一个多目标跟踪器,管理多个卡尔曼滤波器对象,主要包括以下内容:
-
初始化:最大检测数,目标未被检测的最大帧数
-
目标跟踪结果的更新,即跟踪成功和失败的目标的更新
-
初始化
def __init__(self, max_age=1, min_hits=3): """ 初始化:设置SORT算法的关键参数 """ # 最大检测数:目标未被检测到的帧数,超过之后会被删 self.max_age = max_age # 目标命中的最小次数,小于该次数不返回 self.min_hits = min_hits # 卡尔曼跟踪器 self.trackers = [] # 帧计数 self.frame_count = 0
目标跟踪结果的更新: 该方法实现了SORT算法,输入是当前帧中所有物体的检测框的集合,包括目标的score,输出是当前帧标的跟踪框集合,包括目标的跟踪的id要求是即使检测框为空,也必须对每一帧调用此方法,返回一个类似的输出数组,最后一列是目标对像的id。需要注意的是,返回的目标对象数量可能与检测框的数量不同.
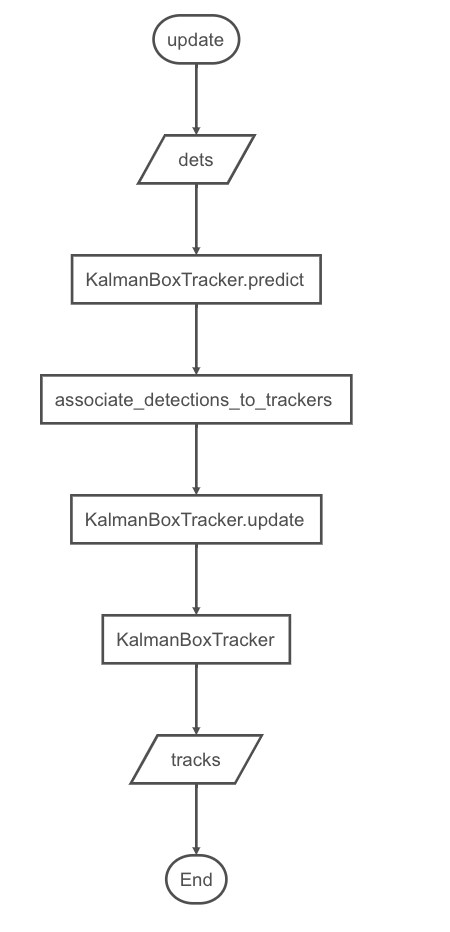
def update(self, dets): self.frame_count += 1 # 在当前帧逐个预测轨迹位置,记录状态异常的跟踪器索引 # 根据当前所有的卡尔曼跟踪器个数(即上一帧中跟踪的目标个数)创建二维数组:行号为卡尔曼滤波器的标识索引,列向量为跟踪框的位置和ID trks = np.zeros((len(self.trackers), 5)) # 存储跟踪器的预测 to_del = [] # 存储要删除的目标框 ret = [] # 存储要返回的追踪目标框 # 循环遍历卡尔曼跟踪器列表 for t, trk in enumerate(trks): # 使用卡尔曼跟踪器t产生对应目标的跟踪框 pos = self.trackers[t].predict()[0] # 遍历完成后,trk中存储了上一帧中跟踪的目标的预测跟踪框 trk[:] = [pos[0], pos[1], pos[2], pos[3], 0] # 如果跟踪框中包含空值则将该跟踪框添加到要删除的列表中 if np.any(np.isnan(pos)): to_del.append(t) # numpy.ma.masked_invalid 屏蔽出现无效值的数组(NaN 或 inf) # numpy.ma.compress_rows 压缩包含掩码值的2-D 数组的整行,将包含掩码值的整行去除 # trks中存储了上一帧中跟踪的目标并且在当前帧中的预测跟踪框 trks = np.ma.compress_rows(np.ma.masked_invalid(trks)) # 逆向删除异常的跟踪器,防止破坏索引 for t in reversed(to_del): self.trackers.pop(t) # 将目标检测框与卡尔曼滤波器预测的跟踪框关联获取跟踪成功的目标,新增的目标,离开画面的目标 matched, unmatched_dets, unmatched_trks = associate_detections_to_trackers(dets, trks) # 将跟踪成功的目标框更新到对应的卡尔曼滤波器 for t, trk in enumerate(self.trackers): if t not in unmatched_trks: d = matched[np.where(matched[:, 1] == t)[0], 0] # 使用观测的边界框更新状态向量 trk.update(dets[d, :][0]) # 为新增的目标创建新的卡尔曼滤波器对象进行跟踪 for i in unmatched_dets: trk = KalmanBoxTracker(dets[i, :]) self.trackers.append(trk) # 自后向前遍历,仅返回在当前帧出现且命中周期大于self.min_hits(除非跟踪刚开始)的跟踪结果;如果未命中时间大于self.max_age则删除跟踪器。 # hit_streak忽略目标初始的若干帧 i = len(self.trackers) for trk in reversed(self.trackers): # 返回当前边界框的估计值 d = trk.get_state()[0] # 跟踪成功目标的box与id放入ret列表中 if (trk.time_since_update < 1) and (trk.hit_streak >= self.min_hits or self.frame_count <= self.min_hits): ret.append(np.concatenate((d, [trk.id + 1])).reshape(1, -1)) # +1 as MOT benchmark requires positive i -= 1 # 跟踪失败或离开画面的目标从卡尔曼跟踪器中删除 if trk.time_since_update > self.max_age: self.trackers.pop(i) # 返回当前画面中所有目标的box与id,以二维矩阵形式返回 if len(ret) > 0: return np.concatenate(ret) return np.empty((0, 5))
我们将上述两个方法封装在一个类中。
(十)yoloV3模型
yoloV3以V1,V2为基础进行的改进,主要有:利用多尺度特征进行目标检测;先验框更丰富;调整了网络结构;对象分类使用logistic代替了softmax,更适用于多标签分类任务。
1.算法简介
YOLOv3是YOLO (You Only Look Once)系列目标检测算法中的第三版,相比之前的算法,尤其是针对小目标,精度有显著提升。
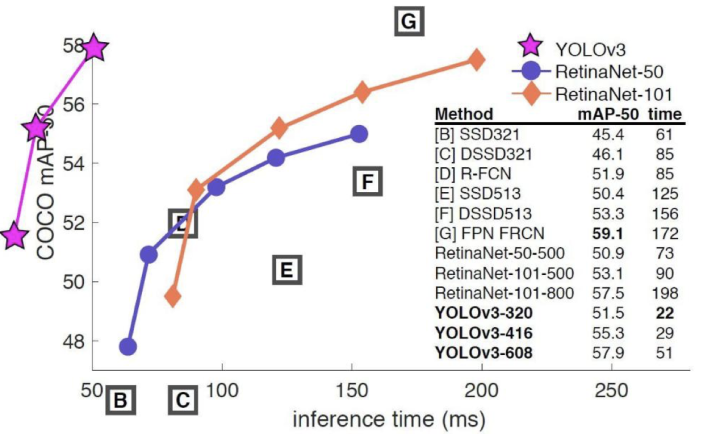
yoloV3的流程如下图所示,对于每一幅输入图像,YOLOv3会预测三个不同尺度的输出,目的是检测出不同大小的目标。
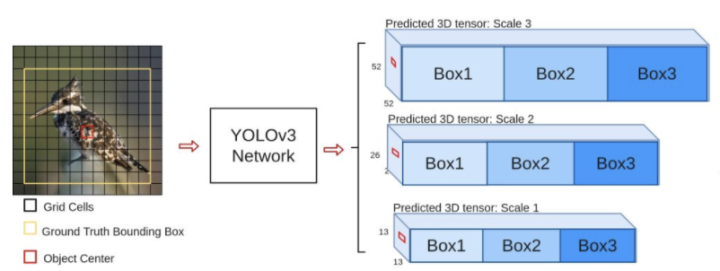
2.多尺度检测
通常一幅图像包含各种不同的物体,并且有大有小。比较理想的是一次就可以将所有大小的物体同时检测出来。因此,网络必须具备能够“看到”不同大小的物体的能力。因为网络越深,特征图就会越小,所以网络越深小的物体也就越难检测出来。
在实际的feature map中,随着网络深度的加深,浅层的feature map中主要包含低级的信息(物体边缘,颜色,初级位置信息等),深层的feature map中包含高等信息(例如物体的语义信息:狗,猫,汽车等等)。因此在不同级别的feature map对应不同的scale,所以我们可以在不同级别的特征图中进行目标检测。如下图展示了多种scale变换的经典方法。
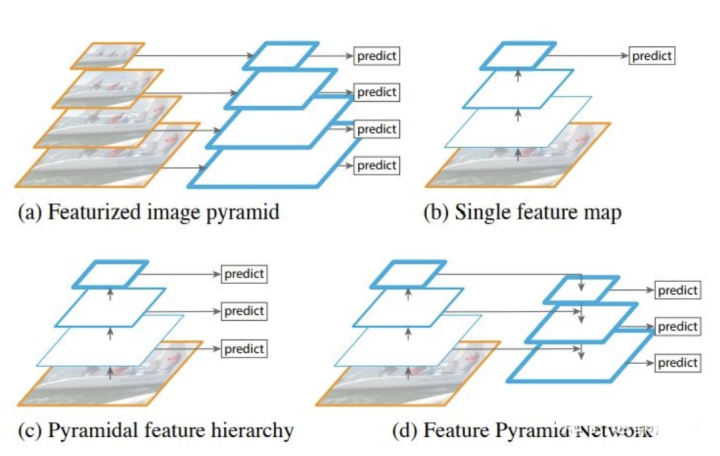
(a) 这种方法首先建立图像金字塔,不同尺度的金字塔图像被输入到对应的网络当中,用于不同scale物体的检测。但这样做的结果就是每个级别的金字塔都需要进行一次处理,速度很慢,在SPPNet使用的就是这种方式。
(b) 检测只在最后一层feature map阶段进行,这个结构无法检测不同大小的物体
(c) 对不同深度的feature map分别进行目标检测。SSD中采用的便是这样的结构。这样小的物体会在浅层的feature map中被检测出来,而大的物体会在深层的feature map被检测出来,从而达到对应不同scale的物体的目的,缺点是每一个feature map获得的信息仅来源于之前的层,之后的层的特征信息无法获取并加以利用。
(d) 与(c)很接近,但不同的是,当前层的feature map会对未来层的feature map进行上采样,并加以利用。因为有了这样一个结构,当前的feature map就可以获得“未来”层的信息,这样的话低阶特征与高阶特征就有机融合起来了,提升检测精度。在YOLOv3中,就是采用这种方式来实现目标多尺度的变换的。
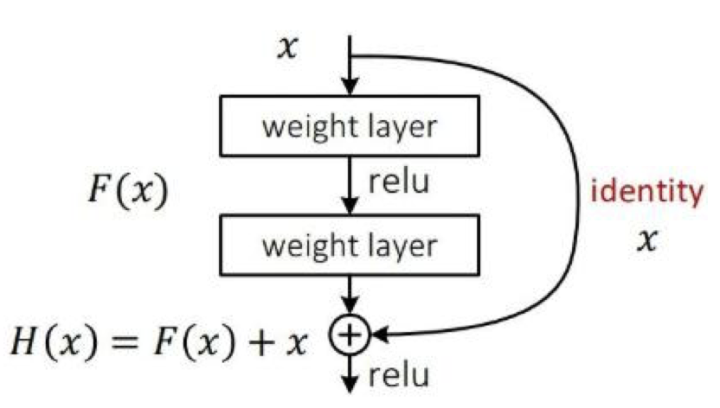
3.网络模型结构
在基本的图像特征提取方面,YOLO3采用了Darknet-53的网络结构(含有53个卷积层),它借鉴了残差网络ResNet的做法,在层之间设置了shortcut,来解决深层网络梯度的问题,shortcut如下图所示:包含两个卷积层和一个shortcut connections。
yoloV3的模型结构如下所示:
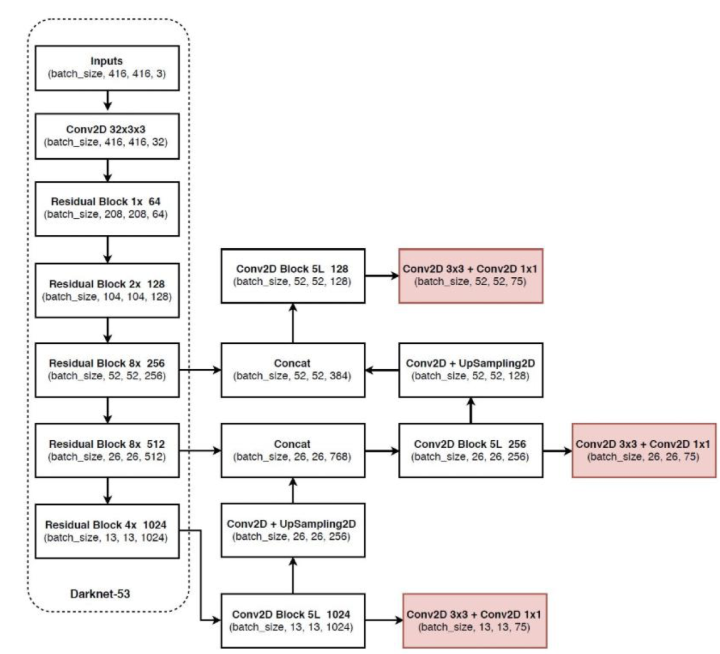
整个v3结构里面,没有池化层和全连接层,网络的下采样是通过设置卷积的stride为2来达到的,每当通过这个卷积层之后图像的尺寸就会减小到一半。残差模块中的1×,2×,8×,8× 等表示残差模块的个数。
4.先验框
yoloV3采用K-means聚类得到先验框的尺寸,为每种尺度设定3种先验框,总共聚类出9种尺寸的先验框。

在COCO数据集这9个先验框是:(10x13),(16x30),(33x23),(30x61),(62x45),(59x119),(116x90),(156x198),(373x326)。在最小的(13x13)特征图上(有最大的感受野)应用较大的先验框(116x90),(156x198),(373x326),适合检测较大的对象。中等的(26x26)特征图上(中等感受野)应用中等的先验框(30x61),(62x45),(59x119),适合检测中等大小的对象。较大的(52x52)特征图上(较小的感受野)应用,其中较小的先验框(10x13),(16x30),(33x23),适合检测较小的对象。
直观上感受9种先验框的尺寸,下图中蓝色框为聚类得到的先验框。黄色框式ground truth,红框是对象中心点所在的网格。

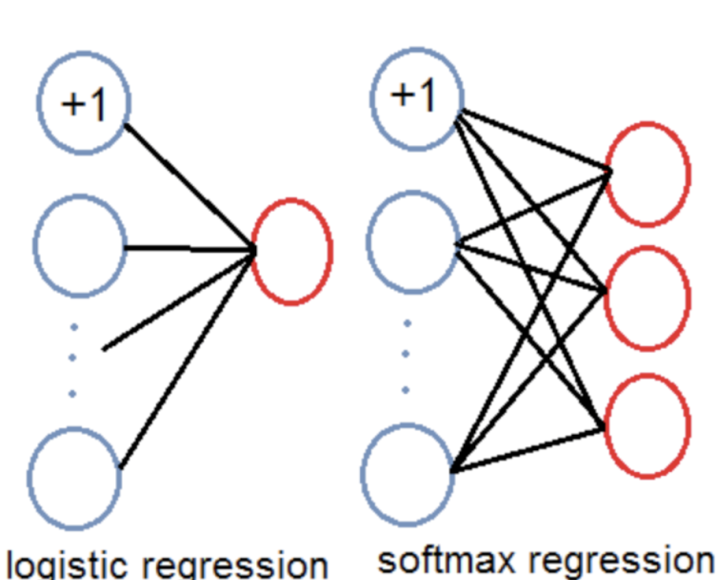
5.ligistic回归
预测对象类别时不使用softmax,而是被替换为一个1x1的卷积层+logistic激活函数的结构。使用softmax层的时候其实已经假设每个输出仅对应某一个单个的class,但是在某些class存在重叠情况(例如woman和person)的数据集中,使用softmax就不能使网络对数据进行很好的预测。
6.yoloV3模型的输入与输出
YoloV3的输入输出形式如下图所示:
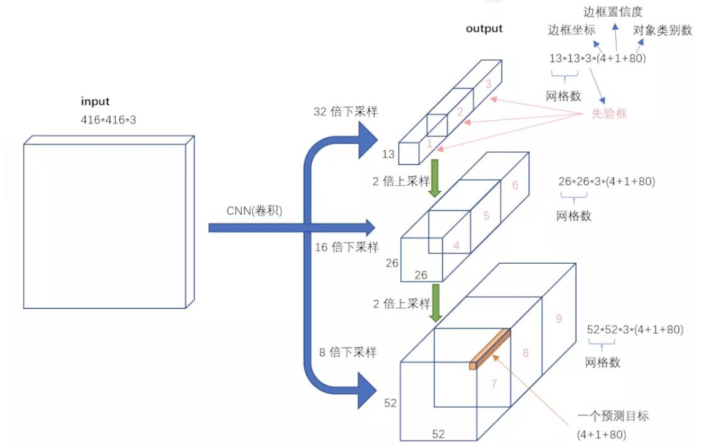
输入416×416×3的图像,通过darknet网络得到三种不同尺度的预测结果,每个尺度都对应N个通道,包含着预测的信息;
每个网格每个尺寸的anchors的预测结果。
YOLOv3共有13×13×3 + 26×26×3 + 52×52×3个预测 。每个预测对应85维,分别是4(坐标值)、1(置信度分数)、80(coco类别概率)。
(十一)基于yoloV3的目标检测
在这里我们进行的目标检测是基于OPenCV的利用yoloV3进行目标检测,不涉及yoloV3的模型结构、理论及训练过程,只是利用训练好的模型进行目标检测,整个流程如下:
基于OPenCV中的DNN模块
-
加载已训练好的yolov3模型及其权重参数
-
将要处理的图像转换成输入到模型中的blobs
-
利用模型对目标进行检测
-
遍历检测结果
-
应用非极大值抑制
-
绘制最终检测结果,并存入到ndarray中,供目标追踪使用。
代码如下:
1.加载yolov3模型及其权重参数
# 1.加载可以识别物体的名称,将其存放在LABELS中,一共有80种,在这我们只使用car labelsPath = "./yolo-coco/coco.names" LABELS = open(labelsPath).read().strip().split("\n") # 设置随机数种子,生成多种不同的颜色,当一个画面中有多个目标时,使用不同颜色的框将其框起来 np.random.seed(42) COLORS = np.random.randint(0, 255, size=(200, 3),dtype="uint8") # 加载已训练好的yolov3网络的权重和相应的配置数据 weightsPath = "./yolo-coco/yolov3.weights" configPath = "./yolo-coco/yolov3.cfg" # 加载好数据之后,开始利用上述数据恢复yolo神经网络 net = cv2.dnn.readNetFromDarknet(configPath, weightsPath) # 获取YOLO中每一网络层的名称:['conv_0', 'bn_0', 'relu_0', 'conv_1', 'bn_1', 'relu_1', 'conv_2', 'bn_2', 'relu_2'...] ln = net.getLayerNames() # 获取输出层在网络中的索引位置,并以列表的形式:['yolo_82', 'yolo_94', 'yolo_106'] ln = [ln[i[0] - 1] for i in net.getUnconnectedOutLayers()]
2.要处理的图像转换成输入到模型中的blobs
# 2. 读取图像 frame = cv2.imread("./images/car1.jpg") # 视频的宽度和高度,即帧尺寸 (W, H) = (None, None) if W is None or H is None: (H, W) = frame.shape[:2] # 根据输入图像构造blob,利用OPenCV进行深度网路的计算时,一般将图像转换为blob形式,对图片进行预处理,包括缩放,减均值,通道交换等 # 还可以设置尺寸,一般设置为在进行网络训练时的图像的大小 blob = cv2.dnn.blobFromImage(frame, 1 / 255.0, (416, 416), swapRB=True, crop=False)
3.利用模型对目标进行检测
# 3.将blob输入到前向网络中,并进行预测 net.setInput(blob) start = time.time() # yolo前馈计算,获取边界和相应的概率 # 输出layerOutsputs介绍: # 是YOLO算法在图片中检测到的bbx的信息 # 由于YOLO v3有三个输出,也就是上面提到的['yolo_82', 'yolo_94', 'yolo_106'] # 因此layerOutsputs是一个长度为3的列表 # 其中,列表中每一个元素的维度是(num_detection, 85) # num_detections表示该层输出检测到bbx的个数 # 85:因为该模型在COCO数据集上训练,[5:]表示类别概率;[0:4]表示bbx的位置信息;[5]表示置信度 layerOutputs = net.forward(ln)
4.遍历检测结果,获得检测框
# 下面对网络输出的bbx进行检查: # 判定每一个bbx的置信度是否足够的高,以及执行NMS算法去除冗余的bbx boxes = [] # 用于存放识别物体的框的信息,包括框的左上角横坐标x和纵坐标y以及框的高h和宽w confidences = [] # 表示识别目标是某种物体的可信度 classIDs = [] # 表示识别的目标归属于哪一类,['person', 'bicycle', 'car', 'motorbike'....] # 4. 遍历每一个输出层的输出 for output in layerOutputs: # 遍历某个输出层中的每一个目标 for detection in output: scores = detection[5:] # 当前目标属于某一类别的概率 classID = np.argmax(scores) # 目标的类别ID confidence = scores[classID] # 得到目标属于该类别的置信度 # 只保留置信度大于0.3的边界框,若图片质量较差,可以将置信度调低一点 if confidence > 0.3: # 将边界框的坐标还原至与原图片匹配,YOLO返回的是边界框的中心坐标以及边界框的宽度和高度 box = detection[0:4] * np.array([W, H, W, H]) (centerX, centerY, width, height) = box.astype("int") # 使用 astype("int") 对上述 array 进行强制类型转换,centerX:框的中心点横坐标, centerY:框的中心点纵坐标,width:框的宽度,height:框的高度 x = int(centerX - (width / 2)) # 计算边界框的左上角的横坐标 y = int(centerY - (height / 2)) # 计算边界框的左上角的纵坐标 # 更新检测到的目标框,置信度和类别ID boxes.append([x, y, int(width), int(height)]) # 将边框的信息添加到列表boxes confidences.append(float(confidence)) # 将识别出是某种物体的置信度添加到列表confidences classIDs.append(classID) # 将识别物体归属于哪一类的信息添加到列表classIDs
5.非极大值抑制
# 5. 非极大值抑制 idxs = cv2.dnn.NMSBoxes(boxes, confidences, 0.5, 0.3)
6.最终检测结果,绘制,并存入到ndarray中,供目标追踪使用
# 6. 获得最终的检测结果 dets = [] # 存放检测框的信息,包括左上角横坐标,纵坐标,右下角横坐标,纵坐标,以及检测到的物体的置信度,用于目标跟踪 if len(idxs) > 0: # 存在检测框的话(即检测框个数大于0) for i in idxs.flatten(): # 循环检测出的每一个box # yolo模型可以识别很多目标,因为我们在这里只是识别车,所以只有目标是车的我们进行检测,其他的忽略 if LABELS[classIDs[i]] == "car": (x, y) = (boxes[i][0], boxes[i][1]) # 得到检测框的左上角坐标 (w, h) = (boxes[i][2], boxes[i][3]) # 得到检测框的宽和高 cv2.rectangle(frame, (x, y), (x+w, y+h), (0,255,0), 2) # 将方框绘制在画面上 dets.append([x, y, x + w, y + h, confidences[i]]) # 将检测框的信息的放入dets中 # 设置数据类型,将整型数据转换为浮点数类型,且保留小数点后三位 np.set_printoptions(formatter={'float': lambda x: "{0:0.3f}".format(x)}) # 将检测框数据转换为ndarray,其数据类型为浮点型 dets = np.asarray(dets) plt.imshow(frame[:,:,::-1])
在视频中进行目标检测:
labelsPath = "./yolo-coco/coco.names" LABELS = open(labelsPath).read().strip().split("\n") # 设置随机数种子,生成多种不同的颜色,当一个画面中有多个目标时,使用不同颜色的框将其框起来 np.random.seed(42) COLORS = np.random.randint(0, 255, size=(200, 3),dtype="uint8") # 加载已训练好的yolov3网络的权重和相应的配置数据 weightsPath = "./yolo-coco/yolov3.weights" configPath = "./yolo-coco/yolov3.cfg" # 加载好数据之后,开始利用上述数据恢复yolo神经网络 net = cv2.dnn.readNetFromDarknet(configPath, weightsPath) # 获取YOLO中每一网络层的名称:['conv_0', 'bn_0', 'relu_0', 'conv_1', 'bn_1', 'relu_1', 'conv_2', 'bn_2', 'relu_2'...] ln = net.getLayerNames() # 获取输出层在网络中的索引位置,并以列表的形式:['yolo_82', 'yolo_94', 'yolo_106'] ln = [ln[i[0] - 1] for i in net.getUnconnectedOutLayers()] """ 视频处理类 """ # 初始化vediocapture类,参数指定打开的视频文件,也可以是摄像头 vs = cv2.VideoCapture('./input/test_1.mp4') # 视频的宽度和高度,即帧尺寸 (W, H) = (None, None) # 视频文件写对象 writer = None try: # 确定获取视频帧数的方式 prop = cv2.cv.CV_CAP_PROP_FRAME_COUNT if imutils.is_cv2() \ else cv2.CAP_PROP_FRAME_COUNT # 获取视频的总帧数 total = int(vs.get(prop)) # 打印视频的帧数 print("[INFO] {} total frames in video".format(total)) except: print("[INFO] could not determine # of frames in video") print("[INFO] no approx. completion time can be provided") total = -1 # 循环读取视频中的每一帧画面 while True: # 读取帧:grabbed是bool,表示是否成功捕获帧,frame是捕获的帧 (grabbed, frame) = vs.read() # 若未捕获帧,则退出循环 if not grabbed: break # 若W和H为空,则将第一帧画面的大小赋值给他 if W is None or H is None: (H, W) = frame.shape[:2] # 根据输入图像构造blob,利用OPenCV进行深度网路的计算时,一般将图像转换为blob形式,对图片进行预处理,包括缩放,减均值,通道交换等 # 还可以设置尺寸,一般设置为在进行网络训练时的图像的大小 blob = cv2.dnn.blobFromImage(frame, 1 / 255.0, (416, 416), swapRB=True, crop=False) # 将blob输入到前向网络中 net.setInput(blob) start = time.time() # yolo前馈计算,获取边界和相应的概率 layerOutputs = net.forward(ln) """ 输出layerOutsputs介绍: 是YOLO算法在图片中检测到的bbx的信息 由于YOLO v3有三个输出,也就是上面提到的['yolo_82', 'yolo_94', 'yolo_106'] 因此layerOutsputs是一个长度为3的列表 其中,列表中每一个元素的维度是(num_detection, 85) num_detections表示该层输出检测到bbx的个数 85:因为该模型在COCO数据集上训练,[5:]表示类别概率;[0:4]表示bbx的位置信息;[5]表示置信度 """ end = time.time() """ 下面对网络输出的bbx进行检查: 判定每一个bbx的置信度是否足够的高,以及执行NMS算法去除冗余的bbx """ boxes = [] # 用于存放识别物体的框的信息,包括框的左上角横坐标x和纵坐标y以及框的高h和宽w confidences = [] # 表示识别目标是某种物体的可信度 classIDs = [] # 表示识别的目标归属于哪一类,['person', 'bicycle', 'car', 'motorbike'....] # 遍历每一个输出层的输出 for output in layerOutputs: # 遍历某个输出层中的每一个目标 for detection in output: scores = detection[5:] # 当前目标属于某一类别的概率 """ # scores = detection[5:] ---> [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. # 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. # 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. # 0. 0. 0. 0. 0. 0. 0. 0.] # scores的大小应该是1*80,因为在训练yolo模型时是80类目标 """ classID = np.argmax(scores) # 目标的类别ID confidence = scores[classID] # 得到目标属于该类别的置信度 # 只保留置信度大于0.3的边界框,若图片质量较差,可以将置信度调低一点 if confidence > 0.3: # 将边界框的坐标还原至与原图片匹配,YOLO返回的是边界框的中心坐标以及边界框的宽度和高度 box = detection[0:4] * np.array([W, H, W, H]) (centerX, centerY, width, height) = box.astype("int") # 使用 astype("int") 对上述 array 进行强制类型转换,centerX:框的中心点横坐标, centerY:框的中心点纵坐标,width:框的宽度,height:框的高度 x = int(centerX - (width / 2)) # 计算边界框的左上角的横坐标 y = int(centerY - (height / 2)) # 计算边界框的左上角的纵坐标 # 更新检测到的目标框,置信度和类别ID boxes.append([x, y, int(width), int(height)]) # 将边框的信息添加到列表boxes confidences.append(float(confidence)) # 将识别出是某种物体的置信度添加到列表confidences classIDs.append(classID) # 将识别物体归属于哪一类的信息添加到列表classIDs # 上一步中已经得到yolo的检测框,但其中会存在冗余的bbox,即一个目标对应多个检测框,所以使用NMS去除重复的检测框 # 利用OpenCV内置的NMS DNN模块实现即可实现非最大值抑制 ,所需要的参数是边界 框、 置信度、以及置信度阈值和NMS阈值 # 第一个参数是存放边界框的列表,第二个参数是存放置信度的列表,第三个参数是自己设置的置信度,第四个参数是关于threshold(阈值 # 返回的idxs是一个一维数组,数组中的元素是保留下来的检测框boxes的索引位置 idxs = cv2.dnn.NMSBoxes(boxes, confidences, 0.5, 0.3) dets = [] # 存放检测框的信息,包括左上角横坐标,纵坐标,右下角横坐标,纵坐标,以及检测到的物体的置信度,用于目标跟踪 if len(idxs) > 0: # 存在检测框的话(即检测框个数大于0) for i in idxs.flatten(): # 循环检测出的每一个box # yolo模型可以识别很多目标,因为我们在这里只是识别车,所以只有目标是车的我们进行检测,其他的忽略 if LABELS[classIDs[i]] == "car": (x, y) = (boxes[i][0], boxes[i][1]) # 得到检测框的左上角坐标 (w, h) = (boxes[i][2], boxes[i][3]) # 得到检测框的宽和高 dets.append([x, y, x + w, y + h, confidences[i]]) # 将检测框的信息的放入dets中 # 设置数据类型,将整型数据转换为浮点数类型,且保留小数点后三位 np.set_printoptions(formatter={'float': lambda x: "{0:0.3f}".format(x)}) # 将检测框数据转换为ndarray,其数据类型为浮点型 dets = np.asarray(dets)
(十二)车流量统计
1.基于虚拟线圈法的车辆统计
基于虚拟线圈的车流量统计算法原理与交通道路上的常见的传统的物理线圈类似,由于物理线圈需要埋设在路面之下,因此会有安装、维护费用高,造成路面破坏等问题,而采用基于视频的虚拟线圈的车辆计数方法完全避免了以上问题,且可以针对多个感兴趣区域进行检测。
虚拟线圈车辆计数法的原理是在采集到的交通流视频中,在需要进行车辆计数的道路或路段上设置一条或一条以上的检测线对通过车辆进行检测,从而完成计数工作。检测线的设置原则一般是在检测车道上设置一条垂直于车道线,居中的虚拟线段,通过判断其与通过车辆的相对位置的变化,完成车流量统计的工作。如下图所示,绿色的线就是虚拟检测线:

在该项目中我们进行检测的方法是,计算前后两帧图像的车辆检测框的中心点连线,若该连线与检测线相交,则计数加一,否则计数不变。
那怎么判断两条线段是否相交呢?
假设有两条线段AB,CD,若AB,CD相交,我们可以确定:
1.线段AB与CD所在的直线相交,即点A和点B分别在直线CD的两边;
2.线段CD与AB所在的直线相交,即点C和点D分别在直线AB的两边;
上面两个条件同时满足是两线段相交的充要条件,所以我们只需要证明点A和点B分别在直线CD的两边,点C和点D分别在直线AB的两边,这样便可以证明线段AB与CD相交了。
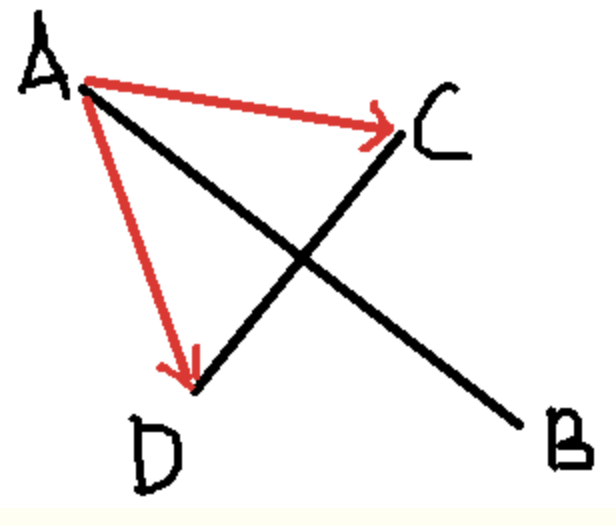
在上图中,线段AB与线段CD相交,于是我们可以得到两个向量AC,AD,C和D分别在AB的两边,向量AC在向量AB的逆时针方向,AB×AC > 0;向量AD在向量AB的顺时针方向,AB×AD < 0,两叉乘结果异号。
这样,方法就出来了:如果线段CD的两个端点C和D,与另一条线段的一个端点(A或B,只能是其中一个)连成的向量,与向量AB做叉乘,若结果异号,表示C和D分别在直线AB的两边,若结果同号,则表示CD两点都在AB的一边,则肯定不相交。
所以我们利用叉乘的方法来判断车辆是否经过检测线。
2.实现
实现车流量检测的代码如下:
1.检测AB和CD两条直线是否相交
# 检测AB和CD两条直线是否相交 def intersect(A, B, C, D): return ccw(A, C, D) != ccw(B, C, D) and ccw(A, B, C) != ccw(A, B, D) # 计算有A,B,C三点构成的向量CA,BA之间的关系, def ccw(A, B, C): return (C[1] - A[1]) * (B[0] - A[0]) > (B[1] - A[1]) * (C[0] - A[0])
遍历跟踪框判断其与检测线是否相交,并进行车辆计数
# 遍历跟踪框 for box in boxes: (x, y) = (int(box[0]), int(box[1])) # 计算跟踪框的左上角坐标 (w, h) = (int(box[2]), int(box[3])) # 计算跟踪框的宽和高 color = [int(c) for c in COLORS[indexIDs[i] % len(COLORS)]] # 对方框的颜色进行设定 cv2.rectangle(frame, (x, y), (w, h), color, 2) # 将方框绘制在画面上 """ 根据当前帧的检测结果,与上一帧检测的检测结过,进行虚拟线圈完成车辆计数:车流量统计 """ if indexIDs[i] in previous: previous_box = previous[indexIDs[i]] # 获取上一帧识别的目标框 (x2, y2) = (int(previous_box[0]), int(previous_box[1])) # 获取上一帧画面追踪框的左上角坐标 (w2, h2) = (int(previous_box[2]), int(previous_box[3])) # 获取上一帧画面追踪框的宽和高 p0 = (int(x + (w - x) / 2), int(y + (h - y) / 2)) # 获取当前帧检测框的中心点 p1 = (int(x2 + (w2 - x2) / 2), int(y2 + (h2 - y2) / 2)) # 获取上一帧检测框的中心点 cv2.line(frame, p0, p1, color, 3) # 将前后两帧图像的检测结果中心连接起来 """ 进行碰撞检测-前后两帧检测框中心点的连线穿过基准线,则进行计数 """ if intersect(p0, p1, line[0], line[1]): # 总计数加1 counter += 1 # 判断行进的方向 if y2 < y: counter_down += 1 # 逆向行驶+1 else: counter_up += 1 # 正向行驶+1
(十三)视频中的车流量统计
前面我们已经完成了视频中车辆的检测功能,下面我们对车辆进行跟踪,并将跟踪结果绘制在视频中。
主要分为以下步骤:
-
对目标进行追踪
-
绘制车辆计数结果
-
将检测结果绘制在视频中并进行保存
1.对目标进行追踪
# yolo中检测结果为0时,传入跟踪器中会出现错误,在这里判断下,未检测到目标时不进行目标追踪 if np.size(dets) == 0: continue else: tracks = tracker.update(dets) # 将检测结果传入跟踪器中,返回当前画面中跟踪成功的目标,包含五个信息:目标框的左上角和右下角横纵坐标,目标的置信度 # 对跟踪器返回的结果进行处理 boxes = [] # 存放tracks中的前四个值:目标框的左上角横纵坐标和右下角的横纵坐标 indexIDs = [] # 存放tracks中的最后一个值:置信度,用来作为memory中跟踪框的Key previous = memory.copy() # 用于存放上一帧的跟踪结果,用于碰撞检测 memory = {} # 存放当前帧目标的跟踪结果,用于碰撞检测 # 遍历跟踪结果,对参数进行更新 for track in tracks: boxes.append([track[0], track[1], track[2], track[3]]) # 更新目标框坐标信息 indexIDs.append(int(track[4])) # 更新置信度信息 memory[indexIDs[-1]] = boxes[-1] # 将跟踪框以key为:置信度,value为:跟踪框坐标形式存入memory中
绘制车辆计数的相关信息
cv2.line(frame, line[0], line[1], (0, 255, 0), 3) # 根据设置的基准线将其绘制在画面上 cv2.putText(frame, str(counter), (30, 80), cv2.FONT_HERSHEY_DUPLEX, 3.0, (255, 0, 0), 3) # 绘制车辆的总计数 cv2.putText(frame, str(counter_up), (130, 80), cv2.FONT_HERSHEY_DUPLEX, 3.0, (0, 255, 0), 3) # 绘制车辆正向行驶的计数 cv2.putText(frame, str(counter_down), (230, 80), cv2.FONT_HERSHEY_DUPLEX, 3.0, (0, 0, 255), 3) # 绘制车辆逆向行驶的计数
将结果保存在视频中
# 未设置视频的编解码信息时,执行以下代码 if writer is None: # 设置编码格式 fourcc = cv2.VideoWriter_fourcc(*"mp4v") # 视频信息设置 writer = cv2.VideoWriter("./output/output.mp4", fourcc, 30, (frame.shape[1], frame.shape[0]), True) # 将处理后的帧写入到视频中 writer.write(frame) # 显示当前帧的结果 cv2.imshow("", frame) # 按下q键退出 if cv2.waitKey(1) & 0xFF == ord('q'): break