函数定义时的几类常见参数:
1、默认参数
看如下代码
def stu_register(name,age,country,course): print("----注册学⽣生信息------") print("姓名:",name)print("age:",age) print("国籍:",country) print("课程:",course)stu_register("王⼭山炮",22,"CN","python_devops")
stu_register("张叫春",21,"CN","linux")
stu_register("刘⽼老老根",25,"CN","linux")
发现 country 这个参数 基本都 是”CN”, 就像我们在⽹网站上注册⽤用户,像国籍这种信息,你不不填写,默认 就会是 中国, 这就是通过默认参数实现的,把country变成默认参数⾮非常简单
def stu_register(name,age,course,country="CN"):
这样,这个参数在调⽤用时不不指定,那默认就是CN,指定了了的话,就⽤用你指定的值。
另外,你可能注意到了了,在把country变成默认参数后,我同时把它的位置移到了了最后⾯面,为什么 呢?
这是语法强制的,默认参数放在其他参数后边,为啥呢? 假设允许这样:
def stu_register(name,age,country="CN",course):
那调⽤用时
stu_register("Mack",22,"Python","US")
你告诉我,第3个参数 python 到底应该给到country还是course呢? ⽆无论给哪个,都会出现歧义,所以 Python语法⼲干脆就让你把默认参数放最后, 解释器在处理理函数时参数时,按优先级,位置参数>默认参数 。
二、关键参数(指定参数)
正常情况下,给函数传参数要按顺序,不不想按顺序就可以⽤用关键参数,只需指定参数名即可(指定了了参数 名的参数就叫关键参数),但记住⼀一个要求就是, 关键参数必须放在位置参数(以位置顺序确定对应关系的参数)之后。
def stu_register(name, age, course='PY' ,country='CN'): print("----注册学⽣生信息------")print("姓名:", name)print("age:", age)print("国籍:", country) print("课程:", course)
调⽤用可以这样( 正确的调用方式: )
stu_register("王⼭山炮",course='PY', age=22,country='JP' )
但绝不可以这样
stu_register("王⼭山炮",course='PY',22,country='JP' )
当然这样也不⾏
stu_register("王⼭山炮",22,age=25,country='JP' )
这样相当于给age赋值2次,会报错!
注意,参数优先级顺序是 位置参数>关键参数
三、⾮固定参数
若你的函数在定义时不不确定⽤用户想传⼊入多少个参数,就可以使⽤用⾮固定参数
def stu_register(name,age,*args): # *args 会把多传⼊入的参数变成⼀一个元组形式 print(name,age,args)stu_register("Alex",22)
#输出
#Alex 22 () #后⾯面这个()就是args,只是因为没传值,所以为空
stu_register("Jack",32,"CN","Python") #输出
# Jack 32 ('CN', 'Python')
还可以有⼀个 **kwargs
def stu_register(name,age,*args,**kwargs): # *kwargs 会把多传⼊入的参数变成⼀一个dict形 式print(name,age,args,kwargs) stu_register("Alex",22)
#输出
#Alex 22 () {}#后⾯面这个{}就是kwargs,只是因为没传值,所以为空
stu_register("Jack",32,"CN","Python",sex="Male",province="ShanDong") #输出
# Jack 32 ('CN', 'Python') {'province': 'ShanDong', 'sex': 'Male'}
1.5 局部变量量与全局变量量
看如下代码
name = "Alex Li" def change_name():
name = "金⻆大王, ⼀个有Tesla的高级屌丝" print("after change", name)
change_name() print("在外面看name改了了么?",name)
# 输出
>>>
after change ⾦⻆大王,⼀个有Tesla的高级屌丝 在外⾯看name改了了么? Alex Li
为什么在函数内部改了name的值后, 在外面print的时候却没有改呢? 因为这两个name根本不是⼀回事
- 在函数中定义的变量称为局部变量,在程序的⼀开始定义的变量称为全局变量。
- 全局变量作用域(即有效范围)是整个程序,局部变量作⽤域是定义该变量的函数。
变量的查找顺序是局部变量>全局变量;- 当全局变量与局部变量同名时,在定义局部变量的函数内,局部变量起作⽤;在其它地⽅方全局变量量起作⽤。
- 在函数⾥是不能直接修改全局变量的。
就是想在函数⾥里里修改全局变量量怎么办?
name = "Alex Li" def change_name():global name #声明⼀一个全局变量量name = "Alex ⼜又名⾦金金⻆角⼤大王,爱⽣生活、爱⾃自由、爱姑娘" print("after change",name)change_name()
print("在外⾯面看看name改了了么?", name)
global name 的作⽤就是要在函数⾥声明全局变量name ,意味着最上⾯的 name = “Alex Li” 即使不写,程序最后面的print也可以打印name。虽然可以改,但不不建议⽤这个global语法,随着代码增多 ,会造成代码调试困难。
1.6 内置函数
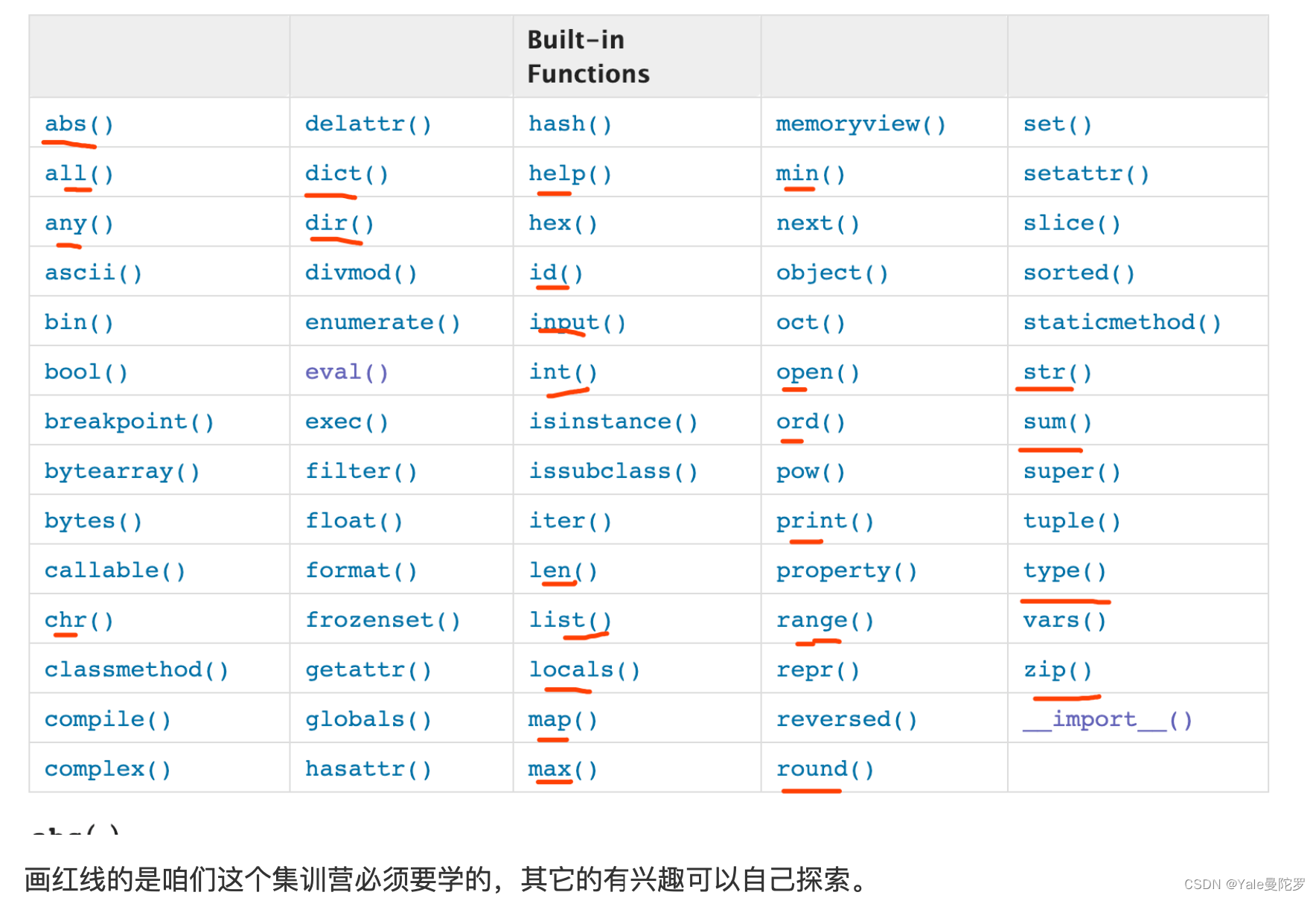
每个函数的作⽤用我都帮你标好了了
1. abs # 求绝对值
2. all #Return True if bool(x) is True for all values x in the iterable.If the iterable is empty, return
True.
3. any #Return True if bool(x) is True for any x in the iterable.If the iterable is empty, return
False.
4. ascii #Return an ASCII-only representation of an object,ascii(“中国”) 返回”‘\u4e2d\u56fd’”
5. bin #返回整数的2进制格式
6. bool # 判断⼀一个数据结构是True or False, bool({}) 返回就是False, 因为是空dict
7. bytearray # 把byte变成 bytearray, 可修改的数组
8. bytes # bytes(“中国”,”gbk”)
9. callable # 判断⼀一个对象是否可调⽤用
10. chr # 返回⼀一个数字对应的ascii字符 , ⽐比如chr(90)返回ascii⾥里里的’Z’
11. classmethod #⾯面向对象时⽤用,现在忽略略
12. compile #py解释器器⾃自⼰己⽤用的东⻄西,忽略略
13. complex #求复数,⼀一般⼈人⽤用不不到
14. copyright #没⽤用
15. credits #没⽤用
16. delattr #⾯面向对象时⽤用,现在忽略略
17. dict #⽣生成⼀一个空dict
18. dir #返回对象的可调⽤用属性19. divmod #返回除法的商和余数 ,⽐比如divmod(4,2),结果(2, 0)
20. enumerate #返回列列表的索引和元素,⽐比如 d = [“alex”,”jack”],enumerate(d)后,得到(0, ‘alex’)
(1, ‘jack’)
21. eval #可以把字符串串形式的list,dict,set,tuple,再转换成其原有的数据类型。
22. exec #把字符串串格式的代码,进⾏行行解义并执⾏行行,⽐比如exec(“print(‘hellworld’)”),会解义⾥里里⾯面的字符
串串并执⾏行行
23. exit #退出程序
24. filter #对list、dict、set、tuple等可迭代对象进⾏行行过滤, filter(lambda x:x>10,
[0,1,23,3,4,4,5,6,67,7])过滤出所有⼤大于10的值
25. float #转成浮点
26. format #没⽤用
27. frozenset #把⼀一个集合变成不不可修改的
28. getattr #⾯面向对象时⽤用,现在忽略略
29. globals #打印全局作⽤用域⾥里里的值
30. hasattr #⾯面向对象时⽤用,现在忽略略
31. hash #hash函数
32. help
33. hex #返回⼀一个10进制的16进制表示形式,hex(10) 返回’0xa’
34. id #查看对象内存地址
35. input
36. int
37. isinstance #判断⼀一个数据结构的类型,⽐比如判断a是不不是fronzenset, isinstance(a,frozenset) 返
回 True or False
38. issubclass #⾯面向对象时⽤用,现在忽略略
39. iter #把⼀一个数据结构变成迭代器器,讲了了迭代器器就明⽩白了了
40. len
41. list
42. locals
43. map # map(lambda x:x**2,[1,2,3,43,45,5,6,]) 输出 [1, 4, 9, 1849, 2025, 25, 36]
44. max # 求最⼤大值
45. memoryview # ⼀一般⼈人不不⽤用,忽略略
46. min # 求最⼩小值
47. next # ⽣生成器器会⽤用到,现在忽略略
48. object #⾯面向对象时⽤用,现在忽略略
49. oct # 返回10进制数的8进制表示
50. open
51. ord # 返回ascii的字符对应的10进制数 ord(‘a’) 返回97,
52. print
53. property #⾯面向对象时⽤用,现在忽略略
54. quit
55. range
56. repr #没什什么⽤用
57. reversed # 可以把⼀一个列列表反转
58. round #可以把⼩小数4舍5⼊入成整数 ,round(10.15,1) 得10.2
59. set
60. setattr #⾯面向对象时⽤用,现在忽略略
61. slice # 没⽤用62. sorted
63. staticmethod #⾯面向对象时⽤用,现在忽略略
64. str
65. sum #求和,a=[1, 4, 9, 1849, 2025, 25, 36],sum(a) 得3949
66. super #⾯面向对象时⽤用,现在忽略略
67. tuple
68. type
69. vars #返回⼀一个对象的属性,⾯面向对象时就明⽩白了了
70. zip #可以把2个或多个列列表拼成⼀一个, a=[1, 4, 9, 1849, 2025, 25, 36],b = [“a”,”b”,”c”,”d”],
list(zip(a,b)) #得结果 [(1, 'a'), (4, 'b'), (9, 'c'), (1849, 'd')]
1.7 模块导⼊入&调⽤用
导入模块有以下几种⽅方式:
import module_a #导⼊
from module import xx # 导入某个模块下的某个⽅法 or ⼦模块
from module.xx.xx import xx as rename #导⼊后⼀个⽅法后重命令
from module.xx.xx import * #导⼊⼀个模块下的所有⽅法,不建议使⽤
module_a.xxx #调⽤
注意:模块⼀旦被调⽤,即相当于执⾏了另外⼀个py⽂文件⾥的代码。
1.8 ⾃定义模块
这个最简单, 创建⼀个.py⽂文件,就可以称之为模块,就可以在另外一个程序⾥导⼊。
1.9 模块的查找路径
有没有发现,⾃⼰写的模块只能在当前路径下的程序里才能导⼊,换一个目录再导⼊自己的模块就报错。说找不到了, 这是为什么? 这与导⼊模块的查找路径有关。
import sys
print(sys.path)
输出(注意不不同的电脑可能输出的不不太⼀一样)
['', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python36.zip', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/lib-dynload', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site- packages']
你导入⼀个模块时,Python解释器会按照上⾯列表顺序去依次到每个⽬录下去匹配你要导⼊的模块名, 只要在⼀个⽬目录下匹配到了了该模块名,就⽴刻导⼊入,不再继续往后找。
注意列表第⼀个元素为空,即代表当前⽬录,所以你⾃己定义的模块在当前目录会被优先导⼊入。
我们自⼰创建的模块若想在任何地⽅都能调用,那就得确保你的模块⽂件⾄少在模块路径的查找列表中。
我们⼀般把自⼰写的模块放在⼀个带有“site-packages”字样的⽬录⾥,我们从⽹上下载安装的各种第三方的模块⼀般都放在这个⽬录。
1.10 第3⽅方开源模块安装
那如何从这个平台上下载代码呢?
- 直接在上⾯面这个⻚页⾯面上点download,下载后,解压并进⼊入⽬目录,执⾏行行以下命令完成安装
编译源码
python setup.py build 安装源码
python setup.py install
- 直接通过pip安装
pip3 install paramiko #paramiko 是模块名
# pip命令会⾃自动下载模块包并完成安装。
软件⼀一般会被⾃自动安装你python安装⽬目录的这个⼦子⽬目录⾥里里
/your_python_install_path/3.6/lib/python3.6/site-packages
pip命令默认会连接在国外的python官⽅方服务器器下载,速度⽐比较慢,你还可以使⽤用国内的⾖豆瓣源,数据 会定期同步国外官⽹网,速度快好多。
pip install -i http://pypi.douban.com/simple/ alex_sayhi --trusted-host pypi.douban.com #alex_sayhi是模块名
-i后⾯跟的是⾖瓣源地址;—trusted-host得加上,是通过网站https安全验证⽤的。
1.11 什么是包(package)
若你写的项⽬较复杂,有很多代码⽂件的话,为了方便便管理,可以⽤包来管理。 ⼀个包其实就是⼀个⽂件⽬录,你可以把属于同一个业务线的代码⽂件都放在同一个包⾥。
如何创建⼀一个包?
只需要在目录下创建⼀个空的 __init__.py ⽂件 , 这个目录就变成了包。这个⽂件叫包的初始化⽂件 ,一般为空,当然也可以写东西,当你调⽤这个包下及其任意⼦包的的任意模块时, 这个 __init__.py ⽂件都会先执⾏。
以下 有a、b 2个包,a2是a的⼦包,b2是b的⼦包。

若在a_module.py模块⾥导⼊b2_mod.py的话,怎么办?
a_module.py的⽂件路径为
/Users/alex/Documents/work/PyProjects/py8days_camp/day6/课件/a/a2/a_module.py
想导入成功,直接写以下代码就可以( 正确调用方式)
from day6.课件.b.b2 import b2_mod
为何从day6开始?⽽不是从 py8days_camp 或 课件 开始呢?
因为你的sys.path列列表里,已经添加了相关的路径
['/Users/alex/Documents/work/PyProjects/py8days_camp/day6/课件/a/a2', '/Users/alex/Documents/work/PyProjects/py8days_camp', # <---就是这个。。
'/Applications/PyCharm.app/Contents/helpers/pycharm_display',
'/Library/Frameworks/Python.framework/Versions/3.6/lib/python36.zip',
'/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6',
'/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/lib-dynload',
'/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site- packages',
'/Applications/PyCharm.app/Contents/helpers/pycharm_matplotlib_backend']
手动添加sys.path路径
你会说,我没有添加这个 ‘/Users/alex/Documents/work/PyProjects/py8days_camp’ 呀,它是怎
么进到 sys.path 里的?
答案是Pycharm自动帮你添加的,若你脱离pycharm再执⾏这个 a_module.py 就会报错了。
Alexs-MacBook-Pro:a2 alex$ python3 a_module.py Traceback (most recent call last):
File "a_module.py", line 7, in <module> from day6.课件.b.b2 import b2_mod
ModuleNotFoundError: No module named 'day6'
不⽤用慌, ⾃己手动添加sys.path路径就可以。
手动添加sys.path路径的实现方式:
import os
import sys
base_dir=os.path.dirname(os.path.dirname(os.path.dirname(os.path.dirname(os.pa th.dirname(os.path.abspath(__file__)))))) # 取到路路 径/Users/alex/Documents/work/PyProjects/py8days_campprint(base_dir)
sys.path.append(base_dir) # 添加到sys.path⾥里里from day6.课件.b.b2 import b2_mod
二、⼏个常⽤Python模块
2.1 系统调⽤用OS模块
os 模块提供了很多允许你的程序与操作系统直接交互的功能。
import os
得到当前工作⽬录,即当前Python脚本工作的⽬录路径: os.getcwd() 返回指定⽬录下的所有⽂件和⽬录名:os.listdir() 函数用来删除⼀个文件:os.remove() 删除多个目录:os.removedirs(r“c:\python”) 检验给出的路径是否是⼀个⽂件:os.path.isfile() 检验给出的路径是否是一个⽬录:os.path.isdir() 判断是否是绝对路路径:os.path.isabs() 检验给出的路径是否真地存:os.path.exists() 返回⼀个路径的⽬录名和文件名:os.path.split() e.g
os.path.split('/home/swaroop/byte/code/poem.txt') 结果: ('/home/swaroop/byte/code', 'poem.txt')分离扩展名:os.path.splitext() 结果:('/usr/local/test', '.py')
e.g os.path.splitext('/usr/local/test.py')获取路径名:os.path.dirname()获得绝对路径: os.path.abspath()获取⽂件名:os.path.basename()运⾏shell命令: os.system()读取操作系统环境变量HOME的值:os.getenv("HOME")返回操作系统所有的环境变量: os.environ 设置系统环境变量,仅程序运⾏行行时有效:os.environ.setdefault('HOME','/home/alex') 给出当前平台使⽤的⾏终止符:os.linesep Windows使用'\r\n',Linux and MAC使用'\n' 指示你正在使用的平台:os.name 对于Windows,它是'nt',⽽对于Linux/Unix⽤用户,它是'posix'重命名:os.rename(old, new) 创建多级⽬录:os.makedirs(r“c:\python\test”) 创建单个⽬录:os.mkdir(“test”) 获取文件属性:os.stat(file) 修改文件权限与时间戳:os.chmod(file) 获取文件⼤小:os.path.getsize(filename) 结合⽬目录名与⽂文件名:os.path.join(dir,filename) 改变⼯工作⽬目录到dirname: os.chdir(dirname) 获取当前终端的⼤大⼩小: os.get_terminal_size() 杀死进程: os.kill(10884,signal.SIGKILL)
2.2 time 模块 在平常的代码中,我们常常需要与时间打交道。在Python中,与时间处理理有关的模块就包括:time,datetime, calendar(很少用,不讲),下⾯分别来介绍。
我们写程序时对间的处理可以归为以下3种:
- 时间的显示,在屏幕显示、记录⽇志等 “2022-03-04” ;
- 时间的转换,⽐如把字符串格式的⽇期转成Python中的⽇日期类型;
- 时间的运算,计算两个日期间的差值等。
在Python中,通常有这⼏种⽅式来表示时间:
-
时间戳(timestamp),表示的是从1970年年1⽉1⽇00:00:00开始按秒计算的偏移量。例例⼦子: 1554864776.161901;
-
格式化的时间字符串,比如“2020-10-03 17:54”;
-
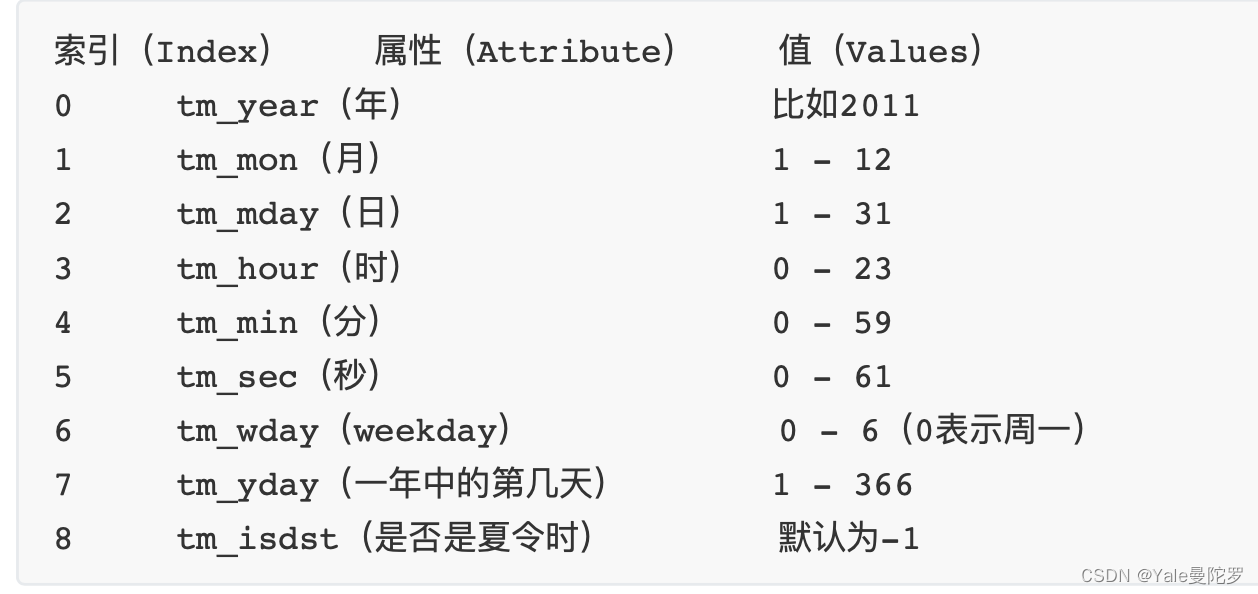
元组(struct_time)共九个元素。由于Python的time模块实现主要调⽤C库,所以各个平台可能
有所不同,mac上:time.struct_time(tm_year=2020, tm_mon=4, tm_mday=10, tm_hour=2, tm_min=53, tm_sec=15, tm_wday=2, tm_yday=100, tm_isdst=0)
time模块的常⽤用方法
-
time.localtime([secs]) :将⼀一个时间戳转换为当前时区的struct_time。若secs参数未提供,
则以当前时间为准。 -
time.gmtime([secs]) :和localtime()⽅方法类似,gmtime()⽅法是将⼀个时间戳转换为UTC时区
(0时区)的struct_time。 -
time.time() :返回当前时间的时间戳。 time.mktime(t) :将⼀个struct_time转化为时间戳。
-
time.sleep(secs) :线程推迟指定的时间运⾏,单位为秒。
-
time.strftime(format[, t]) :把⼀个代表时间的元组或者struct_time(如由 time.localtime()和time.gmtime()返回)转化为格式化的时间字符串。如果t未指定,将传⼊ time.localtime()。
举例: time.strftime(“%Y-%m-%d %X”, time.localtime()) #输出’2017-10-01
12:14:23’
- time.strptime(string[, format]) :把⼀一个格式化时间字符串串转化为struct_time。实际上它
和strftime()是逆操作。
举例: time.strptime(‘2017-10-3 17:54’,”%Y-%m-%d %H:%M”) #输出 time.struct_time(tm_year=2017, tm_mon=10, tm_mday=3, tm_hour=17, tm_min=54, tm_sec=0, tm_wday=1, tm_yday=276, tm_isdst=-1)
字符串转时间格式对应表
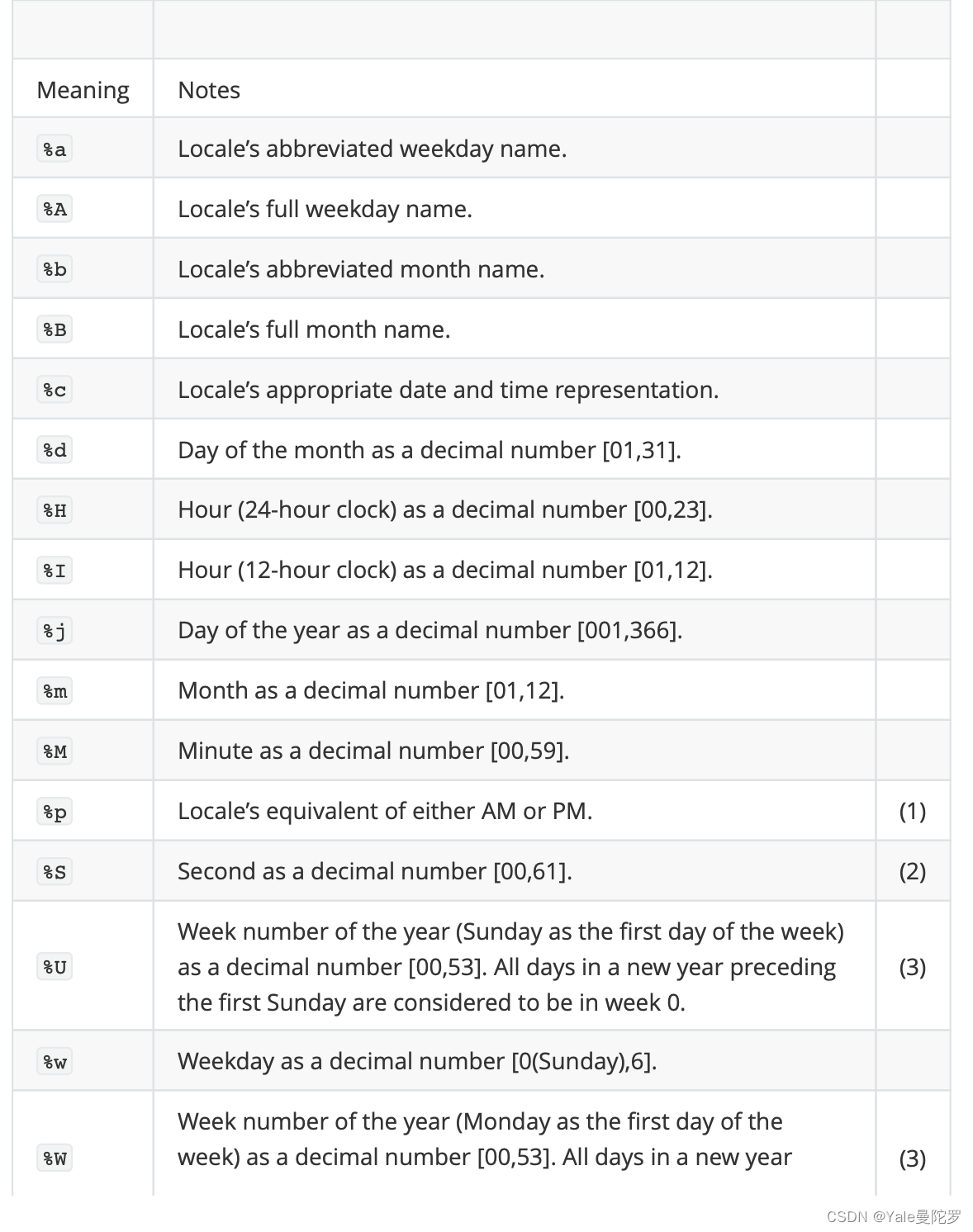
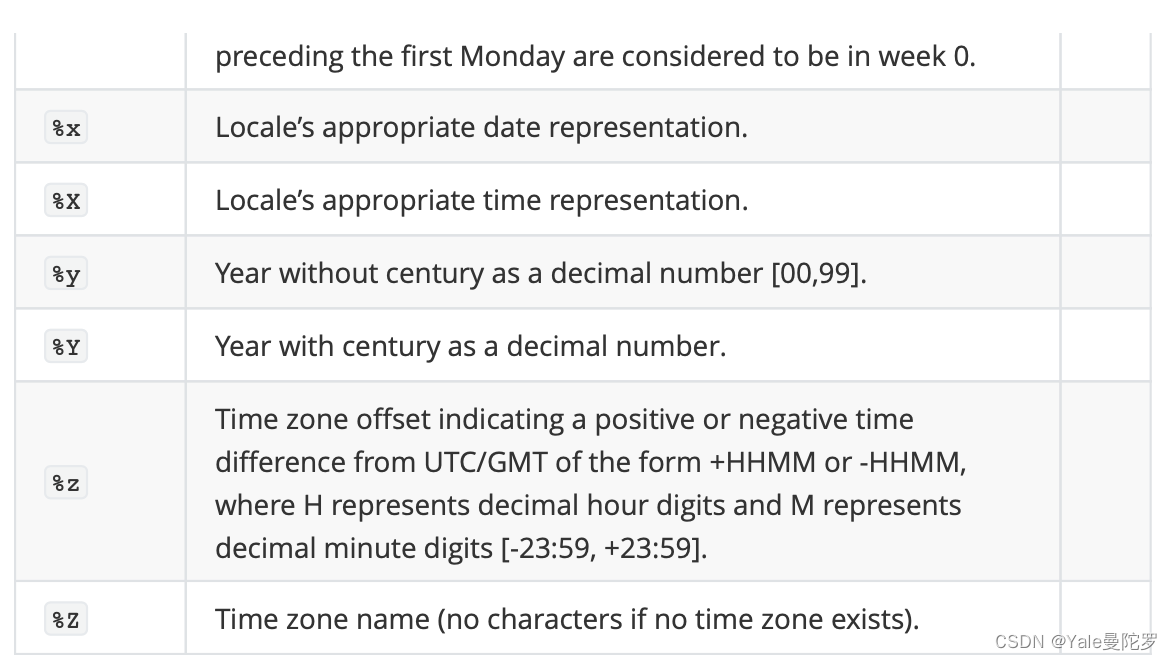
2.3 datetime模块
相⽐于time模块,datetime模块的接⼝则更直观、更容易易调用 datetime模块定义了下面这⼏个类:
- datetime.date:表示⽇日期的类。常⽤用的属性有year, month, day;
- datetime.time:表示时间的类。常⽤用的属性有hour, minute, second, microsecond;
- datetime.datetime:表示⽇日期时间。
- datetime.timedelta:表示时间间隔,即两个时间点之间的⻓长度。
- datetime.tzinfo:与时区有关的相关信息。(这⾥里里不不详细充分讨论该类,感兴趣的童鞋可以参考 python⼿手册)
我们需要记住的⽅方法仅以下⼏几个:
- d=datetime.datetime.now() 返回当前的datetime⽇日期类型, d.timestamp(),d.today(), d.year,d.timetuple()等⽅方法可以调⽤用
- datetime.date.fromtimestamp(322222) 把⼀一个时间戳转为datetime⽇日期类型
- 时间运算
>>> datetime.datetime.now()
datetime.datetime(2017, 10, 1, 12, 53, 11, 821218)
>>> datetime.datetime.now() + datetime.timedelta(4) #当前时间 +4天
datetime.datetime(2017, 10, 5, 12, 53, 35, 276589)
>>> datetime.datetime.now() + datetime.timedelta(hours=4) #当前时间+4⼩小时
datetime.datetime(2017, 10, 16, 53, 42, 876275)
- 时间替换
>>> d.replace(year=2999,month=11,day=30) datetime.date(2999, 11, 30)
2.4 random随机数
程序中有很多地⽅需要⽤到随机字符,⽐如登录⽹站的随机验证码,通过random模块可以很容易⽣成随机字符串。
>>> random.randrange(1,10) #返回1-10之间的⼀一个随机数,不不包括10
>>> random.randint(1,10) #返回1-10之间的⼀一个随机数,包括10
>>> random.randrange(0, 100, 2) #随机选取0到100间的偶数
>>> random.random() #返回⼀一个随机浮点数
>>> random.choice('abce3#$@1') #返回⼀一个给定数据集合中的随机字符 '#'
>>> random.sample('abcdefghij',3) #从多个字符中选取特定数量量的字符 ['a', 'd', 'b']
#⽣生成随机字符串串
>>> import string
>>> ''.join(random.sample(string.ascii_lowercase + string.digits, 6)) '4fvda1'
#洗牌
>>> a
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> random.shuffle(a)
>>> a
[3, 0, 7, 2, 1, 6, 5, 8, 9, 4]
2.5 序列列化json模块 什什么是Json?
JSON(JavaScriptObject Notation, JS 对象简谱) 是⼀种轻量量级的数据交换格式。它采⽤完全独⽴立于编程语⾔的文本格式来存储和表示数据。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语⾔。 易于⼈人阅读和编写,同时也易于机器解析和⽣生成,并有效地提升⽹络传输效率。
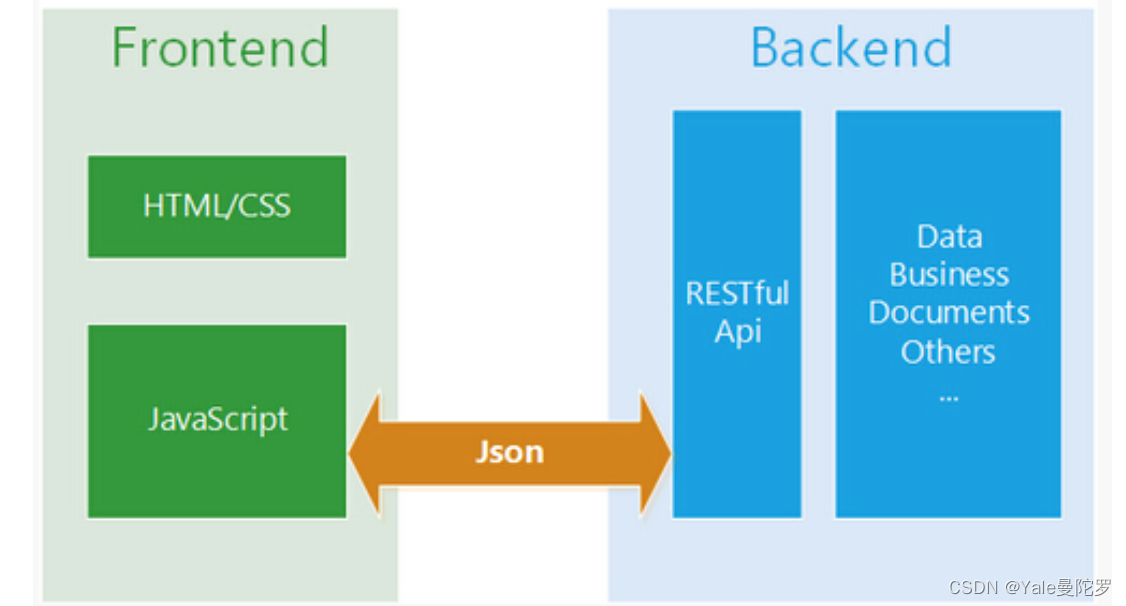
Json的作⽤用是⽤用于不不同语⾔言接⼝口间的数据交换,⽐比如你把python的list、dict直接扔给javascript, 它是解 析不不了了的。2个语⾔言互相谁也不不认识。Json就像是计算机界的英语 ,可以帮各个语⾔言之间实现数据类型 的相互转换。
JSON⽀支持的数据类型
Python中的字符串串、数字、列列表、字典、集合、布尔 类型,都可以被序列列化成JSON字符串串,被其它任何编程语⾔言解析
什么是序列化?
序列列化是指把内存⾥里里的数据类型转变成字符串串,以使其能存储到硬盘或通过⽹网络传输到远程,因为硬盘 或⽹网络传输时只能接受bytes
为什么要序列化?
你打游戏过程中,打累了了,停下来,关掉游戏、想过2天再玩,2天之后,游戏⼜从你上次停⽌的地方继续运⾏,你上次游戏的进度肯定保存在硬盘上了了,是以何种形式呢?游戏过程中产⽣生的很多临时数据是不规律律的,可能在你关掉游戏时正好有10个列列表,3个嵌套字典的数据集合在内存⾥,需要存下来?你如何存?把列表变成⽂文件⾥的多⾏多列形式?那嵌套字典呢?根本没法存。所以,若是有种办法可以直接把内存数据存到硬盘上,下次程序再启动,再从硬盘上读回来,还是原来的格式的话,那是极好的。
⽤于序列化的两个模块
json,⽤于字符串和 python数据类型间进⾏转换pickle,⽤于python特有的类型和python的数据类型间进⾏转换。
pickle
模块提供了了四个功能:dumps、dump、loads、load
import pickle
data = {'k1':123,'k2':'Hello'}
# pickle.dumps 将数据通过特殊的形式转换位只有python语⾔言认识的字符串串
p_str = pickle.dumps(data) # 注意dumps会把数据变成bytes格式 print(p_str)
# pickle.dump 将数据通过特殊的形式转换位只有python语⾔言认识的字符串串,并写⼊入⽂文件 with open('result.pk',"wb") as fp:
pickle.dump(data,fp)
# pickle.load 从⽂文件⾥里里加载 f = open("result.pk","rb") d = pickle.load(f) print(d)
json
Json模块也提供了了四个功能:dumps、dump、loads、load,用法跟pickle一致。
import json
# json.dumps 将数据通过特殊的形式转换位所有程序语⾔言都认识的字符串串
j_str = json.dumps(data) # 注意json dumps⽣生成的是字符串串,不不是bytes print(j_str)
#dump⼊入⽂文件
with open('result.json','w') as fp:
json.dump(data,fp) #从⽂文件⾥里里load
with open("result.json") as f: d = json.load(f)
print(d)
json vs pickle:
JSON:
- 优点:跨语⾔言(不不同语⾔言间的数据传递可⽤用json交接)、体积⼩小
- 缺点:只能⽀支持int\str\list\tuple\dict
Pickle: - 优点:专为python设计,⽀支持python所有的数据类型
- 缺点:只能在python中使⽤用,存储数据占空间⼤大
2.6 Excel处理理模块 第3⽅方开源模块,安装
pip install openpyxl
2.6.1 打开⽂文件
⼀、创建
from openpyxl import Workbook # 实例例化
wb = Workbook()
# 获取当前active的sheet
ws = wb.active
print(sheet.title) # 打印sheet表名 sheet.title = "salary luffy" # 改sheet 名
⼆、打开已有⽂件
>>> from openpyxl import load_workbook >>> wb2 = load_workbook('⽂文件名称.xlsx')
2.6.2 写数据
# 方式⼀一:数据可以直接分配到单元格中(可以输⼊入公式) sheet["C5"] = "Hello 金⻆大王"
sheet["C7"] = "Hello ⾦金金⻆角⼤大王2"
# 方式⼆:可以附加⾏,从第一列开始附加(从最下⽅空⽩处,最左开始)(可以输入多行) sheet.append([1, 2, 3])
# 方式三:Python 类型会被⾃自动转换
sheet['A3'] = datetime.datetime.now().strftime("%Y-%m-%d")
2.6.3 选择表
# sheet 名称可以作为 key 进⾏行行索引
ws3 = wb["New Title"]
ws4 = wb.get_sheet_by_name("New Title")
print(wb.get_sheet_names()) # 打印所有的sheet sheet = wb.worksheets[0] # 获得第1个sheet
2.6.4 保存表
wb.save('⽂文件名称.xlsx')
2.6.5 遍历表数据
- 按⾏遍历
for row in sheet: # 循环获取表数据for cell in row: # 循环获取每个单元格数据print(cell.value, end=",") print()
- 按列遍历
# A1, A2, A3这样的顺序
for column in sheet.columns:for cell in column: print(cell.value,end=",")print()
遍历指定⾏&列
# 从第2⾏行行开始⾄至第5⾏行行,每⾏行行打印5列列
for row in sheet.iter_rows(min_row=2,max_row=5,max_col=5):for cell in row: print(cell.value,end=",")print()
遍历指定⼏列的数据
取得第2-第5列的数据
for col in sheet.iter_cols(min_col=2,max_col=5,): for i in col:print(i.value,end=",") print()
2.6.6 删除⼯工作表
# ⽅式⼀
wb.remove(sheet)
# 方式⼆
del wb[sheet]
2.6.7 设置单元格样式
⼀、需导⼊的类
from openpyxl.styles import Font, colors, Alignment
⼆、字体
下面的代码指定了等线24号,加粗斜体,字体颜⾊红色。直接使⽤cell的font属性,将Font对象赋值给它。
bold_itatic_24_font = Font(name='等线', size=24, italic=True, color=colors.RED, bold=True) # 声明样式
sheet['A1'].font = bold_itatic_24_font # 给单元格设置样式
三、对⻬⽅式
也是直接使用cell的属性aligment,这⾥指定垂直居中和⽔平居中。除了了center,还可以使⽤right、left 等参数。
# 设置B1中的数据垂直居中和⽔水平居中
sheet['B1'].alignment = Alignment(horizontal='center', vertical='center')
四、设置⾏⾼&列宽
# 第2行行高
sheet.row_dimensions[2].height = 40
# C列列宽
sheet.column_dimensions['C'].width = 30
2.7 邮件发送smtplib
SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议,它是⼀组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转⽅式。
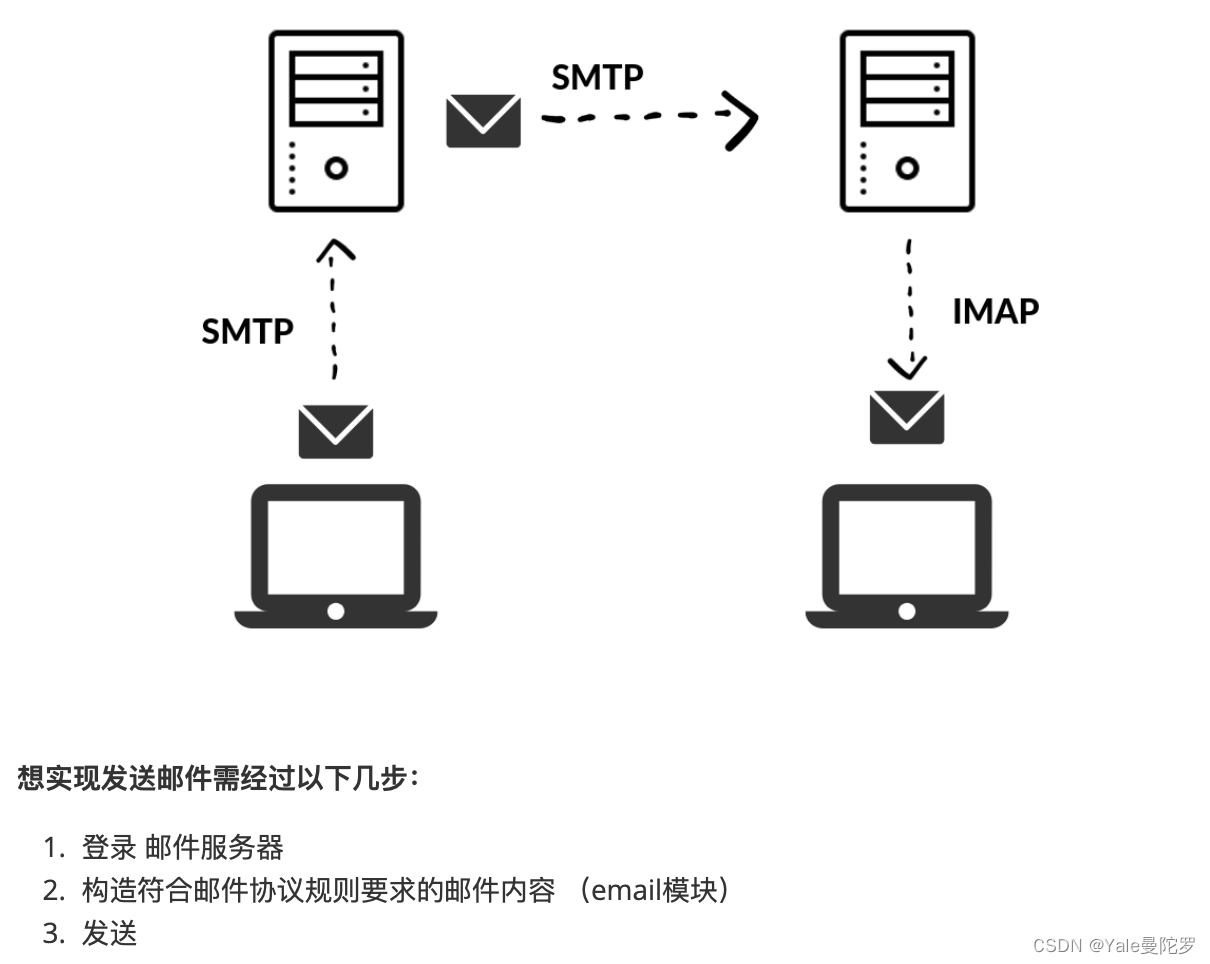
Python对SMTP⽀持有 smtplib 和 email 两个模块, email 负责构造邮件, smtplib 负责发送邮件,它 对smtp协议进⾏了简单的封装。
2.7.1 发送一封最简单的信语法如下:
import smtplib
from email.mime.text import MIMEText # 邮件正⽂文
from email.header import Header # 邮件头
# 登录邮件服务器器
smtp_obj = smtplib.SMTP_SSL("smtp.exmail.qq.com", 465) # 发件人邮箱中的SMTP服务器,端⼝口是25
smtp_obj.login("nami@luffycity.com", "xxxx-sd#gf") # 括号中对应的是发件人邮箱账号、邮箱密码
#smtp_obj.set_debuglevel(1) # 显示调试信息
# 设置邮件头信息
msg = MIMEText("Hello, ⼩小哥哥,约么?800上⻔门,新到学⽣生妹...", "plain", "utf-8") msg["From"] = Header("来⾃自娜美的问候","utf-8") # 发送者
msg["To"] = Header("有缘⼈人","utf-8") # 接收者
msg["Subject"] = Header("娜美的信","utf-8") # 主题
# 发送
smtp_obj.sendmail("nami@luffycity.com", ["alex@luffycity.com", "317822232@qq.com"], msg.as_string())
2.7.2 发送HTML格式的邮件
只需要改⼀下 MIMEText() 第2个参数为 html 就可以
# 设置邮件头信息 mail_body = '''<h5>hello,⼩小哥哥</h5> <p>⼩哥哥,约么?800,新到学⽣妹.. <a href="http://wx1.sinaimg.cn/mw1024/5ff6135fgy1gdnghz2vbsg205k09ob2d.gif">这是我 的照⽚片</a></p></p> '''msg = MIMEText(mail_body, "html", "utf-8")
2.7.3 在HTML⽂本中插入图⽚
# -*- coding:utf-8 -*-
# created by Alex Li - 路路⻜飞学城import smtplib
from email.mime.image import MIMEImage
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
from email.header import Header
# 登录邮件服务器器
smtp_obj = smtplib.SMTP_SSL("smtp.exmail.qq.com", 465) # 发件⼈人邮箱中的SMTP服务 器器,端⼝口是25
smtp_obj.login("nami@luffycity.com", "333dsfsf#$#") # 括号中对应的是发件⼈人邮箱账 号、邮箱密码
smtp_obj.set_debuglevel(1) # 显示调试信息
# 设置邮件头信息 mail_body = '''<h5>hello,⼩小哥哥</h5> <p>小哥哥,约么?800,新到学⽣妹.. <p><img src="cid:image1"></p>
</p> '''
msg_root = MIMEMultipart('related') # 允许添加附件、图⽚片等
msg_root["From"] = Header("来⾃自娜美的问候","utf-8") # 发送者
msg_root["To"] = Header("有缘⼈人","utf-8") # 接收者
msg_root["Subject"] = Header("娜美的信","utf-8") # 主题
# 允许添加图⽚
msgAlternative = MIMEMultipart('alternative') msgAlternative.attach(MIMEText(mail_body, 'html', 'utf-8'))
msg_root.attach(msgAlternative) # 把邮件正⽂文内容添加到msg_root⾥里里
# 加载图⽚,
fp = open('girl.jpg', 'rb')
msgImage = MIMEImage(fp.read())
fp.close()
# 定义图⽚片 ID,在 HTML ⽂文本中引⽤
msgImage.add_header('Content-ID', '<image1>')
msg_root.attach(msgImage) # 添加图⽚片到msg_root对象⾥里里
# 发送
smtp_obj.sendmail("nami@luffycity.com", ["alex@luffycity.com", "317828332@qq.com"], msg_root.as_string())

![[Android实例] android注册 登录+修改帐号密码+添加资料+给指定帐号充值 .....](http://static.oschina.net/uploads/img/201412/01094751_Gkeg.png)

