Coggle 30 Days of ML (23年7月)任务二:数据可视化
任务二:对数据集字符进行可视化,统计标签和字符分布
- 说明:在这个任务中,需要使用Pandas库对数据集的字符进行可视化,并统计数据集中的标签和字符的分布情况,以便更好地理解数据集。
- 实践步骤:
- 使用Pandas库读取和加载数据集。
- 使用Pandas的可视化功能,如柱状图或饼图,对数据集的字符进行可视化展示。
- 使用Pandas的统计功能,如value_counts()方法,统计数据集中的标签和字符的分布情况。
数据读取
与任务一相同,首先利用Pandas库读取和加载数据集
train_data = pd.read_csv('ChatGPT/train.csv')
test_data = pd.read_csv('ChatGPT/test.csv')
数据可视化
接下来进行数据可视化,name字段是顺序是无意义的,所以我们主要是看有关于label字段和content字段的信息
在数据中,我发现有一个比较奇怪的地方,在content字段中,每一个数字都是占4位,以空格为分隔,为了方便操作,我先将其转为数字的数组,“ 0”也变成“0”,把左右两边的空格去掉,方便后续进行统计,统计得到数据如图所示
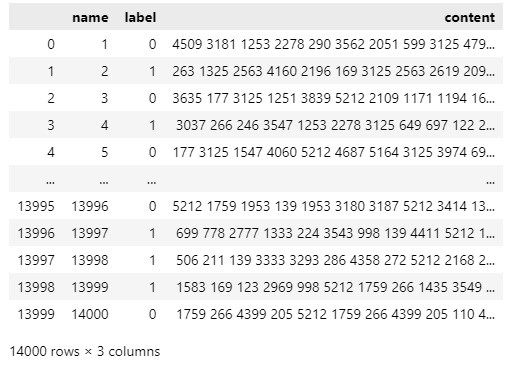
接下来我首先统计了一下content字段的数字列表长度,发现大部分长度实际上都是200,只有少部分长度不是200
train_data['char_count'] = train_data['content'].apply(lambda x:len(x.split(' ')))
print(train_data['char_count'].value_counts())# 绘制字符数量分布柱状图
train_data['char_count'].plot(kind='hist', bins=30, rwidth=0.8)
plt.xlabel('Character Count')
plt.ylabel('Frequency')
plt.title('Distribution of Character Counts')
plt.show()
200 13956
176 3
150 3
1 2
188 2
181 2
198 2
184 2
193 2
167 2
177 2
187 2
166 2
81 1
197 1
180 1
196 1
160 1
134 1
199 1
130 1
102 1
142 1
172 1
173 1
171 1
185 1
195 1
154 1
186 1
161 1
Name: char_count, dtype: int64

处于好奇心,我对这一部分长度不是200的进行筛选,查看有什么关系
train_data[train_data['char_count'] != 200]['label'].value_counts()
1 30
0 14
Name: label, dtype: int64
对于整体的数据来说,几乎大部分都是200的长度,另外不同的数据里面,大部分都是标签为1的数据,所以在这种情况下,数据更可能是gpt生产的
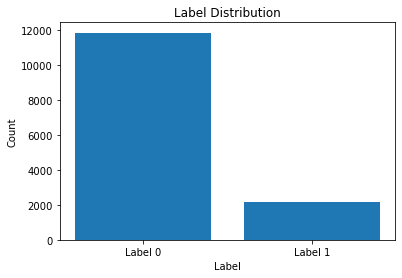
标签分布可视化
接下里对标签分布进行可视化,从结果可以看出,大部分的数据分布额都是Label为0的,数据的比例大概是5:1,所以存在一部分样本不平衡的情况,可以后续进行改进。
# 统计标签分布
label_counts = train_data['label'].value_counts()
print(label_counts)
# 绘制标签分布条形图
plt.bar(label_counts.index, label_counts.values)
plt.xlabel('Label')
plt.ylabel('Count')
plt.title('Label Distribution')# 添加标签名称
label_names = ['Label 0', 'Label 1'] # 用实际的标签名称替换这些示例名称
plt.xticks(label_counts.index, label_names)plt.show()
0 11836
1 2164
Name: label, dtype: int64
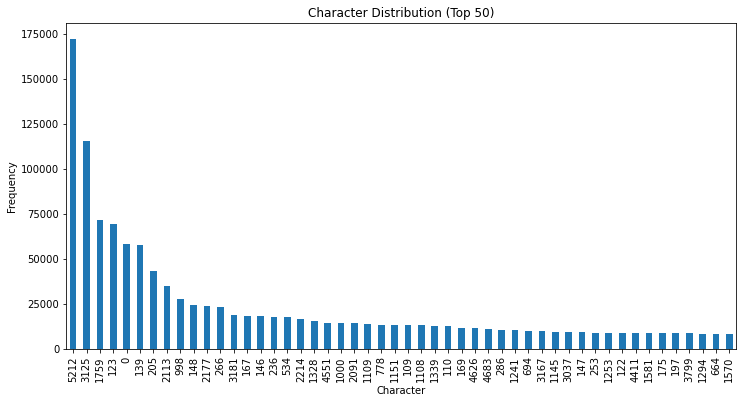
字符分布统计
接下来统计每一个content中的数字的分布,查看出现最多的50个,如下图所示,可以看到3125这个数字出现过很多次,也可以猜测这是一个主语等,后续可以对其进行分析
# 获取字符数量分布数据
char_distribution = train_data['content'].str.split(' ', expand=True).stack().value_counts()# 绘制前50个字符数量分布柱状图
char_distribution[:50].plot(kind='bar', figsize=(12, 6))
plt.xlabel('Character')
plt.ylabel('Frequency')
plt.title('Character Distribution (Top 50)')
plt.show()
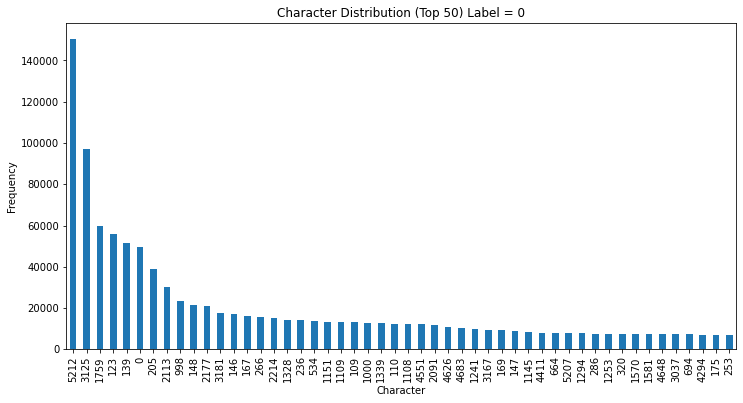
为了查看不同标签数据的分布,我也分别进行筛选查看字符分布统计
Label为0
# 获取字符数量分布数据
char_distribution = train_data[train_data['label']==0]['content'].str.split(' ', expand=True).stack().value_counts()# 绘制前50个字符数量分布柱状图
char_distribution[:50].plot(kind='bar', figsize=(12, 6))
plt.xlabel('Character')
plt.ylabel('Frequency')
plt.title('Character Distribution (Top 50) Label = 0')
plt.show()
Label为1
# 获取字符数量分布数据
char_distribution = train_data[train_data['label']==1]['content'].str.split(' ', expand=True).stack().value_counts()# 绘制前50个字符数量分布柱状图
char_distribution[:50].plot(kind='bar', figsize=(12, 6))
plt.xlabel('Character')
plt.ylabel('Frequency')
plt.title('Character Distribution (Top 50) Label = 1')
plt.show()
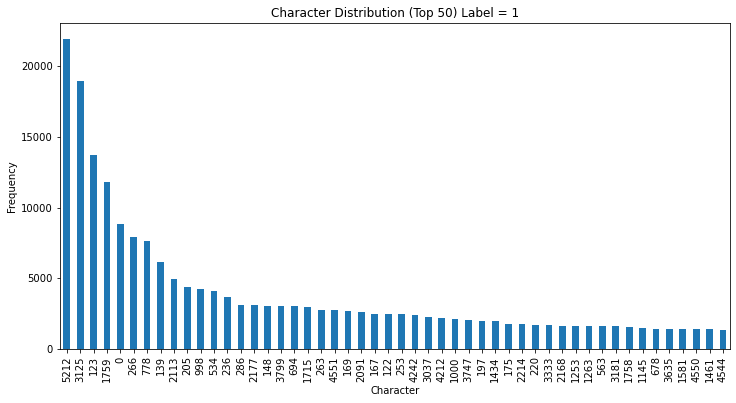
从结果可以看出,label不同的社会,整体的分布在top5的分布差异不大,但是在后续,似乎有不同,可能是因为数据量大小原因,后续可以进行探究和学习