*****
语音交互过程:
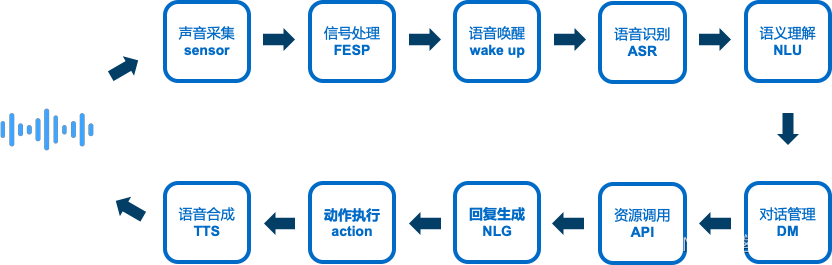
声音采集(sensor)、前端信号处理(FESP)、语音唤醒(wake up)、语音识别(ASR)、语义理解(NLU)、智能对话/对话管理(DM)、资源调用(API)、回复内容生成/自然语言生成(NLG)、动作执行(action)、合成音播报(TTS)
| 项目 | 依赖的资源和能力 | 说明 | 对应语音技术 |
|---|---|---|---|
| 声 音采集 | 基于硬件支持或使用环境的依赖则需要硬件支持声音信号的采集、处理、传输; | 如果大家常说的麦克风阵列、降噪处理、唤醒、拾音、监听等所依赖的算法和处理能力 | 声音采集、声音处理、语音唤醒 |
| 声音处理 | 在硬件和对应算法能力环节完成声音采集和按照标准格式传输后,则需要进行以下环节的处理: (1)语义理解,完成声音到可执行命令的转化过程; (2)完成命令转换后,基于当前的环境、场景等条件进行有效的智能对话管理和分发; (3)选择比较合适方案进行后面环节的资源调取、处理,然后把结果告诉下一个环节。 | 在这个过程会涉及大家常见的:语音识别、语义理解、处理、对话管理、资源调用、生成回复结果和动作执行,这个环节则是整个语音交互系统的中枢,这个环节完成处理和结果生成,然后再通知下个环节来进行执行 | 语音识别、语义理解、对话管理、资源调用、回复生成 |
| 结果执行 | 在拿到上一个环节的结果后,则接下进行结果对应内容的播报、动作执行,完成这一轮的处理过程。 | 这个环节则是执行动作和播报结果的过程。 | 动作执行、语音合成 |
******
4.1 前端信号处理
语音交互之前对采集到的单路或多路音频信号进行处理,用以提取到用户输入、交互部分的音频信号,降低噪声干扰,提升信噪比,降低后端语音识别或语音唤醒的难度。
音频信号处理的好坏,会直接影响到后续语音识别的交互体验。
4.2 语音唤醒
当设备处于休眠状态也能检测到特定的词汇,从休眠状态进入到等待用户输入指令的状态,这种在连续实时检测出说话人特定片段的能力,我们称之为语音唤醒。
4.3 语音识别
目标是以计算机自动将人类的语音内容转换为相应的文字。
4.4 语义理解
也称之为自然语言理解,自然语言理解是研究如何让电脑读懂人类语言的一门技术,是自然语言处理技术中最困难的一项。
其中语义理解部分的处理过程都已经融合在SDK内提供的识别引擎内,开发者无需关注太多。
4.5 对话管理
控制着人机对话的过程,DM 根据对话历史信息,决定此刻对用户的反应。最常见的应用还是任务驱动的多轮对话,用户带着明确的目的如订餐、订票等,用户需求比较复杂,有很多限制条件,可能需要分多轮进行陈述,一方面,用户在对话过程中可以不断修改或完善自己的需求,另一方面,当用户陈述的需求不够具体或明确的时候,机器也可以通过询问、澄清或确认来帮助用户找到满意的结果。对话管理模块也直接决定了整个语音助手交互流程控制,是整个工程最核心和最复杂的模块。
4.6 语音合成
也称之为文本转语音技术(TTS),它是将计算机自己产生的、或外部输入的文字信息转变为可以听得懂的、流利的汉语口语输出的技术。
******
ASR - Automatic Speech Recognition 缩写,指语音识别技术,其目标是将人类语音中的词汇内容转换为计算机可读的输入。
VAD - Voice Activity Detection 缩写,指语音活动检测技术(人声检测),目的是从声音信号流里识别和消除长时间的静音期,以达到在不降低业务质量的情况下节省话路资源的作用,主要用于识别场景下检测人声并送入识别内核。
TTS - Text To Speech 缩写,指语音合成技术,用作将文本转换成自然语音输出。
AEC - Acoustic Echo Cancellation 缩写,指回声消除技术,其目标是通过采集回路音频来消除麦克风采集到的音频部分中设备发出的分部音频信号。
NR - Noise Reduction 缩写,指降噪技术。
DOA - Direction Of Arrival 缩写,指利用麦克风阵列实现声源到达方向估计,也常常称之为声源定位。
BF - Beamforming 缩写,指波束成形技术。
DM - Dialog Management 指对话管理。
NLU - Natural language understanding,指自然语言理解。
NLP - Natural Language Processing,指自然语言处理。
NLG - Natural LanguageGeneration,指自然语言生成。
BSS - Blind source separation,指盲源分离。
*****
Dialog:对话
VUI(Voice User Interface 语音用户界面)+ GUI(Graphical User Interface 图形用户界面)的相辅相成,完成“语音+触控”的完美结合
******
前端信号处理
顾名思义是指在语音交互之前对采集到的单路或多路音频信号进行处理,用以提取到用户输入、交互部分的音频信号,降低噪声干扰,提升信噪比,降低后端语音识别或者语音唤醒的难度。常见的前端信号处理技术包含:VAD(语音活动检测)、NR(降噪)、AEC(声学回声消除)、DOA(声源定位)、BF(波束成形) 、BSS(盲源分离)等。
多种信号处理方案包含:echo(回升消除)、vad(人声检测)、fespCar(车载双麦)、dmasp(车载四麦) 等方案
引擎处理的音频一般按照 :采样率=16000,位宽=16bit 的原始音频
*******
回声消除
回声对消(AEC)的能力,AEC的调用方式主要取决于设备的MIC数量,AEC效果的好坏,更多的取决于回路音频的质量,如回路音频和MIC采集到的音频未对齐,或者回路音频质量比较差,那么AEC的效果都不能得到保证。在车载项目中,好的音频质量,是产品拥有一个好的交互体验的基本前提。
******
语音唤醒
当设备处于休眠状态也能检测到特定的词汇,从而让设备从休眠状态进入到等待用户输入指令的状态的这种在连续语流中实时检测出说话人特定片段的能力,我们称之为语音唤醒。
使用场景
这些年,伴随人工智能的逐步火热,越来越多搭载着相关语音技术能力的设备进入到人们的生活中,产品对唤醒的使用场景要求越来越多,下面是常见的几种唤醒使用场景:
传统唤醒
包含主唤醒和快捷唤醒。其中,
主唤醒方式:设定主唤醒词,如:小爱同学、天猫精灵、你好小驰等,语音输入上述内置的特定唤醒词,则将启动识别,等待用户输入指令。
快捷唤醒方式:不需要先唤醒语音,直接对系统说出快捷命令,系统在不弹出语音交互界面的情况下即可做出对应的处理。如系统接收到“增大音量”、“减小音量”、“放大地图”、“缩小地图”等指令,分别直接进行音量调节和地图缩放的操作。
场景唤醒
意为在不同场景下可直接响应不同的特定唤醒词命令,离开该场景时,对应的唤醒词立即失效。如导航列表场景下,可以响应“上一页”、“下一页”、“第一个”、“第二个”等场景唤醒词,但是退出该列表场景时,这些唤醒词失效。
one-shot 唤醒
直接将唤醒词和命令词一起说出,如:小爱同学,我要听周杰伦的发如雪。客户端需要在唤醒后直接启动识别,并将之前的音频 一起cache下来并送入识别。
zero-shot 唤醒
将常用命令词直接设置为唤醒词,达到用户无感知唤醒。如:导航去天安门。就可以把导航去等高频使用的唤醒词设置为唤醒词,达到用户无感知唤醒交互的目的。
可见即可说
一种新型的个性化交互方案,字面意思就是页面上一些关键信息皆可以直接说,并能准确执行相关命令。如:导航去海底捞,页面上出现海底捞方大城店、海底捞南山店、海底捞南山茂业店选项,用户可直接说:方大城店、南山店、南山茂业店即可。
*******
语音识别
识别引擎提供音频信息转换成相应的识别文本的能力,按照其使用条件又可分为:云端识别、本地识别。开发者应该按照设备的使用场景(网络条件)和需求,合理的选择识别方案。
云端识别
在线识别依托云端识别服务,将大规模的语言模型和声学模型托管在服务端,可承载领域信息复杂的识别需求,云端识别引擎依赖网络,通过网络传输,可支持较大规模词汇的识别能力,如:导航、音乐、信源数据查询等领域的说法。云端识别方案特别适合网络环境稳定的产品选择。
本地识别
本地识别不依赖网络,允许用户内置部分说法(词条)到本地的本地语言模型,因为识别模块属于计算密集度较高的复杂计算,依赖设备的计算性能。因此不推荐将太多的说法内置到本地语言模型内,只推荐将一些离线必须的说法(词条)内置到本地语言模型内,支撑一些离线必备的功能,如车载场景下的 :车身控制,系统控制等说法。
******
混合识别
混合识别的思想是不区分离线在线,同时将音频送入离线和在线识别引擎。待识别结果给出,通过融合算法抉择出最终的识别结果。混合识别其实是融合了云端识别和本地识别两种能力,因为终端用户说法不可预料,复杂的说法可以通过云端识别解决并给出结果,离线内置的必备说法又在离线场景下可以做到基本可用的状态,适合终端设备网络环境不稳定的产品选用。
混合识别有很多优点,但在实际实现的时候,对开发者要求较多,特别需要考虑混合识别融合算法及云端和本地语义一致性的问题。
融合算法
不同的产品在设计融合算法应该有所不同,在设计融合算法的时候多数应该考虑如下因素:
-
云端技能和本地技能取舍,依赖网络的技能如:信源数据查询、音乐、导航等领域建议设置为云端优先,车身控制、系统设置、电话等技能,与网络依赖度不高的技能可以设置为本地优先。
-
需要对选择结果的语义合法性做校验,是否包含正确的语义字段。
-
需要对本地识别结果做置信度校验,本地识别结果应该满足最低置信度要求。(建议置信度阈值 0.63)
-
当云端结果或本地结果不满足语义和置信度要求的时候,可以等待另外一个结果给出后再做抉择。
-
允许异常识别结果出现。
-
融合算法应该考虑设备计算性能,多数设备上本地识别结果给出的延迟应该小于云端识别结果给出延迟。
语义一致性
采用混合策略需要处理最为麻烦的事情是语义一致性的问题,该问题在一些计算性能较差的设备上表现尤为明显,具体的表现不同场景下相同的说法语音助手给出的响应不一致,如:cpu资源不紧张的时候,说打开地图,能正常打开地图。当cpu资源紧张的时候,说打开地图,语音助手播报听不懂等说法。问题原因可能就是对话内只处理了离线语义给出的打开地图说法的语义,而在线识别技能未支持打开地图说法,没有给出语义。
解决方案:
-
调整融合策略,在融合策略内尽量选择包含语义的识别结果给出。
-
在编写离线说法语义和给在线技能语义的时候,保持同一个说法语义的一致性。
******
语音合成
使用场景
TTS 多数是用作将计算机处理的文本转换成人耳可以听到的音频信号,SDk内提供两种TTS能力,一种是离线TTS能力,一种是在线TTS能力,这两种TTS能力开发者在选择的时候,需要注意区分的是,语音助手的使用场景,如网络环境较为稳定,如家居环境,推荐在线TTS引擎(AICloudTTSEngine),如果设备网络环境不稳定,如车载环境,推荐离线TTS引擎(AILocalTTSEngine)。
在线TTS
优点:
1、音色更加自然,更加贴近人声。
2、对设备资源占用较低。
缺点:
1、对网络依存度较高,如设备网络环境不稳定,会存在合成中断等问题。
离线TTS
优点:
1、不依赖网络,网络环境变换不影响播报。
缺点:
1、音色不如在线自然自然
2、合成计算时候,因计算复杂度较高,cpu瞬时资源占用较高。
*******
对话管理
对话管理(Dialog Management, DM) 控制着人机对话的过程,DM 根据对话历史信息,决定此刻用户的反应。最常见的应用还是任务驱动的多轮对话,用户带着明确的目的如订餐、订票等,用户需求比较复杂,有很多限制条件,可能需要分多轮进行陈述。一方面,用户在对话过程中可以不断修改或完善自己的需求,另一方面,当用户的陈述的需求不够具体或明确的时候,机器也可以通过询问、澄清或确认来帮助用户找到满意的结果。
云端DM
在早期大部分对话管理在本地实现(本地 DM),实现简单,响应速度也非常快,但非常依赖于本地对话的业务丰富度,同时很难做到动态更新或定制新的对话场景,只能通过 OTA 来更新迭代。
随着移动互联网4G、5G的快速发展,提供了云端对话管理的能力,配合在线更新能力,可以做到云端对话技能秒级更新。,达到可定制化的场景对话,云端DM也会是后续语音交互的发展趋势。
全双工技术
过去,在人机交互的设计中有一个假设前提:让用户知道是在与机器对话。
基于这个前提,产品经理定义产品时,通常设计苛刻的交互条件或者话术。如频繁使用唤醒词来明确是与机器交互。 而用户对人工智能的预期较高,交互方式具有多样性,更加接近人与人的交互方式。 为了在有限的条件下,尽可能贴近人与人的交互,研究人员开发了各式交互技术。如,oneshot、唤醒打断等。 而使用多种技术,在产品落地中又存在各项技术的相互融合、参数调优等费时、费力的问题,导致落地周期长。
在此技术背景上,研发人员从工程的角度,提出了全双工交互的概念。下图可以很好的解释全双工交互,以及与现有人机交互的对比。
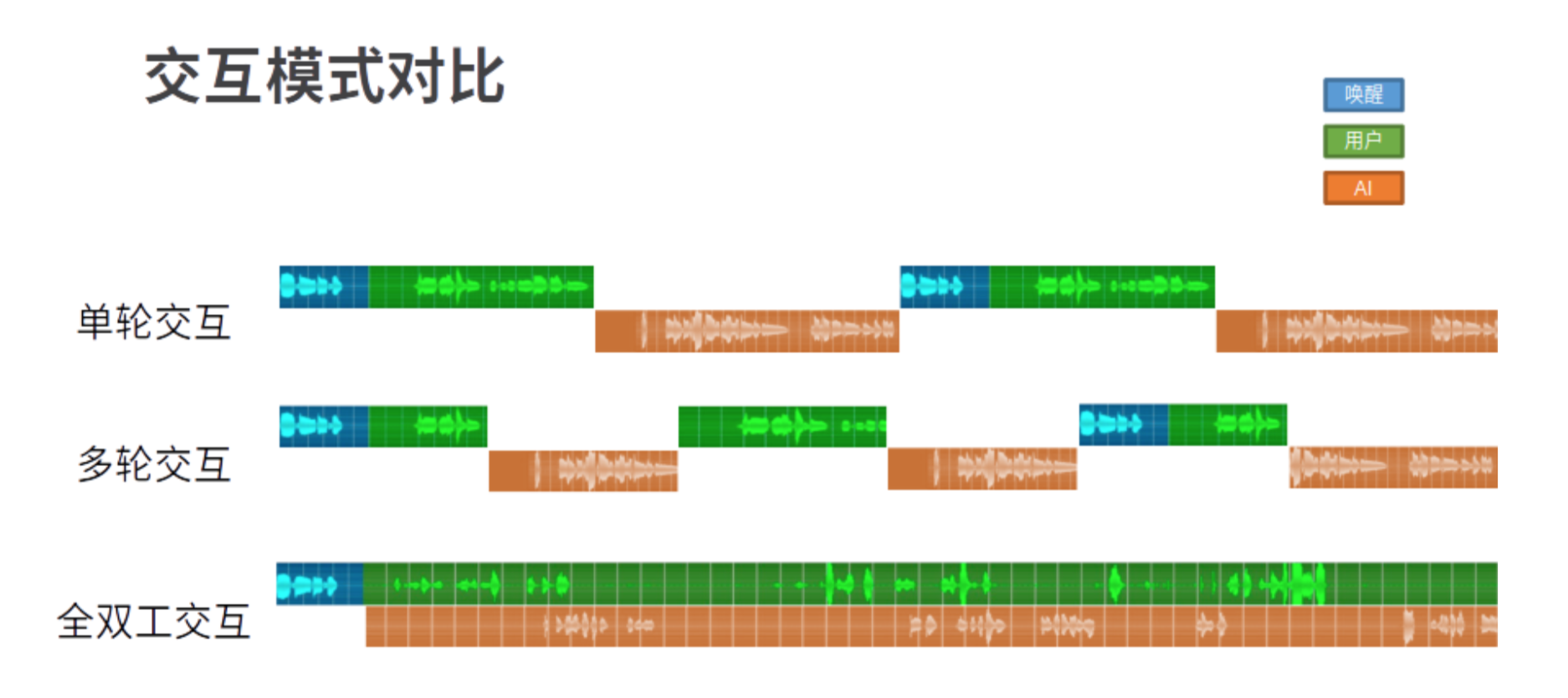
基本特性
1. 连续语音识别
-
功能点:
在全双工交互中,连续音频采集,连续语音识别,用户音频上传与机器内容播报两条链路并行,交互期间没有任何中断。同时大量减少交互的中唤醒的次数,全双工交互只需要在开始交互时唤醒开启。
-
使用场景:
一次唤醒、连续对话,不再是一问一答的模式,不必每次说“你好小驰”来唤醒后再执行指令。
-
实现方式:
识别语义一体化
动态VAD
2. 智能动态断句
-
功能点:
动态断句/犹豫发问,云端根据用户说话节奏和内容,动态断句,根据断句结果送对话。
适用用户:特别适合儿童、老人的交互
-
使用场景:
User:我想听...周杰伦的...七里香
User:查一下...云朵的云字...怎么写
User:窗前...明月光
-
实现方式:
DUI 高级配置
3. 实时语义
-
功能点:
语义打断/交互加速
-
使用场景:
TTS时长过长,用户高频使用的领域,识别错误纠正等。
-
实现方式:
实时语义
4. 拒识
-
功能点:
无效输入拒识
-
使用场景:
周围人的聊天声音
唤醒后与他人说话
设备内发出的人声
-
实现方式:
声学语义一体化
多模态:声学图像一体化
5. 多次请求多次响应
-
功能点:
一次请求多次响应,支持在智能家居等预期延迟较大的领域上,通过先导语或话术策略,保持交互流畅
-
使用场景:
User:打开空调 Sys:好的正在为您打开 Sys:空调已开启
-
实现方式:
-
在云端异步处理
*****
声纹
声纹(Voiceprint),是用电声学仪器显示的携带言语信息的声波频谱,是由多种维度组成的生物特征。具有如下特点:
-
差异性:人类语言的产生是人体语言中枢与发音器官之间一个复杂的生理物理过程,发声器官--舌、牙齿、喉头、肺、鼻腔在尺寸和形态方面每个人的差异很大,所以任何两个人的声纹图谱都有差异
-
稳定性:每个人的语音声学特征既有相对稳定性,又有变异性,不是一成不变的。这种变异可来自生理、病理、心理、模拟、伪装、地区口音,也与环境干扰有关。
尽管如此,由于每个人的发音器官都不尽相同,因此在一般情况下,仍能区别不同的人的声音或判断是否是同一人的声音。
声纹识别
声纹识别(Voiceprint Recognition, VPR),也称为 说话人识别(Speaker Recognition) 技术,以声纹的个体差异特性为基础,如何在语音多变性的背后,挖掘不变的身份特征信息,来识别说话人身份的一项生物特征识别技术
*******
声音复刻
声音复刻(VoiceCopy) 又称声音克隆,即发音者通过录制一些固定文本对应的音频,通过训练得到一个与 发音者声音相似的 tts 音色资源。可以通过 AICloudTTSEngine (云端合成引擎)来合成并播放发音者专属的声音。