语音翻译常用数据集
- Fisher and CALLHOME Spanish-English Speech Translation
【基本信息】
Fisher and CALLHOME Spanish-English Speech Translation数据集是由约翰霍普金斯大学开发的,包含英语参考翻译和语音识别器各种形式的输出,补充了LDC Fisher Spanish (LDC2010T04) 和CALLHOME Spanish音频和转录版本 (LDC96T17)。两者一起组成了一个四向平行的数据集,包括西班牙语音频、转录、语音识别词图(ASR lattices)和大约38小时的语音的英文翻译。
源数据是由LDC开发的Fisher Spanish和CALLOME Spanish语料库,包括各种方言的(主要是母语)西班牙语使用者之间转录的电话对话。Fisher Spanish数据集包含 819 次转录对话,内容涉及各种提供的主题,主要是在陌生人之间,产生大约160小时的在发音级别对齐语音,包含150万个token。CALLHOME Spanish语料库包括120份主要是朋友和家人之间自发对话的转录,产生了大约20小时的在发音级别对齐语音,转录文本仅超过20万个token。
数据被分成训练、开发和测试集,通过亚马逊的Mechanical Turk众包获得翻译。CALLHOME 数据集定义了自己的数据拆分,组织为train、devtest和evltest,这里保留。对于Fisher数据集,产生了四个数据拆分:一个大的训练部分和三个测试集。这些测试集对应于存在四种翻译的数据部分。
【数据集特点】
包含平行语音(西班牙语-英语),转录、翻译和语音识别词图,拓展了两个LDC西班牙语语音集。
【相关文章】
[1]Post, M., Kumar, G., Lopez, A., Karakos, D., Callison-Burch, C., & Khudanpur, S. (2013). Improved Speech-to-Text Translation with the Fisher and Callhome Spanish–English Speech Translation Corpus.
[2]Salesky, E., & Black, A. (2020). Phone Features Improve Speech Translation. ArXiv, abs/2005.13681.
【下载链接】
https://github.com/joshua-decoder/fisher-callhome-corpus
https://joshua.incubator.apache.org/data/fisher-callhome-corpus/
2.Multilingual Speech Translation Corpus (MuST-C)
【基本信息】
MuST-C是一个多语言语音翻译语料库,其规模和质量有助于训练端到端系统将英语语音翻译成多种语言。对于每种目标语言,MuST-C包含数百小时的英语TED演讲语音,这些语音在句子级别自动与其手动转录和翻译对齐。MuST-C目前是用于语音翻译最大的公开可用的多语言语料库。它涵盖八个语言方向,从英语到德语、西班牙语、法语、意大利语、荷兰语、葡萄牙语、罗马尼亚语和俄语。带有预定义的训练、验证和测试数据拆分。
【数据集特点】
英语语音到其他8种语言的转录与翻译,规模大,多语言。
【相关文章】
[1] Gangi, M.A., Cattoni, R., Bentivogli, L., Negri, M., & Turchi, M. (2019). MuST-C: a Multilingual Speech Translation Corpus. NAACL.
[2] S. Indurthi et al., End-end Speech-to-Text Translation with Modality Agnostic Meta-Learning. ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020, pp. 7904-7908, doi: 10.1109/ICASSP40776.2020.9054759.
[3] Zhang, B., Titov, I., Haddow, B., & Sennrich, R. (2020). Adaptive Feature Selection for End-to-End Speech Translation. ArXiv, abs/2010.08518.
【下载链接】
https://docs.google.com/forms/d/e/1FAIpQLSer9jNfUtxbi610n3T6diXRlANBbuzShsCje-GtKs1Sngh0YQ/viewform
3.Europarl-ST
【基本信息】
Europarl-ST,是一个新的多语言SLT语料库,包含语音翻译的音频文本配对样本,包含了来自9种欧洲语言的SLT的配对音频文本样本,共包含72个不同的翻译方向。本文集是根据2008年至2012年期间欧洲议会举行的辩论汇编而成的。开发集、测试集都在3到6小时之间,各语言之间的训练集时长如下图。共8.9G。
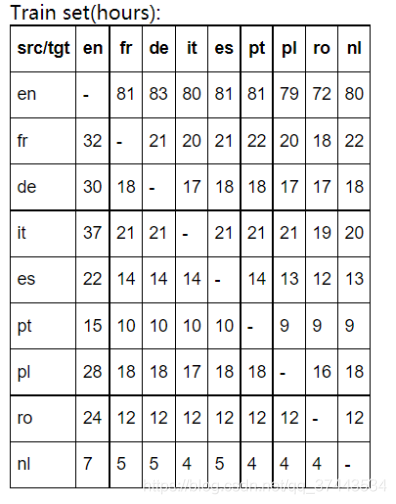
【数据集特点】
多语言,都为欧洲语言,时长相对较小。
【相关文章】
- Iranzo-Sánchez, Javier et al. “Europarl-ST: A Multilingual Corpus for Speech Translation of Parliamentary Debates.” ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (2020): 8229-8233.
- Fantinuoli, C., & Prandi, B. (2021). Towards the evaluation of simultaneous speech translation from a communicative perspective. ArXiv, abs/2103.08364.
【下载链接】
https://www.mllp.upv.es/europarl-st/




