前言:这学期计算机软件课程设计的其中一个题目是使用C语言爬取HTML,本打算使用C语言的CSpidr库来实现,但是因为它的依赖liburi没有找到在哪里安装,所以放弃了这个想法,使用的是curl以及libxml2这两个库,能够提供访问网页以及xpath解析的功能就够用了。
-
项目使用C语言爬取壁纸,爬取的网站是https://wallhaven.cc
-
开发环境使用的是Ubuntu22.04,编译器gcc 11.3,使用makefile管理项目
依赖库的安装:
sudo apt update
sudo apt install curl libxml2-dev
项目结构:
项目由两个文件组成,一个是main.c源代码,另一个是用于makefile编译的makefile文件。
├── main.c
└── Makefile
程序编译并执行完成之后项目目录如下:
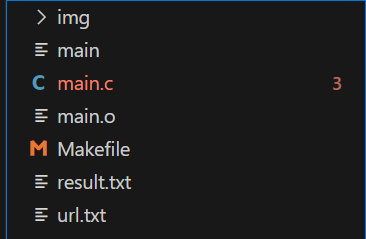
- img:存放爬取的图片
- main main.o可执行文件
- result.txt:图片页面的URL
- url.txt:每张图片的url
流程图如下:
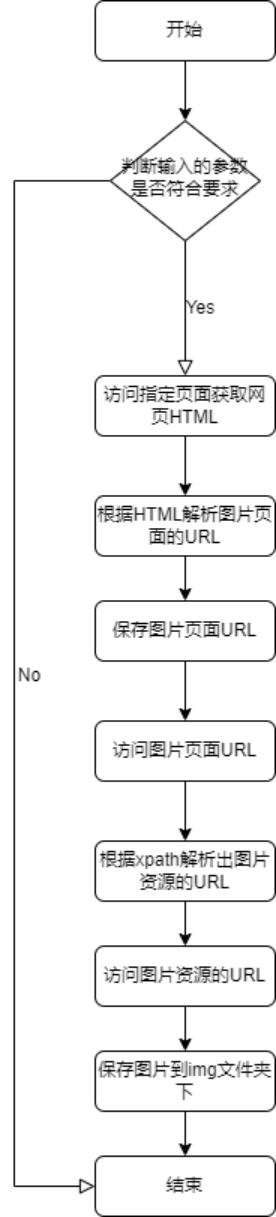
使用说明:
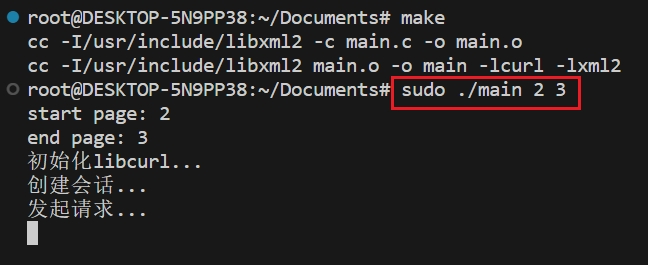
该程序使用make命令对程序进行编译

该程序可以通过命令行参数指定起始页和结束页,命令如下:
sudo ./main start_page end_page
爬取的壁纸

以后再也不缺壁纸啦
源码:
makefile
# CC = gcc
CFLAGS = -I/usr/include/libxml2
LDFLAGS = -lcurl -lxml2TARGET = main
SRCS = main.c
OBJS = $(SRCS:.c=.o)all: $(TARGET)$(TARGET): $(OBJS)$(CC) $(CFLAGS) $(OBJS) -o $(TARGET) $(LDFLAGS)%.o: %.c$(CC) $(CFLAGS) -c $< -o $@clean:rm -f $(OBJS) $(TARGET)源码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <curl/curl.h>
#include <libxml/HTMLparser.h>
#include <libxml/xpath.h>
#include <dirent.h>
#include <sys/stat.h>
#include <unistd.h>void get_imgpage_url(int start_page, int end_page); // 获取图片页面的url
void get_img_url(); // 获取图片的url
void download_img(char *url, char *outfilename); // 下载图片#define USER_AGENT "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 Edg/104.0.1293.63"typedef struct
{char *buffer;size_t size;
} MemoryStruct;// 回调函数,将获取的数据写入缓冲区
size_t write_callback(void *contents, size_t size, size_t nmemb, void *userp)
{size_t real_size = size * nmemb;MemoryStruct *mem = (MemoryStruct *)userp;mem->buffer = realloc(mem->buffer, mem->size + real_size + 1);if (mem->buffer == NULL){printf("Failed to allocate memory.\n");return 0;}memcpy(&(mem->buffer[mem->size]), contents, real_size);mem->size += real_size;mem->buffer[mem->size] = '\0';return real_size;
}/// @brief 获取每一页的图片链接
/// @param start_page
/// @param end_page
void get_imgpage_url(int start_page, int end_page)
{CURL *curl;CURLcode res;MemoryStruct response;response.buffer = malloc(1);response.size = 0;printf("初始化libcurl...\n");curl_global_init(CURL_GLOBAL_DEFAULT); // 初始化libcurlprintf("创建会话...\n");curl = curl_easy_init(); // 创建会话if (curl){FILE *file = fopen("result.txt", "w"); // 打开文件以保存结果if (file == NULL){printf("Failed to open file.\n");return;}// 循环获取每一页的图片链接for (int page = start_page; page <= end_page; ++page){char url[100]; // 保存URLsnprintf(url, sizeof(url), "https://wallhaven.cc/toplist?page=%d", page); // 设置URLcurl_easy_setopt(curl, CURLOPT_URL, url); // 设置URLcurl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, write_callback); // 设置回调函数curl_easy_setopt(curl, CURLOPT_WRITEDATA, (void *)&response); // 设置回调函数的参数printf("发起请求...\n");res = curl_easy_perform(curl); // 执行请求if (res != CURLE_OK){printf("curl_easy_perform() failed: %s\n", curl_easy_strerror(res));continue;}htmlDocPtr doc = htmlReadMemory(response.buffer, response.size, NULL, NULL, HTML_PARSE_NOWARNING | HTML_PARSE_NOERROR); // 解析HTMLif (doc == NULL){printf("Failed to parse HTML.\n");continue;}xmlXPathContextPtr xpathCtx = xmlXPathNewContext(doc); // 创建XPath上下文if (xpathCtx == NULL){printf("Failed to create XPath context.\n");xmlFreeDoc(doc);continue;}for (int i = 0; i < 20; i++) // 获取每页的20个图片链接{char xpath[] = "/html/body/main/div[1]/section/ul/li[%d]/figure/a/@href";snprintf(xpath, sizeof(xpath), "/html/body/main/div[1]/section/ul/li[%d]/figure/a/@href", i + 1);xmlXPathObjectPtr xpathObj = xmlXPathEvalExpression((xmlChar *)xpath, xpathCtx); // 评估XPath表达式if (xpathObj == NULL){printf("Failed to evaluate XPath expression.\n");xmlXPathFreeContext(xpathCtx);xmlFreeDoc(doc);continue;}xmlNodeSetPtr nodes = xpathObj->nodesetval; // 获取结果for (int i = 0; i < nodes->nodeNr; ++i){xmlChar *href = xmlNodeListGetString(doc, nodes->nodeTab[i]->xmlChildrenNode, 1);if (href != NULL){fprintf(file, "%s\n", href); // 将结果写入文件xmlFree(href);}}xmlXPathFreeObject(xpathObj);}xmlXPathFreeContext(xpathCtx);xmlFreeDoc(doc);printf("Page %d 链接获取完成.\n", page);}fclose(file);free(response.buffer);curl_easy_cleanup(curl);}else{printf("curl_easy_init() failed.\n");}curl_global_cleanup();printf("开始解析图片链接...\n");get_img_url();
}
static size_t write_data(void *ptr, size_t size, size_t nmemb, void *stream)
{size_t written = fwrite(ptr, size, nmemb, (FILE *)stream);return written;
}
void download_img(char *url, char *outfilename)
{printf("正在下载%s\n",outfilename);CURL *curl;FILE *fp;CURLcode res;// char url[256] = "https://w.wallhaven.cc/full/p9/wallhaven-p9w7l9.png";// char outfilename[256] = "image.png";curl_global_init(CURL_GLOBAL_DEFAULT);curl = curl_easy_init();if (curl){curl_easy_setopt(curl, CURLOPT_USERAGENT, USER_AGENT);curl_easy_setopt(curl, CURLOPT_URL, url);curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, write_data);// 打开当前目录下的img文件夹,没有则创建DIR *dir = opendir("img");if (dir == NULL){mkdir("img", 0777);}closedir(dir);// 打开img文件夹下的图片,没有则创建char img_path[256] = "img/";strcat(img_path, outfilename);fp = fopen(img_path, "wb");if (fp){curl_easy_setopt(curl, CURLOPT_WRITEDATA, fp);res = curl_easy_perform(curl);if (res != CURLE_OK){fprintf(stderr, "curl_easy_perform() failed: %s\n", curl_easy_strerror(res));}else{printf("Image saved successfully.\n");}fclose(fp);}else{fprintf(stderr, "Failed to create file: %s\n", outfilename);}curl_easy_cleanup(curl);}curl_global_cleanup();
}
void get_img_url()
{FILE *file;FILE *furl;char url[256];char outfilename[256];int count = 1;file = fopen("result.txt", "r");furl = fopen("url.txt", "w");if (file){while (fgets(url, sizeof(url), file) != NULL){// 去除换行符url[strcspn(url, "\n")] = '\0';//// 访问页面并获取内容CURL *curl = curl_easy_init();if (curl){curl_easy_setopt(curl, CURLOPT_URL, url);curl_easy_setopt(curl, CURLOPT_FOLLOWLOCATION, 1L);MemoryStruct html_content;html_content.buffer = malloc(1);html_content.size = 0;curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, write_callback);curl_easy_setopt(curl, CURLOPT_WRITEDATA, (void *)&html_content);// printf("start curl_easy_perform\n");CURLcode res = curl_easy_perform(curl);if (res != CURLE_OK){fprintf(stderr, "curl_easy_perform() failed: %s\n", curl_easy_strerror(res));curl_easy_cleanup(curl);free(html_content.buffer);return;}// 解析HTML内容// printf("start Parsing\n");xmlDocPtr doc = htmlReadMemory(html_content.buffer, html_content.size, "noname.html", NULL, HTML_PARSE_NOERROR | HTML_PARSE_NOWARNING);xmlXPathContextPtr xpathCtx = xmlXPathNewContext(doc);// 执行XPath查询,获取图片URLchar *xpathExpr = "//*[@id='wallpaper']/@src";xmlXPathObjectPtr xpathObj = xmlXPathEvalExpression((xmlChar *)xpathExpr, xpathCtx);xmlNodeSetPtr nodes = xpathObj->nodesetval;if (nodes != NULL && nodes->nodeNr > 0){xmlChar *imgUrl = xmlNodeListGetString(doc, nodes->nodeTab[0]->xmlChildrenNode, 1);if (imgUrl != NULL){// fwrite(imgUrl, strlen(imgUrl), 1, furl);// 将结果写入文件并加换行符fprintf(furl, "%s\n", imgUrl);printf("图片URL: %s\n", imgUrl);// print_image_url((const char *)imgUrl);xmlFree(imgUrl);}else{printf("imgUrl is NULL\n");}}xmlXPathFreeObject(xpathObj);xmlXPathFreeContext(xpathCtx);xmlFreeDoc(doc);// free(html_content.buffer);}curl_easy_cleanup(curl);}printf("图片链接获取完成.\n准备下载\n");}fclose(file);fclose(furl);furl = fopen("url.txt", "r");// 读取url.txt文件,download图片if (furl){count = 1;while (fgets(url, sizeof(url), furl) != NULL){// 去除换行符url[strcspn(url, "\n")] = '\0';// 根据读取url的后3位判断图片的类型,并设置图片的后缀名,后缀名还需要有count序号char *suffix = url + strlen(url) - 3;if (strcmp(suffix, "jpg") == 0){strcpy(outfilename, "image");char count_str[10];sprintf(count_str, "%d", count);strcat(outfilename, count_str);strcat(outfilename, ".jpg");}else if (strcmp(suffix, "png") == 0){strcpy(outfilename, "image");char count_str[10];sprintf(count_str, "%d", count);strcat(outfilename, count_str);strcat(outfilename, ".png");}else if (strcmp(suffix, "gif") == 0){strcpy(outfilename, "image");char count_str[10];sprintf(count_str, "%d", count);strcat(outfilename, count_str);strcat(outfilename, ".gif");}else{printf("图片类型错误\n");continue;}download_img(url, outfilename);count++;}}else{printf("Failed to open furl.\n");}fclose(furl);
}int main(int argc, char const *argv[])
{if (argc != 3){printf("Usage: %s <start_page> <end_page>\n", argv[0]);return 0;}else if (atoi(argv[1]) > atoi(argv[2])){printf("<start_page> must 大于 <end_page>\n");}else{printf("start page: %s\n", argv[1]);printf("end page: %s\n", argv[2]);get_imgpage_url(atoi(argv[1]), atoi(argv[2]));}return 0;
}