Dubbo源码篇06---SPI神秘的面纱---原理篇---上
- 引言
- 核心思想
- SPI模块架构设计
- 源码追踪
- Dubbo的分层模型获取扩展加载器对象
- 创建ExtensionLoader
- ExtensionLoader
- 自适应扩展对象创建
- Extension Instance创建生命周期
- SPI机制获取扩展对象实现类型
- 获取扩展类型
- 使用不同的加载策略加载不同目录下的扩展
- 类加载器加载扩展类的所有SPI文件
- 使用找到的扩展文件URL加载具体扩展到内存中
- @Adaptive,@Activate,Wrapper机制说明
- 自适应扩展代理对象的代码生成与编译
- 为扩展对象的set方法注入自适应扩展对象
- 获取注入对象
- 初始化扩展类
- 前后置处理
引言
上一篇文章,Dubbo源码篇05—SPI神秘的面纱—使用篇带领大家过了一遍Dubbo SPI的机制和使用,本文我们来深入Dubbo源码,一览背后原理。
本文基于: Dubbo SPI机制解析 一文而做,简化原文源码篇幅,加以图画解释。
核心思想
随着服务化的推广,网站对Dubbo服务框架的需求逐渐增多,Dubbo 的现有开发人员能实现的需求有限,很多需求都被 delay,而网站的同学也希望参与进来,加上领域的推动,所以平台计划将部分项目对公司内部开放,让大家一起来实现,Dubbo 为试点项目之一。
既然要开放,那 Dubbo 就要留一些扩展点,让参与者尽量黑盒扩展,而不是白盒的修改代码,否则分支,质量,合并,冲突都会很难管理。
即然要扩展,扩展点的加载方式,首先要统一,微核心+插件式,是比较能达到 OCP 原则的思路。
由一个插件生命周期管理容器,构成微核心,核心不包括任何功能,这样可以确保所有功能都能被替换,并且,框架作者能做到的功能,扩展者也一定要能做到,以保证平等对待第三方,所以,框架自身的功能也要用插件的方式实现,不能有任何硬编码。
通常微核心都会采用 Factory、IoC、OSGi 等方式管理插件生命周期。考虑 Dubbo 的适用面,不想强依赖 Spring 等 IoC 容器。自已造一个小的 IoC 容器,也觉得有点过度设计,所以打算采用最简单的 Factory 方式管理插件。
最终决定采用的是 JDK 标准的 SPI 扩展机制
在了解Dubbo SPI机制前先了解下JAVA SPI机制。Dubbo SPI的作用和JAVA SPI的作用基本类似,都是一种服务发现机制。SPI 的本质是将接口实现类的全限定名配置在文件中,并由服务加载器读取配置文件,加载实现类。这样可以在运行时,动态为接口替换实现类。正因此特性,我们可以很容易的通过 SPI 机制为我们的程序提供拓展功能。
这里大家可以和Spring对比一下,思考一下Spring如何通过IOC容器实现OCP原则的。
SPI模块架构设计
SPI 模型对象图:
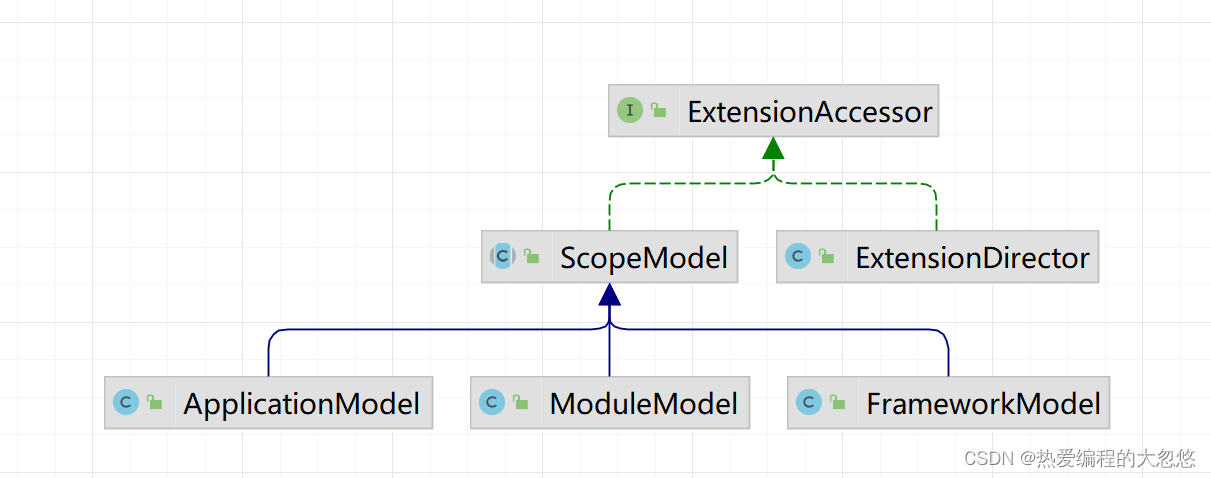
模型对象一共有4个,公共的属性和操作放在了域模型类型中,下面我们来详细说下这几个模型类型:
- ExtensionAccessor 扩展的统一访问器

- ScopeModel 模型对象的公共抽象父类型
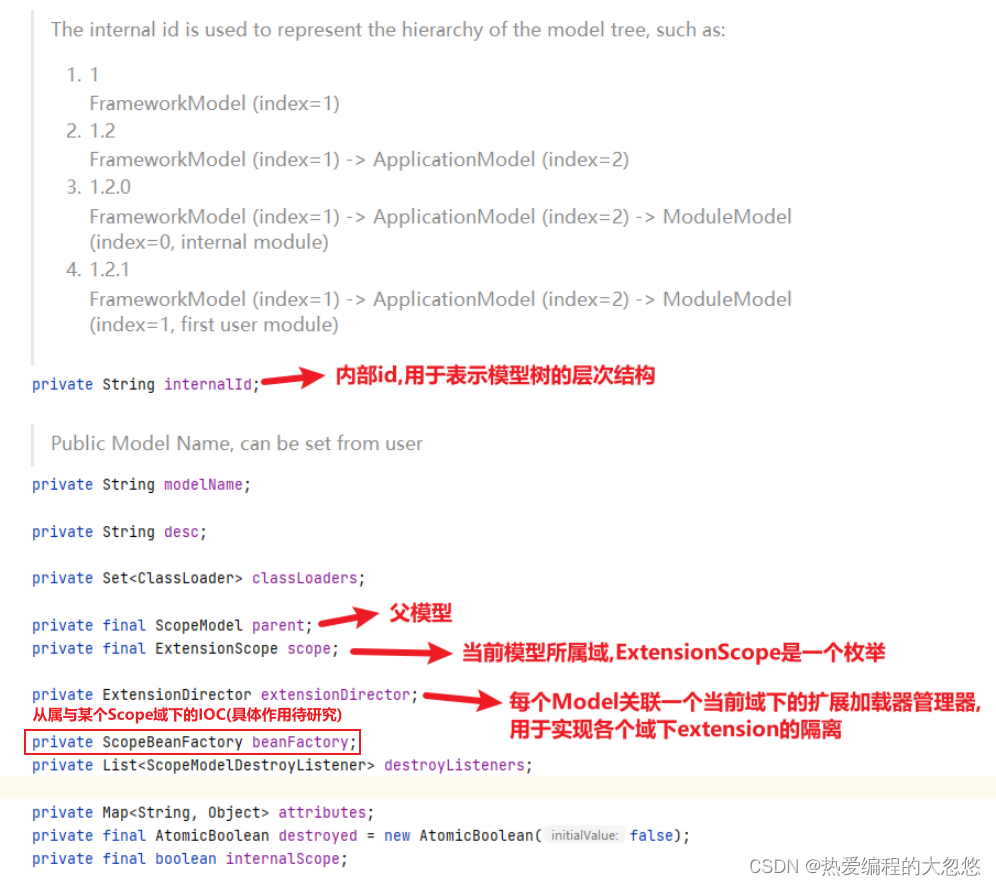
每个ScopeModel属于某个特定域 —> ExtensionScope有:
- FRAMEWORK(框架)
- APPLICATION(应用)
- MODULE(模块)
- SELF(自给自足,为每个作用域创建一个实例,用于特殊的SPI扩展,如ExtensionInjector)
不同类型的Scope之间的关系和作用可以参考下面我整理过的官方英文注释(中文翻译可能会产生误导,看英文确保语义无偏差)
public enum ExtensionScope {/*** 1. The extension instance is used within framework, shared with all applications and modules.* 2. Framework scope SPI extension can only obtain FrameworkModel, cannot get the ApplicationModel and ModuleModel* 3. Consideration:* 3.1 Some SPI need share data between applications inside framework* 3.2 Stateless SPI is safe shared inside framework*/FRAMEWORK,/*** 1. The extension instance is used within one application, shared with all modules of the application,* and different applications create different extension instances.* 2. Application scope SPI extension can obtain FrameworkModel and ApplicationModel, cannot get the ModuleModel* 3. Consideration:* 3.1 Isolate extension data in different applications inside framework* 3.2 Share extension data between all modules inside application*/APPLICATION,/*** 1. The extension instance is used within one module, and different modules create different extension instances.* 2. Module scope SPI extension can obtain FrameworkModel,ApplicationModel and ModuleModel* 3. Consideration:* 3.1 Isolate extension data in different modules inside application*/MODULE,/*** self-sufficient, creates an instance for per scope, for special SPI extension, like ExtensionInjector*/SELF
}
- FrameworkModel dubbo框架模型,可与多个应用程序共享

- ApplicationModel 表示正在使用Dubbo的应用程序,并存储基本元数据信息,以便在RPC调用过程中使用。 ApplicationModel包括许多关于发布服务的ProviderModel和许多关于订阅服务的Consumer Model。

- ModuleModel 服务模块的模型

dubbo ScopeModel体系并非本文重点,大家可以先不必纠结,这部分内容本文讲解的也是模棱两可,如果想深入了解,可参考下面这篇文章:
- 关于ScopeModel的设计疑惑 #10829
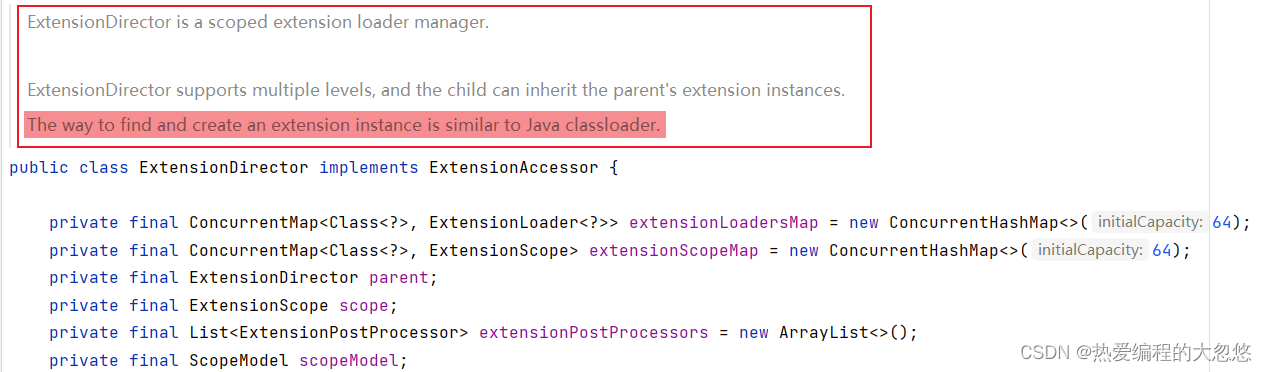
- ExtensionDirctor 类加载管理器负责管理
- 所有已加载过的ExtensionLoader集合
- 所有已加载过的ExtensionScope集合
- 父类加载管理器
- 所属模型ScopeModel的ExtensionScope
- 所有模型的实例对象ScopeModel
模型引用结构:
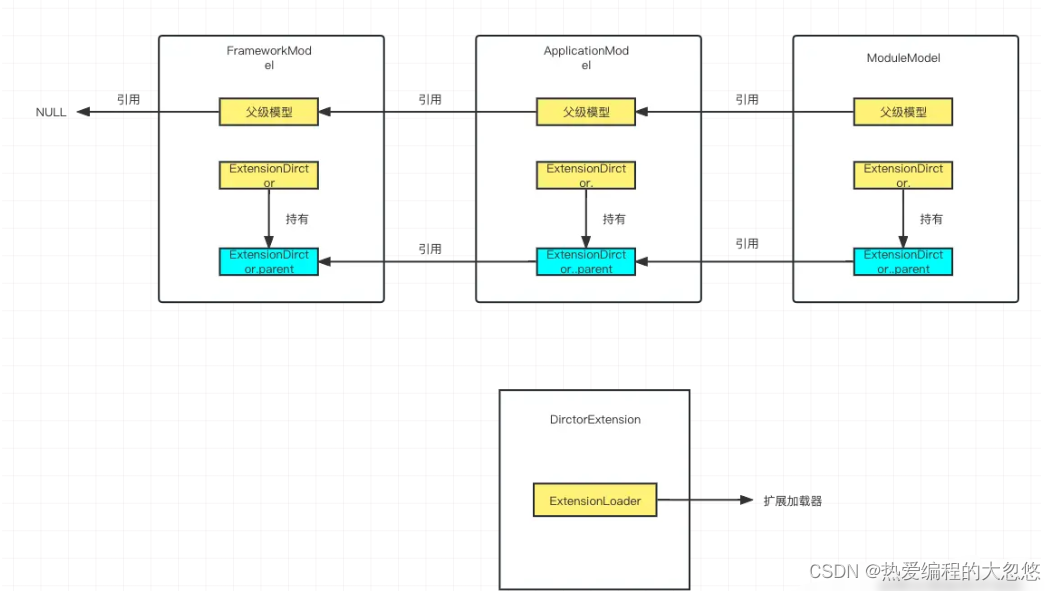
从模型图中可以看到每一个Model都会维护一个父级模型,来存放上级Model,同时ExtensionDirector中也会维护一个parent,存放的是上级Model中的ExtensionDirector,这种模型结构和ClassLoader的结构很类似。
- 当我们获取一个ExtensionLoader实例时,会优先从当前ExtensionDirector中去获取,如果当前ExtensionDirector中没有同时Scope不等于当前ExtensionDirector能解析的Scope,则委托给父
在这里插入代码片级ExtensionDirector 进行获取。
为什么要这样设计?
- 由于模块领域模型Model是分层的,同时每个 SPI 接口都有作用域(在配置 SPI 有scope选项),设计成跟ClassLoader类似的模型目的就是为了让子Model域能够获取父Model域中的 SPI 接口的实现类。达到从对象的管理上是分层的,从实际使用角度而言又可以达到父子传递的效果。
SPI的基本模型和作用都已经了解了,领域模型Model在这篇文章的就不详细展开了。接下来要讲的还是 SPI 的核心 ExtensionDirector 和 ExtensionLoader
源码追踪
我们从dubbo源码中找一个扩展加载例子,来看看整个加载流程 ,这里以ServiceConfig对象的postProcessAfterScopeModelChange()方法为入口进行追踪:
protected void postProcessAfterScopeModelChanged(ScopeModel oldScopeModel, ScopeModel newScopeModel) {super.postProcessAfterScopeModelChanged(oldScopeModel, newScopeModel);protocolSPI = this.getExtensionLoader(Protocol.class).getAdaptiveExtension();proxyFactory = this.getExtensionLoader(ProxyFactory.class).getAdaptiveExtension();}
Dubbo的分层模型获取扩展加载器对象
protected <T> ExtensionLoader<T> getExtensionLoader(Class<T> type) {return scopeModel.getExtensionLoader(type);}
ScopeModel的getExtensionLoader()方法继承至ExtensionAccessor接口中的默认方法:
default <T> ExtensionLoader<T> getExtensionLoader(Class<T> type) {return this.getExtensionDirector().getExtensionLoader(type);}
获取扩展加载器之前需要先获取扩展访问器:
- 模型对象(FrameworkModel)-–> 扩展访问器(ExtensionAccessor) —> 作用域扩展加载程序管理器(ExtensionDirector)
这个getExtensionDirector()方法来源于抽象父类型ScopeModel中的getExtensionDirector(), 如下代码:
public ExtensionDirector getExtensionDirector() {return extensionDirector;
}
这里的ExtensionDirector来源于ScopeModel的初始化方法initialize(),代码如下:
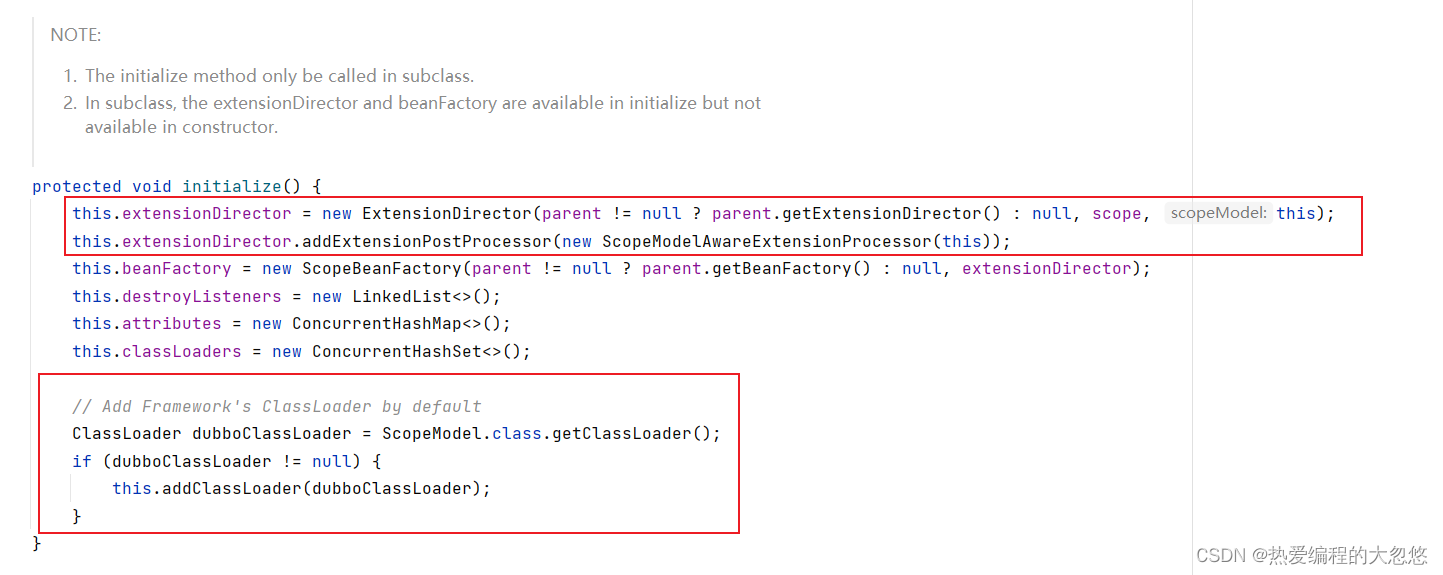
在生成ExtensionDirector的时候就会将父模型中的ExtensionDirector放到当前模型的ExtensionDirector中
我们继续前面getExtensionLoader(type)方法调用逻辑,前面我们知道了这个扩展访问器的对象是ExtensionDirector,接下来我们看下ExtensionDirector中获取扩展加载器的代码(如下所示):
public <T> ExtensionLoader<T> getExtensionLoader(Class<T> type) {// 检查当前的扩展加载管理器是否已被销毁,已销毁则抛出异常checkDestroyed();if (type == null) {throw new IllegalArgumentException("Extension type == null");}if (!type.isInterface()) {throw new IllegalArgumentException("Extension type (" + type + ") is not an interface!");}// 检查扩展接口上是否有@SPI注解,没有则抛出异常if (!withExtensionAnnotation(type)) {throw new IllegalArgumentException("Extension type (" + type +") is not an extension, because it is NOT annotated with @" + SPI.class.getSimpleName() + "!");}// 被加载过的扩展加载器会被放入缓存中,优先根据扩展接口从缓存中获取对应的扩展加载器ExtensionLoader<T> loader = (ExtensionLoader<T>) extensionLoadersMap.get(type);// 获取扩展接口定义的作用域,作用域分为 Frameworker,application,module,selfExtensionScope scope = extensionScopeMap.get(type);if (scope == null) {SPI annotation = type.getAnnotation(SPI.class);scope = annotation.scope();extensionScopeMap.put(type, scope);}// 如果作用域是SELF,代表不需要再上下文中被共享,则直接在当前管理器中创建对应的ExtensionLoaderif (loader == null && scope == ExtensionScope.SELF) {// create an instance in self scopeloader = createExtensionLoader0(type);}// 作用域是另外3个的情况,代表会再上下文中被共享,所以优先从父扩展加载管理器中获取对应的ExtensionLoader,这部分跟ClassLoader的双亲委派就很类似,每一个扩展加载管理器都不会直接尝试去加载ExtensionLoader,而是优先从父管理器中去获取if (loader == null) {if (this.parent != null) {loader = this.parent.getExtensionLoader(type);}}// 父加载管理器中没有对应的加载器则走这里的创建构造的对应ExtensionLoaderif (loader == null) {// 构造的时候会校验扩展接口的作用域是否和当前扩展加载管理器的作用域相同,相同则创建,否则返回nullloader = createExtensionLoader(type);}return loader;
}
getExtensionLoader方法使用模板方法设定好了ExtensionLoader加载的双亲委派流程。
创建ExtensionLoader
private <T> ExtensionLoader<T> createExtensionLoader(Class<T> type) {ExtensionLoader<T> loader = null;//当前类型注解的scope与当前扩展访问器ExtensionDirector的scope是否一致//当前类型ExtensionDirector的scope是在构造器中传递的,在Model对象初始化的时候创建的本类型if (isScopeMatched(type)) {// if scope is matched, just create itloader = createExtensionLoader0(type);} else {// if scope is not matched, ignore it}return loader;}
从createExtensionLoader方法可知,ExtensionDirector只会加载与自身scope一致的扩展类。
createExtensionLoader0方法是真正为扩展类创建ExtensionLoader的地方:
private <T> ExtensionLoader<T> createExtensionLoader0(Class<T> type) {//检查当前扩展访问器是否被销毁掉了checkDestroyed();ExtensionLoader<T> loader;//为当前扩展类型创建一个扩展访问器并缓存到,当前成员变量extensionLoadersMap中extensionLoadersMap.putIfAbsent(type, new ExtensionLoader<T>(type, this, scopeModel));loader = (ExtensionLoader<T>) extensionLoadersMap.get(type);return loader;}
ExtensionLoader
ExtensionLoader(Class<?> type, ExtensionDirector extensionDirector, ScopeModel scopeModel) {//当前扩展接口类型this.type = type;//创建扩展加载器的扩展加载管理器this.extensionDirector = extensionDirector;//从扩展访问器中获取扩展执行前后的回调器this.extensionPostProcessors = extensionDirector.getExtensionPostProcessors();//创建实例化对象的策略对象initInstantiationStrategy();//如果当前扩展类型为扩展注入器类型则设置当前注入器变量为空,否则的话获取一个扩展注入器扩展对象this.injector = (type == ExtensionInjector.class ? null : extensionDirector.getExtensionLoader(ExtensionInjector.class).getAdaptiveExtension());//创建Activate注解的排序器this.activateComparator = new ActivateComparator(extensionDirector);//为扩展加载器下的域模型对象赋值this.scopeModel = scopeModel;
}
创建实例化对象的策略对象: initInstantiationStrategy(); 方法干了啥 ?
private void initInstantiationStrategy() {for (ExtensionPostProcessor extensionPostProcessor : extensionPostProcessors) {//ScopeModelAwareExtensionProcessor在域模型对象时候为扩展访问器添加了这个域模型扩展处理器对象ScopeModelAwareExtensionProcessor,这个类型实现了ScopeModelAccessor域模型访问器可以用来获取域模型对象if (extensionPostProcessor instanceof ScopeModelAccessor) {instantiationStrategy = new InstantiationStrategy((ScopeModelAccessor) extensionPostProcessor);break;}}if (instantiationStrategy == null) {instantiationStrategy = new InstantiationStrategy();}}
InstantiationStrategy用于处理构造函数挑选和实例化。
自适应扩展对象创建
自适应扩展又称为动态扩展,用于将实现类的选择延迟到运行时动态决定。
自适应扩展对象更可以理解为一个分发器,调用时由自适应扩展对象根据一定规则决定将当前请求分发给对应的实现类来完成。
ExtensionLoader中的getAdaptiveExtension()方法,这个方法也是我们看到的第一个获取扩展对象的方法. ,这个方法可以帮助我们通过SPI机制从扩展文件中找到需要的扩展类型并创建它的对象, 自适应扩展:如果对设计模式比较了解的可能会联想到适配器模式,自适应扩展其实就是适配器模式的思路,自适应扩展有两种策略:
- 一种是我们自己实现自适应扩展:然后使用@Adaptive修饰,这个时候适配器的逻辑由我们自己实现,当扩展加载器去查找具体的扩展的时候可以通过找到我们这个对应的适配器扩展,然后适配器扩展帮忙去查询真正的扩展。这个比如我们下面要举的扩展注入器的例子,具体扩展通过扩展注入器适配器,注入器适配器来查询具体的注入器扩展实现来帮忙查找扩展。
- 还有一种方式是我们未实现这个自适应扩展,Dubbo在运行时通过字节码动态代理的方式在运行时生成一个适配器,使用这个适配器映射到具体的扩展. 第二种情况往往用在比如 Protocol、Cluster、LoadBalance 等。有时,有些拓展并不想在框架启动阶段被加载,而是希望在拓展方法被调用时,根据运行时参数进行加载。
public T getAdaptiveExtension() {// 检查加载器是否被销毁,被销毁则抛出异常checkDestroyed();// 从自适应扩展缓存中查询扩展对象如果存在就直接返回Object instance = cachedAdaptiveInstance.get();if (instance == null) {//创建异常则抛出异常直接返回(多线程场景下可能第一个线程异常了第二个线程进来之后走到这里)if (createAdaptiveInstanceError != null) {throw new IllegalStateException("Failed to create adaptive instance: " +createAdaptiveInstanceError.toString(),createAdaptiveInstanceError);}// 扩展对象是单例的,这里使用双重检索模式创建扩展对象synchronized (cachedAdaptiveInstance) {instance = cachedAdaptiveInstance.get();if (instance == null) {try {// 创建扩展对象instance = createAdaptiveExtension();cachedAdaptiveInstance.set(instance);} catch (Throwable t) {createAdaptiveInstanceError = t;throw new IllegalStateException("Failed to create adaptive instance: " + t.toString(), t);}}}}return (T) instance;
}
每一个ExtensionLoader负责管理一个Type类型相关扩展实现类,并且一个ExtensionLoader只会和一个AdaptiveInstance相关联----由cachedAdaptiveInstance负责缓存。
Extension Instance创建生命周期
我们先来看ExtensionLoader类型中createAdaotiveExtension()方法,这个方法包含了扩展对象创建初始化的整个生命周期,如下图代码所示:
private T createAdaptiveExtension() {try {// 获取扩展实现类,创建扩展对象T instance = (T) getAdaptiveExtensionClass().newInstance();// 注入扩展对象前的回调方法instance = postProcessBeforeInitialization(instance, null);// 注入扩展对象injectExtension(instance);// 注入扩展对象后的回调方法instance = postProcessAfterInitialization(instance, null);//初始化扩展对象的属性,如果当前扩展实例的类型实现了Lifecycle则调用当前扩展对象的生命周期回调方法initialize()(来自Lifecycle接口)initExtension(instance);return instance;} catch (Exception e) {throw new IllegalStateException("Can't create adaptive extension " + type + ", cause: " + e.getMessage(), e);}
}
SPI机制获取扩展对象实现类型
private Class<?> getAdaptiveExtensionClass() {//获取扩展类型,将扩展类型存入成员变量cachedClasses中进行缓存getExtensionClasses();//在上个方法的详细解析中的最后一步loadClass方法中如果扩展类型存在Adaptive注解将会将扩展类型赋值给cachedAdaptiveClass,否则的话会把扩展类型都缓存起来存储在扩展集合extensionClasses中if (cachedAdaptiveClass != null) {return cachedAdaptiveClass;}//扩展实现类型没有一个这个自适应注解Adaptive时候会走到这里//刚刚我们扫描到了扩展类型然后将其存入cachedClasses集合中了 接下来我们看下如何创建扩展类型return cachedAdaptiveClass = createAdaptiveExtensionClass();
}
获取扩展类型
private Map<String, Class<?>> getExtensionClasses() {// 查看扩展类型缓存是否存在Map<String, Class<?>> classes = cachedClasses.get();// 加载扩展类型缓存使用的依旧是双重检索模式if (classes == null) {synchronized (cachedClasses) {classes = cachedClasses.get();if (classes == null) {try {// 加载扩展类型classes = loadExtensionClasses();} catch (InterruptedException e) {....}// 加入到缓存中cachedClasses.set(classes);}}}return classes;
}
使用不同的加载策略加载不同目录下的扩展
private Map<String, Class<?>> loadExtensionClasses() throws InterruptedException {// 检查扩展加载器是否被销毁,销毁则抛出异常checkDestroyed();// 从扩展接口上的 SPI 注解获取扩展名缓存到成员变量cacheDefaultName中cacheDefaultExtensionName();Map<String, Class<?>> extensionClasses = new HashMap<>();//LoadingStrategy扩展策略有三种//DubboInternalLoadingStrategy:Dubbo内置的扩展加载策略,将加载文件目录为META-INF/dubbo/internal/的扩展//DubboLoadingStrategy:Dubbo普通的扩展加载策略,将加载目录为META-INF/dubbo/的扩展//ServicesLoadingStrategy:JAVA SPI加载策略 ,将加载目录为META-INF/services/的扩展for (LoadingStrategy strategy : strategies) {// 根据策略从指定的目录中加载扩展类型loadDirectory(extensionClasses, strategy, type.getName());// compatible with old ExtensionFactory// 如果当前扩展类型是扩展注入类型,则扫描ExtensionFactory下的扩展if (this.type == ExtensionInjector.class) {loadDirectory(extensionClasses, strategy, ExtensionFactory.class.getName());}}//通过loadDirectory扫描 扫描到了ExtensionInjector类型的扩展实现类有3个 我们将会得到这样一个集合例子://"spring" -> "class org.apache.dubbo.config.spring.extension.SpringExtensionInjector"//"scopeBean" -> "class org.apache.dubbo.common.beans.ScopeBeanExtensionInjector"//"spi" -> "class org.apache.dubbo.common.extension.inject.SpiExtensionInjector"return extensionClasses;
}
从文件中加载扩展实现loadDirectory方法:
private void loadDirectory(Map<String, Class<?>> extensionClasses, LoadingStrategy strategy, String type) {//根据扩展策略来加载扩展实现loadDirectory(extensionClasses, strategy.directory(), type, strategy.preferExtensionClassLoader(),strategy.overridden(), strategy.includedPackages(), strategy.excludedPackages(), strategy.onlyExtensionClassLoaderPackages());...}
private void loadDirectory(Map<String, Class<?>> extensionClasses, String dir, String type,boolean extensionLoaderClassLoaderFirst, boolean overridden, String[] includedPackages,String[] excludedPackages, String[] onlyExtensionClassLoaderPackages) {//获取文件名称,规则是扩展目录名称+扩展类型名称//比如:META-INF/dubbo/internal/org.apache.dubbo.rpc.ProtocolString fileName = dir + type;try {List<ClassLoader> classLoadersToLoad = new LinkedList<>();// 优先获取ExtensionLoader的类加载器作为扩展实现类的类加载器if (extensionLoaderClassLoaderFirst) {ClassLoader extensionLoaderClassLoader = ExtensionLoader.class.getClassLoader();// 如果不是系统类加载器,则缓存到classLoaderToLoad中if (ClassLoader.getSystemClassLoader() != extensionLoaderClassLoader) {classLoadersToLoad.add(extensionLoaderClassLoader);}}// 获取域模型对象的类型加载器,这个域模型对象在初始化的时候会将自己的类加载器放入集合中Set<ClassLoader> classLoaders = scopeModel.getClassLoaders();// 如果没有域模型类加载器可以使用,则借助系统级别的ClassLoader来加载所有的资源if (CollectionUtils.isEmpty(classLoaders)) {//借助系统类加载器来加载对应扩展类的SPI文件Enumeration<java.net.URL> resources = ClassLoader.getSystemResources(fileName);if (resources != null) {while (resources.hasMoreElements()) {loadResource(extensionClasses, null, resources.nextElement(), overridden, includedPackages, excludedPackages, onlyExtensionClassLoaderPackages);}}} else {//ExtensionLoader的类加载器和域模型类加载器合并classLoadersToLoad.addAll(classLoaders);}//使用类加载资源加载器(ClassLoaderResourceLoader)来加载具体的资源,这个位置是使用多线程进行资源的加载//遍历从所有资源文件中读取到资源url地址,key为类加载器,值为扩展文件url如下所示//jar:file:/Users/dhy/.m2/repository/org/apache/dubbo/dubbo/3.0.7/dubbo-3.0.7.jar!/META-INF/dubbo/internal/org.apache.dubbo.common.extension.ExtensionInjector// 这里的加载模式和 JAVA SPI 的ServiceLoader是一样的,都是先根据ClassLoader加载所有的资源文件,然后再读取资源文件中的信息Map<ClassLoader, Set<java.net.URL>> resources = ClassLoaderResourceLoader.loadResources(fileName, classLoadersToLoad);resources.forEach(((classLoader, urls) -> {loadFromClass(extensionClasses, overridden, urls, classLoader, includedPackages, excludedPackages, onlyExtensionClassLoaderPackages);}));} catch (Throwable t) {logger.error("Exception occurred when loading extension class (interface: " +type + ", description file: " + fileName + ").", t);}}
类加载器加载扩展类的所有SPI文件
根据文件名查询扩展文件的URLS方法,ClassLoaderResourceLoader#loadResources()方法,代码如下:
public static Map<ClassLoader, Set<URL>> loadResources(String fileName, List<ClassLoader> classLoaders) throws InterruptedException {Map<ClassLoader, Set<URL>> resources = new ConcurrentHashMap<>();// 使用多线程计数器阻塞当前方法,等待内部使用多线程异步使用不同的类加载器完成资源文件的扫描CountDownLatch countDownLatch = new CountDownLatch(classLoaders.size());for (ClassLoader classLoader : classLoaders) {GlobalResourcesRepository.getGlobalExecutorService().submit(() -> {resources.put(classLoader, loadResources(fileName, classLoader));countDownLatch.countDown();});}countDownLatch.await();return Collections.unmodifiableMap(new LinkedHashMap<>(resources));
}
资源文件的加载 loadResources()方法,代码如下:
public static Set<URL> loadResources(String fileName, ClassLoader currentClassLoader) {Map<ClassLoader, Map<String, Set<URL>>> classLoaderCache;//第一次进来类加载器资源缓存是空的if (classLoaderResourcesCache == null || (classLoaderCache = classLoaderResourcesCache.get()) == null) {synchronized (ClassLoaderResourceLoader.class) {if (classLoaderResourcesCache == null || (classLoaderCache = classLoaderResourcesCache.get()) == null) {classLoaderCache = new ConcurrentHashMap<>();//创建一个类资源映射url的软引用缓存对象//软引用(soft references),用于帮助垃圾收集器管理内存使用和消除潜在的内存泄漏。当内存快要不足的时候,GC会迅速的把所有的软引用清除掉,释放内存空间classLoaderResourcesCache = new SoftReference<>(classLoaderCache);}}}// 第一次进来classloader对应的资源文件缓存都是为空,创建一个缓存,map里放的是key是filename,value是文件对应的所有资源URLSif (!classLoaderCache.containsKey(currentClassLoader)) {classLoaderCache.putIfAbsent(currentClassLoader, new ConcurrentHashMap<>());}Map<String, Set<URL>> urlCache = classLoaderCache.get(currentClassLoader);// 第一次进来文件对应的资源文件是空的,进行查找if (!urlCache.containsKey(fileName)) {Set<URL> set = new LinkedHashSet<>();Enumeration<URL> urls;try {//getResources这个方法是这样的:加载当前类加载器以及父类加载器所在路径的资源文件,将遇到的所有资源文件全部返回!这个可以理解为使用双亲委派模型中的类加载器 加载各个位置的资源文件urls = currentClassLoader.getResources(fileName);boolean isNative = NativeUtils.isNative();if (urls != null) {//遍历找到的对应扩展的文件url将其加入集合while (urls.hasMoreElements()) {URL url = urls.nextElement();if (isNative) {//In native mode, the address of each URL is the same instead of different paths, so it is necessary to set the ref to make it differentsetRef(url);}set.add(url);}}} catch (IOException e) {e.printStackTrace();}urlCache.put(fileName, set);}return urlCache.get(fileName);
}
使用找到的扩展文件URL加载具体扩展到内存中
ExtensionLoader类型中的loadFromClass方法 遍历url 开始加载扩展类型:
private void loadFromClass(Map<String, Class<?>> extensionClasses, boolean overridden, Set<java.net.URL> urls, ClassLoader classLoader,String[] includedPackages, String[] excludedPackages, String[] onlyExtensionClassLoaderPackages) {if (CollectionUtils.isNotEmpty(urls)) {for (java.net.URL url : urls) {loadResource(extensionClasses, classLoader, url, overridden, includedPackages, excludedPackages, onlyExtensionClassLoaderPackages);}}
}
ExtensionLoader类型中的loadResource方法 使用IO流读取扩展文件的内容 读取内容之前我这里先贴一下我们参考的扩展注入类型的文件中的内容如下所示:
adaptive=org.apache.dubbo.common.extension.inject.AdaptiveExtensionInjector
spi=org.apache.dubbo.common.extension.inject.SpiExtensionInjector
scopeBean=org.apache.dubbo.common.beans.ScopeBeanExtensionInjector
扩展中的文件都是一行一行的,并且扩展名字和扩展类型之间使用等号隔开= 了解了文件内容之后 应该下面的代码大致思路就知道了,我们可以详细看下:
private void loadResource(Map<String, Class<?>> extensionClasses, ClassLoader classLoader,java.net.URL resourceURL, boolean overridden, String[] includedPackages, String[] excludedPackages, String[] onlyExtensionClassLoaderPackages) {try {// 解析URL并获取每一行数据,这里就不做了解了List<String> newContentList = getResourceContent(resourceURL);String clazz;// 读取每一行并按照“=”号分隔for (String line : newContentList) {final int ci = line.indexOf('#');if (ci >= 0) {line = line.substring(0, ci);}line = line.trim();if (line.length() > 0) {try {String name = null;int i = line.indexOf('=');if (i > 0) {name = line.substring(0, i).trim();clazz = line.substring(i + 1).trim();} else {clazz = line;}//isExcluded是否为加载策略要排除的配置,参数这里为空代表全部类型不排除//isIncluded是否为加载策略包含的类型,参数这里为空代表全部文件皆可包含//onlyExtensionClassLoaderPackages参数是否只有扩展类的类加载器可以加载扩展,其他扩展类型的类加载器不能加载扩展 这里结果为false 不排除任何类加载器if (StringUtils.isNotEmpty(clazz) && !isExcluded(clazz, excludedPackages) && isIncluded(clazz, includedPackages)&& !isExcludedByClassLoader(clazz, classLoader, onlyExtensionClassLoaderPackages)) {//根据类全路径加载类到内存loadClass(extensionClasses, resourceURL, Class.forName(clazz, true, classLoader), name, overridden);}} catch (Throwable t) {IllegalStateException e = new IllegalStateException("Failed to load extension class (interface: " + type +", class line: " + line + ") in " + resourceURL + ", cause: " + t.getMessage(), t);exceptions.put(line, e);}}}} catch (Throwable t) {logger.error("Exception occurred when loading extension class (interface: " +type + ", class file: " + resourceURL + ") in " + resourceURL, t);}
}
ExtensionLoader类型中的loadClass方法加载具体的类到内存:
private void loadClass(Map<String, Class<?>> extensionClasses, java.net.URL resourceURL, Class<?> clazz, String name,boolean overridden) {// 检查解析出来扩展实现类是否为扩展接口的实现,不是则抛出异常 if (!type.isAssignableFrom(clazz)) {throw new IllegalStateException("Error occurred when loading extension class (interface: " +type + ", class line: " + clazz.getName() + "), class "+ clazz.getName() + " is not subtype of interface.");}// 检查扩展实现类是否包含Adaptive注解--> 不允许覆盖的话出现同同名字扩展将抛出异常if (clazz.isAnnotationPresent(Adaptive.class)) {cacheAdaptiveClass(clazz, overridden);}//扩展子类型构造器中是否有这个类型的接口 (这个可以想象下我们了解的Java IO流中的类型使用到的装饰器模式 构造器传个类型),简单来讲就是是否使用了装饰模式 else if (isWrapperClass(clazz)) {cacheWrapperClass(clazz);} else {//无自适应注解,也没有构造器是扩展类型参数 ,这个name我们在扩展文件中找到了就是等号前面那个//如果name为空,也就是我们在SPI文件中只写了实现类的全类名,没有起别名,那么别名采用自动获取方式:if (StringUtils.isEmpty(name)) {//低版本中可以使用@Extension 扩展注解来标注扩展类型,这里获取别名有两个渠道://1.先查询@Extension注解是否存在如果存在则取value值//2.如果不存在@Extension注解则获取当前类型的名字name = findAnnotationName(clazz);if (name.length() == 0) {throw new IllegalStateException("No such extension name for the class " + clazz.getName() + " in the config " + resourceURL);}}//获取扩展名字数组,扩展名字可能为逗号隔开的String[] names = NAME_SEPARATOR.split(name);if (ArrayUtils.isNotEmpty(names)) {//@Avtivate注解处理---> cachedActivates.put(name, activate(注解对象));cacheActivateClass(clazz, names[0]);for (String n : names) {//cachedNames缓存集合缓存当前扩展类型的扩展名字--> cachedNames.put(clazz, name);cacheName(clazz, n);//将扩展类型加入结果集合extensionClasses中,不允许覆盖的话出现同同名字扩展将抛出异常//--> extensionClasses.put(name, clazz);saveInExtensionClass(extensionClasses, clazz, n, overridden);}}}
}
@Adaptive,@Activate,Wrapper机制说明
每一个ExtensionLoader实例负责管理一个Type扩展类实现类的管理,并且一个ExtensionLoader实例只能和一个Adaptive实例相关联:
private volatile Class<?> cachedAdaptiveClass = null;
@Adaptive自适应注解修饰的扩展实现类时,同一个扩展只能有一个自适应扩展实现类型, 扩展策略中提供的参数overridden是否允许覆盖扩展覆盖
private void cacheAdaptiveClass(Class<?> clazz, boolean overridden) {if (cachedAdaptiveClass == null || overridden) {//成员变量存储这个自适应扩展类型,即缓存cachedAdaptiveClass = clazz;} else if (!cachedAdaptiveClass.equals(clazz)) {throw new IllegalStateException("More than 1 adaptive class found: "+ cachedAdaptiveClass.getName()+ ", " + clazz.getName());}}
如果我们没有通过@Adaptive注解指定自适应扩展实现类型,那么dubbo会通过动态代理生成默认的自适应扩展类型。
dubbo支持AOP机制,这是采用Wrapper机制实现的,即扩展类的包装机制,就是对扩展类的SPI接口方法进行包装,可以类比IO流中的装饰器模式,一个扩展类下可以存在多个Wrapper包装器:
protected boolean isWrapperClass(Class<?> clazz) {// 获取所有构造器Constructor<?>[] constructors = clazz.getConstructors();// 构造器有且只有一个参数,同时入参等于当前扩展类接口代表当前扩展实现类是一个装饰类for (Constructor<?> constructor : constructors) {if (constructor.getParameterTypes().length == 1 && constructor.getParameterTypes()[0] == type) {return true;}}return false;
}
private void cacheWrapperClass(Class<?> clazz) {if (cachedWrapperClasses == null) {cachedWrapperClasses = new ConcurrentHashSet<>();}//缓存这个Wrapper类型的扩展cachedWrapperClasses.add(clazz);
}
dubbo支持按条件批量激活扩展类,这是通过@Activate注解实现的,这个扩展类型可以出现多个比如:
- 过滤器, 可以同一个扩展名字多个过滤器实现, 所以不需要有override判断
private void cacheActivateClass(Class<?> clazz, String name) {Activate activate = clazz.getAnnotation(Activate.class);if (activate != null) {//缓存Activate类型的扩展cachedActivates.put(name, activate);} else {// support com.alibaba.dubbo.common.extension.Activatecom.alibaba.dubbo.common.extension.Activate oldActivate = clazz.getAnnotation(com.alibaba.dubbo.common.extension.Activate.class);if (oldActivate != null) {cachedActivates.put(name, oldActivate);}}}
上面扩展对象加载了这么多最终的目的就是将这个扩展类型存放进结果集合extensionClasses中,扩展策略中提供的参数overridden是否允许覆盖扩展覆盖:
private void saveInExtensionClass(Map<String, Class<?>> extensionClasses, Class<?> clazz, String name, boolean overridden) {Class<?> c = extensionClasses.get(name);if (c == null || overridden) {extensionClasses.put(name, clazz);} else if (c != clazz) {// duplicate implementation is unacceptableunacceptableExceptions.add(name);String duplicateMsg = "Duplicate extension " + type.getName() + " name " + name + " on " + c.getName() + " and " + clazz.getName();logger.error(duplicateMsg);throw new IllegalStateException(duplicateMsg);}}
自适应扩展代理对象的代码生成与编译

private Class<?> createAdaptiveExtensionClass() {// Adaptive Classes' ClassLoader should be the same with Real SPI interface classes' ClassLoader// 获取类加载器ClassLoader classLoader = type.getClassLoader();try {//native配置 是否为本地镜像(可以参考官方文档:https://dubbo.apache.org/zh/docs/references/graalvm/support-graalvif (NativeUtils.isNative()) {// 在3.0.8中有对应的实现类代码,位与dubbo-native包下,比如Protocol的扩展类代理类名称就是 Protocol$Adaptivereturn classLoader.loadClass(type.getName() + "$Adaptive");}} catch (Throwable ignore) {}//创建一个代码生成器,来生成代码 详细内容我们就下一章来看String code = new AdaptiveClassCodeGenerator(type, cachedDefaultName).generate();// 获取编译器org.apache.dubbo.common.compiler.Compiler compiler = extensionDirector.getExtensionLoader(org.apache.dubbo.common.compiler.Compiler.class).getAdaptiveExtension();// 生成的代码进行编译 return compiler.compile(type, code, classLoader);}Complier详细过程可以参考本专栏04篇文章(本文发稿前,04篇处于编稿,待发布中…)
为扩展对象的set方法注入自适应扩展对象

之前我们已经了解到了获取扩展实现类并实例化的过程,接下来就涉及到 Dubbo SPI 比较重要的一个功能,就是 DI 依赖注入:
// 注入扩展对象injectExtension(instance);
ExtensionLoader类型的injectExtension方法具体代码如下:
private T injectExtension(T instance) {// 这里的扩展注入器不为空,在ExtensionLoader创建时会获取ExtensionInjector的自适应扩展类// 这里的injector即是ExtensionInjector扩展接口的的自适应扩展类AdaptiveExtensionInjector// 如果为空则直接返回当前实例对象,不进行依赖注入if (injector == null) {return instance;}try {// 遍历所有方法 --- 只包括本类和父类的public方法for (Method method : instance.getClass().getMethods()) {// 如果当前方法不是一个setXXXX()方法则继续处理下一个方法// public + set开头 + 只有一个参数if (!isSetter(method)) {continue;}//校验当前方法上携带了@DisableInject注解吗,即禁止注入的当前属性,符合则跳过if (method.isAnnotationPresent(DisableInject.class)) {continue;}// 第一个参数是原生类型(String、Boolean、Integer ...) 跳过Class<?> pt = method.getParameterTypes()[0];if (ReflectUtils.isPrimitives(pt)) {continue;}try {// 获取set方法对应的成员变量如setProtocol 属性为protocolString property = getSetterProperty(method);// 根据参数类型如Protocol和属性名字如protocol获取应该注入的对象Object object = injector.getInstance(pt, property);if (object != null) {method.invoke(instance, object);}} catch (Exception e) {logger.error("Failed to inject via method " + method.getName()+ " of interface " + type.getName() + ": " + e.getMessage(), e);}}} catch (Exception e) {logger.error(e.getMessage(), e);}return instance;}
获取注入对象
这里我们主要来看下如何通过注入器找到需要注入的那个对象 调用代码如下:
Object object = injector.getInstance(pt, property);
injector的生成可以看前面的ExtensionLoader的构造,来源就是ExtensionInjector的自适应扩展实现实例AdaptiveExtensionInjector,这个位置的getInstance也是在AdaptiveExtensionInjector中实现的
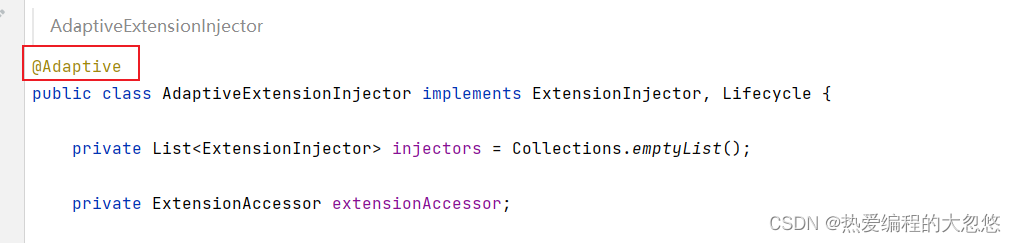
public <T> T getInstance(final Class<T> type, final String name) {// 遍历所有的扩展注入器并调用getinstance()方法,并取第一个返回return injectors.stream().map(injector -> injector.getInstance(type, name)).filter(Objects::nonNull).findFirst().orElse(null);}
ExtensionInjector是 Dubbo 源码中为数不多的自适应扩展实现实例,ExtensionInjector扩展接口的自适应扩展实现就是AdaptiveExtensionInjector,接口实现类默认有三个
- SpiExtensionInjector: 根据实例 class 从 ExtensionLoader 中获取实例
- ScopeBeanExtensionInjector: 从 Dubbo 自定义的beanfactory中获取实例
- SpringExtenisonInjector: 从 Spring 的beanfactory中获取实例
这个AdaptiveExtensionInjector在初始化的时候会获取所有的ExtensionInjector的扩展,非自适应的,它本身是自适应的扩展。
初始化扩展类

private void initExtension(T instance) {// 相当于一个初始化回调接口---类比: spring中的afterPropertiesSetif (instance instanceof Lifecycle) {Lifecycle lifecycle = (Lifecycle) instance;lifecycle.initialize();}}
前后置处理
- 前置处理和后置处理都实现思路和Spring类似
private T postProcessBeforeInitialization(T instance, String name) throws Exception {if (extensionPostProcessors != null) {for (ExtensionPostProcessor processor : extensionPostProcessors) {instance = (T) processor.postProcessBeforeInitialization(instance, name);}}return instance;}private T postProcessAfterInitialization(T instance, String name) throws Exception {if (instance instanceof ExtensionAccessorAware) {((ExtensionAccessorAware) instance).setExtensionAccessor(extensionDirector);}if (extensionPostProcessors != null) {for (ExtensionPostProcessor processor : extensionPostProcessors) {instance = (T) processor.postProcessAfterInitialization(instance, name);}}return instance;}
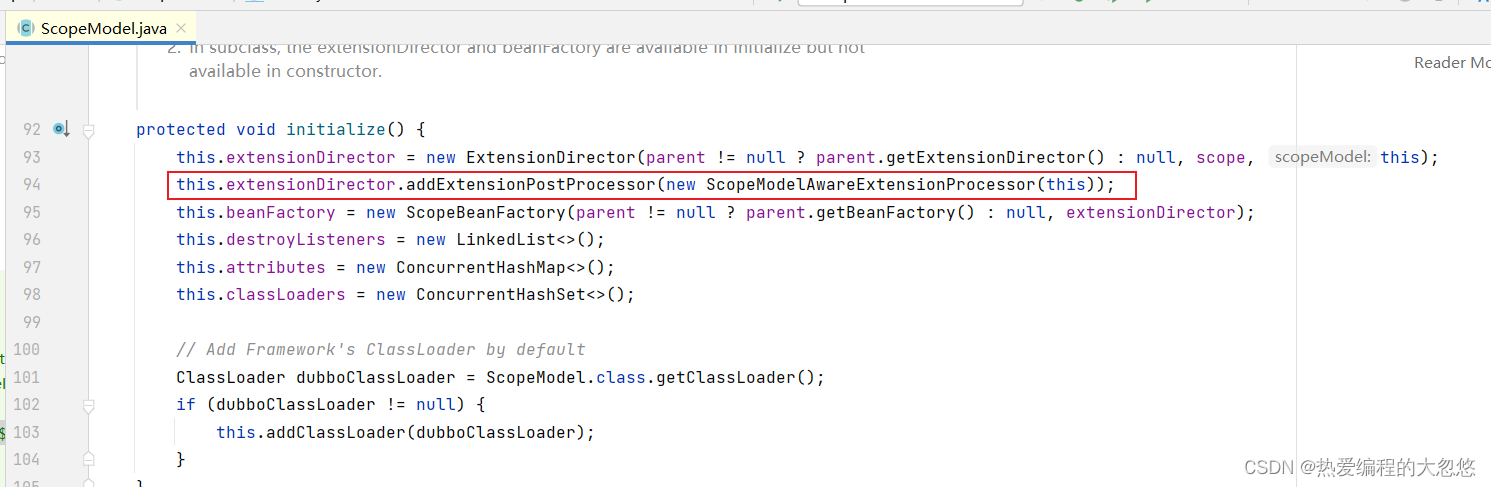
默认只有ScopeModelAwareExtensionProcessor一个后置处理器,用来处理ScopeModelAware注入。