目录
项目背景
数据介绍
数据来源
属性介绍
算法介绍
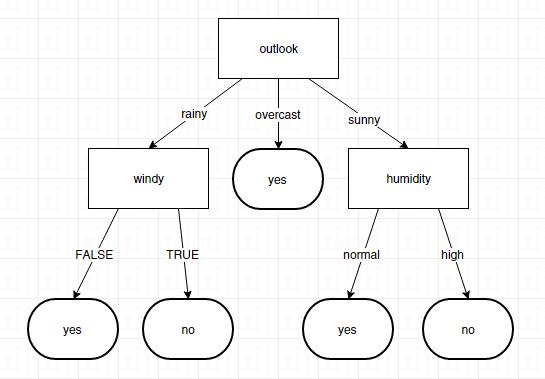
随机森林算法
决策树
随机森林定义
随机森林构建过程
随机森林算法评价
随机森林算法的发展现状及趋势
实验步骤
1.导入模块与数据
2.查看数据
3.数据预处理
4.可视化分析
5.特征工程
6.构建模型
实验总结
项目背景
我们所经历的全球化进程带来了一系列变化,因为社会、政治、经济和文化进程错综复杂地交织在一起,改变了习俗和习惯,特别是我们的生活方式。这导致与食物过度消费有关的疾病大量增加。肥胖就是一个明显的例子,它越来越常见,因为越来越多的低营养和热量食物被摄入,而且由于交通工具的多种选择以及新的工作和娱乐形式,没有进行必要的体育活动。
世界卫生组织将肥胖和超重描述为在某些身体部位过度积累脂肪,可能对健康有害。自1980年以来,患肥胖症的人数翻了一番,2014年,超过19亿18岁或以上的成年人体重发生变化。超重的一些原因是高脂肪高能量食物的摄入量增加,以及由于久坐工作的性质、新的交通方式和日益城市化而导致的体力活动减少。
肥胖可以被认为是一种具有多种因素的疾病,其症状是体重不受控制地增加,原因是脂肪摄入过多和能量消耗。肥胖可以由遗传背景等生物危险因素引起,因此可以有几种肥胖类型:单基因、瘦素、多基因和综合征。此外,还有其他风险因素,如社会、心理和饮食习惯。另一方面,有人提出了肥胖的其他决定因素,如“独生子女、离婚等家庭冲突、抑郁和焦虑”。
肥胖的发展需要遗传易患这种疾病和暴露于不利环境条件的综合影响。遗传因素决定着组织脂肪形式能量积累的能力或容易程度,而热量形式能量释放的能力或容易程度较低,这意味着肥胖的能源效率较高。产生这种情况的原因是,从长远来看,个人的能源支出低于他所投入的能源,即存在积极的能源平衡。遗传影响与恶劣的饮食习惯和定居生活方式等外部条件有关。
肥胖是一个被称为"世纪流行病"的公共卫生问题,并且根据世界卫生组织的数据表明肥胖的人数持续增加。肥胖这个问题以前与工业化国家有关,但在发展中国家,特别是在城市地区,超重和肥胖现象明显增加。比如,在墨西哥,这是最常见的代谢疾病,作为世界上最肥胖的国家,疟疾流行率从2000年的59.7%上升到2006年的66.7%,对发病率和死亡率居首位的疾病的发展构成了重大风险。成瘾的风险与患糖尿病、高血压、肺和心血管疾病等慢性疾病的高发病率有关,也是发展各种癌症的高风险因素。它还影响到个人的心理领域,降低了受影响者的自尊,影响到他们的社会关系。因此,这一问题的严重程度是显而易见的,而且由于肥胖不分年龄、性别、种族或社会经济地位影响到任何人,情况变得更加令人担忧。
肥胖是一个全球性的公共健康问题,它可以在成人、青少年和儿童中出现。同时,注意到儿童肥胖是成年人肥胖的一个危险因素这一令人震惊的事实,从生命的早期阶段就预防和控制肥胖至关重要,也必须考虑到儿童体重的增加必须是渐进的。由于城市化、经济和技术发展带来的生活方式不断变化,儿童受到影响,导致肥胖儿童人数增加,因此,很多研究集中在对儿童肥胖问题的上。
本文使用UCI中一项关于人们饮食习惯和身体状况调查的数据集,分别通过决策树、随机森林、GBDT算法对数据进行处理,拟在寻找肥胖的成因。算法通过对15种影响因子进行多标签分类获取各影响因子与肥胖程度之间的权值,最终获取肥胖评估模型。人们可以通过评估模型就自己目前的生活习惯和身体状况来对未来的肥胖程度进行评估,并根据评估结果寻求解决肥胖问题的合理方式。
数据介绍
数据来源
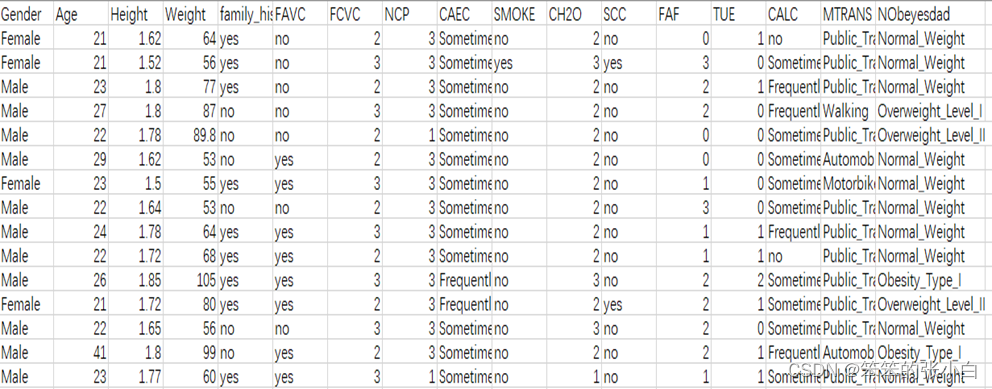
该数据集来自于UCL机器学习知识库,数据集包括墨西哥、秘鲁和哥伦比亚等国基于饮食习惯和身体状况的个体肥胖水平估计数据。数据包含17个属性和2111条记录,这些记录标有类变量肥胖等级,允许使用体重不足、正常体重、超重一级、超重二级、肥胖一级、肥胖二级和肥胖三级的值对数据进行分类。77%的数据是使用Weka工具和SMOTE过滤器综合生成的,23%的数据是通过网络平台直接从用户那里收集的。这些数据可用于生成智能计算工具,以识别个人的肥胖水平,并构建监控肥胖水平的推荐系统。部分原始数据如图 。
属性介绍
数据共包括17个属性,下面对各属性进行说明,如表 :
| 属性 | 含义 | 取值 |
| Gender | 性别 | Female、Male |
| Age | 年龄 | 整数取值 |
| Height | 身高 | 小数(m) |
| Weight | 体重 | 整数取值(kg) |
| Family history with overweight | 家庭肥胖历史 | Yes、NO |
| FAVC | 经常食用高热量食物 | Yes、NO |
| FCVC | 食用蔬菜的频率 | No(0)、Sometimes(1)、Frequently(2)、Always(3) |
| NCP | 主餐次数 | 1-2、3、>3 |
| CAEC | 两餐之间食用食物 | No、Sometimes、Frequently、Always |
| SMOKE | 是否抽烟 | Yes、NO |
| CH2O | 每日饮水量 | 1(a little)、2(1-2L)、3(>2L) |
| CALC | 饮酒 | No、Sometimes、Frequently、Always |
| SCC | 卡路里消耗监测 | Yes、NO |
| FAF | 身体活动频率 | 0(NO)、1(1-2天)、2(2-4天)、3(4-5天) |
| TUE | 使用技术设备的时间 | 0(0-2h)、1(3-5h)、2(>5h) |
| MTRANS | 使用的交通工具 | Automobile、Motorbike、Bike、Public、Transportation、Walking |
| NObeyesdad | 肥胖等级 | Based on the WHO Classification |
Gender、Age、Family_history_with_overweight、FAVC、FCVC、NCP、CAEC、SMOKE、CH2O、CALC、SCC、FAF、TUE为特征, Height、Weight作为两个使用如下公式计算体重指数(MBI)的特征,NObeyesdad作为标签,计算出每个个体的体重指数后,为了确定肥胖水平,我们使用了世界卫生组织提供的表 2,对基于体重指数分析的数据进行了正确分类,得出每个个体的肥胖等级。
Mass body index=WeightHeight*Height (2.1)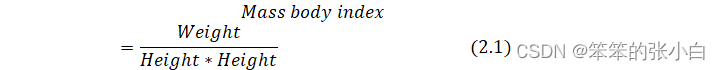
表 2 体重指数分类表
| 标准 | 等级 |
| MBI <18.5 | 体重不足 |
| 18.5≤MBI≤24.9 | 正常 |
| 25.0≤MBI≤29.9 | 超重 |
| 30.0≤MBI≤34.9 | 肥胖一级 |
| 35.0≤MBI≤39.9 | 肥胖二级 |
| MBI≥40 | 肥胖三级 |
算法介绍
随机森林算法
传统的机器学习分类方法就是根据现有的数据资料和分析成果进行建模,探索出规律并能对新的数据进行分类预测的技术,目前主要的算法非常多,有决策树(decision tree,DT,包含 ID3 算法、C4.5 算法、CART 算法等)、神经网络、支持向量机(support vector machine,SVM)和随机森林(random forest,RF)等。随机森林在二十一世纪初被提出,能解决过拟合的问题,它的基分类器是决策树,通过 bagging 抽样的方式生成多棵决策树,结果由多棵决策树共同决定,因此分类效果要好于传统的分类算法。它是一种自然的非线性建模工具,要理解这个算法必须先理解决策树的概念。
决策树
决策树是一种非常快速的分类模型,是最为经典的分类算法之一,不需要进行先验假设,也不需要对特征值进行归一化或标准化处理,算法规则简单直观易于理解。
决策树算法具体是根据某种分割规则,将根节点按设定的阈值,分为两个子节点,并在子节点重复这个步骤,直到得出类别结果。若是将这个过程用流程图形式显示,就类似于一个二叉树,如图 2所示,N0是根节点,没有入边但有零或两条出边(edge),指向两个内节点(internal node),即Ni(2,3,4);内节点有一条入边、两条出边,出边指向终节点(terminal node),即最终的分类结果Cr。
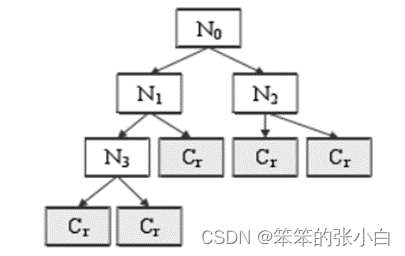
图 2 决策树结构图
决策树的构建原理大致为给定一个样本集D={ω1,……,ωn } ,根据概率分布 P 从空间 Ω 抽取 N 个独立样本,寻找一个分类树Tr 使得误分率函数Rp达到最小。决策树中,根节点和内节点都有一个属性条件Xt,Xt∈{X1,,。。。,Xm},用来分割不同分类结果的记录,因此称其为分割变量。所以,分类决策树最重要的问题就是如何选择最佳分割特征。决策树中用来筛选特征的常用的算法有 1979 年提出的 ID3 算法、1984 年提出的 CART 算法和 1993 年提出的 C4.5算法,其中 CART 最为常见。
此处需要引入增益的概念,即父节点和子节点间不纯度的差。CART 遍历自变量的所有可能值,来得到使得不纯度增益∆t(t) 最大时的点作为最佳分割点。决策树的分类实质上就是选择最大化增益,即最小化不纯性度量的加权平均值。现在设父节点、左子节点、右子节点分别为:tp、tl、tr ,分别来解释现在常用的三种度量方法:CART 中的 Gini 指数法、ID3 中的信息增益法和C4.5中的增益比率法。
1. Gini指数法
Gini 指数是使用最广泛的一种分割方式,CART 使用的就是此方法,其不纯度i(t) 见(2.2)式:
i(t)=1-j=1J{p(j∣t)}2
在上式中,J表示分类总数,p(j/t)表示在节点t中,属于j类的条件概率,对样本而言,表示第j类样本的占比。由此可以得到不纯度增益∆i(t) ,如式所示:
Δi(t)=-j=1Jp2(j∣tp)+PLj=1Jp2(j∣tp)+PRj=1Jp2(j∣tp)
Gini 指数所指的最优分割就是要求式(2.4)达到最大时的分割:
argmaxxj≤Xj2,j-1…M[-j=1Jp2(j∣tp)+PLj=1Jp2(j∣tp)+PRj=1Jp2(j∣tp)]
2. 信息增益法(information gain)
该方法的思想就是用尽量少的东西得到更多结果。首先计算每个特征的信息增益,选择最高的一个来做分裂节点。利用熵值(entropy)来度量不纯度函数i(t),如式(2.5)所示。
i(t)= entropy (T)=-i=1Jlnp(i∣T) (2.5)
父子节点熵值的差即为信息增益,如式(2.6)所示:
Δi(t)=IG(T,X,Q)= entropy (T)-j=1nlnP[qj(X)∣T]* entropy (Tj) (2.6)
3. 增益比率法(gain ratio)
方法是信息增益的改进,可以抵消因较大定义域的分类变量引起的误差,信息增益率如(2.7)式所示:
GR(T,X,Q)=IG(T,X,Q)j=1Dm(X)lnP[X=xj∣T] (2.7)
总体而言,决策树采用一种自上而下的分类策略,通过递归的方式遍历数据集的特征属性,并在每个节点选取分类性能最佳的属性进行分割,直到得到一个最佳的决策树模型。这个过程需要将数据集划分为训练集和测试集,对训练集用 CART 算法进行建模,得到分类规则,再用测试集对分类规则的性能进行评估,评估通过就可以对未知类型的数据进行分类预测。方法是信息增益的改进,可以抵消因较大定义域的分类变量引起的误差,信息增益率如(2.7)式所示。
决策树算法虽然简单好用,但存在着一些缺陷,主要有:(1)随着节点越来越多,树越来越深,某些叶子节点的记录会过少,得不出具有统计意义的规则;(2)子树可能重复出现过多次,使得决策树冗余又复杂,此时训练误差减小,但是测试误差开始增大,这就是典型的训练过度,造成模型过拟合。
要解决决策树的过拟合问题,研究学者们想出了许多种方案,如:(1)先剪枝法,在完全拟合训练集的全增长树形成时,提前结束决策树的生长,但是实际操作过程中很难确定停止的阈值;(2)后剪枝法,允许决策树过度拟合,最后将置信度过小的节点子树用叶子节点代替,但是这种方法产生了过多的额外开销。因此,在 1996 年,算法工程师们提出了随机森林方法,将决策树作为基分类器,同时引入了随机抽样和随机选取特征这两次随机过程,生成多棵决策树,以少数服从多数的方式来决定最终样本类型。随机森林不仅很好的规避了过拟合问题,还大大提升了分类精度。
随机森林定义
随机森林(Random Forest,RF),顾名思义就是将多棵相互之间并无关联的决策树整合起来形成一个森林,再通过各棵树投票或取均值来产生最终结果的分类器。在介绍随机森林前需要了解几个概念:Bootstrap 自助抽样法、Bagging 套袋法和 Boosting 提升法。
Bootstrap 是一种抽样方法,即采取随机有放回的方式采样数据,也就是每次抽取一个样本,再将其放回样本集中,下次还有可能抽到这个样本;而每轮中未抽到的数据组合起来,形成袋外数据集(Out of Band, OOB),用来在模型中做测试集。Bangging 和 Boosting 都是一种集成学习的方法,但两者有一些区别。Bagging 算法使用 Bootstrap 方法从原始样本集中随机不一定有放回的抽取n个样本,共抽取k轮,得到k个独立的训练集,元素可能有重复。每个训练集训练一个模型,得到k个结果,分类问题则从结果中取多数值作为最终结果,回归问题则取平均值作为最终结果。Boosting 则是对每个训练样本设立一个权值,被错分的样本在下一轮分类中会有更大的权值,也就是说,每轮样本相同但样本权重不同;对于分类器来说,分类误差小的拥有更大权值,分类误差大的相应权值更小。
随机森林采取的就是 bagging 方法,它将决策树用作 bagging 后的子分类模型。首先,对原始数据集使用 bootstrap 随机抽样的方法生成多个子训练集和相应的测试集,每个子训练集都构造一颗独立的决策树。其次,在构造决策树时,随机森林并不是在所有特征中找到性能最佳的特征进行分类,而是随机抽取一部分特征,在抽到的特征中间找到最优解应用于树节点进行分裂,这也是随机森林中两个关键随机步骤。最后由每个决策树投票产生最终的分类结果。随机森林由于有了 bagging,也就是集成的思想在,实际上相当于对样本和特征都进行了随机采样,所以可以避免过拟合。Bagging 策略过程如图3(a)所示,随机森林过程如图3(b)所示。
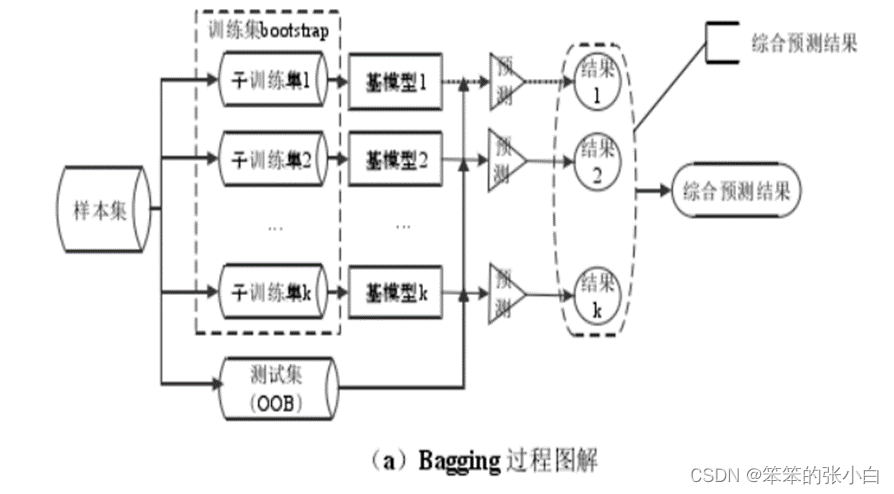
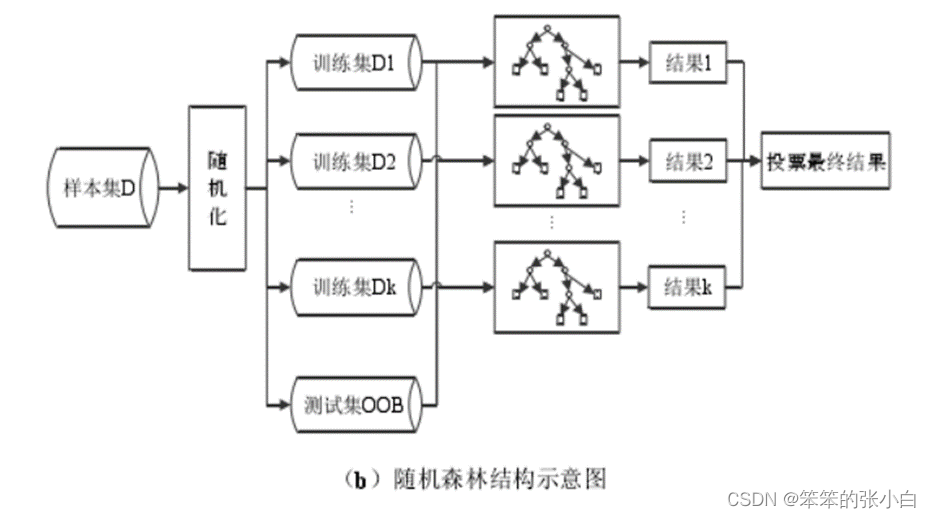
图 3 随机森林结构示意图
随机森林构建过程
随机森林的构建过程用文字表述大致如下:假设原始样本集 D(X,Y),样本个数 n,要建立 k 棵树。
1) 抽取样本集:从原始训练集中随机有放回地抽取n个样本(子训练集)并重复n次,每一个样本被抽中的概率均为1/n。被剩下的样本组成袋外数据集(OOB),作为最终的测试集。
2) 抽取特征:从总数为 M 的特征集合中随意抽取m个组成特征子集,其中m<M。
3) 特征选择:计算节点数据集中每个特征对该数据集的基尼指数,选择基尼指数最小的特征及其对应的切分点作为最优特征与最优切分点(一般方法有 ID3、CART 和信息增益率),从节点生成两个子节点,将剩余训练数据分配到两个子节点中。
4) 生成 CART 决策树:在每个子节点的样本子集中重复执行3)步骤,递归地进行节点分割,直到生成所有叶节点。
5) 随机森林:重复执行(2)~(4),得到k棵不同的决策树。
6) 测试数据:每一棵决策树都对测试集中的每一条数据进行分类,统计 k 个分类结果,票数最多的类别,即为该样本的最终类别。
随机森林算法评价
随机森林相比于传统的分类算法在分类进度上要更进一步,其次,在其他方面也有着不小的优势:
1)随机森林通过抽取不同的训练集以及随机抽取特征进行训练的方式,来达到增加分类模型间差异的目的,最终结果由彼此之间并无相关性的多棵决策树共同决定,可以很好地避免决策树分类中的过拟合问题。并且计算精度较决策树有很大提升。
2)Bagging方法产生的袋外数据集OOB可以用来做测试集,也可以做OOB估计计算出单个变量的重要程度,以此来测算模型的泛化误差。
3)随机森林一般采用 CART 作为分割特征方法,因此,随机森林可以灵活地处理连续变量或离散变量,同时不需要对变量值做归一化,大大减少了数据处理的步骤。
4)随机抽取样本和随机选取特征值是随机森林算法最大的特征之一,因此,算法能很好地容忍异常值和缺失值,避免个别差值对模型造成过大影响。
5)随机森林算法在训练过程中产生的多棵决策树之间并无关联性,因此算法非常适合在并行环境下运行,加入并行计算框架可以大大减少大体量数据集的训练时间。
尽管随机森林优势如此明显,但是该算法在特殊的应用场景下仍然有一些劣势,如医学数据、基金信贷数据等,这类数据有两个很大的特点:特征非常多且易缺失、不同种类数据量相差悬殊。第一,算法的分类思想是少数服从多数,因此在面对类别样本数相差悬殊的数据集时,容易将少数类归为多数类,造成很高的假分类精度;第二,过多的冗余特征会扰乱模型的学习能力,导致模型过拟合,限制了模型的普适性。因此,算法在这两点上有很大的改进空间。
随机森林算法的发展现状及趋势
随机森林算法采用多分类器投票的策略,本身能很好地避免过拟合问题,其中两次典型的抽样过程也使得随机森林相对于传统分类器,在解决特征冗余和过拟合问题方面有更好表现。然而,当不平衡率增加(例如正负类数量比超过 5:1)时,随机森林偏向将少数类归为多数类,造成假的高分类精度;另外,特征维度过高时,会降低单个分类器的分类性能,导致算法的整体分类能力被削弱。
多年来,原始随机森林算法被多次很多改进,如分别通过聚类方式、贪婪方法挑选出一批具有代表性的高精度低相似性决策树,这些方法提高了部分数据集的分类精度,但对上述提到的医疗健康大数据效果甚微,因此本节主要对随机森林在特征选择和不平衡领域研究现状进行分析。
1. 特征选择领域
良好的特征选择方法应该能有效地从所有特征中选择出最有用的一批特征,一些学者对此进行了大量研究。粗糙集、邻域互信息、聚类、ReliefF 算法等都是常见的筛选出强分类能力特征的方法,在随机森林中也有广泛的应用,如有人提出了卡方检验与随机森林结合的算法,用卡方检验对特征进行排序并分为不同区间,随机森林抽取不同区间的特征构建决策树,该方法能减轻过拟合的问题,但也会导致结果产生偏向性;有人提出了一种基于最大互信息系数的随机森林算法,利用最大互信息衡量特征的区分能力,并将特征分为高中低三个子集,从每个子集中抽取特征构建决策树,很好地避免了干扰树的产生,但是每棵树分类能力过于平均,容易引起过拟合问题;Vakharia 等先用 ReliefF 算法计算特征的权重,删除低于权值的特征后再进行随机森林训练,有效地提高了轴承故障诊断的准确率;也有人利用肯德尔系数来代替随机森林的随机特征选择步骤,在医学数据集中取得了不错的效果。
2. 不平衡分类领域
不平衡数据指的是在某一个数据集中不同类型的样本数量悬殊过大。常用的一些解决方法如过采样、欠采样、混合抽样等是从数据层面来使数据集达到相对类均衡,还有SMOTE、GAN 等方法是从算法层面通过一定的计算来生成新的少数类,也能有效的解决不平衡问题。已经有不少学者将上述方法应用到随机森林中,如有人通过对多数样本欠采样,对少数样本过采样的方式使数据相对类均衡,并在随机森林算法中进行实验,一定程度下提高了算法的分类精度,但是数据量缩减了很多;有人采用 SMOTE 算法计算出一批少数类样本,降低了数据的不平衡程度,然而该方法不能保证伪样本的类型正确性;有人提出了一种基于 GAN 的随机森林算法,采用集成学习 GAN 来生成少数类,以得到分布平衡的数据集;还有其他针对不平衡问题的改进研究,如有人等提出了一种基于随机森林算法的类权重投票(CWsRF)算法,为每个类分配单独的权重,有效提高了少数类的识别性能;也有人采用 k-means 聚类算法计算每个类的区分度,将区分度应用到随机森林的特征选择步骤中,减轻了不平衡数据集对算法的影响。
实验步骤
1.导入模块与数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
import seaborn as sns
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix,accuracy_score
import warnings
warnings.filterwarnings('ignore')
plt.rcParams['font.sans-serif']=['SimHei'] #显示中文标签
plt.rcParams['axes.unicode_minus']=False# 导入数据
data = pd.read_csv('data.csv')
data.head()Age Height Weight family_history_with_overweight FAVC FCVC NCP CAEC SMOKE CH2O SCC FAF TUE CALC MTRANS NObeyesdad
0 Female 21.0 1.62 64.0 yes no 2.0 3.0 Sometimes no 2.0 no 0.0 1.0 no Public_Transportation Normal_Weight
1 Female 21.0 1.52 56.0 yes no 3.0 3.0 Sometimes yes 3.0 yes 3.0 0.0 Sometimes Public_Transportation Normal_Weight
2 Male 23.0 1.80 77.0 yes no 2.0 3.0 Sometimes no 2.0 no 2.0 1.0 Frequently Public_Transportation Normal_Weight
3 Male 27.0 1.80 87.0 no no 3.0 3.0 Sometimes no 2.0 no 2.0 0.0 Frequently Walking Overweight_Level_I
4 Male 22.0 1.78 89.8 no no 2.0 1.0 Sometimes no 2.0 no 0.0 0.0 Sometimes Public_Transportation Overweight_Level_II2.查看数据
# 查看数据大小
data.shape(2111, 17)该数据共有2111行,17列数据
# 查看数据类型
data.dtypesGender object
Age float64
Height float64
Weight float64
family_history_with_overweight object
FAVC object
FCVC float64
NCP float64
CAEC object
SMOKE object
CH2O float64
SCC object
FAF float64
TUE float64
CALC object
MTRANS object
NObeyesdad object
dtype: object数据类型有object和float两种类型
# 查看数值型数据描述
data.describe()Age Height Weight FCVC NCP CH2O FAF TUE
count 2111.000000 2111.000000 2111.000000 2111.000000 2111.000000 2111.000000 2111.000000 2111.000000
mean 24.312600 1.701677 86.586058 2.419043 2.685628 2.008011 1.010298 0.657866
std 6.345968 0.093305 26.191172 0.533927 0.778039 0.612953 0.850592 0.608927
min 14.000000 1.450000 39.000000 1.000000 1.000000 1.000000 0.000000 0.000000
25% 19.947192 1.630000 65.473343 2.000000 2.658738 1.584812 0.124505 0.000000
50% 22.777890 1.700499 83.000000 2.385502 3.000000 2.000000 1.000000 0.625350
75% 26.000000 1.768464 107.430682 3.000000 3.000000 2.477420 1.666678 1.000000
max 61.000000 1.980000 173.000000 3.000000 4.000000 3.000000 3.000000 2.000000可以看出数值型数据的总数、平均值、标准差、最大最小值、4分位值
# 查看非数值型数据描述
data.describe(include=np.object) Gender family_history_with_overweight FAVC CAEC SMOKE SCC CALC MTRANS NObeyesdad
count 2111 2111 2111 2111 2111 2111 2111 2111 2111
unique 2 2 2 4 2 2 4 5 7
top Male yes yes Sometimes no no Sometimes Public_Transportation Obesity_Type_I
freq 1068 1726 1866 1765 2067 2015 1401 1580 351可以看出非数值型数据的总数、数值类型的个数、出现次数最多的值以及出现的频率
3.数据预处理
# 查看缺失值
data.isnull().sum()Gender 0
Age 0
Height 0
Weight 0
family_history_with_overweight 0
FAVC 0
FCVC 0
NCP 0
CAEC 0
SMOKE 0
CH2O 0
SCC 0
FAF 0
TUE 0
CALC 0
MTRANS 0
NObeyesdad 0
dtype: int64可以看出数据没有缺失值,不需要处理
# 查看重复值
any(data.duplicated())Truedata.duplicated()返回的是一堆布尔值,重复数据第一次出现为False,第二次以后均为True,故我们可以用any()函数来进行判断,当数据只要有有一个重复值,则最终结果为True,否则为False。本次为True,说明数据存在重复值。需要处理
# 删除重复行
data.drop_duplicates(inplace=True)data.shape(2087, 17)原始数据有2111行,删除重复值还剩2087行
4.可视化分析
不同肥胖程度的总人数
data['NObeyesdad'].value_counts().plot.barh() 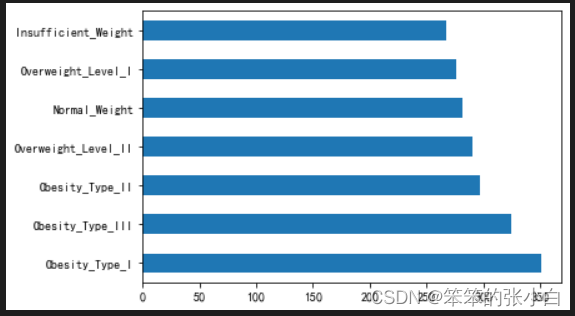
我们可以看出不同程度的人数相差不大
分析不同肥胖程度的男女比例
sex_group = data.groupby(['NObeyesdad','Gender'])['Gender'].count()
sex_groupsex_group.plot(kind='bar')NObeyesdad Gender
Insufficient_Weight Female 169Male 98
Normal_Weight Female 137Male 145
Obesity_Type_I Female 156Male 195
Obesity_Type_II Female 2Male 295
Obesity_Type_III Female 323Male 1
Overweight_Level_I Female 145Male 131
Overweight_Level_II Female 103Male 187
Name: Gender, dtype: int64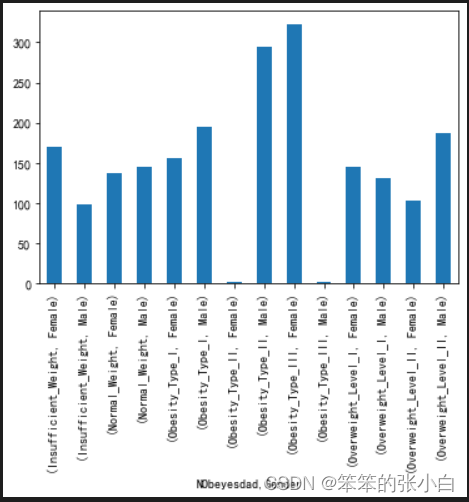
在体重瘦弱人数中,女性远多于男性;在肥胖2级人数中,男性远超过女性;在肥胖3级人数中,女性远超过男性;其余比例相差不大。
分析家庭肥胖历史对肥胖程度的影响
family_group = data.groupby(['NObeyesdad','family_history_with_overweight'])['family_history_with_overweight'].count()
family_groupfamily_group.plot.bar()NObeyesdad family_history_with_overweight
Insufficient_Weight no 142yes 125
Normal_Weight no 130yes 152
Obesity_Type_I no 7yes 344
Obesity_Type_II no 1yes 296
Obesity_Type_III yes 324
Overweight_Level_I no 67yes 209
Overweight_Level_II no 18yes 272
Name: family_history_with_overweight, dtype: int64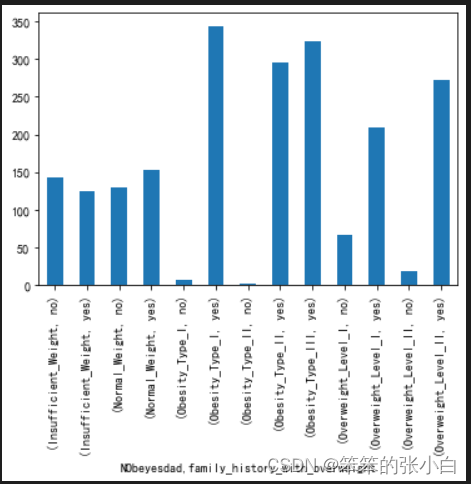
我们可以看出肥胖1-3级和超重1-2级的人数几乎都有家庭肥胖历史,说明家庭肥胖是可以遗传给后代的。
特征相关性分析
#相关性import seaborn as sns
fig = plt.figure(figsize=(18,18))
sns.heatmap(data.corr(),vmax=1)
画出热力图便于观察个特征之间的相关性,颜色越深说明相关性越强
5.特征工程
为了后面更好的建立模型,我们将NObeyesdad肥胖等级用0-6来表示 体重不足、正常体重、超重一级、超重二级、肥胖一级、肥胖二级和肥胖三级;将CAEC、CALC的值用1-4表示;将MTRANS值用1-5表示;将family_history_with_overweight、FAVC、SMOKE、SCC、Gender的值用0,1表示。
# 将NObeyesdad肥胖等级用0-6来表示 体重不足、正常体重、超重一级、超重二级、肥胖一级、肥胖二级和肥胖三级
data.NObeyesdad.replace(to_replace={'Insufficient_Weight':0,'Normal_Weight':1,'Overweight_Level_I':2,'Overweight_Level_II':3,'Obesity_Type_I':4,'Obesity_Type_II':5,'Obesity_Type_III':6},inplace=True)
data['NObeyesdad'].value_counts()# 将CAEC、CALC的值用1-4表示
data.CAEC.replace(to_replace={'no':1,'Sometimes':2,'Frequently':3,'Always':4},inplace=True)
data.CALC.replace(to_replace={'no':1,'Sometimes':2,'Frequently':3,'Always':4},inplace=True)# 将MTRANS值用1-5表示
data.MTRANS.replace(to_replace={'Bike':1,'Motorbike':2,'Walking':3,'Automobile':4,'Public_Transportation':5},inplace=True)# 将family_history_with_overweight、FAVC、SMOKE、SCC、Gender的值用0,1表示
data['family_history_with_overweight'] = data['family_history_with_overweight'].apply(lambda x:0 if x == 'no' else 1)
data['FAVC'] = data['FAVC'].apply(lambda x:0 if x == 'no' else 1)
data['SMOKE'] = data['SMOKE'].apply(lambda x:0 if x == 'no' else 1)
data['SCC'] = data['SCC'].apply(lambda x:0 if x == 'no' else 1)
data['Gender'] = data['Gender'].apply(lambda x:0 if x == 'Female' else 1)来看一下经过值变换后的结果
data.head(10) Gender Age Height Weight family_history_with_overweight FAVC FCVC NCP CAEC SMOKE CH2O SCC FAF TUE CALC MTRANS NObeyesdad
0 0 21.0 1.62 64.0 1 0 2.0 3.0 2 0 2.0 0 0.0 1.0 1 5 1
1 0 21.0 1.52 56.0 1 0 3.0 3.0 2 1 3.0 1 3.0 0.0 2 5 1
2 1 23.0 1.80 77.0 1 0 2.0 3.0 2 0 2.0 0 2.0 1.0 3 5 1
3 1 27.0 1.80 87.0 0 0 3.0 3.0 2 0 2.0 0 2.0 0.0 3 3 2
4 1 22.0 1.78 89.8 0 0 2.0 1.0 2 0 2.0 0 0.0 0.0 2 5 3
5 1 29.0 1.62 53.0 0 1 2.0 3.0 2 0 2.0 0 0.0 0.0 2 4 1
6 0 23.0 1.50 55.0 1 1 3.0 3.0 2 0 2.0 0 1.0 0.0 2 2 1
7 1 22.0 1.64 53.0 0 0 2.0 3.0 2 0 2.0 0 3.0 0.0 2 5 1
8 1 24.0 1.78 64.0 1 1 3.0 3.0 2 0 2.0 0 1.0 1.0 3 5 1
9 1 22.0 1.72 68.0 1 1 2.0 3.0 2 0 2.0 0 1.0 1.0 1 5 16.构建模型
首先要划分数据集
# 划分训练集和测试集
X = data.drop('NObeyesdad',axis=1)
y = data['NObeyesdad']
x_train,x_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=42)1.构建决策树模型
# 决策树
tree = DecisionTreeClassifier()
tree.fit(x_train,y_train)
y_pred = tree.predict(x_test)
print('模型准确率',accuracy_score(y_test,y_pred))
print(confusion_matrix(y_test,y_pred))模型准确率 0.9138755980861244
[[54 5 0 0 0 0 0][ 8 42 11 0 0 0 0][ 0 4 49 1 1 0 0][ 0 0 0 47 2 0 0][ 0 0 0 2 67 1 0][ 0 0 0 0 1 63 0][ 0 0 0 0 0 0 60]]我们可以看出决策树模型的准确率为0.91,下面是它的混淆矩阵
2.构建随机森林模型
# 训练模型
rfc = RandomForestClassifier(n_estimators=1000)
rfc.fit(x_train,y_train)
y_pred = rfc.predict(x_test)
print('模型准确率',accuracy_score(y_test,y_pred))
print(confusion_matrix(y_test,y_pred))
#打印特征重要性评分
feat_labels = x_train.columns[0:]
importances = rfc.feature_importances_
indices = np.argsort(importances)[::-1]
for f,j in zip(range(x_train.shape[1]-1),indices):print(f + 1, feat_labels[j], importances[j])模型准确率 0.9688995215311005
[[56 3 0 0 0 0 0][ 1 58 2 0 0 0 0][ 0 4 50 1 0 0 0][ 0 0 0 49 0 0 0][ 0 0 0 2 68 0 0][ 0 0 0 0 0 64 0][ 0 0 0 0 0 0 60]]
1 Weight 0.3461717299548839
2 Height 0.10306677126361354
3 Age 0.09179444276446319
4 FCVC 0.08913744112847972
5 Gender 0.060092403930844605
6 NCP 0.05001535496608815
7 TUE 0.0453552733033558
8 FAF 0.041620900666372085
9 CH2O 0.040322835978721744
10 family_history_with_overweight 0.031376522711946964
11 CAEC 0.029667089265592847
12 CALC 0.028755767084792445
13 MTRANS 0.01894906014847046
14 FAVC 0.016471000893701973
15 SCC 0.0051458394162270426我们可以看出随机森林模型的准确率为0.968,其中重要特征排名中,体重、身高、年龄、食用蔬菜的评率、性别、主餐次数等因素重要程度得分较高,说明重要程度越高。
3.构建GBDT模型
from sklearn.ensemble import GradientBoostingClassifiergbdt = GradientBoostingClassifier()
gbdt.fit(x_train,y_train)
y_pred = gbst.predict(x_test)
print('模型准确率',accuracy_score(y_pred,y_test))
print(confusion_matrix(y_test,y_pred))模型准确率 0.9617224880382775
[[54 5 0 0 0 0 0][ 3 53 5 0 0 0 0][ 0 1 54 0 0 0 0][ 0 0 0 49 0 0 0][ 0 0 0 1 69 0 0][ 0 0 0 0 1 63 0][ 0 0 0 0 0 0 60]]我们可以看出模型的准确率为0.96,准确率较高
综上3种分类模型算法,随机森林模型的准确率最高,我们建议用随机森林来进行预测和探究肥胖的成因。
实验总结
肥胖是一种全球性的疾病,无论人们的社会或文化水平如何,它始终都是热点话题,而且全球患者的数量逐年增长。为了帮助对抗这种疾病,开发工具和解决方案去检测或预测疾病的出现显得非常重要,而数据挖掘是让我们发现信息的重要工具。
本文使用随机森林算法对数据集进行处理,通过对多个影响因子进行多标签分类获取各影响因子与肥胖水平之间的权值,由此建立肥胖评估模型,模型准确率达到96%,从而探究肥胖的成因。实验结果表明了众多影响因子与肥胖水平之间的关系,肥胖家族病史与肥胖水平之间强正相关,年龄以及是否经常食用高热量也与肥胖水平之间呈较强的正相关关系,也就是说,通常有肥胖家族病史的人患病可能性更大,年龄越大以及经常食用高热量食物的人更容易肥胖;是否进行卡路里消耗监测以及是否经常活动身体等与肥胖水平有着负相关关系,换言之,规律的监测卡路里消耗以及频繁的身体活动可以降低患病几率;是否频繁饮酒、长时间使用技术设备每日饮水量等对肥胖水平有一定影响。
因此,根据实验结果,要想控制肥胖应努力加强家庭可以采用的健康习惯,例如均衡白天的饮食、确定饮食时间、少吃高热量的食物、降低饮酒频率等;必须认识到,除了饮食变化外,增加日常体育活动,例如每天至少步行半小时,每天至少喝两升水,是必不可少的,因为没有不锻炼的饮食;对卡路里消耗进行规律检测,减少使用技术设备的时间等。儿童和成人的高肥胖率是导致总体肥胖率较高的原因,我们再也不能对此视而不见,应在生命早期阶段就进行预防和控制,这样才能可持续的解决肥胖问题,而我们每一个人也应该提高认识,养成健康的生活习惯。
随着云计算、物联网和移动互联网等技术的飞速发展,数据的类型和规模以前所未有的速度增长,而人工智能和数据挖掘的快速发展提高了数据管理效率。通过本实验对实际案例的研究与学习,对数据挖掘有关的知识有了初步的了解,为以后继续学习数据挖掘与分析奠定了基础。
因为对数据挖掘不够了解,实验过程中遇到了很多问题。实验仍存在很多问题,如实验结果与实际情况存在偏差,模型准确率有待提高;算法的很多代码不够完善,存在漏洞;对实验结果分析不够深入,有待进一步挖掘等等。针对这些不足,在今后不断学习过程中会不断完善。