LRN全称为Local Response Normalization,即局部响应归一化层,具体实现在CAFFE_ROOT/src/caffe/layers/lrn_layer.cpp和同一目录下lrn_layer.cu中。
为什么输入数据需要归一化(Normalized Data)?
归一化后有什么好处呢?原因在于神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另外一方面,一旦每批训练数据的分布各不相同(batch 梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度,这也正是为什么我们需要对数据都要做一个归一化预处理的原因。
对于深度网络的训练是一个复杂的过程,只要网络的前面几层发生微小的改变,那么后面几层就会被累积放大下去。一旦网络某一层的输入数据的分布发生改变,那么这一层网络就需要去适应学习这个新的数据分布,所以如果训练过程中,训练数据的分布一直在发生变化,那么将会影响网络的训练速度。
该层需要参数有:
norm_region: 选择对相邻通道间归一化还是通道内空间区域归一化,默认为ACROSS_CHANNELS,即通道间归一化;
local_size:两种表示(1)通道间归一化时表示求和的通道数;(2)通道内归一化时表示求和区间的边长;默认值为5;
alpha:缩放因子(详细见后面),默认值为1;
beta:指数项(详细见后面), 默认值为5;
局部响应归一化层完成一种“临近抑制”操作,对局部输入区域进行归一化。
在通道间归一化模式中,局部区域范围在相邻通道间,但没有空间扩展(即尺寸为 local_size x 1 x 1);
在通道内归一化模式中,局部区域在空间上扩展,但只针对独立通道进行(即尺寸为 1 x local_size xlocal_size);
每个输入值都将除以
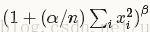
[写作时的 Caffe版本较旧,新版 Caffe已经增加参数 k,变为(k + (alpha / n) ……))]
其中 n 为局部尺寸大小local_size, alpha和beta前面已经定义。
求和将在当前值处于中间位置的局部区域内进行(如果有必要则进行补零)。
![ldr r0, =0x12345678,ldr r0, [r0]的含义说明](/images/no-images.jpg)


