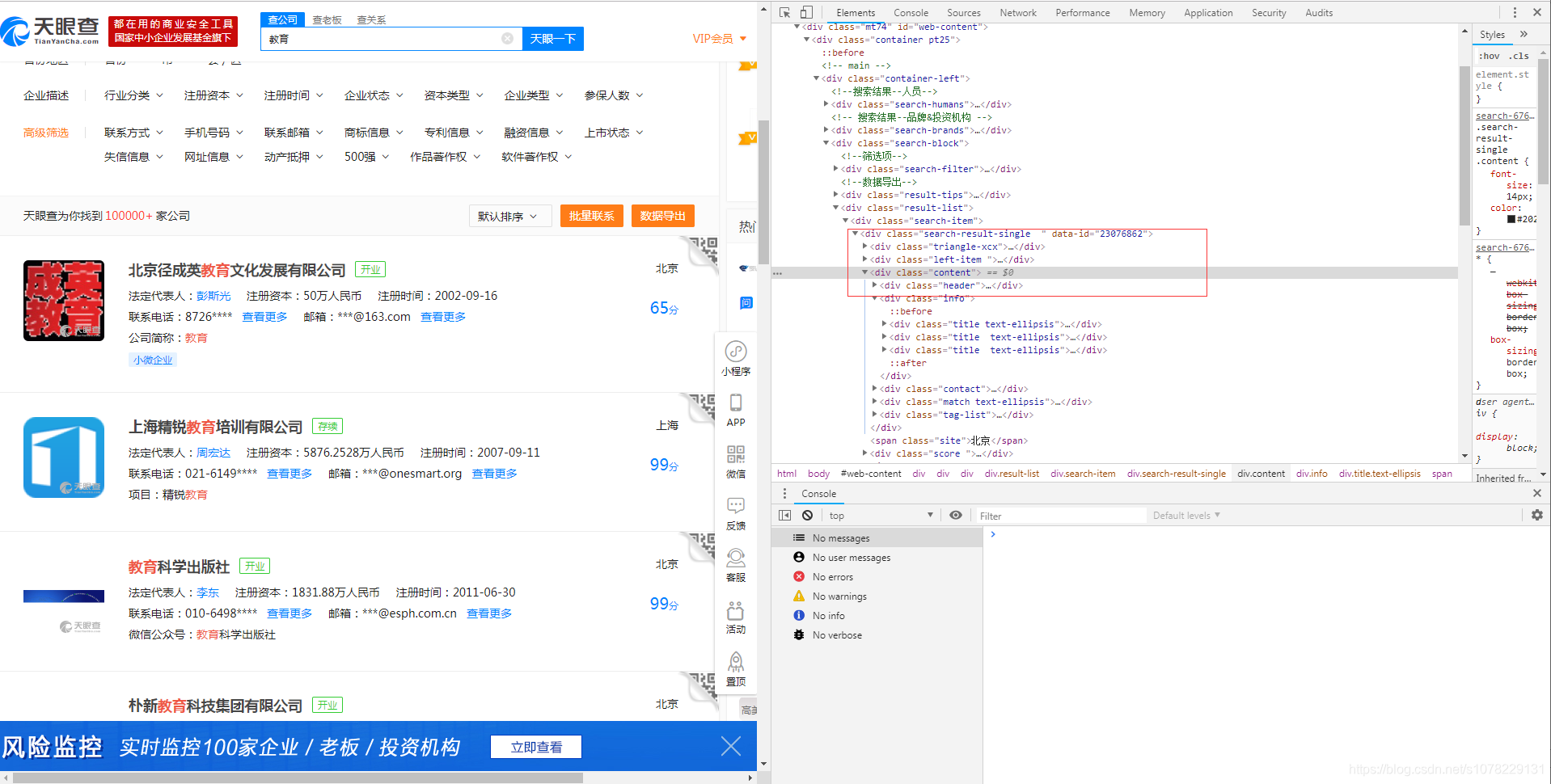
最近接到一个需求,终端要加入企业图谱的功能、能无线穿透下去,之前写过一个类似树形图但是节点长度没有自适应(如下图),样式也不够好看,产品提出做一个类似企查查那种的企业图谱,能更直观的展示企业信息,无奈只能继续研究....
改版前

改版后:

新版的是用的d3.v5版本的,因为之前用的是v3版,但是v5改动比较大还是得对照着D3的官方文档和实例。
顺便附带上所需版本APi链接 d3v5: https://github.com/d3/d3/blob/master/API.md#axes-d3-axis d3v3 https://github.com/d3/d3/wiki/API--%E4%B8%AD%E6%96%87%E6%89%8B%E5%86%8C
接下来就是写代码了,
基础布局想必大家照着官方demo都可以实现,直接搬过来就行。
官方api demo给的都是最简单的实现,所以大部分还是的自己加的。这里有两个问题1、 节点位置(长度)计算、2、链接线的绘制,我这里是自定义的线,默认的好像是贝赛尔曲线,我这里运用svg的基础画线方式Path(M,H, S,L,V,A,Q,C这样的基础属性)。
首先节点位置计算(包含节点长度),我们需要在绘制图像之前根据当前layer的最长文字长度来确定下一层级节点的开始位置,我是写了一个方法来专门计算当前层级最大的长度,来保证整个布局不会出现重叠现象的....
刚开始我用字体长度length * this.fontSize的方式算出的字体长度,但是因为文本中包含很多未知的符号()% 导致长度计算不准确,后来想到一个笨方法
遍历数据把它们放到text 中通过d3.select(this.getComputedTextLength())这个方法来获取能到准确长度,如果小伙伴有更好的方法可以加扣扣交流一下qq1414452830

长度计算出来,节点的位置就能确定,链接线就能直接画出参考svgPath,第一次写博客有点匆忙、很多点没有说明白、需要源码的小伙伴可以评论或加qq,下次讲解力项导图、股权穿透图可以细化一点....