Python简单爬取电影磁力链接
网页的链接:http://www.ygdy8.net/html/gndy/dyzz/list_23_2.html
打开你想要的电影:http://www.ygdy8.net/html/gndy/dyzz/20181124/57807.html
找到下载地址:

代码:
import requests#网络请求模块
import re #提取数据
for n in range(1, 187):
# 网址
a_url = ‘http://www.ygdy8.net/html/gndy/dyzz/list_23_’ + str(n) + ‘.html’
#打印检查页面链接
print(a_url)
打印出的网页链接:

一共186页

for n in range(1, 2):# 网址a_url = 'http://www.ygdy8.net/html/gndy/dyzz/list_23_' + str(n) + '.html'#print(a_url)html_1 = requests.get(a_url)html_1.encoding='gb2312'print(html_1.status_code) #200re.findall #列表detil_list=re.findall('<a href="(.*?)" class="ulink',html_1.text)print(detil_list)#返回列表[]
以列表形式返回提取的每个电影链接:(还不是完整的链接)
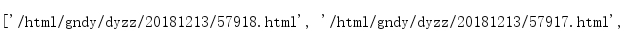
#拼接网址:
for m in detil_list:b_url = 'http://www.ygdy8.net'+mhtml_2 = requests.get(b_url)html_2.encoding = 'gb2312' # 网站格式‘gb2312’,防乱码#print(b_url)
提取完整下载链接代码:
ftp=re.findall('<a href="(.*?)">.*?</a></td>',html_2.text)print(ftp)#打印列表html_2

打印到txt文本代码:
with open('C:\\Users\\张云强\\Desktop\\test\\dytt.txt','a',encoding='utf-8')as f:#写入本地 write写文本f.write(ftp[0]+'\n')
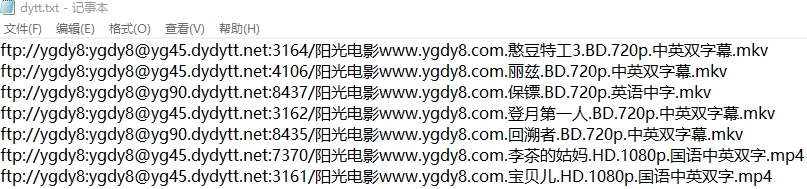
把txt文本的链接复制到迅雷下载即可。
最终代码:
import requests#网络请求
import re#提取数据def xb(pages):for n in range (1,pages):#网址a_url = 'http://www.ygdy8.net/html/gndy/dyzz/list_23_'+str(n)+'.html'#print(a_url)html_1=requests.get(a_url)html_1.encoding = 'gb2312'# print(html_1.status_code) #200#print(html_1.text) #查看网页源代码# re.findall 列表detil_list=re.findall('<a href="(.*?)" class="ulink',html_1.text)# print(detil_list)for m in detil_list:#for m in detil_list[0]:提取一个b_url ='http://www.ygdy8.net/'+ m#print(b_url)html_2=requests.get(b_url)#指定网页编码格式html_2.encoding = 'gb2312'#print(html_2.text)#re.findall()返回列表ftp = re.findall('<a href="(.*?)">.*?</a></td>',html_2.text)#print(ftp)打印查看with open('C:\\Users\\张云强\\Desktop\\test\\dytt.txt','a',encoding='utf-8')as f:#写入本地 write写文本f.write(ftp[0]+'\n')xb(20)
![[初学Python]利用某网站的功能写一个磁力链转种子工具](/images/no-images.jpg)