作者 | 一笑泯恩仇 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/507722579
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【BEV感知】技术交流群
后台回复【3D检测综述】获取最新基于点云/BEV/图像的3D检测综述!
概述
自动驾驶需要准确表示自我车辆周围的环境。环境包括道路布局和车道结构等静态元素,以及其他汽车、行人和其他类型的道路使用者等动态元素。静态元素可以通过包含车道级别信息的高清地图捕获。
通常通过offline mapping和online mapping得到。offline mapping可以认为是高精地图,包括众包、激光、卫星和无人机等方案,其主要的思想是slam。online mapping就是现在流程的bev方案,在bev上做语义分割和检测,在线生成地图。这个BEV并非一个新的东西,轨迹预测和规划通常在这种自上而下的视图(或鸟瞰图,BEV)中完成,因为高度信息不太重要,而自动驾驶汽车所需的大部分信息可以是方便地用 BEV 表示。
传统计算机视觉任务,在相同的坐标系中进行估计。像检测、分割等任务输出还是在图像坐标系中——透视图空间。透视空间变换到BEV上,对于单目,没有明确的深度信息,使得两种空间转换存在鸿沟。
过去的做法,一种是IPM,另一种通过双目等手段,得到深度信息。IPM使用了几何先验:地平面假设和相机外参不变,这两个条件,在实际中很容易不满足。
另一个挑战是如何在在3D上进行标注。一种方法是让无人机始终跟随自动驾驶汽车(类似于MobileEye 的 CES 2020 演讲),然后通过人工进行标注。
BEV方案,关键在于如何从相机的透视空间的特征编码到BEV上。下面有列出主要几种方案
IPM
逆透视变换,见real:IPM
Cam2BEV[8]
本文是讨论如何给定来自多个车载摄像机图像获得校正的360度BEV图像。校正的BEV图像被分割成语义类别,并且包括对遮挡区域的预测。神经网络方法并不依赖手动标记数据,而是在模拟合成数据集上进行训练,并泛化到现实世界数据。以语义分割图像作为输入,可以减少模拟数据与现实世界数据之间的现实差距,并也证明该方法可以成功应用于现实世界中。
将图像特征转换到BEV下,采用的是IPM方法,具体的网络实现如下:
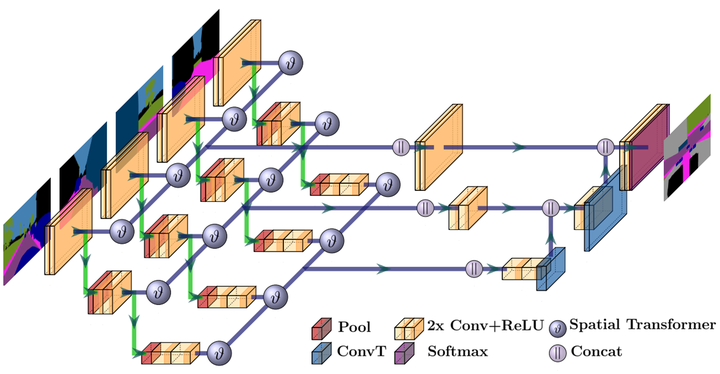
上图中,不同金字塔特征单独去做IPM转换,下一层金字塔特征是在做IPM变换前的featuremap上做的conv,做降采样的。最后只在结果级特征上做IPM,再进行concat。
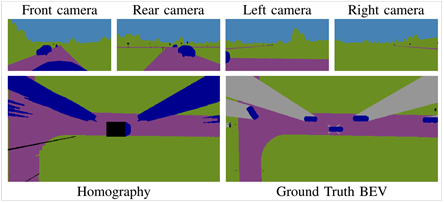
从上
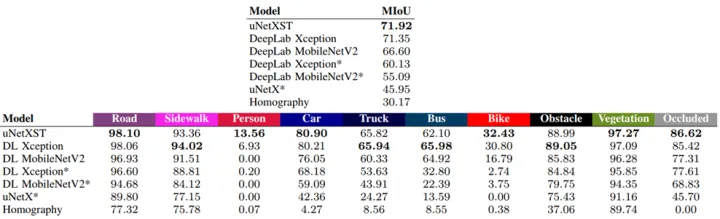
上面的表格中,Homography是基线,是直接将gt投影到BEV上;DL(deeplab)是直接B将多个视角的BEV图进行concat,uNetXST是在特征层使用了IPM,带* 的表示没有使用IPM。使用仿真数据进行实验的。从上述结果来看,特征层concat要稍好,但没有IPM就差很多了。另外行人和自行车效果非常差,原因是小目标。
学习变换空间
VPN[2]
VPN(Cross-view Semantic Segmentation for Sensing Surroundings)是最早探索BEV语义分割的作品之一,将其称为“cross-view语义分割”。这篇文章讨论的是跨域视图语义分割,定义一种名为View Parsing Network (VPN)的框架来解决该问题。在跨视图语义分割任务中,训练后将第一视图观察结果解析为从上到下的语义图,指出所有目标在像素级的空间位置。此任务的主要问题是缺乏自上而下的视图数据的真实注释。为了缓解这种情况,在3D图形环境中训练VPN,并利用域自适应技术将其迁移到实际数据。
下图是原理图。输入由N个视角,M种模态,即6个相机,2个模态(rgb和depth)。对rgb和depth,分别进行cnn编码,得到 HWC 的特征,针对featuremap上每个点,学习一个透视空间到bev空间的变换R,即文章中写的
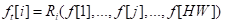
这个类似的实现,在pointnet里有类似的操作,即通过MLP实现。将featuremap reshape到上 HW*C大小,这样每个点,通过MLP,在针对rgb和depth一起fusion下,就得到了BEV下的特征,后面进行decode做分割。
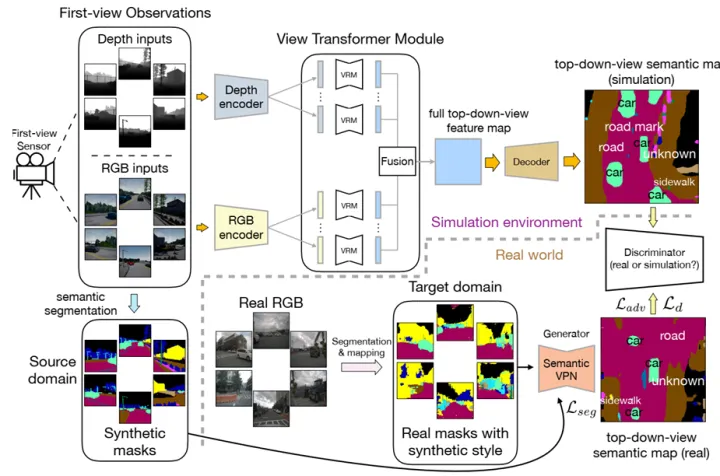
于实际缺乏数据,所以作者在仿真数据上做。为了缓解仿真到实际的差异,作者通过GAN的思想,设计了sim2real。为了减小差异,将实际的rgb图,通过全景分割得到mask图,mask通过VPN得到BEV的分割结果。上图展示真实世界通过VPN迁移到现实世界的域自适应过程。输入有两种,一种是实际图像得到的全景分割的mask,一种是仿真的mask。
下面是作者的结果:

这种方法,忽略了强几何先验,而纯粹采用数据驱动的方法来学习透视到 BEV 的变形。这种变形是特定于相机的,每个相机都必须学习一个网络。该方法需要保持输入与输出的大小一致,而实际上是不需要的。
FishingNet[3]
Fishing Net将激光雷达、雷达和相机融合转换为 BEV 空间中的单一统一表示。这种表示使得跨不同模式执行后期融合变得更加容易。多个神经网络,每个传感器模态(雷达,雷达和摄像头)一个,接收一系列输入传感器数据,并输出代表3个目标类别(弱势道路用户即VRU、车辆和背景)的一系列自上而下的共享语义网格;然后,使用聚合函数融合序列,以输出语义网格的融合序列。
下图中的图像的网络结构中有orthographic feature transformation模块,它就是采用VPN中的MLP。由于变换是自己学习到的,可以多视角,时序上都通过MLP结构进行融合。
该网络结构的BEV的分辨率为10cm和20cm,这个比offline mapping中的4-5cm粗多了。
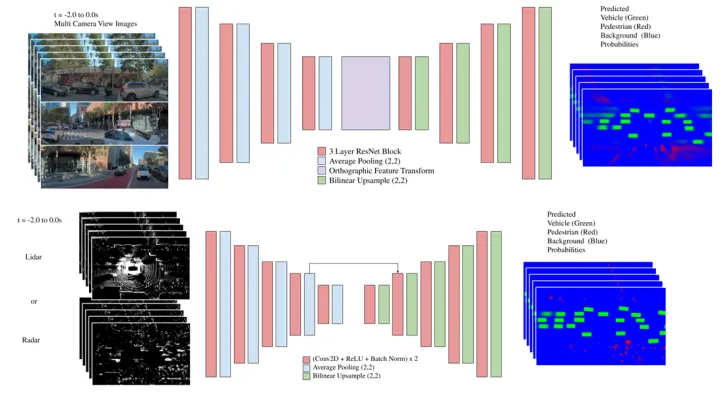
这里需要提及下lidar与radar的BEV特征。
LiDAR共8个维度的特征,包括:1)二进制激光雷达占用率(如果给定的网格单元中存在激光雷达点,则为1,否则为0)。2)激光雷达密度(在一个网格中所有激光雷达点的对数归一化密度)。3)Max z(给定网格单元激光雷达点的最大高度值)。4)最大z切片(每个网格单元在5个线性切片的最大z值,例如0-0.5m,...,2.0-2.5m)。
雷达共6个维度的特征,包括:1)二进制雷达占用率(如果在给定的网格单元中存在任何雷达点,则为1,否则为0);2)每个雷达回波多普勒速度的X,Y值,均用自车运动进行了补偿;3)雷达横截面(RCS);4)信噪比(SNR);5)多义的多普勒间隔。
VAE
VAE介绍[4]
通过VAE(变分自编码Variational Autoencoder),得到其转换关系。这里先简单介绍下VAE。
autoencode,结构很简单,如下:
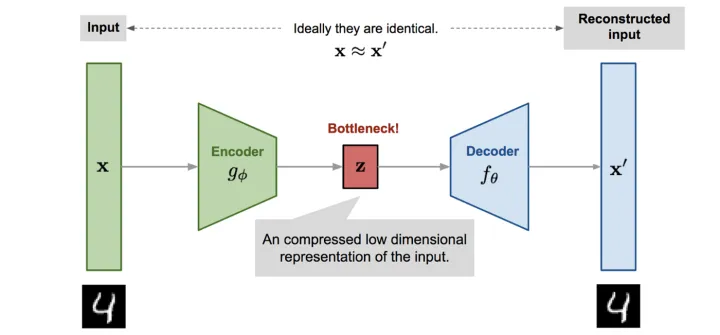
而VAE结构如下:
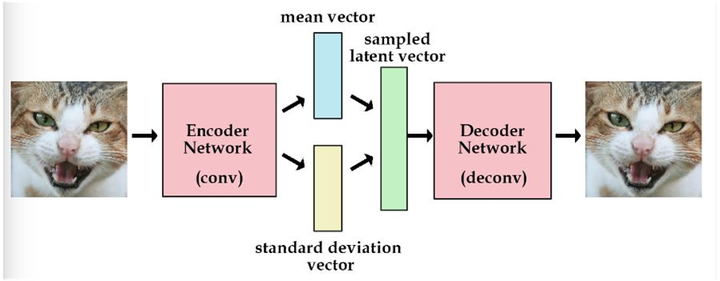
将中间的z,换成了均值和方差(两个都是向量,并非是一个值)了,这到底是什么意思呢?这个是改进autoencode产生的。如果输入是一个随机噪音,输出是一张图,是否能够训练呢?很明显,不可能,绝不可能。
实际上是可能的,机器学习中,每个样本都有自己的噪音,现在比较流行学习不确定度(uncertainty),就是能够学习到该样本的输出与gt之间的均值和方差,在网络中预测均值和方差即可
如何训练呢?
回归任务假设需要学的真实值是 ,回归出来的东西是 ,一般就是最小化MSE损失:
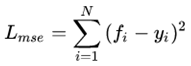
但是加入不确定度之后,回归出来的就不只是一个值了,而是一个由均值 和方差 决定的一整个高斯分布,于是问题就变成了要最大化一个likelihood:
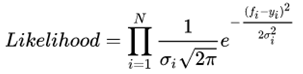
然后优化这个损失函数就可以了,方差也就一起学出来了,方差越大,高斯分布越扁平,不确定度也就越大。同时方差越大损失也越大,意味着我们希望能学到确定性高的东西。
实际上,还可以学习样本本身的方差,那就BNN。那如果我们反过来,输入一个噪音,也可以输出对应的样本,但每个样本的均值和方差是不一样的。所以这里采用学习均值和方差,来生成数据。
如果后面的sample latent vector也是全部是学习的,没有加入人工的东西,学习到最后方差为0了,这样就会退化为autoencode,噪声不再起作用。所以对均值和方差向标准方差看齐,就能够防止噪音为0了。
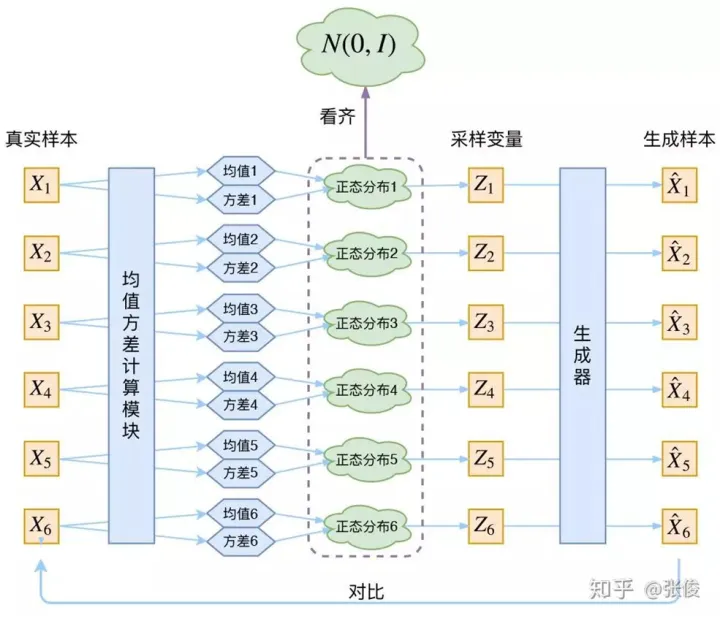
那问题来了,我怎么用这个均值和方差,得到后面的向量,这里实际上又重采样进行恢复了
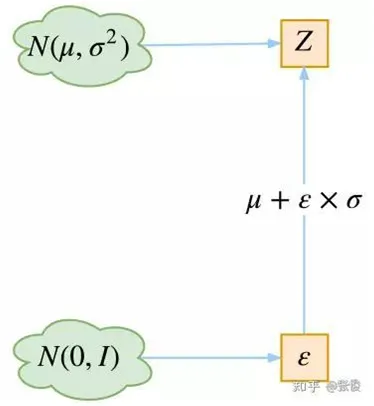

在 VAE 中,它的 Encoder 有两个,一个用来计算均值,一个用来计算方差,这已经让人意外了:Encoder 不是用来 Encode 的,是用来算均值和方差的,这真是大新闻了,还有均值和方差不都是统计量吗,怎么是用神经网络来算的?
事实上,我觉得 VAE 从让普通人望而生畏的变分和贝叶斯理论出发,最后落地到一个具体的模型中,虽然走了比较长的一段路,但最终的模型其实是很接地气的。
它本质上就是在我们常规的自编码器的基础上,对 encoder 的结果(在VAE中对应着计算均值的网络)加上了“高斯噪声”,使得结果 decoder 能够对噪声有鲁棒性;而那个额外的 KL loss(目的是让均值为 0,方差为 1),事实上就是相当于对 encoder 的一个正则项,希望 encoder 出来的东西均有零均值。
那另外一个 encoder(对应着计算方差的网络)的作用呢?它是用来动态调节噪声的强度的。
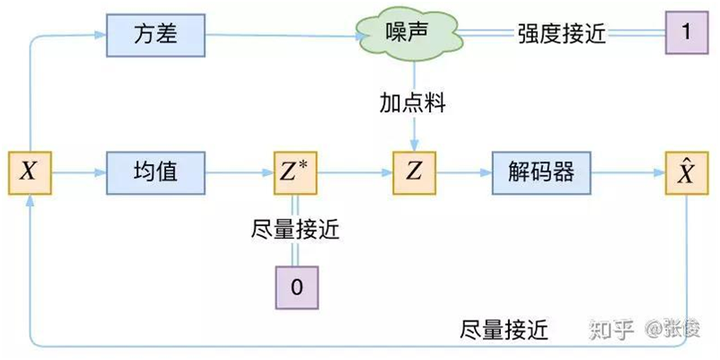
所以loss为:
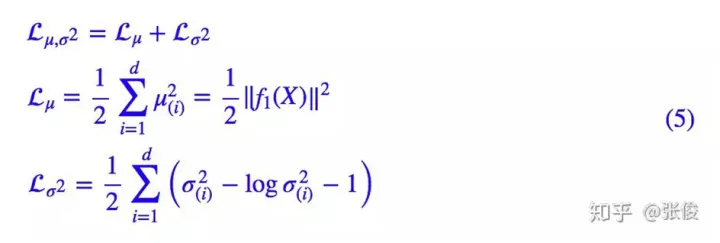
VED[5]
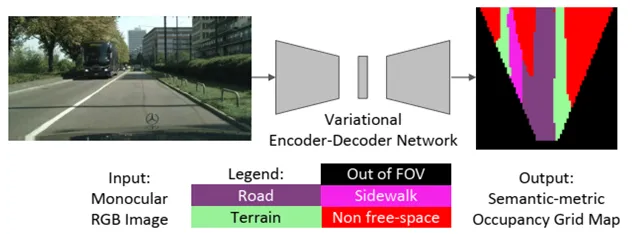
VED是利用VAE的架构进行语义占用网格图预测。它对驾驶场景的前视视觉信息进行编码,并解码为 BEV 语义占用网格(occupancy grid)。原理图如下:
其网络结构如下:
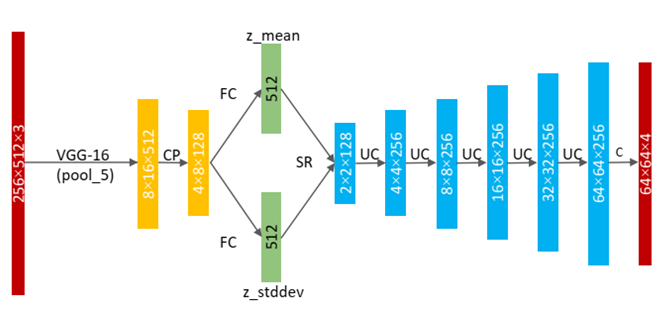
明白VAE是怎么回事,就很容易看明白了。
这个groundtruth是使用CityScape数据集中立体匹配的视差图生成的。这个过程是有噪音的,使用 VED 和从潜在空间进行采样,以使模型对不完美的 GT 具有鲁棒性。然而,由于是 VAE,它通常不会产生锐利的边缘,这可能是由于高斯先验和均方误差造成的。
Lift-splat深度信息
Learning to Look around Objects[6]
本文中透视空间到BEV空间的方法:
利用深度信息,恢复到3D坐标系中,然后以BEV视角,做正交投影,即z值直接丢掉,x和y值直接取整,相同的像素点的特征求平均值。其通道维度为 分类信息。
本文在鸟瞰图中估计遮挡情况下的语义场景layout。这个具有挑战性的问题不仅需要对3D几何形状和可见场景语义有准确的了解,而且对遮挡区域进行准确的理解。本文提出一个卷积神经网络,通过周围前景目标(例如汽车或行人)学习预测场景layout中的遮挡部分。其实,与其用RGB颜色信息、不如说直接预测被遮挡区域的语义和深度,可以更好地转换为鸟瞰图。作者通过从模拟或可以有的地图数据中学习有关典型道路layout的先验知识和规则,可以大大增强初始鸟瞰图表示。其直观表示如图所示:
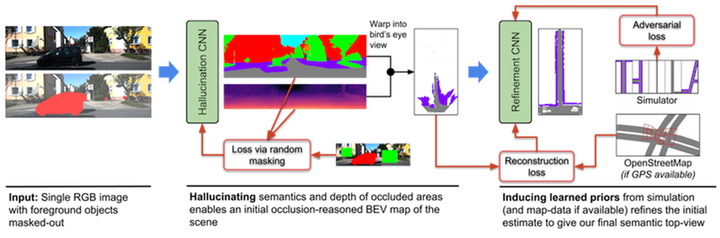
我们的目的是将一个透视RGB图,映射成BEV遮挡语义形式。
1) 输入为RGB(hw3)和前景分割mask图( hwc ),C为类别数量,提供遮挡背景的前景目标位置,用于去除前景,使得网络(Hallucination CNN)能够自己推断被遮挡的背景的深度。
2) 利用无前景的分割和深度图,恢复背景的BEV图。论文中的occlusion-reasoned depth map指的是无前景的深度图。
3) 我们需要训练一个这样能够自动恢复被遮挡的背景的网络。在输入的数据中去除前景,训练中,又扣除其它的背景区域,因为这些区域本来是有深度值的,这样就可以使网络自己去补充被遮挡的部分。
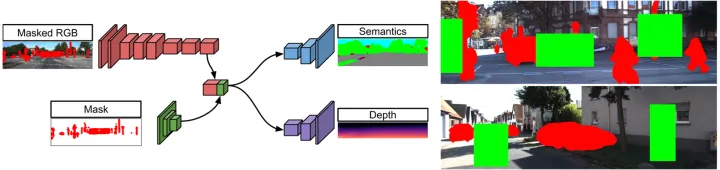
由于深度值是有误差的,导致生成的BEV图存在一些问题,本文设计了refine网络进行恢复。使用对抗性损失来指导模拟和OpenStreetMap数据的学习,以确保生成的道路布局看起来像真实的道路布局。
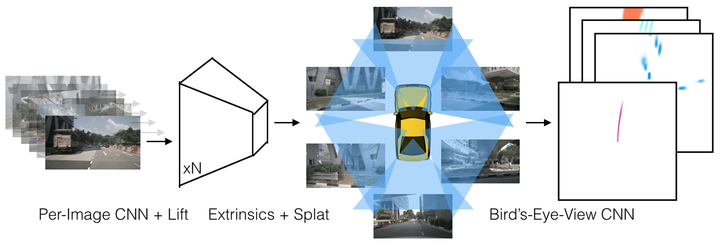
Lift, Splat, Shoot[7]
这是一个端到端架构,直接从任意数量的摄像头数据提取给定图像场景的鸟瞰图表示。将每个图像分别“提升(lift)”到每个摄像头的视锥(frustum),然后将所有视锥“投放(splat)”到光栅化的鸟瞰图网格中。这里要学习的是,如何表示图像以及如何将所有摄像机的预测融合到场景的单个拼接表示,同时又能抵抗标定误差。为学习运动规划的密集表示,这里模型推断的表示,“捕捉(shoot)”模板轨迹到网络输出的鸟瞰损失图,从而实现可解释的端到端运动规划。
本文采用像素级深度分布,将图像特征映射到BEV上。输入图像HW3 ,D代表离散深度维度,对于每个像素都有 (h,w,d) ,这样我们模型预测结果 HWD 。同时对每个像素都会提取出长度为c的向量,和一个深度分布 的向量( 为归一化的),c维度的特征,在D维度上进行重复,并乘上对应的 值,得到下图。
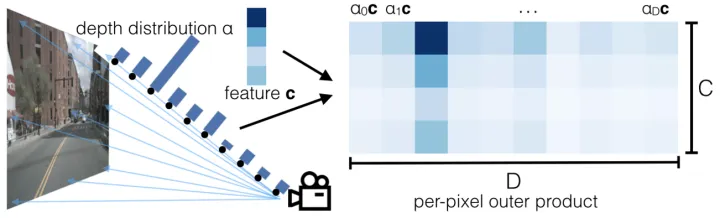
每个像素+深度值,得到一个 (x,y,z) 点,再像pointpillar一样处理,每个点落在最近的pillar上,在高程上求sum pooling。整个过程,可以通过像OFT中的积分表来进行加速。不同相机之间,通过外参+depth来对齐。
lift是提升,即像pointpillar中特征通过pointnet来提升维度;splat为投放,即将特征放在BEV上。
OFT[16]
该篇整体性能不算很强,在KITTI上的结果也排的很后。但是其中有一些思想(3D如何使用2D图像特征)是值得一定程度借鉴的。我们重点来讲作者如何利用2D的图像特征来构建3D的鸟瞰图特征的。
核心一点就是将卷积网络对图像卷积得到的feature,经过3D到2D的project+各种average pooling取到3D鸟瞰图上,从而构成3D鸟瞰图的feature map。这样一来,我们就可以在该feature map上自由地回归各种具有3D属性的对象了。具体如下:
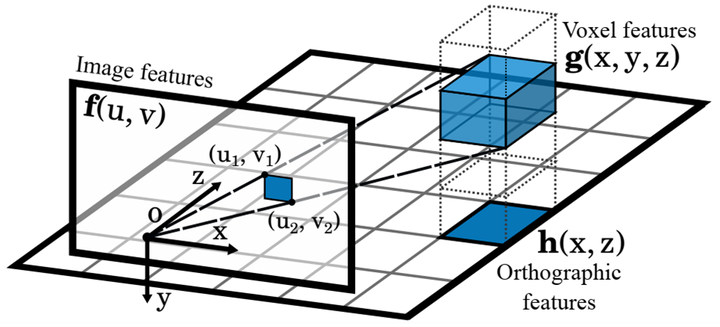
将3D voxel投影到图像上,会计算出一个矩形框,然后将该矩形框内对应的特征向量求平均。然后同一个高度的voxel通过加权平均得到BEV的特征
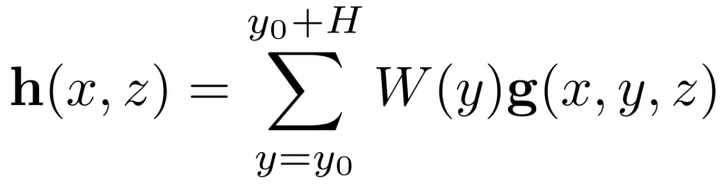
整体的结构如下:
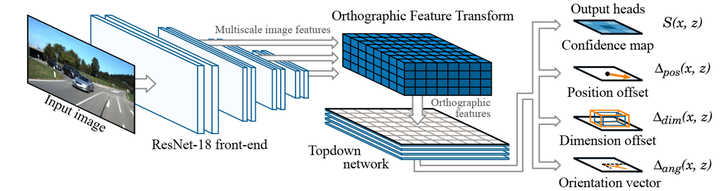
M2BEV[18]
这个是我第一次见到PDF有动图的文件。该论文重要贡献有四点:
1)有效的BEV编码设计,减小voxel特征的空间维度
2)使用learning-to-match,来分配带anchor的gt
3)对距离越远的预测,权重越大
4)大规则使用预训练和辅助监督
整体上,能够用更大的分辨率的输入,更快的推理速度,内存使用效率高。原理图如下:
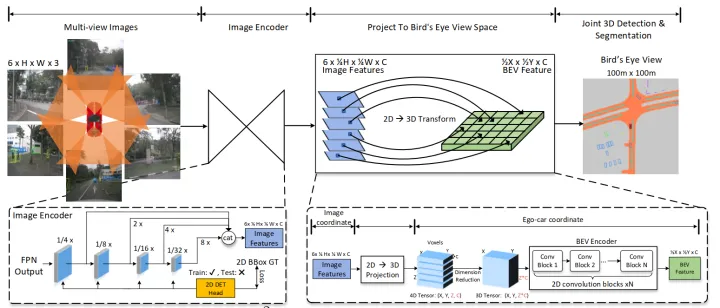
先主要看看2D到3D的转换
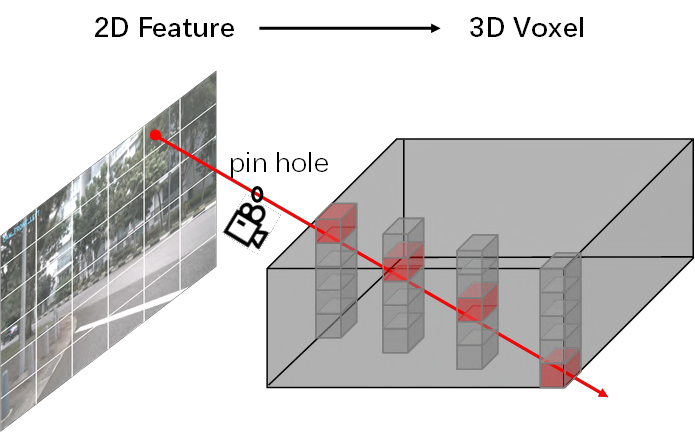
这个做法,其实就是OFT的思路。相对LLS(即Lift,Splat,Shoot)的思路,这里的深度上是均匀分布的,这样就避免了深度的学习。将像素特征点,同权重的映射到每个3D voxel上,避免了depth的问题。正常情况下,生成的是4D tensor,作者这里把4D tensor reshape成3D Tensor,相当于在高度上,直接进行特征堆叠。假如像素特征维度为C,空间高度分辨率为0.5m,那么0-C维度放的是0-0.5m的高度voxel特征,C-2C维度放的是0.5-1m的高度voxel特征,。。。,形象化如下:
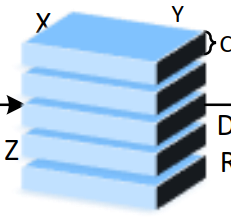
这样,2D卷积比3D卷积效率要高的多。对于3D detection head,直接使用pointpillar的检测头。这种堆叠的思想,在lidar点云检测,越来越普遍了,例如FishingNet[3],RAD[19]。在量产的激光点云上,如果追求速度的话,可以采用这种表达方式,只要有足够的数据,效果都不会差太多。
作者和LLS比较,LLS的内存使用要比这里高3倍,而且能够使用1600X900的分辨率,而LLS只有128X384.
对于BEV centerness,这里可不是fcos里的,而且直接作为loss的权重用的,距离越远,权重越大。
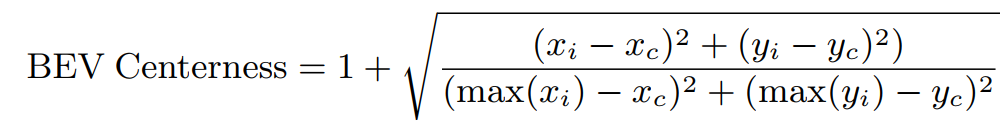
它的值的范围为[1,2],为什么不是[0,1],这种做法很常见,目的都是有一个基线为1,使用权重差异不至退化到过大的程度。
参考文献
[1] Philion J, Fidler S. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d[C]//European Conference on Computer Vision. Springer, Cham, 2020: 194-210.
[2] Pan B, Sun J, Leung H Y T, et al. Cross-view semantic segmentation for sensing surroundings[J]. IEEE Robotics and Automation Letters, 2020, 5(3): 4867-4873.
[3] Hendy N, Sloan C, Tian F, et al. Fishing net: Future inference of semantic heatmaps in grids[J]. arXiv preprint arXiv:2006.09917, 2020.
[4] https://zhuanlan.zhihu.com/p/34998569
https://zhuanlan.zhihu.com/p/27549418
[5] Lu C, van de Molengraft M J G, Dubbelman G. Monocular semantic occupancy grid mapping with convolutional variational encoder–decoder networks[J]. IEEE Robotics and Automation Letters, 2019, 4(2): 445-452.
[6] Schulter S, Zhai M, Jacobs N, et al. Learning to look around objects for top-view representations of outdoor scenes[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 787-802.
[7] Philion J, Fidler S. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d[C]//European Conference on Computer Vision. Springer, Cham, 2020: 194-210.
[8] Reiher L, Lampe B, Eckstein L. A sim2real deep learning approach for the transformation of images from multiple vehicle-mounted cameras to a semantically segmented image in bird’s eye view[C]//2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2020: 1-7.
[9] Carion N, Massa F, Synnaeve G, et al. End-to-end object detection with transformers[C]//European conference on computer vision. Springer, Cham, 2020: 213-229.
[10] Yang W, Li Q, Liu W, et al. Projecting Your View Attentively: Monocular Road Scene Layout Estimation via Cross-view Transformation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 15536-15545.
[11] Chitta K, Prakash A, Geiger A. NEAT: Neural Attention Fields for End-to-End Autonomous Driving[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 15793-15803.
[12] Can Y B, Liniger A, Paudel D P, et al. Structured Bird's-Eye-View Traffic Scene Understanding from Onboard Images[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 15661-15670.
[13] Wang Y, Guizilini V C, Zhang T, et al. Detr3d: 3d object detection from multi-view images via 3d-to-2d queries[C]//Conference on Robot Learning. PMLR, 2022: 180-191.
https://zhuanlan.zhihu.com/p/499795161
[14] Zhu X, Su W, Lu L, et al. Deformable detr: Deformable transformers for end-to-end object detection[J]. arXiv preprint arXiv:2010.04159, 2020.
[15] Li Z, Wang W, Li H, et al. BEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers[J]. arXiv preprint arXiv:2203.17270, 2022.
https://www.zhihu.com/question/521842610/answer/2431585901
[16] Roddick T, Kendall A, Cipolla R. Orthographic feature transform for monocular 3d object detection[J]. arXiv preprint arXiv:1811.08188, 2018.
[17] https://towardsdatascience.com/monocular-bev-perception-with-transformers-in-autonomous-driving-c41e4a893944
[18] Xie E, Yu Z, Zhou D, et al. M^ 2BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Birds-Eye View Representation[J]. arXiv preprint arXiv:2204.05088, 2022.
[19] Aghdam H H, Heravi E J, Demilew S S, et al. RAD: Realtime and Accurate 3D Object Detection on Embedded Systems[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 2875-2883.
(一)视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、传感器标定、传感器部署、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知、决策规划、轨迹预测等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
视频官网:www.zdjszx.com
(二)国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

(三)【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称