文章总括图
数据存储
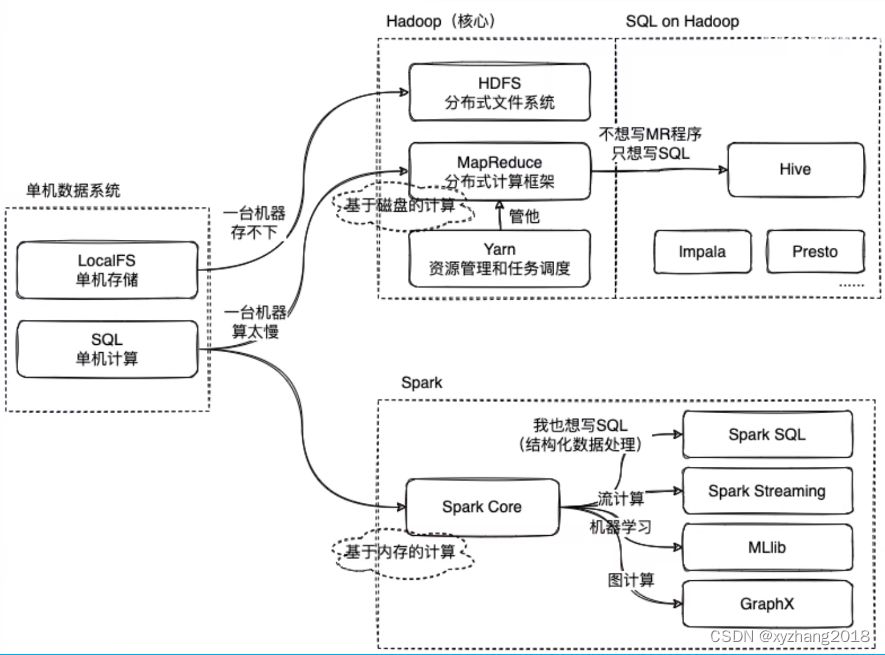
单机数据库时代
所有数据在单机都能存的下,数据处理的任务都是IO密集型,更谈不上分布式系统
一个典型的2U服务器可以插6块硬盘,每块硬盘4T,共24T原始容量,再加上一些数据包的可用冗余,再加上一些格式化的损失,保守估计一台服务器至少可以有10T以上的可用容量,再加上128G内存和两颗CPU,装入DBMS,稍微调优,单表处理10e条数据问题不大
多机数据库时代
当数据量变多时,单台机器无法满足容量需求,一个很常规的想法就是加机器,一台机器存不下就用10台乃至100台。
那么HDFS就诞生了,HDFS会统一管理100台机器上的存储空间,提供一个接口,让100台机器的存储空间看起来就像在一台机器上,让用户感觉到这是一个无限大的存储空间,然后再基于这个去写应用程序。
数据计算
数据分布式的存储于每台机器,每台机器都有自己的CPU和内存,如果能充分利用这些资源可以使数据计算更快完成。
但对于程序员来讲很难去操作100台机器,编写程序将一个计算任务分配到这些机器上,并让这些任务进行同步、机器容错等问题过于复杂,于是MapReduce就出现了。
MapReduce提供了一个任务并行的框架,通过他的API的抽象,让用户将并行程序分为两个阶段分别是:
- map阶段:将完整任务分成多份交给分布式设备分别完成
- reduce阶段:将分布式计算完成的任务结果进行聚合,输出最终结果
Spark与Mapreduce类似都是计算引擎,主要区别是Spark基于内存计算,MapReduce基于磁盘,因此Spark速度更快,在数据集不大、机器内存能完全装下的极端情况,Spark比MR快100倍,但正常情况下大约比MR快2-3倍。
Spark核心模块与Mapreduce使用上类似,都会提供一系列API,让开发者写数据处理程序,同时,Spark生态中也有SparkSQL实现MR的Hive的功能。此外,Spark中也有其他类型的抽象,如Spark Streaming实现流处理程序、MLlib实现机器学习相关程序、GraphX实现图处理程序。
数据查询
单机数据库时代用户使用SQL语句即可实现数据查询,而分布式数据库如果需要查询数据需要用户自己写程序,而且还是比较专业的分布式处理程序。其核心诉求是再Hadoop上写SQL,于是Hive出现了(Impala、Presto等也可实现SQL on Hadoop)
Hive是在Hadoop上进行结构化数据处理的解决方案,为了能让用户写SQL处理程序,那么程序就需要对数据进行结构化处理,Hive中的一个核心模块Metastore,就是用来存储这些结构化信息,比如一些“表”的信息,列的数量,表中每个列是什么样的数据结构。
Hive执行过程:
- 解析阶段(该阶段与单机数据库无异):Hive的执行引擎会把一条SQL语句进行语法分析,生成语法分析树;
- 执行阶段:Hive的执行引擎会把SQL语句翻译成Mapreduce程序进行执行,将结果进行加工返回给用户;
但是复杂性与灵活性是一对矛盾体,在实际应用是还需要根据场景来选择使用Hive还是直接写MR程序
参考资料:
强烈推荐B站视频,讲得非常通俗易懂:【大数据技术生态中,Hadoop、Hive、Spark是什么关系?| 通俗易懂科普向】 https://www.bilibili.com/video/BV1LU4y1e7Ve/?share_source=copy_web&vd_source=f193a6361a31cec8fe86dfc200c75753