论文信息
number headings: auto, first-level 2, max 4, _.1.1
name_en: Speak, Read and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision
name_ch: 说话、阅读和提示:少量监督实现高保真文本转语音
paper_addr: http://arxiv.org/abs/2302.03540
date_read: 2023-04-25
date_publish: 2023-02-07
tags: [‘深度学习’,‘TTS’]
author: Eugene Kharitonov, Google research
code: https://google-research.github.io/seanet/speartts/examples/
1 读后感
这是一个完整的TTS系统,可视为AudioLM的延展。
2 摘要
多语言的语音合成系统,使用大量无监督数据,少量有监督数据训练,结合了两种类型的离散语音表示,解耦了:从文本生成语义标记(读),由语义标记再生成声音标记(说)两部分,用大量纯音频数据训练“说模块”,减少“读模块”对并行数据(并行数据指:文本语音数据对)的需求。
为控制说话人,使用提示方法,只需要3秒音频即可合成在训练集中未见过的说话人的语音。
实验表明,SPEAR-TTS 仅使用 15 分钟的并行数据即可与最先进的方法的字符错误率相比较,主观测试证明其可在自然度和声学质量方面与真实语音相媲美。
3 离散的语音表示
详见AudioLM
3.1 语义token
语义标记的作用是提供一个粗略的、高层级的条件来生成随后的声学标记。因此,应该提供一种表示,其中语言内容(从语音到语义)是显著的,同时不考虑说话人身份和声学细节等副语言信息。
为了获得这样的表示,训练了一个基于 w2v-BERT 的自监督语音表示模型。该模型结合了Mask语言建模和对比学习以获得语音表示。训练结束后,对特定层的均值方差归一化输出运行 k 均值聚类。使用质心索引作为离散标记。
3.2 声学token
声学标记是离散的音频表示,可提供声学细节的高保真重建。训练了一个 SoundStream 神经编解码器来重建语音,同时将其压缩成一些离散单元。 SoundStream 通过在卷积自编码器的瓶颈中添加一个残差量化器来实现这一目标。
4 SPEAR-TTS 概述
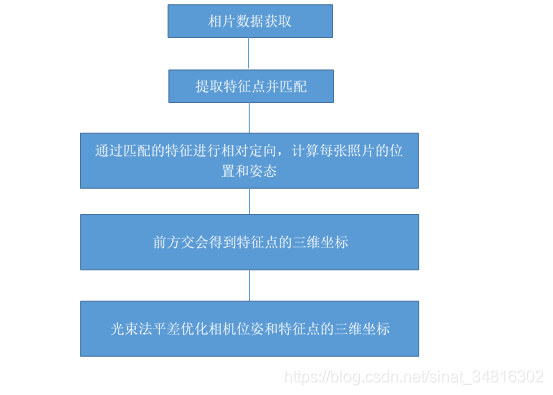
SPEAR-TTS 通过将文本作为生成条件来扩展 AudioLM。如图-1所示,主要分为两个场景:S1文本转成离散的语义标记,S2将语义转声学标记,再利用SoundStream转成音频。
其中需要两步转换,原因是:语义信息在逻辑上介于文本和声学信息之间;且语义转声学只需要无标注的音频数据训练。另外,还可以再加入与 AudioLM类似的第三种场景,通过预测与精细残差矢量量化级别对应的声学标记,来提高合成语音的质量。
5 S1:提升监督效率
通过有监督学习从文本到语义标记的映射,使用语音合成数据集提取语义标记,将S1变为序列到序列seq2seq的任务,具体使用Transformer结构。

有监督学习需要大量标注数据,对于小语种比较困难,文中使用了两种改进策略:
5.1 预训练
在一个去噪预训练任务上对Encoder-Decoder的Transformer进行预训练。给模型提供了一个原始语义token序列的损坏版本,目标是产生相应的未损坏token序列。
典型的损坏方法包括随机替换、删除和遮蔽单个token或整个token范围。在初步研究中观察到独立地以恒定概率删除单个token的方法比其他替代方案更有效。
在对模型进行去噪任务的预训练之后,对S1任务进行微调。微调时冻结编码器的上层和解码器的参数。
5.2 回译:Backtranslation
相同的文本序列可以对应多种音频,比如不同的声音、口音、韵律、情感内容和录音条件。这使得文本和音频高度不对称。回译方法是:使用可用的并行数据对来训练语音到文本模型,并使用它和来自纯音频的语料来生成并行数据,增加模型的训练数据。

从左下开始看图-2,首先,利用有限数据的损坏方法(加噪再去噪)来预训练模型P,生成语义token表征音频数据;然后训练回译模块,利用少量的并行数据微调解码器,训练模型B;利用模型B的回译方法以及大量无标签数据生成大量可用于训练的并行数据(右上);最后用所有并行数据精调模型(右下)只精调编码器的下面几层。
6 S2:控制生成过程
第二个场景是将语义标记映射到声学标记,此处,可从只有音频的数据集的句子中提取语义声学标记,然后训练Transformer模型实现seq2seq的翻译功能。第二阶段生成语音、节奏和录音条件随机变化的话语,再现训练数据中观察到的特征分布。
由于 S1 和 S2 的训练是解耦的,因此当 S1 在单说话人数据集上训练时,S2 可保留生成语音的多样性。
为了控制说话者声音的特征,在训练的时候就考虑了有音频提示和无音频提示两种情况。如图-3所示:
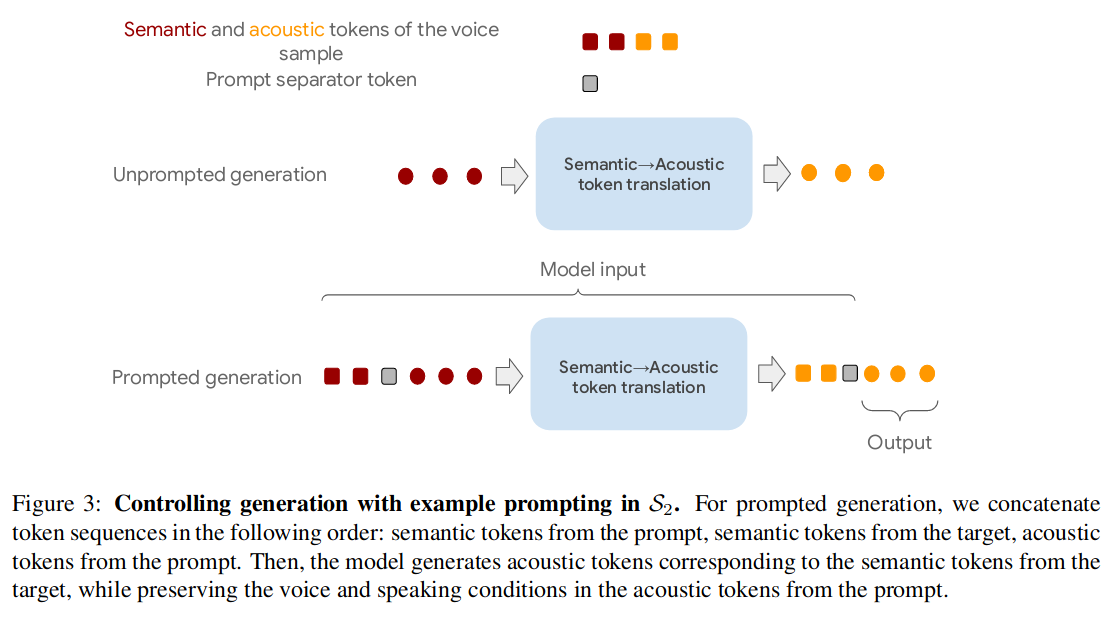
这里的红色块是语义token,黄色块是声学token,灰色为提示分隔符。在按音频提示生成语音的场景中(下图),用以下训练连接序列:来自提示的语义token,来自目标的语义token,来自提示的声学token。该模型生成与来自目标的语义标记相对应的声学token(Output),同时保留来自提示的声学标记中的语音和说话条件。
在训练时,从每个训练集中随机选择两个不重叠的语音窗口,从中计算语义和声学标记的序列。将其中一个窗口视为提示,将另一个视为目标输出。
在推理时,输入也是前三块,使用自回归方式生成Output。