1、爬虫项目单独使用scrpay框架的不足
当前网站普遍采用了javascript 动态页面,特别是vue与react的普及,使用scrapy框架定位动态网页元素十分困难,而selenium是最流行的浏览器自动化工具,可以模拟浏览器来操作网页,解析元素,执行动作,可以处理动态网页,使用selenium处理1个大型网站,速度很慢,而且非常耗资源,是否可以将selenium集成到scrapy框架中,发挥二者的优点呢?
Scrapy集成selenium的关键是,将其放入DownloaderMiddleware. 如下面的scrapy原理图,可以在Downloader的中间件方法中,修改request与response对象,再返回给scrapy
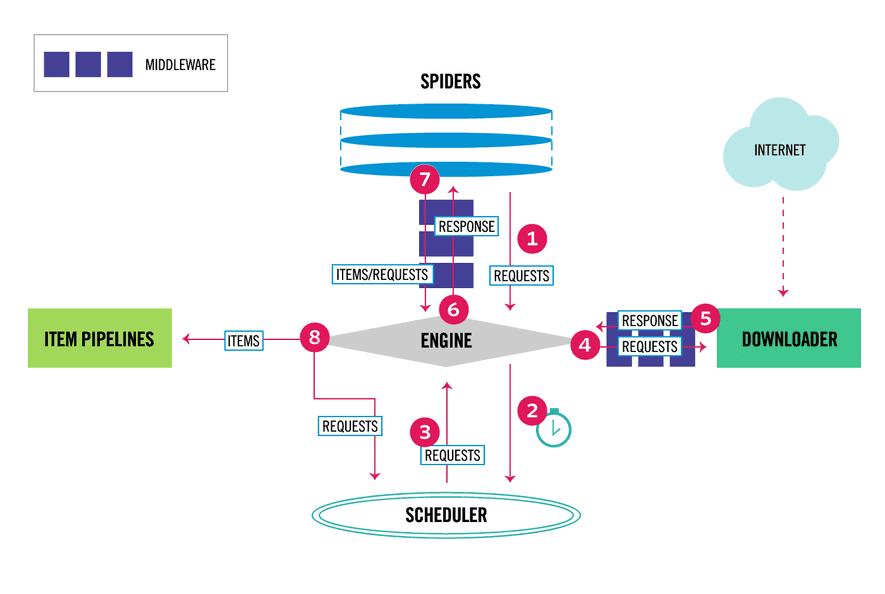
可以自定义downloader middleware 中间件类来集成selenium,当然实现selenium的所有特性,工作量比较大。因此,我们推荐使用scrapy-selenium第3方为来集成。
2. 搭建 scrapy-selenium 开发环境
2.1 安装scrapy-selenium库
pip install scrapy-selenium
python 版本应大于3.6,
2.2 安装浏览器驱动
本机上应该安装有1个selenium支持的浏览器,如chrom, firefox, edge等
再安装对应浏览器、版本的webdrive
下载 downloaded chromedriver.exe 之后,放在项目根目录下,或者加入系统环境变量。
2.3 集成selenium到scrapy 项目
项目结构如下
├── scrapy.cfg
├── chromedriver.exe ## <-- Here
└── myproject├── __init__.py├── items.py├── middlewares.py├── pipelines.py├── settings.py└── spiders└── __init__.py进入项目文件夹,更新settings.py
## settings.py# for Chrome driver
from shutil import whichSELENIUM_DRIVER_NAME = 'chrome'
SELENIUM_DRIVER_EXECUTABLE_PATH = which('chromedriver')
SELENIUM_DRIVER_ARGUMENTS=['--headless'] DOWNLOADER_MIDDLEWARES = {'scrapy_selenium.SeleniumMiddleware': 800}3. 在spider中使用selenium来解析网页
在spider中,用SeleniumRequest 类来代替selenium内置的Request类。
## spider.py
import scrapy
from quotes_js_scraper.items import QuoteItem
from scrapy_selenium import SeleniumRequestclass QuotesSpider(scrapy.Spider):name = 'quotes'def start_requests(self):url = 'https://quotes.toscrape.com/js/'yield SeleniumRequest(url=url, callback=self.parse)def parse(self, response):quote_item = QuoteItem()for quote in response.css('div.quote'):quote_item['text'] = quote.css('span.text::text').get()quote_item['author'] = quote.css('small.author::text').get()quote_item['tags'] = quote.css('div.tags a.tag::text').getall()yield quote_item
scrapy 会自动调用selenium来解析response回传的页面元素,这里selenium 使用的是headless chrom浏览器。
4. 使用selenium 的特性来爬取数据
可以使用selenium的特性,如
• 网页元素等待
• 模拟点击等操作
• 屏幕截图
等。
(1)Waits 功能
动态网页定位不到元素,通常是由于组件加载顺序,ajax 异步请求更新等造成的,而selenium提供了 wait_until的功能来处理实现对动态网页元素的定位。
所有request 等待10秒
def start_requests(self):url = 'https://quotes.toscrape.com/js/'yield SeleniumRequest(url=url, callback=self.parse, wait_time=10)
使用selenium wait_until条件等待功能
## spider.py
import scrapy
from quotes_js_scraper.items import QuoteItemfrom scrapy_selenium import SeleniumRequest
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as ECclass QuotesSpider(scrapy.Spider):name = 'quotes'def start_requests(self):url = 'https://quotes.toscrape.com/js/'yield SeleniumRequest(url=url, callback=self.parse, wait_time=10,wait_until=EC.element_to_be_clickable((By.CLASS_NAME, 'quote')))def parse(self, response):quote_item = QuoteItem()for quote in response.selector.css('div.quote'):quote_item['text'] = quote.css('span.text::text').get()quote_item['author'] = quote.css('small.author::text').get()quote_item['tags'] = quote.css('div.tags a.tag::text').getall()yield quote_item
(2) 点击按钮
比如,可以配置selenium执行 a 标签的点击事件
lass QuotesSpider(scrapy.Spider):name = 'quotes'def start_requests(self):url = 'https://quotes.toscrape.com/js/'yield SeleniumRequest(url=url,callback=self.parse,script="document.querySelector('.pager .next>a').click()",)
(3)页面截图
## spider.py
import scrapy
from quotes_js_scraper.items import QuoteItem
from scrapy_selenium import SeleniumRequestclass QuotesSpider(scrapy.Spider):name = 'quotes'def start_requests(self):url = 'https://quotes.toscrape.com/js/'yield SeleniumRequest(url=url, callback=self.parse, screenshot=True)def parse(self, response):with open('image.png', 'wb') as image_file:image_file.write(response.meta['screenshot'])