换脸软件DFL2.0官方使用手册详解
- 前景提要
- 2.0主要新增功能
- 硬件要求
- 文件目录
- 术语解释
- 具体过程
- 1,工作区清理
- 2,从src视频中提取画面 (data_src.mp4)
- 3,视频切割 (可选环节)
- 4,从目标视频中提取画面(data_dst.mp4)
- 5,提取Data_src中的人脸
- 6,Data_src 整理
- 7,Data_dst 数据准备
- 7.1 手动人脸提取的操作说明
- 7.2 Data_dst 数据整理
- 7.3 XSeg model 的训练和使用(画遮罩)
- 8,训练
- 8.1 参数配置与说明
- 8.2 Merging合成
- 8.3 把转化好的帧合成为视频
- 9,附录:
- 10,常见问题和回答(来自于网络)
- 11,笔记(持续更新)
前景提要
2.0主要新增功能
-
2个模型大类: SAEHD 和 Quick 96
-
支持多GPU
-
比DFL 1.0 更快的提脸、训练、合成速度
-
提供人脸素材加强脚本
-
训练支持GAN(一种AI技术),以还原更多细节
-
新增TrueFace参数 - (只支持 DF 模型架构) - 让SRC和DST表情更相似,减少死鱼脸
-
合成阶段附带输出遮罩图片, 方便后期导入其他软件编辑
-
带交互界面的合成脚本(1.0的合成需要手动填参数,非常反人类,这个2.0做的很人性化)
-
提脸使用s3fd算法,并支持手动模式
-
模型分辨率可选择为任意16或32倍数
-
多种模型架构 (两种核心框架DF, LIAE,以及 -U, -D ,-UD 三种附加后缀,这个下文详细展开)
-
使用Xseg遮罩模型,提供自带画遮罩的工具
硬件要求
dfl2.0最新版已经支持英伟达显卡和AMD显卡,但AMD显卡效率不行,买电脑还是推荐英伟达显卡,英伟达GPU 10gb显存以上,CPU i7以上。win10系统,安装英伟达最新驱动程序,cuda11开发工具。
文件目录
-
DeepFaceLab 2.0由几个.bat文件组成,这些文件用于执行创建deepfake的各种任务/步骤,它们与两个子文件夹一起位于主文件夹中:
-
_internal - 相关源代码
-
workspace - 放置你的模型、视频、人脸数据的地方
术语解释
Dataset (faceset) - 是一组从图片帧(从视频中提取)或照片已提取的图像。
DFL 2.0中使用了两个数据集,分别是data_dst和data_src:
- src顾名思义是就是源source, dst就是目标destination。假设我想要把张三的脸放到李四的头上,换一种表述就是我想给李四换张脸。
- “data_dst” “ data_dst”是一个文件夹,其中包含从data_dst.mp4文件提取的帧-这是我们要换脸的目标视频。 它还包含2个文件夹,这些文件夹是在从提取的帧中提取人脸后创建的:“aligned”包含人脸图像(内嵌了人脸特征点数据,用于生成原始遮罩)
“aligned_debug”包含原始帧,这些帧画出了人脸特征点,用于标识检验人脸提取是否正确(并且不参与训练或合成过程)。清理完数据集后,可以将其删除以节省空间。 - “data_src” 是一个文件夹,用于保存从data_src.mp4文件提取的帧(可以是采访,电影,预告片等),也可以在其中放散装图片-就是您要在换到视频上的人。
- “aligned”包含人脸图像(内嵌了人脸特征点数据,用于生成原始遮罩)
- “aligned_debug”包含原始帧,这些帧画出了人脸特征点,用于标识检验人脸提取是否正确(并且不参与训练或合成过程)。清理完数据集后,可以将其删除以节省空间。
举个例子:我要做一个马保国替换你自己的人脸的换脸视频。 那么马保国视频就是data_src,你自己视频data_dst,但是在提取脸部之前,必须先从以下对象中提取脸部: - 对于data_dst,您应该准备目标(目标)视频并将其命名为data_dst.mp4
- 对于data_src,您应该准备源视频(如上例所示)并将其命名为data_src.mp4,或者准备jpg或png格式的图像。从视频中提取帧的过程也称为提取,因此在本指南的其余部分中,我将这两个过程都称为“面部提取”和“帧提取”。
- 如开头所述,所有这些数据都存储在“ workspace”文件夹中。
- data_dst.mp4和data_src.mp4放在workspace文件夹目录;
- data_src文件夹和data_dst文件夹用于放置分解视频得到的原始画面帧或散装图片。运行面部提取后,会在其中自动生成存储人脸的“ aligned”文件夹
具体过程
1,工作区清理
Clear Workspace -删除workspace下所有内容。别手贱点他
2,从src视频中提取画面 (data_src.mp4)
Extract images from video data_src - 从data_src.mp4视频中提取帧并将其放入自动创建的“ data_src”文件夹中,可用选项:-FPS-跳过视频的默认帧速率,输入其他帧速率的数值(例如,输入5将仅以每秒5帧的速度呈现视频,这意味着将提取较少的帧)
-JPG / PNG-选择提取帧的格式,jpg较小,通常质量足够好,因此建议使用,png较大,不能提供明显更高的质量,但是可以选择。
3,视频切割 (可选环节)
cut video (drop video on me) - 通过将视频拖放到该.bat文件中,可以快速将视频剪切为所需的长度。 如果您没有视频编辑软件并且想快速剪切视频,则很有用,可以选择以下选项:
- 从时间开始-视频开始
- 结束时间-视频结束
- 音轨-保留默认设置
- 比特率-让我们更改视频的比特率(质量)-最好保留默认设置
4,从目标视频中提取画面(data_dst.mp4)
extract images from video data_dst FULL FPS - 从data_dst.mp4视频文件中提取帧并将其放入自动创建的“ data_dst”文件夹中,可用选项:JPG/PNG - 同2)
5,提取Data_src中的人脸
准备源数据集的第一步是对齐人脸(把人脸都摆正了),并从位于“ data_src”文件夹中的提取帧中生成512x512面部图像。
有2个选项:
- data_src faceset extract MANUAL - 手动提取器
- data_src faceset extract - 使用S3FD算法的自动提取
S3FD和MANUAL提取器的可用选项包括:
- 根据要训练的模型的面部类型选择提取的覆盖区域:
a) full face (简称F脸,额头部分有些许被裁到)
b) whole face (简称WF脸,范围更大,整个额头都取了,兼容WF和F脸模型)
c) head (不常用,给高玩做avatar用,萌新用不到) - 选择用于面部提取/对齐过程的GPU(或cpu)
- 选择是否生成“ aligned_debug”文件夹
6,Data_src 整理
完成此操作后,下一步是清理错误faceset /数据集/不正确对齐的faces,把不清楚的脸部图片删除掉即可。
data_src view aligned result - 不常用
data_src sort - 给图片排序,方便你筛选错误图片
[0] blur 模糊程度
[1] face yaw direction 俯仰角度
[2] face pitch direction 左右角度
[3] face rect size in source image 人脸在原图中的大小
[4] histogram similarity 颜色直方图相似度
[5] histogram dissimilarity 颜色直方图不相似度
[6] brightness 亮度
[7] hue 颜色色相
[8] amount of black pixels 黑色像素的数量(常用于筛选异常人脸提取结果)
[9] original filename 源文件名字
[10] one face in image 是否是画面中唯一人脸
[11] absolute pixel difference 绝对的像素差异
[12] best faces 筛选最佳的人脸
[13] best faces faster 更快的筛选最佳的人脸
data_src util add landmarks debug images -重新生成debug文件夹
data_src util faceset enhance - 用AI算法提升素材清晰度
data_src util faceset metadata restore and data_src util faceset metadata save - 让我们从源面集/数据集中保存和还原嵌入的对齐数据,以便在提取某些面部图像(例如将它们锐化,编辑眼镜,皮肤瑕疵,颜色校正)后可以对其进行编辑,而不会丢失对齐数据。如果不按此步骤编辑“已对齐”文件夹中的任何图像,则将不会再使用对齐数据和这些图片进行训练,因此,在保持名称相同的情况下,不允许翻转/旋转,仅是简单的编辑,例如彩色 。
data_src util faceset pack and data_src util faceset unpack - 将“aligned”文件夹中的所有面孔打包/解压缩到一个文件中。 主要用于准备自定义的预训练数据集或更易于共享为一个文件。
other) data_src util recover original filename - 将面部图像的名称恢复为原始顺序/文件名(排序后)。 可选,无论SRC face文件名如何,训练和合成都能正确运行
7,Data_dst 数据准备
这里的步骤与源数据集几乎相同,除了少数例外,让我们从面部提取/对齐过程开始。
我们仍然有Manual和S3FD提取方法,但是还有一种结合了这两种方法和一种特殊的手动提取模式,始终会生成“
aligned_debug”文件夹。
data_dst faceset extract MANUAL RE-EXTRACT DELETED ALIGNED_DEBUG - 从“ aligned_debug”文件夹中删除的帧进行手动重新提取。
data_dst faceset extract MANUAL - 纯手动模式
data_dst faceset extract manual fix - 半自动,机器识别不了的会切手动
data_dst faceset extract - 纯自动提取
选项和src的一样,不重复说了
7.1 手动人脸提取的操作说明
启动手动提取器或重新提取器后,将打开一个窗口,您可以在其中手动找到要提取/重新提取的脸部:
- 使用鼠标定位脸部
- 使用鼠标滚轮更改搜索区域的大小
- 确保所有或至少是大多数地标(在某些情况下,取决于角度,照明或当前障碍物,可能无法精确对齐所有地标,因此,请尝试找到一个最能覆盖所有可见位并且是“ t太不对准)落在重要的部位,例如眼睛,嘴巴,鼻子,眉毛上,并正确遵循面部形状,向上箭头指示您面部的“向上”或“顶部”在哪里
- 使用键A更改精度模式,现在地标不会对检测到的面部“粘”太多,但您可能能够更正确地定位地标
- 用户<和>键(或,和。)来回移动,以确认检测到鼠标左键单击并移至下一个或按Enter
- 鼠标右键,用于检测无法检测到的正面或非人脸(需要应用xseg进行正确的遮罩)
- q跳过剩余的面孔并退出提取器(到达最后一张面孔并确认时也会关闭)
7.2 Data_dst 数据整理
对齐data_dst面后,我们必须清理它们,类似于我们使用源faceset / dataset进行处理时,我们将选择一些排序方法,由于它们的工作方式与src完全相同,因此我将不作解释。
但是清理目标数据集与源数据集有所不同,因为我们要使所有存在的帧的所有面对齐(包括可以在XSeg编辑器中标记的受遮挡的面),然后训练XSeg模型以将其遮盖 -有效地使障碍物在学到的面孔上清晰可见,更多的是在下面的XSeg阶段。
这块做法和data_src类似,区别在于,最后合成时是根据dst中aligned文件数量来合成。删掉的dst人脸数据对应的画面就不会换脸
7.3 XSeg model 的训练和使用(画遮罩)
这章比较复杂,萌新先不要使用遮罩。不用遮罩正常也能训练的。
8,训练
有两种模式可以选择:
SAEHD (6GB ): 高质量模型,至少6GB显存
特点/设置
- 最高640x640分辨率,
- 可支持half face, mid-half face, full face, whole face and head face 5中人脸尺寸类型
- 8种模型结构: DF, LIAE, 每种4 个变种 - regular, -U, -D and -UD
- 可调节的批大小(batchsize)
- 可调节的模型各层维度大小
- Auto Backup feature 自动备份
- Preview History预览图存档
- Adjustable Target Iteration 目标迭代次数
- Random Flip (yaw) 随机水平翻转
- Uniform Yaw 按角度顺序来训练
- Eye Priority 眼神训练优先
- Masked Training 带遮罩训练
- GPU Optimizer 优化器放GPU上
- Learning Dropout 学习率自动下降
- Random Warp 随机扭曲
- GAN Training Power 使用GAN
- True Face Training Power 提高人脸相似度
- Face and Background Style Power 提高颜色相似度
- Color Transfer modes 变对素材变色
- Gradient Clipping 梯度裁剪
- Pretrain Mode 使用预训练模式
Quick96 (2-4GB): 低配电脑可用
特点:
- 96x96 分辨率
- 只支持Full Face
- Batch size 4
- 默认DF-UD结构
由于Quick96不可调节,因此您将看到命令窗口弹出并仅询问一个问题-CPU或GPU(如果您有更多问题,它将选择其中之一或同时进行训练)。
但是,SAEHD将为您提供更多调整选项。
在这两种情况下,首先都会出现一个命令行窗口,您可以在其中输入模型设置。 初次使用时,您将可以访问以下说明的所有设置,在使用已经受过训练的模型进行训练并在“模型”文件夹中显示该模型时,您还将收到提示,您可以在其中选择要训练的模型( (如果您的“模型”文件夹中存在多个模型文件)。
您还将始终提示您选择要在其上运行培训器的GPU或CPU。
启动后将看到的第二件事是预览窗口,如下所示:

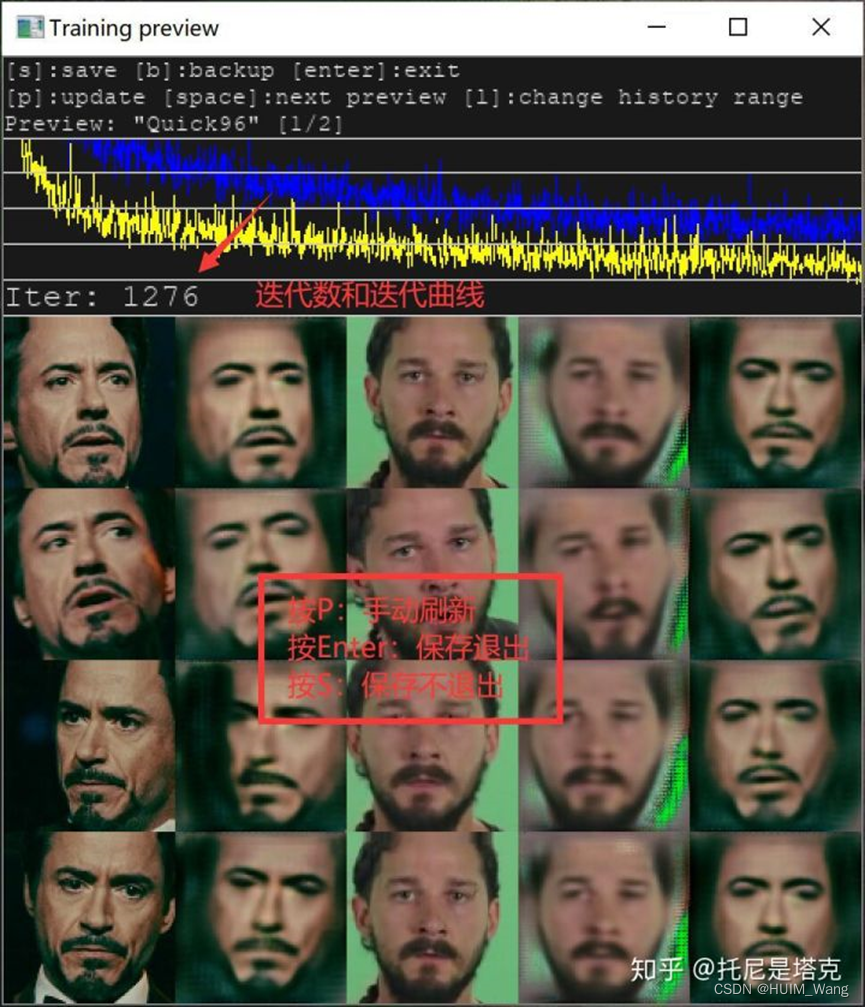
这是所有功能的更详细说明,以便在开始训练新模型时将其呈现给用户。
请注意,由于这些模型的工作方式,其中一些已锁定,一旦开始训练就无法更改,例如,稍后无法更改的示例如下:
- model resolution 模型分辨率
- model architecture 模型结构
- models dimensions (dims settings) 模型维度参数
- face type 人脸类型
8.1 参数配置与说明
模型备份(Autobackup every N hour ( 0..24 ?:help ) )
- 建议设置为1
-
自动备份频率,0不备份。输入2表示两个小时备份一次
Write preview history ( y/n ?:help) 记录保存预览图
- 建议设置n
-
每次迭代会保存⼀张当前训练效果图,⽅便你查看模型进步效果,来判断是否已经训练到顶峰了。图⽚保存在model内⼀个以history结尾的⽂件夹中。⼀般⼈看预览窗⼝的图就OK了。这个功能给做专业对⽐测试的⽤
目标迭代(Target iteration )
- 默认无限制
-
设置一个整数,当迭代次数达到这个值就会自动停止训练,默认为无限制,直到你手动停止为止。
随机反转(Flip faces randomly ( y/n ?:help ))
- 建议设置Y
-
当你人脸素材比较少的时候比较有用,通过这个参数将人脸图片垂直翻转,增加素材量。比如目标视频有右侧连,原视频只有左侧脸的时候。但是翻转后的样本和真是的情况可能会有一些误差。素材比较充分的情况下建议关闭,保证相似度,自然度。
批量大小(Batch_size ( ?:help ) )
- 默认无限制
-
批处理大小设置会影响每次迭代中相互比较的面孔数。 最低值是2,您可以提高到GPU允许的最大值,受GPU影响。 模型分辨率,尺寸越高,启用的功能越多,将需要更多的显存,因此可能需要较小的批处理大小。 建议不要使用低于4的值。批量越大,质量越好,但训练时间越长(迭代时间越长)。 对于初始阶段,可以将其设置为较低的值以加快初始训练的速度,然后将其升高。 最佳值为6-12 。 11gb显存设置为4,24gb显存可以尝试8~16
模型像素 (Resolution ( 64-640 ?:help ))
- 推荐设置256
-
这里你设置了你的模型分辨率,此选项不可重置。分辨率可以从64×64增加到640×640,增量为:16(对于常规和-U架构变体),32(对于-D和-UD架构变体)。原则上来说分辨率越高,模型学习到的脸就越详细,最终清晰度越高,但是对配置的要求也会越来越高,使用的时间越来越多。
人脸区域(Face type ( h/mf/f/wf/head ?:help ) )
- 建议设置mf
-
这个选项可以指定人脸训练区域的大小,主要包括半脸,中脸,全脸,整脸,头。从左到有,区域越来越大。
半脸h:主要包括眉毛到嘴巴的区域,眉毛可能会出现问题
中脸mf:优化了眉毛的处理,面积提升30%,基本解决眉毛的问题。建议)
全脸f:脸部区域大于中脸,贴合人脸边缘,不包含额头。推荐。
整脸wf:全脸的基础上,可以解决额头的问题,需要配合遮罩处理(xseg)
头h:包含整个头部,包括脸和头发,配合遮罩处理实现换头。

模型结构(AE architecture)
- 默认无限制
-
[liae-ud] AE architecture ( ?:help ) :
模型结构主要包含DF和LIAE, 以及一些扩展选项-U,-D,[b]-UD。-U , -D可以和DF LIAE组合使用。演变出如:DF-U,DF-D,DF-UD,LIAE-UD等。
DF:此模型架构提供了更直接的人脸交换,不使人脸变形,所以源与目标自己的人脸匹配很重要。该模型在正面拍摄时效果最好,并且要求您的源数据集具有所有所需的角度,否则在侧面轮廓上可能会产生较差的结果。官方推荐的模式,复用后相似度高,适合复用!
LIAE: 该模型结构可以使面部变形,这种模型与源头镜头的相似性较差,但是可以更好地处理侧面轮廓,并且在数据集方面更宽容,通常可以产生更精致的人脸交换,并具有更好的颜色光线匹配度。
-U: 这个选项是为了提升合成结果与源素材的相似度。
-D:这个版本旨在提高效率。同等配置下,它可以让你以两倍的分辨率训练你的模型,比如之前只能跑128,启用之后可以跑256。如果分辨率相同,单次迭代时间更少,消耗显存更少。但是在质量上可能会有所降低,有待验证。
-UD:结合了两个变量,以实现最大相似度并提高分辨率/性能。 达到最佳效果吗,可能需要更长的训练。
接下来的4个选项用来设置神经网络的维度,修改这些会对学习人脸的表现和质量有很大影响,所以推荐使用默认值。
自编码器维度 AutoEncoder dimensions ( 32-1024 ?:help ) :
- 默认
-
自动编码器尺寸设置,影响模型学习人脸的整体能力。
编码器维度 Encoder dimensions ( 16-256 ?:help ) :
- 默认
-
编码器尺寸设置,影响模型学习面部总体结构的能力。
解码器维度 Decoder dimensions ( 16-256 ?:help ) :
- 默认
-
解码器尺寸设置,影响模型学习细节的能力。
遮罩解码器维度 Decoder mask dimensions ( 16-256 ?:help ) :
- 默认
-
遮罩解码器的尺寸设置,影响已学习遮罩的质量。可能会,也可能不会影响培训的其他方面。
每一种设置的改变都会对性能产生不同的影响,如果没有广泛的测试,无法确定这些设置对性能和质量具体影响。每一项都提供了默认值,一般来说这是在训练速度和质量的最佳平衡。
可以根据自己的应用场景做适当的修改,当然需要大量的测试验证效果。
一般来说值越大会质量越好,但是需要的配置也会急剧上升,而效果的提升会越来越慢,直到微乎其微。
推荐值:
== archi: df ==
== ae_dims: 128 ==
== e_dims: 64 ==
== d_dims: 64 ==
== d_mask_dims: 22 ==
眼部优先(Eyes priority ( y/n ?:help ))
- 建议设置 Y
-
试图通过强制神经网络以更高优先级训练眼睛来解决眼神涣散(鬼眼)的问题。
请记住,他不能解决眼珠子方向不对的问题,只会影响眼睛和周围区域的细节问题。
[n] Uniform yaw distribution of samples ( y/n ?:help ) :
- 无
-
无
侧脸优化(Uniform_yaw ( y/n ?:help ))
- 默认不开启
-
有助于训练轮廓脸部,迫使模型根据其偏航角在所有面孔上均匀地训练,并优先考虑轮廓脸部,可能会导致正面脸部的训练速度变慢,这在预训练期间默认启用,可与随机变形类似地使用(在开始时 (训练过程)或在禁用或禁用RW后启用(当您对面部进行或多或少的训练,并且您希望轮廓脸部看起来更好且更少模糊时)。 当您的源数据集没有很多轮廓照片时很有用。 可以帮助降低损失值。 默认值为n(禁用)。 这个参数有利于提升侧脸效果。默认不用开启,当训练很久侧脸效果不佳的是时候启用。
GPU优先 (Place models and optimizer on GPU ( y/n ?:help ) )
- 建议设置Y
-
默认启用,如果出现OOM,又不想改变其他参数的时候可以尝试关闭这个参数。关闭后,单次迭代时间会变长。也可以通过改变这个参数,提升res/bs/dims等参数的值。
一般来说使用默认,显卡配置不够的时候启用。
[y] Use AdaBelief optimizer? ( y/n ?:help ) :
- 无
-
无
Use learning rate dropout ( y/n/cpu ?:help )
- 建议设置N
-
LRD的目的是通过改变启用时的学习率dropout来帮助训练,从而加速人脸的训练,获取更低的损失,并减少亚像素抖动。必须在启用GAN之前启用LRD。这个选项会影响到VRAM的使用,所以开启后可能会遇到OOM。
默认推荐不启用,loss降不下来的时候可以试试。
随机扭曲 (Enable random warp of samples ( y/n ?:help ))
- 根据情况Y或N
-
利用随机扭曲来泛化模型,它能更好的学习人脸形状、面部特征、面部结构、人脸表情等。但只启用后,可能影响模型对细节的学习。因此只要效果还在快速提升(loss下降,图片变清晰)的情况下建议开启。当训练足够充分后可以关闭这个功能,继续训练几千个迭代,应该能获得更好的细节。
GAN强度 (GAN power ( 0.0 .. 10.0 ?:help ) )
- 默认值为0.0(禁用)
-
GAN代表Generative Adversarial Network(生成对抗网络),在DFL 2.0中,使用这个选项可以获得更详细/更清晰面孔。 此选项可取值范围为0.0到10.0。并且仅在模型训练最够多之后启用(禁用随机扭曲并启用LRD之后)。默认推荐使用0.1,可以尝试更大的值获取更强的效果。一旦启用,就不再关闭了。启用前记得备份模型,有崩溃风险,可能会出现很诡异的效果。
- 启用前/启用后

- 别看这个例子效果提升了,但是也要防范崩溃的风险。
刚开始训练0.0,在一段时间训练后,重新启动训练,将此值设置为0.1,可以得到更好的效果
真脸强度(’True face’ power. ( 0.0000 .. 1.0 ?:help ) )
- 默认值是0.0(禁用)
-
改选项取值范围为0.xx-1.0 , 使用目的是让合成的人更像src。和GAN强度一样,只有在训练充分并关闭了随机扭曲之后在考虑启用。启用之前,建议先备份。典型值是0.01 ,你可以尝试更低的值,比如0.001,切勿求高。这个参数对性能的影响很小,当然也有可能会导致OOM。
人脸和背景强度(Face style power and Background style power)
- 默认值是0.0(禁用)。
-
此设置控制图像的面部或背景部分的样式转移,能提升合成质量(说是这么说,但是大部分情况下会蹦)。启用后对性能有影响,可能需要降低bs或禁止GPU优化器,启用前记得备份,使用的数值不要太大。
颜色转换 Color transfer for src faceset (none/rct/lct/mkl/idt/sot ?:help )
- 默认使用None,如果后期发现合成效果不好,尝试换一种,只能试,没有标准答案
-
这个选项是用来匹配src和dst的颜色,有几个选项可供选择:
– rct (reinhard color transfer): 基于 https://www.cs.tau.ac.il/~turkel/imagepa…ansfer.pdf
– lct (linear color transfer): 使用线性变换将目标图像的颜色分布与源图像的颜色分布匹配。
– mkl (Monge-Kantorovitch linear): 基于 http://www.mee.tcd.ie/~sigmedia/pmwiki/u…tie07b.pdf
– idt (Iterative Distribution Transfer): 基于 http://citeseerx.ist.psu.edu/viewdoc/dow…1&type=pdf
– sot (sliced optimal transfer): 基于 https://dcoeurjo.github.io/OTColorTransfer/
梯度剪裁(Enable gradient clipping ( y/n ?:help ))
- 默认值为n(禁用)
-
梯度裁剪。实现此功能是为了防止在使用DFL 2.0的各种功能时可能发生的所谓的模型崩溃/损坏。 它对性能的影响很小,因此,如果您真的不想使用它,则必须启用自动备份,因为崩溃后的模型无法恢复,必须将其废弃,并且必须从头开始进行培训。 默认值为n(禁用),但是由于对性能的影响非常低,并且如果保持启用状态,可以防止模型崩溃而节省大量时间。 使用Style Powers时最容易发生模型崩溃,因此强烈建议您启用渐变裁剪或备份(也可以手动进行)。 这个功能最初引入是为了防止模型崩溃(后来好像没啥用了,不开也不太蹦)。 它对性能的影响很小,如果不想使用它,就自觉把自动备份打开,有备无患。
预训练(Enable pretraining mode ( y/n ?:help ) )
- 默认值为n(禁用)
-
启用预训练过程,该过程使用随机人脸数据集对模型进行初始训练,将其训练约200k-400k次迭代后,可以在开始使用要训练的实际data_src和data_dst进行训练时使用此类模型,因为您可以节省时间不必每次都从0开始全面训练(模型将“知道”面孔的外观,从而加快初始训练阶段)。可以随时启用pretrain选项,但建议在开始时仅对模型进行一次预训练。您还可以使用自己的自定义面集进行预训练,您要做的就是创建一个(可以是data_src或data_dst),然后使用4.2)data_src(或dst)util faceset pack .bat文件打包成一个文件,然后将其重命名为faceset.bak并替换(备份旧的)“ … \ _ internal \ pretrain_CelebA”文件夹中的文件。默认值为n(禁用)。但是,如果要节省一些时间,可以去论坛找别人训练好的模型。
要使用共享的预训练模型,只需下载它,将所有文件直接放入模型文件夹中,开始训练,在选择要训练的模型(如果在模型文件夹中有更多内容)和用于训练的设备后2秒钟内按任意键 (GPU / CPU)来覆盖模型设置,并确保禁用预训练选项,以便您开始正确的训练;如果您启用了预训练选项,则模型将继续进行预训练。 请注意,该模型会将迭代计数恢复为0,这是预训练模型的正常行为。
8.2 Merging合成
训练完模型后,该将学习的人脸合并到原始帧上以形成最终视频了(转换)。为此,我们有对应的转换脚本:
merge SAEHD
双击后,命令行窗口将出现,并带有多个提示。
第一个将询问您是否要使用带交互界面的转化器,默认值为y(启用),建议开启,边调参数边预览。
Use interactive merger? ( y/n ) :
第二个将询问您要使用哪种模型:
Choose one of saved models, or enter a name to create a new model.
[r] : rename
[d] : delete
[0] : new - latest
第3个会问您要在合并(转换)过程中使用哪个GPU / GPU:
Choose one or several GPU idxs (separated by comma).
[CPU] : CPU
[0] : GeForce GTX 2070 8GB
[0] Which GPU indexes to choose? :
按Enter将使用默认值(0)。
完成之后,您将看到一个带有当前设置的命令行窗口以及一个预览窗口,其中显示了操作交互式转换器/合并程序所需的所有控件。
这是命令行窗口和转换器预览窗口的快速浏览:
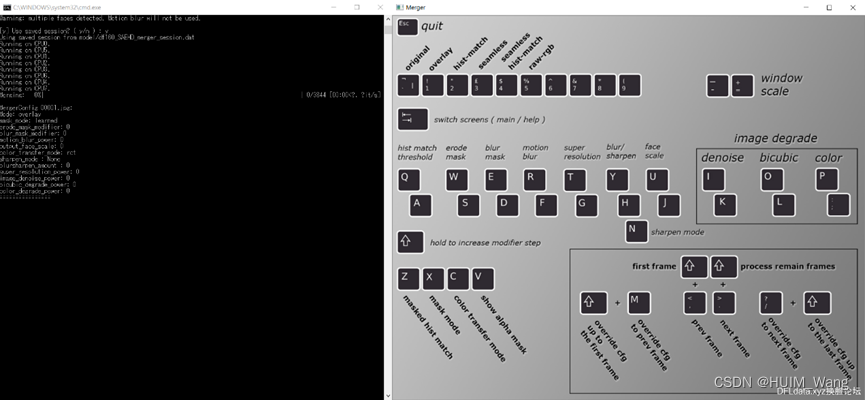
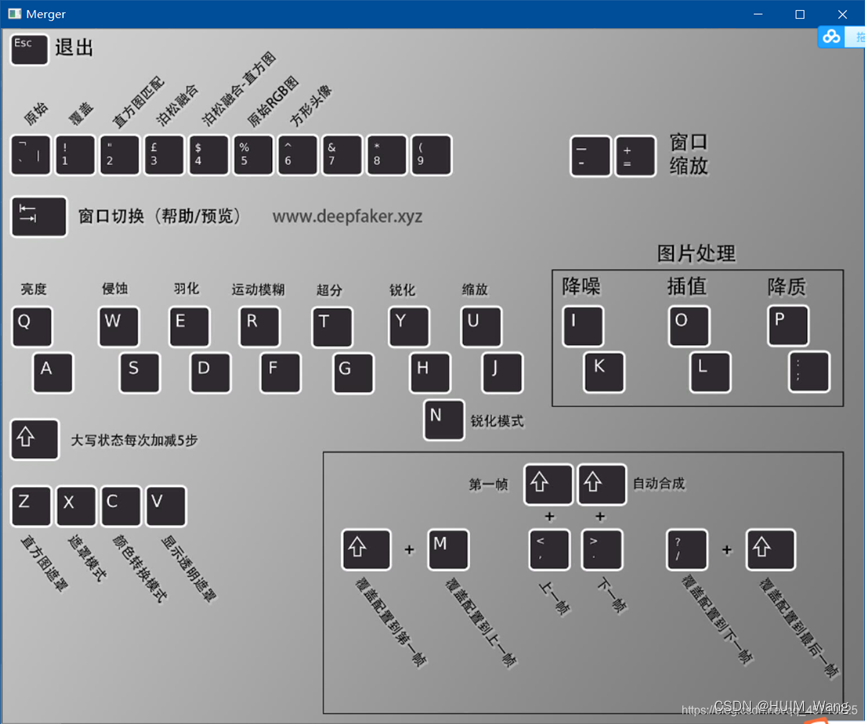
Converter具有许多选项,可用于更改遮罩类型,大小,羽化/模糊,还可以添加其他颜色转移并进一步锐化/增强最终训练的脸部。

首先调整W/S,E/D快捷键:
(W和S键是调节遮罩侵蚀的加减;E和D键是调节遮罩⽻化效果的加减)
Shift+?(向后应用到所有帧),然后再按下shift+>(自动合成)就开始自动合成了。也可以通过键盘上的<和>进行手动切换,查看前后帧的合成效果
这是解释的所有合并/转换器功能的列表:
1. Main overlay modes:
-
original: 显示原始画面而没有换脸
-
推荐下面加粗字体的三种方式: -
overlay: 简单地将学习到的脸覆盖在框架上 (推荐用这个,滚石注)
-
hist-match: 根据直方图叠加学习的面部和试图以使其匹配(具有2种模式:正常模式和可通过Z切换的蒙版)
-
seamless: 使用opencv泊松无缝克隆功能在原始帧的头部上方融合新学习的面部
-
seamless hist match: 结合了直方图匹配和无缝匹配。
-
raw-rgb: 覆盖原始学习过的脸部而没有任何遮罩
注意:无缝模式可能导致闪烁。
2. Hist match threshold:在直方图匹配和无缝直方图覆盖模式下控制直方图匹配的强度。
Q - 增加值
A - 减小值
不建议修改
3. Erode mask: 控制遮罩的大小。 建议修改
W - 增加遮罩腐蚀(较小的遮罩)
S - 减少遮罩腐蚀(较大的遮罩)
4. Blur mask: 使遮罩边缘模糊/羽化,以实现更平滑的过渡。建议修改
E - 增加值
D - 减小值
5. Motion blur: 动态模糊。
- 输入初始参数(转换器模式,模型,GPU / CPU)后,合并将加载所有帧和data_dst对齐的数据,同时,它会计算用于创建此设置控制的运动模糊效果的运动矢量,让您 将其添加到人脸移动的地方,但是即使移动很小,高值也可能使人脸模糊。 该选项仅在“ data_dst / aligned”文件夹中存在一组面孔时才有效-如果在清理过程中某些面孔带有_1前缀(即使只有一个人的面孔),效果将不起作用,同样 如果有一个可以反射目标人员面部的镜子,在这种情况下,您将无法使用运动模糊,并且添加该模糊的唯一方法是分别训练每组面部。
R - 增加motion blur
F - 减少motion blur
6. Super resolution: 超分辨率使用与data_src数据集/面部设置增强器类似的算法,它可以为牙齿,眼睛等区域添加更多定义,并增强所学面部的细节/纹理。 建议修改
T - 增加细节 the enhancement effect
G - 减少细节
7. Blur/sharpen: 使用方块或高斯方法模糊或锐化所学的面部。建议修改下面的Y
Y - sharpens the face
H - blurs the face
N - box/gaussian mode switch
8. Face scale: 缩放人脸。 建议修改
U - scales learned face down
J - scales learned face up
9. Mask modes: 6种遮罩计算方式,效果自己试一遍就知道了建议修改加粗字体
dst: uses masks derived from the shape of the landmarks generated during data_dst faceset/dataset extraction.
learned-prd: uses masks learned during training. Keep shape of SRC faces.
learned-dst: uses masks learned during training. Keep shape of DST faces.
learned-prd*dst: combines both masks, smaller size of both.
learned-prd dst: combines both masks, bigger size of both.
XSeg-prd: uses XSeg model to mask using data from source faces.
XSeg-dst: uses XSeg model to mask using data from destination faces.
XSeg-prddst: combines both masks, smaller size of both.
learned-prddstXSeg-dstprd: combines all 4 mask modes, smaller size of all.
10. Color transfer modes: 与训练过程中的颜色转移类似,您可以使用此功能将学习到的脸部的肤色与原始帧更好地匹配,以实现更加无缝和逼真的脸部交换。 有8种不同的模式: 建议修改 RCT和LCT
- RCT
- LCT
- MKL
- MKL-M
- IDT
- IDT-M
- SOT - M
- MIX-M
11. Image degrade modes: 您可以使用3种设置来影响原始帧的外观(不影响换面):
Denoise - denoises image making it slightly blurry (I - increases effect, K - decrease effect)
Bicubic - blurs the image using bicubic method (O - increases effect, L - decrease effect)
Color - decreases color bit depth (P - increases effect, ; - decrease effect)
附加控件::
TAB button - 在主预览窗口和帮助屏幕之间切换。
请记住,您只能在主预览窗口中更改参数,按帮助屏幕上的任何其他按钮都不会更改它们。
-/_ and =/ buttons are used to scale the preview window.
Use caps lock to change the increment from 1 to 10 (affects all numerical values).
要保存/覆盖当前一帧中所有下一帧的设置 shift /
要保存/覆盖当前一帧中所有先前帧的设置 shift M
要开始合并所有帧,请按 shift >
要返回第一帧,请按 shift <
要仅转换下一帧,请按 >
要返回上一帧,请按 <
8.3 把转化好的帧合成为视频
合并/转换所有面部之后,“ data_dst”文件夹中将有一个名为“ merged”的文件夹,其中包含构成视频的所有帧。
最后一步是将它们转换回视频,并与data_dst.mp4文件中的原始音轨合并。
为此,您将使用提供的4个.bat文件之一,这些文件将使用FFMPEG将所有帧组合成以下格式之一的视频-avi,mp4,lessless mp4或lossless mov:
- merged to avi
- merged to mov lossless 无损mov
- merged to mp4 lossless 无损MP4
- merged to mp4
9,附录:
src和dst视频素材,任何一个换人了都要重新训练model模型,始终保持一对一。
可以这样:假如src中的视频人物是钢铁侠,那么后面可以找很多钢铁侠的视频素材来充当src素材进行训练,也就是说src中的人物一样,但是具体视频可以多样,dst也如此。
10,常见问题和回答(来自于网络)
(10.1) 1.0和2.0有什么区别?
2.0是经过改进和优化的版本,由于进行了优化,它提供了更好的性能,这意味着您可以训练更高分辨率的模型或更快地训练现有模型。 合并和提取也明显更快。 问题在于DFL 2.0不再支持AMD GPU / OpenCL,唯一的使用方法是与Nvidia
GPU(需要最少3.0 CUDA计算级别的GPU支持)或CPU一起使用。
请记住,在CPU上进行训练的速度要慢得多,其他所有步骤(例如提取和合并(以前称为转换))也要慢得多。
此外,新版本仅提供2种型号-SAEHD和Quick 96,没有H128 / H64 / DF / LIAEF / SAE型号。
同样,从1.0开始的所有训练/预训练模型(SAE / SAEHD)与2.0不兼容,因此您需要训练新模型。
在上面的主要指南中,您还可以了解其他一些更改。
(10.2) 做一次换脸需要多长时间?
根据目标(DST)视频的时长,SRC数据集/面集的大小以及用于训练的硬件(GPU)的模型的类型。
如果您是从头开始训练模型或制作更长的deepfake,则在经过预训练的模型上进行简单,短暂的可能需要半天到5到7天的时间,特别是如果高分辨率全脸型需要额外的时间
培训XSeg模型,甚至在合并视频编辑软件后进行一些工作。 这也取决于您拥有的硬件,如果您的GPU的VRAM较少(4-6
GB),则需要花费更长的时间来训练具有更强大GPU(8-24GB)的模型。
它还取决于您的技能,查找SRC数据集/面容的原始资料的速度,可以找到合适的目标(DST)视频的速度以及为训练准备两个数据集的速度有多快。
(10.3) 你能用几张照片制作一个deepfake视频吗?
通常,答案是“否”。 推荐使用面部表情制作像样的deepfake的方法是使用视频。角度和面部表情越多越好。
当然,您可以尝试只用几百张照片制作一个deepfake视频,它可以正常工作,但结果却不那么令人信服。
(10.4) 理想的人脸数据数量是多少?
对于data_src 脸部,建议至少拥有4000-6000张不同的图像。当然,您可以拥有更多但通常10.000-15.000张图像就足够了,只要数据集中有多种(不同的面部角度和表情)。
最好将它们用于尽可能少的源,使用的源越多(尤其是当不同源之间相似的表达式/角度“重叠”时),将模型变形为DST的可能性越高,看起来更像是SRC,可能需要运行TF 或保持启用RW的模型训练时间更长。
(10.5) 为什么我的deepfake变得模糊?
面孔模糊的原因很多。最常见的原因包括-训练时间不够长,源数据集中缺少必要的角度,提取的源或目标面集/数据集的对齐方式不正确,训练或合并过程中的设置不正确,源面或目标面集/数据集中的人脸模糊。 如果您想知道做些什么以及在做一次深度仿真时应避免什么
(10.6) 为什么我的结果脸没有眨眼/眼睛看起来不对/眼睛交叉?
这很可能是由于data_src中缺少图像而导致的,这些图像包含闭着眼睛或以特定角度或某些角度朝特定方向注视的面孔。确保在所有可能的角度上都有相当数量的不同面部表情,以匹配目标/目标视频中的面部表情和角度-其中包括睁着眼睛并朝不同方向看的面部,而模型不知道这些 脸部的眼睛看起来应该怎样,导致眼睛无法睁开或看上去全都错了。
造成此问题的另一个原因可能是使用错误的设置或调暗设置减少了跑步训练。
(10.7) 我什么时候应该停止训练?
没有正确的答案,但是普遍的共识是使用预览窗口来判断何时停止训练和转换。没有确切的迭代次数或损失值,您应在此停止训练。 如果您正在运行预训练的模型,则建议至少进行100.000次迭代;如果从0开始运行新模型,则建议至少进行200.000次迭代,但是该数目甚至可能高达300.000次迭代(取决于模型必须学习的面孔的数量和数量) 。
(10.8) 我什么时候应该启用或禁用随机扭曲,GAN,真面,样式效果,色彩转移和学习率下降
1.从“随机扭曲”开始,只要使模型能够泛化并达到0.4-0.6左右的损耗值,就应启用它-预测面(预览的第二和第四列)和最终结果面(第五列)应看起来正确,但可能仍然模糊。
2.接下来,您可以启用诸如Uniform Yaw之类的选项,以帮助概括轮廓面或帮助培训它们,以防您在源数据集中没有很多东西的情况下使用,但是不必总是使用RW来运行此选项,以后可以在启用该选项时启用禁用RW。
3.在禁用RW之前,您可以启用LRD并对其进行更多地训练,以使其在此阶段中学习更多,接下来,您将禁用RW和LRD,以便模型可以在下一阶段中正确进行训练。稍后,在禁用RW的情况下进行训练并有选择地为4-9运行一些其他选项之后,您可以第二次启用LRD,在LRD之后,您不应启用GAN以外的任何其他选项。
4.可以在禁用“随机扭曲”之前或之后使用“ True Face and Style Power”,但是建议在禁用RW之后以及启用LRD之前使用它们。
5. GAN应该最后启用,并且在同时启用LRD时也必须启用。
6.可以从培训开始或结束时就启用颜色转移,这完全取决于您的SRC面部表情/数据集在色彩方面与DST /目标视频的匹配程度。
7.仅当源面集/数据集缺少某些角度时才应启用随机翻转-注意使用随机翻转可能会导致某些问题,并且如果面部具有一些不对称的特征-它们将被镜像,建议您在启动随机翻转时RW仍处于启用状态。
8.对于大多数训练,应该启用蒙版训练(仅全脸),因为它有助于训练模型需要学习的内容,即所应用的XSeg遮罩(如果XSeg遮罩为未应用),但是如果您打算在合并过程中腐蚀蒙版(如果源面比DST大/宽,并且您不希望它的形状被蒙版剪切),则可以禁用它(如果这样做)确保在启用GAN之前先执行此操作。
9.禁用RW之后但在LRD和GAN之前,应启用眼睛优先级,因为其他选项可能会引起问题(真面目,样式效果)。在某些情况下,当仍在使用RW时,用户在运行它时报告了良好的效果,但请记住,启用它会优先考虑眼睛区域和面部其余部分,其学习速度不会像平常那样快。
(10.9) DFL根本不起作用(提取,培训,合并)和/或我收到错误消息。
您的GPU可能不受支持,您正在尝试在较新版本的DFL上运行旧模型(或以其他方式),或者软件或PC出现问题。
首先检查您的GPU是否受支持,DFL需要CUDA计算能力为3.0:
然后查看是否拥有DFL的最新版本:GOOGLE DRIVE TORRENT
然后检查您要运行的模型是否仍然兼容,最简单的方法是尝试运行具有相同参数的新模型(将批次大小调整为较低的值,例如2-4,以进行测试)
如果仍然有问题,请检查您的PC,GPU驱动程序过时和Windows更新等待中之类的事情可能会引起一些问题。
如果仍然无法运行,则可以在问题部分中创建一个新线程.
(10.10) 训练SAEHD时出现OOM /内存不足错误。
如果遇到OOM错误,则意味着您的VRAM即将用尽,可以更改各种设置来解决此问题:
a)减少批次大小-较低的批次大小意味着模型在较少的图像上进行训练,因此使用较少的VRAM,但这意味着与达到较高的批次大小相比,您将需要更长的训练时间才能达到相同的结果,例如2-4的极低批次大小也会导致结果准确性降低。
b)更改优化器设置(models_opt_on_gpu)-设置为True时,优化器和模型均由GPU处理,这意味着更快的迭代时间/性能/更快的训练,但VRAM使用率更高;如果设置为False,则将处理运行网络优化器的职责通过CPU进行操作,这意味着较少的VRAM使用量,可能没有OOM,甚至可能的批处理量更大,但是由于迭代时间较长,因此训练速度会变慢。
c)关闭其他功能,例如面部和bg样式转换,TrueFace训练,GAN训练或性能沉重的CT方法(如SOT-M)-使它们增加迭代/训练时间并使用更多的VRAM。
(10.11) 我的源数据集中有太多相似的面孔,有没有可以用来删除它们的工具?
您可以使用内置的DFL排序方法,也可以使用VisiPics之类的应用来检测源数据集中的相似外观并将其删除。
(10.12) 我正在训练已经进行了数千次迭代的模型,但是预览窗口中的面孔突然变成黑/白/看起来很怪异,我的损失值上升/为零。
您的模型已经崩溃,这意味着您不能再使用它,必须重新开始,如果有备份,请使用它们。为防止模型崩溃,请使用渐变裁剪或仅启用备份,通常除非使用样式功能(否则强烈建议启用渐变裁剪),否则模型不会崩溃(但强烈建议您启用渐变裁剪),即使您担心即使没有启用任何其他功能也要崩溃 您可以始终在不影响性能的情况下始终启用它(可能很难注意到,根据我的测试,最多最多可以增加50-100毫秒)。
(10.13) 如果我训练Celeb A的模型(data_src)并使用Celeb B(data_dst)作为目的地,是否可以使用相同的Celeb A模型替换新的Celeb C? 我可以重用模型吗?
实际上,如果您打算对同一来源进行更多的创作,甚至在使用同一数据集时,也建议重用您的模型。 当使用完全不同的源和目标/目标时,您也可以重新使用模型。
(10.14) 我应该预训练我的模型吗?
与重用一样,是的,您应该进行预训练。使用DFL内置的预训练功能,您可以在启动模型时选择该功能。 这是预训练模型,在200k至400k迭代中的任何位置运行此功能并在要完成预训练后将其关闭的正确方法。
(10.15) 我遇到错误:不是在DeepFaceLab中训练所需的dfl图像文件error: is not a dfl image file required for training in DeepFaceLab
这意味着data_src / aligned和/或data_dst内部的图片对于DFL训练无效。
这可能是由以下几方面引起的:
1.您正在使用的共享数据集之一,尽管它们看起来像对齐的面孔(256x256图像)可能只是从中提取的图片,但它们是由不同于DFL的软件或较旧版本制作的。以不同方式存储界标/路线数据的不同应用。要修复它们,您只需要对它们运行对齐过程,只需将它们放入“ data_src”文件夹(而不是其中的“ aligned”文件夹),然后使用4重新对齐它们即可。data_src提取面S3FD
2.对齐后,您在gimp / photoshop中的data_src或data_dst的对齐文件夹中编辑了脸部/图像。
编辑这些图像时,将覆盖存储在其中的地标/路线数据。
如果要编辑这些图像,请首先运行4.2)data_src util faceset元数据保存以将对齐信息保存在单独的文件中,然后编辑图像并运行4.2)data_src util faceset元数据恢复以还原该数据。
仅允许编辑AI放大/增强功能(您现在也可以使用4.2进行操作)data_src实用面部设置增强功能,而不是使用外部应用程序(例如Gigapixel),颜色校正或对不改变其形状的面部进行编辑(例如删除或添加内容),则不允许翻转/镜像或旋转。
3.您的“ data_src / dst”或“ aligned”文件夹中有未提取的未对齐的常规图像。
4.您的“ data_src / aligned”文件夹中有_debug面。删除它们。
(10.16) 转换时出现错误:找不到XYZ.jpg / png的人脸,没有人脸地复制。
这意味着对于“ data_dst”文件夹中的XYZ帧,没有脸部被提取到“ aligned”文件夹中。
这可能是因为在该帧中实际上没有可见的脸部(正常),或者它们是可见的,但是由于它们所处的角度或障碍物而无法检测到。
要解决此问题,您需要手动提取这些面孔。 查看主要指南,尤其是有关清理data_dst数据集的部分。
总体而言,在开始训练之前,应确保已对齐并正确提取了多少张面孔。
并记住,在训练之前应该清理两个数据集.
(10.17) 合并后,我在某些或所有合并帧中看到原始/ DST面
确保将转换器模式设置为叠加模式或“原始”模式以外的任何其他模式,并确保已对齐data_dst.mp4文件所有帧中的面。
如果您仅在某些帧上看到原始人脸,那是因为未从相应的帧中检测到它们/将它们对齐,则可能由于各种原因而发生这种情况:难以看到人脸的极端角度,模糊/运动模糊,障碍物等。 总体而言,您希望始终将data_dst.mp4中的所有面孔对齐。
(10.18) 训练时那些0.2513 0.5612代表什么意思?
这些是损失值。 它们表明模型的训练程度。但是,除非它们已经稳定在某个值附近(假设您没有更改任何模型参数),否则您不应该关注它们,除非看到它们的值突然上升(上下波动),而应关注预览窗口并查找诸如 牙齿分离,美容痕迹,鼻子和眼睛,如果它们锋利且看起来不错,那么您就不必担心任何事情。 如果您发现损耗值由于某些原因尽管没有改变但仍因某些原因而上升,请考虑停止训练并通过梯度裁剪恢复它,或者禁用一些其他选项,这些选项可能是您在错误的设置下启用的,这现在会引起问题。
(10.19) 理想损耗值是多少,低/高损耗值应为多少?
这完全取决于设置,数据集和各种不同的因素。通常,您希望在禁用所有功能的情况下开始训练,但样本的随机扭曲(以及可选的梯度裁剪,以防止模型崩溃和万一您的源数据集缺少某些面部/头部角度的情况下进行随机翻转)损失到0.4-0.5以下(取决于 模型架构,以及是启用了屏蔽训练的全脸模型还是启用了屏蔽训练的全脸/头部模型,以及模型分辨率或模型尺寸。
禁用随机扭曲模型后,应该能够达到0.15到0.25之间的损失值。
在某些情况下,您的模型可能会陷入某些损失值,或者永远无法达到较低的损失值。
(10.20) 我的模型崩溃了,我能以某种方式恢复它吗?
不,您需要重新开始,或者如果使用了备份,请使用备份。
(10.21) 如果您使用名人面部表情训练并且想要向其中添加更多面部/图像/框架怎么办? 如何为现有src / source / celebrity数据集增加更多种类?
最安全的方法是将整个“data_src”文件夹的名称更改为其他名称,或将其临时移动到其他位置,然后从新的data_src.mp4文件中提取帧,或者如果您已经提取了帧并准备好一些图片,则创建一个 新文件夹“ data_src”,将其复制到其中并运行data_src提取/对齐过程,然后将对齐的图像从旧的data_src / aligned文件夹复制到新文件夹中,并在Windows要求替换或跳过时,选择重命名选项 文件,因此您可以保留所有文件,而不会最终用新文件替换旧文件。
(10.22)dst faceset / data_dst.mp4是否也需要清晰且高质量? dst faceset / dataset / data_dst中的某些面孔会有点模糊/有阴影等吗? 我的data_dst / aligned文件夹中的面孔模糊怎么办
您希望您的data_dst尽可能清晰,并且没有任何运动模糊。 data_dst中的面孔模糊会导致几个问题:
-首先是某些框架中的某些面孔将不会被检测到-转换/合并时,原始面孔将显示在这些框架上,因为在提取过程中无法正确对齐它们,因此您必须手动提取。
-其次是其他人可能未正确对齐-这将导致该帧上的最终脸部旋转/模糊,并且看起来很不正确,并且与其他模糊脸部相似,必须手动对齐才能用于训练和转换。
-第三-即使在某些情况下使用手动对齐,也可能无法正确检测/对齐面部,这又将导致原始面部在相应的帧上可见。
-包含运动模糊或正确对齐的模糊(不清晰)的面部可能仍会产生不良结果,因为用于训练的模型无法理解运动模糊,模糊时面部的某些部分(如嘴巴)可能显得更大/更宽或只是不同而已,模型会将其解释为该部分的形状/外观发生了变化,因此,预测的假面和最终的假面都将看起来不自然。
您应该从训练数据集(data_dst / aligned文件夹)中删除那些模糊的面部,然后将它们放在其他地方,然后再将它们复制回data_dst / aligned文件夹,然后再进行转换,这样我们可以将交换的面部显示在与那些模糊的面部相对应的帧上。
要消除运动中的怪异表情,您可以在合并中使用运动模糊(但不适用于“ data_dst / aligned”文件夹中只有一组面孔且所有文件都以_0前缀结尾的情况)。
您希望SRC数据集和DST数据集都尽可能清晰和高质量。
某些帧上的少量模糊不应该引起很多问题。至于阴影,这取决于我们在谈论多少阴影,可能看不见小的浅色阴影,您可以在脸上带有阴影的情况下获得良好的效果,但在很大程度上也会看起来很糟糕,您希望将脸部照亮均匀分布,并尽可能减少刺眼/尖锐和深色阴影。
(10.23) 我不小心删除了data_dst.mp4文件,无法恢复,仍然可以将合并/转换后的帧转换为mp4视频吗?
是的,如果您已经永久删除了data_dst.mp4,并且无法恢复它或呈现相同的文件,您仍然可以使用ffmpeg和适当的命令将其手动转换回mp4(尽管没有声音)
(10.24) 您可以暂停合并,然后再恢复吗? 您可以保存合并设置吗? 我的合并失败/合并时出现错误,并且卡在%处,我可以再次启动它,然后从上一个成功合并的帧开始合并吗?
是的,默认情况下,交互式转换器/合并在“模型”文件夹中创建会话文件,该文件同时保存进度和设置。
如果您只想暂停训练,则可以单击>,它将暂停。 但是,如果您需要将其完全关闭/重新启动PC等,则退出了与esc的合并,并等待它保存进度,下次选择合并/转换器(Y / N)后,下次启动合并时-是,您会 将会提示您是否要使用保存/会话文件并恢复进度,合并将在正确的框架处以正确的设置加载。
如果合并失败并且没有保存进度,则必须手动恢复它,方法是先备份“ data_dst”文件夹,然后删除data_dst中所有提取的帧以及“ aligned”文件夹中的所有图像 在“ data_dst”内部,对应于已在文件夹“ merged”中转换/合并的帧。 然后,只需启动合并/转换器,输入之前使用的设置,然后转换其余帧,然后从备份的“ data_dst”文件夹中将新合并的帧与旧的合并,并照常转换为.mp4即可。
(10.25) 训练期间预览中的面孔看起来不错,但转换后看起来很糟。 我看到了原始脸的一部分(下巴,眉毛,双脸轮廓)。
预览中的面孔是AI的原始输出,然后需要在原始素材上进行合成。因此,当人脸形状不同或稍小/较大时,您可能会在DFL合并创建的蒙版周围/外部看到原始人脸的一部分。
要解决此问题,您需要更改转换设置,方法是:
-调整遮罩类型
-调整遮罩腐蚀(大小)和模糊(羽化,使边缘平滑)
-调整脸部大小(比例)
注意:负腐蚀会增加面罩的尺寸(覆盖更多),正腐蚀会减小面罩的尺寸。
(10.26) 半脸,半脸,全脸和全脸face_type模式有什么区别?
全脸是覆盖整个脸部/头部的新模式,这意味着它也覆盖了整个额头,甚至覆盖了某些头发和其他特征,这些特征可能会被全脸模式剪切掉,并且在使用一半或一半时绝对不会出现脸部模式。它还在训练过程中带有新选项,让您训练称为masked_training的额头。首先,先启用它,然后将训练蒙版剪切到整个脸部区域,一旦对脸部进行了足够的训练,就禁用它并训练整个脸部/头部。此模式需要在后期手动屏蔽或训练自己的XSeg模型:
建议使用全脸face_type模式,以尽可能多地遮盖脸部,而无需多余的东西(发际线,额头和头部其他部位)半脸模式是H64和H128模型中的默认face_type模式。它只覆盖一半的脸(从嘴到眉毛以下)
半脸是覆盖半脸约30%区域的一种模式。
(10.27) 什么是最适合深度伪造的GPU? 我想升级我的GPU,我应该得到哪一个?
20系最好,30系等更新
(10.28) AutoEncoder,Encoder,Decoder和D_Mask_Decoder维度设置有什么作用? 更改它们有什么作用?
可以更改它们以提高性能或质量,将它们设置为高将使模型真的很难训练(缓慢,高使用vram),但会提供更准确的结果和更多的src,如外观,将其设置为低将提高性能但是结果将不太准确,并且模型可能无法学习人脸的某些特征,从而导致通用输出看起来更像dst或什么都不像dst或src。
自动编码器尺寸(32-1024?:help):这是学习的整体模型能力。
价值太低,将无法学习所有内容-更高的价值将使模型能够学习更多表达式,并且以性能为代价更加准确。
编码器尺寸(16-256?:help):这会影响模型学习不同表情,面部状态,角度,照明条件的能力。
值太低,模型可能无法学习某些表达式,模型可能无法闭上眼睛,嘴巴,某些角度的细节可能不够准确,较高的值将导致模型更加准确和富有表现力,但会相应提高性能成本。
解码器尺寸(16-256?:help):这会影响模型学习精细细节,纹理,牙齿,眼睛的能力,这些微小的事物会使人的面部变得细腻且可识别。
值太低将导致无法学习某些细节(例如牙齿和眼睛看起来模糊,缺少纹理),也可能无法正确学习一些微妙的表情和面部特征/纹理,从而导致像面部表情一样的src更少,价值更高将使面部更加细化,模型将能够以性能为代价选择更多这些细微的细节。
解码器蒙版尺寸(16-256?:help):在启用学习蒙版的情况下进行训练时,会影响学习的蒙版的质量。不影响培训质量。
(10.29) 推荐的批量大小是多少? 我应该设置多大的批量大小? 批量大小可以设置多低?
没有建议的批量大小,但是合理的值在8-12之间,其中16-22以上的值非常好,最小4-6的值。批次大小2不足以正确训练模型,因此建议的最小值为4,值越大越好,但是在某些时候批次大小可能不利,尤其是在迭代时间开始增加或您有禁用models_opt_on_gpu-从而在CPU上强制优化器,这会减慢训练速度/增加迭代时间。
您可以通过将迭代时间除以批次大小来计算何时增加批次大小变得效率较低。选择可以在给定的迭代时间内为每个批次降低ms值的批次大小,例如:
批次8-1000/8 = 1000时1000 ms
批处理1500毫秒10-1500/10 = 150
在这种情况下,与批次10相比,在批次8中运行将在给定时间内提供更多的数据模型,但是差异很小。如果说我们要使用批处理12,但得到一个OOM-因此我们禁用models_opt_on_gpu,它现在看起来可能像这样:
批次12时为2300毫秒(CPU上的Optimizer)-2300/12 = 191毫秒,这比批次8和迭代时间为1000毫秒的128毫秒长得多。
启动模型时,最好使用较小的批处理大小-较长的迭代时间,然后在禁用随机扭曲时增加它。
(10.30) 如何使用预训练模型?
只需下载它,然后将所有文件直接放入模型文件夹即可。
开始训练,在选择要训练的模型(如果文件夹中还有更多)和要训练的设备(GPU / CPU)之后的2秒钟内按任意键,以覆盖模型设置,并把最后一个选项(是否启用预训练模式 use pretrain mode)改为N,以便正确启动 训练中,如果您启用了预训练选项,则模型将继续进行预训练。 请注意,关闭预训练模式后,模型会将迭代计数还原为0,这是预训练模型的正常行为,莫慌。正常情况下,关闭预训练模式后,模型训练预览图是直接能看到八九不离十的人脸,如果你发现你的预览图又从一片完全看不出人形的灰褐色开始,莫慌,按以下步骤操作:
- 按enter回车结束训练
- 把下载的预训练模型原始文件中几个.npy文件(只要.npy格式的文件,其余文件不要)复制替换到 模型文件夹中
- 重新启动训练,把最后一个选项(是否启用预训练模式 use pretrain mode)改为N
然后就可以愉快的训练自己的人脸数据了
(10.31) 我的GPU使用率非常低,尽管选择了GPU进行训练/合并,也没有使用GPU。
它可能正在使用中,但是Windows不仅报告CUDA使用情况(这是您应该查看的),而且GPU的总使用情况可能会更低(大约5-10%)。
要在培训期间(在Windows 10中)查看CUDA / GPU的真实使用情况,请进入任务管理器->性能->选择GPU->将4个较小的图形之一更改为CUDA。
如果您使用的是其他版本的Windows,请下载外部监视软件(例如HWmonitor或GPU-Z),或者查看VRAM的使用情况,该使用率应接近培训期间的最大值。
11,笔记(持续更新)
1、分享滚石大佬的通用训练方式
先开这组参数训练10-60W
face type : WF
random_flip : off
adabelief : on
eyes_mouth_prio : on
ct_mode: lct .
再开这个训练10-30W
learning rate drop:y (建议不要轻易开)
再关闭随机扭曲训练10-30W
random warp:n
最后开GAN训练10-30W
GAN poewer: 0.1
2、在有底丹的基础上换src
方法1:
首先,训练数据要足够清晰,减少模糊素材比例
其次,训练足够充分
然后,训练充分后把随机扭曲(random warp)关闭
最后,训练充分后开GAN 0.01-0.1(一定要开启自动备份和梯度裁剪Enable gradient clipping,以免模型跑崩)
方法2:先开 RW随即翻转 和 MAKSK遮罩训练,然后跑到基本清晰了再开LR和嘴眼和侧脸,记得关闭随机扭曲,逐渐恢复原始参数
3、颜色不一致问题
关闭所有选项, 颜色转换 开启 RCT, 练习至颜色统一


![[ZT]Window Mobile视频会议程序的开发](/images/no-images.jpg)