用法很简单,先安装Scrapy,我这里是win10环境,py3.10+
安装scrapy
pip install Scrapy
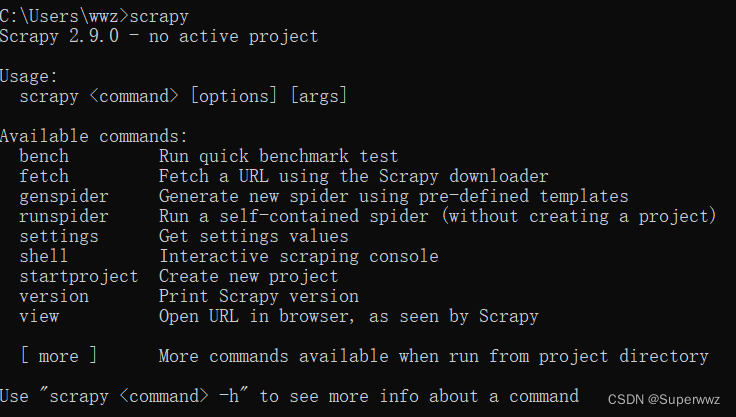
显示如图安装完毕
创建项目
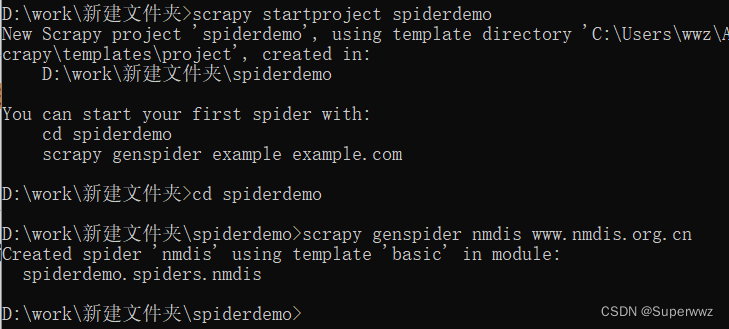
分三步创建
scrapy stratproject spiderdemo #创建spiderdemo 项目,项目名随意取
cd spiderdemo #进入项目目录下
scrapy genspider nmdis www.nmdis.org.cn #爬虫名为nmdis ,后面接url
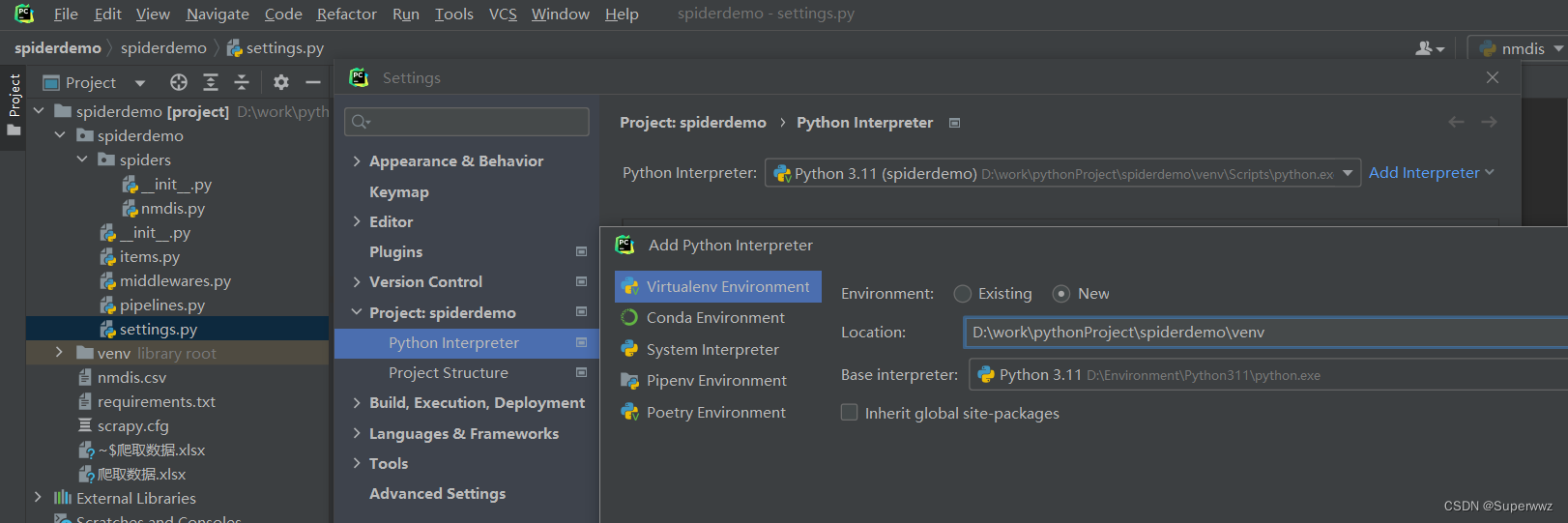
项目创建完配置venv虚拟环境,目的是为了每个项目用自己的包,当然也可以不配置用全局环境,至此环境搭建完成。
例子:爬取网页 https://www.nmdis.org.cn/hyxw/gnhyxw/ 新闻模块
nmdis.py文件
import scrapy
from scrapy import Selector, Request
from scrapy.http import HtmlResponsefrom spiderdemo.items import DetailItemclass NmdisSpider(scrapy.Spider):name = "nmdis"allowed_domains = ["nmdis.org.cn"]def start_requests(self):for page in range(1):print(f"爬取页数:{page + 1}")if page < 1:yield Request(url=f'https://www.nmdis.org.cn/hyxw/gnhyxw/')else:yield Request(url=f'https://www.nmdis.org.cn/hyxw/gnhyxw/index_{page + 1}.shtml')# 获取详情页的urldef parse(self, response: HtmlResponse):sel = Selector(response)url_items = sel.css("div.title.fl.ellipsis > a::attr(href)")for url in url_items:detail_item = DetailItem()detail_item['details_url'] = response.urljoin(url.extract())details_url = response.urljoin(url.extract())# 回调yield Request(url=details_url, callback=self.parse_detail, cb_kwargs={'item': detail_item})# 获取详情页数据def parse_detail(self, response, **kwargs):detail_item = kwargs['item']sel = Selector(response)detail_item['title'] = sel.xpath('//h2[@class="maintit"]/text()').extract_first()detail_item['source'] = sel.xpath('//em[@class="fl"]/text()').extract_first()detail_item['release_time'] = sel.xpath('//em[@class="fr"]/text()').extract_first()detail_arr = sel.xpath('//div[@class="bodytext"]//text()').extract()detail_item['context'] = "".join(detail_arr)yield detail_itemitems.py文件
import scrapyclass DetailItem(scrapy.Item):details_url = scrapy.Field()title = scrapy.Field()source = scrapy.Field()release_time = scrapy.Field()context = scrapy.Field()
配置settings.py代理 f12 在请求里面找一个就行

scrapy crawl nmdis运行即可
导入到excel
导入openpyxl包
pip install openpyxl
pipelines.py 编写管道输出
class SpiderdemoPipeline:def __init__(self):self.wb = openpyxl.Workbook()self.ws = self.wb.activeself.ws.title = '标题测试'self.ws.append(('来源地址', '标题', '信息来源', '发布时间', '内容'))def close_spider(self, spider):self.wb.save('爬取数据.xlsx')def process_item(self, item, spider):details_url = item.get('details_url') or ''title = item.get('title') or ''source = item.get('source') or ''release_time = item.get('release_time') or ''context = item.get('context') or ''self.ws.append((details_url, title, source, release_time, context))return item
settings.py打开管道配置

scrapy crawl nmdis运行即可
实用命令
可以在自己的项目中生成包文件
pip freeze > requirements.txt #生成pip文件
若存在requirements文件可以导入其他项目中的包依赖
pip install -r requirements.txt #安装文件的依赖项