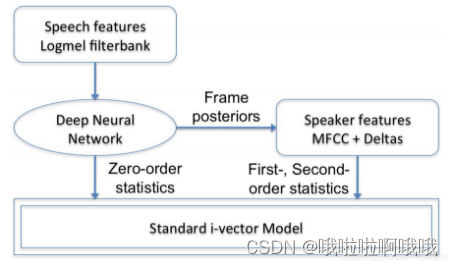
声纹识别属于生物识别技术的一种,是一项根据语音波形中反映说话人生理和行为特征的语音参数,自动识别说话人身份的技术。与语音识别不同的是,声纹识别利用的是语音信号中的说话人信息,而不考虑语音中的字词意思,它强调说话人的个性;而语音识别的目的是识别出语音信号中的言语内容,并不考虑说话人是谁,它强调共性。 声纹识别系统主要包括两部分,即特征检测和模式匹配。特征检测的任务是选取唯一表现说话人身份的有效且稳定可靠的特征,模式匹配的任务是对训练和识别时的特征模式做相似性匹配。
1.特征提取
声纹识别系统中的特征检测即提取语音信号中表征人的基本特征,此特征应能有效地区分不同的说话人,且对同一说话人的变化保持相对稳定。考虑到特征的可量化性、训练样本的数量和系统性能的评价问题,目前的声纹识别系统主要依靠较低层次的声学特征进行识别。说话人特征大体可归为下述几类:
谱包络参数语音信息通过滤波器组输出,以合适的速率对滤波器输出抽样,并将它们作为声纹识别特征。
基音轮廓、共振峰频率带宽及其轨迹 这类特征是基于发声器官如声门、声道和鼻腔的生理结构而提取的参数。
线性预测系数使用线性预测系数是语音信号处理中的一次飞跃,以线性预测导出的各种参数,如线性预测系数、自相关系数、反射系数、对数面积比、线性预测残差及其组合等参数,作为识别特征,可以得到较好的效果。主要原因是线性预测与声道参数模型是相符合的。
反映听觉特性的参数模拟人耳对声音频率感知的特性而提出了多种参数,如美倒谱系数、感知线性预测等。
此外,人们还通过对不同特征参量的组合来提高实际系统的性能,当各组合参量间相关性不大时,会有较好的效果,因为它们分别反映了语音信号的不同特征。
2.模式匹配
目前针对各种特征而提出的模式匹配方法的研究越来越深入。这些方法大体可归为下述几类:
概率统计方法
语音中说话人信息在短时内较为平稳,通过对稳态特征如基音、声门增益、低阶反射系数的统计分析,可以利用均值、方差等统计量和概率密度函数进行分类判决。其优点是不用对特征参量在时域上进行规整,比较适合文本无关的说话人识别。
动态时间规整方法
说话人信息不仅有稳定因素(发声器官的结构和发声习惯),而且有时变因素(语速、语调、重音和韵律)。将识别模板与参考模板进行时间对比,按照某种距离测定得出两模板间的相似程度。常用的方法是基于最近邻原则的动态时间规整DTW。
矢量量化方法
矢量量化最早是基于聚类分析的数据压缩编码技术。Helms首次将其用于声纹识别,把每个人的特定文本编成码本,识别时将测试文本按此码本进行编码,以量化产生的失真度作为判决标准。Bell实验室的Rosenberg和Soong用VQ进行了孤立数字文本的声纹识别研究。这种方法的识别精度较高,且判断速度快。
隐马尔可夫模型方法
隐马尔可夫模型是一种基于转移概率和传输概率的随机模型,最早在CMU和IBM被用于语音识别。它把语音看成由可观察到的符号序列组成的随机过程,符号序列则是发声系统状态序列的输出。在使用HMM识别时,为每个说话人建立发声模型,通过训练得到状态转移概率矩阵和符号输出概率矩阵。识别时计算未知语音在状态转移过程中的最大概率,根据最大概率对应的模型进行判决。HMM不需要时间规整,可节约判决时的计算时间和存储量,在目前被广泛应用。缺点是训练时计算量较大。
人工神经网络方法
人工神经网络在某种程度上模拟了生物的感知特性,它是一种分布式并行处理结构的网络模型,具有自组织和自学习能力、很强的复杂分类边界区分能力以及对不完全信息的鲁棒性,其性能近似理想的分类器。其缺点是训练时间长,动态时间规整能力弱,网络规模随说话人数目增加时可能大到难以训练的程度。
把以上分类方法与不同特征进行有机组合可显著提高声纹识别的性能,如NTT实验室的T. Matsui和S. Furui使用倒谱、差分倒谱、基音和差分基音,采用VQ与HMM混和的方法得到99.3%的说话人确认率。
对于说话人确认系统,表征其性能的最重要的两个参量是错误拒绝率和错误接受率。前者是拒绝真实的说话人而造成的错误,后者是接受假冒者而造成的错误,二者与阈值的设定相关。说话人确认系统的错误率与用户数目无关,而说话人辨认系统的性能与用户数目有关,并随着用户数目的增加,系统的性能会不断下降。
总的说来,一个成功的说话人识别系统应该做到以下几点:
能够有效地区分不同的说话人,但又能在同一说话人语音发生变化时保持相对的稳定,如感冒等情况。
不易被他人模仿或能够较好地解决被他人模仿问题。
在声学环境变化时能够保持一定的稳定性,即抗噪声性能要好
声纹识别应用前景
与其他生物识别技术,诸如指纹识别、掌形识别、虹膜识别等相比较,声纹识别除具有不会遗失和忘记、不需记忆、使用方便等优点外,还具有以下特性:
用户接受程度高,由于不涉及隐私问题,用户无任何心理障碍。
利用语音进行身份识别可能是最自然和最经济的方法之一。声音输入设备造价低廉,甚至无费用(电话),而其他生物识别技术的输入设备往往造价昂贵。
在基于电信网络的身份识别应用中,如电话银行、电话炒股、电子购物等,与其他生物识别技术相比,声纹识别更为擅长,得天独厚。
由于与其他生物识别技术相比,声纹识别具有更为简便、准确、经济及可扩展性良好等众多优势,可广泛应用于安全验证、控制等各方面,特别是基于电信网络的身份识别。