关于声纹识别的算法及知识层出不穷,一文带你了解声纹识别:
一、算法总览
1. 最早的GMM-UBM i-vector
利用GMM高斯混合模型提取特征i-vector;克服训练数据不多的情况,引入UBM;将语音分为说话人空间和环境空间,解决环境带来的信道,PLDA实现信道补偿,将提取的i-vector更加纯粹。
当然,获取i-vector的方法不仅仅局限在高斯混合模型,利用一起其它的机器学习方法进行补充一样可以,甚至是DNN提取的特征。
2. DNN
DNN的引入极大的降低了识别错误率。这时候的算法,可以称为embedding算法,依然是提取特征,不过这时候提取的是神经网络最后隐藏层的激活单元了,作为embedding,代替i-vector来作为一段语音的特征表示。
这时候出现了d-vector(深度神经网络最后一个隐藏层作为embeddings特征)、x-vector(从TDNN网络中提取embeddings特征)、j-vector模型(适用于文本相关说话人确认)
3. 端到端系统
无论是获得i-vector,还是DNN提取出的embedding,都是从语音中提取出特征再做分类或者确认。而端到端系统将这2段合到一个系统中,从输入到输出,一体化特征训练和分类打分。这和之前有了重大的不同。
二、初识声纹
1. 什么是声纹?
声纹(Voiceprint )是用电声学仪器现实的携带言语信息的声波频谱, 是由波长频率以及强度等百余种特征维度组成的生物特征,具有稳定性、可测量性、唯一性等特点。
- 人类语言的产生是人体语言中枢与发音器官之间一个复杂的生理物理过程,发声器官–舌、牙齿、喉头、肺、鼻腔在尺寸和形态方面每个人的差异很大,所以任何两个人的声纹图谱都有差异。
- 每个人的语音声学特征既有相对稳定性,又有变异性,不是一成不变的。这种变异可来自生理、病理、心理、模拟、伪装,也与环境干扰有关。
声纹不如图像那样直观展现,在实际分析中,可通过波形图和语谱图进行展现

2. 声纹识别的原理
人在讲话时使用的发声器官在尺寸和形态方面每个人的差异很大,所以任何两个人的声纹图谱都有差异,主要体现在如下方面:
- 共鸣方式特征:咽腔共鸣、鼻腔共鸣和口腔共鸣
- 嗓音纯度特征:不同人的嗓音,纯度一般是不一样的,粗略地可分为高纯度(明亮)、低纯度(沙哑)和中等纯度三个等级
- 平均音高特征:平均音高的高低就是一般所说的嗓音是高亢还是低沉
- 音域特征:音域的高低就是通常所说的声音饱满还是干瘪
不同人的声音在语谱图中共振峰的分布情况不同,声纹识别正是通过比对两段语音的说话人在相同音素上的发声来判断是否为同一个人,从而实现“闻声识人”的功能。

3. 声纹识别算法的技术指标
声纹识别在算法层面可通过如下基本的技术指标来判断其性能,除此之外还有其它的一些指标,如:信道鲁棒性、时变鲁棒性、假冒攻击鲁棒性、群体普适性等指标,这部分后续于详细展开讲解。
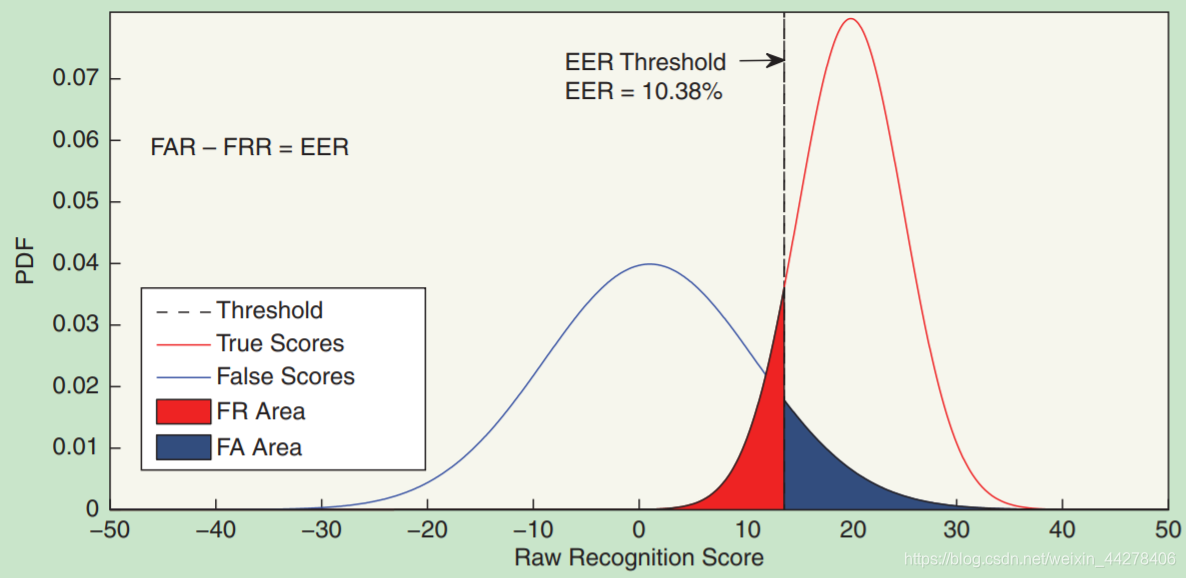
- 错误拒绝率(False Rejection Rate, FRR) :分类问题中,若两个样本为同类(同一个人),却被系统误认为异类(非同一个人),则为错误拒绝案例。错误拒绝率为错误拒绝案例在所有同类匹配案例的比例。
- 错误接受率(False Acceptance Rate, FAR) :分类问题中,若两个样本为异类(非同一个人),却被系统误认为同类(同一个人),则为错误接受案例。错误接受率为错误接受案例在所有异类匹配案例的比例。
- 准确率(Accuracy,ACC):调整阈值,使得FAR+FRR最小,1减去这个值即为识别准确率,即ACC=1 - min(FAR+FRR)
- 速度:(提取速度:提取声纹速度与音频时长有关、验证比对速度):Real Time Factor 实时比(衡量提取时间跟音频时长的关系,比如:1秒能够处理80s的音频,那么实时比就是1:80)。验证比对速度是指平均每秒钟能进行的声纹比对次数。
- ROC曲线:描述FAR与FRR之间相互变化关系的曲线,X轴为FAR的值,Y轴为FRR的值。从左到右,当阈值增长期间,每一个时刻都有一对FAR和FRR的值,将这些值在图上描点连成一条曲线,就是ROC曲线。
- 阈值:在接受/拒绝二元分类系统中,通常会设定一个阈值,分数超过该值时才做出接受决定。调节阈值可以根据业务需求平衡FAR与FRR。 当设定高阈值时,系统做出接受决定的得分要求较为严格,FAR降低,FRR升高;当设定低阈值时,系统做出接受决定的得分要求较为宽松,FAR升高,FRR降低。在不同应用场景下,调整不同的阈值,则可在安全性和方便性间平平衡

4. 影响声纹识别水平的因素
训练数据和算法是影响声纹识别水平的两个重要因素,在应用落地过程中,还会受很多因素的影响。
声源采样率
- 人类语音的频段集中于50Hz ~ 8KHz之间,尤其在4KHz以下频段
- 离散信号覆盖频段为信号采样率的一半(奈奎斯特采样定理)
- 采样率越高,信息量越大
- 常用采样率:8KHz (即0 ~ 4KHz频段),16KHz(即0 ~ 8KHz频段)
信噪比(SNR)
- 信噪比衡量一段音频中语音信号与噪声的能量比,即语音的干净程度
- 15dB以上(基本干净),6dB(嘈杂),0dB(非常吵)
信道
- 不同的采集设备,以及通信过程会引入不同的失真
- 声纹识别算法与模型需要覆盖尽可能多的信道
- 手机麦克风、桌面麦克风、固话、移动通信(CDMA, TD-LTE等)、微信……
语音识别
- 语音时长(包括注册语音条数)会影响声纹识别的精度
- 有效语音时长越长,算法得到的数据越多,精度也会越高
- 短语音(1~3s)
- 长语音(20s+)
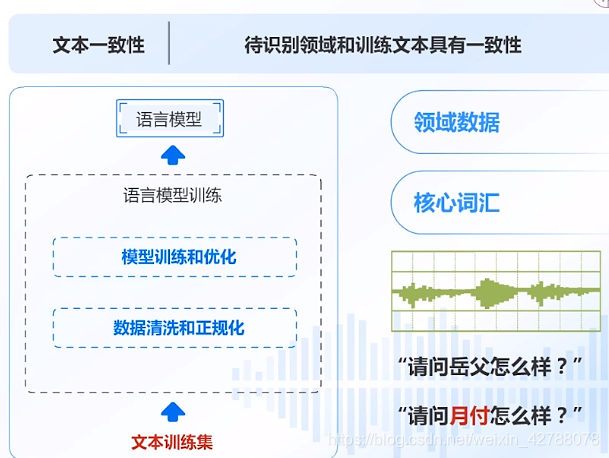
文本内容
- 通俗地说,声纹识别系统通过比对两段语音的说话人在相同音素上的发声来判断是否为同一个人
- 固定文本:注册与验证内容相同
- 半固定文本:内容一样但顺序不同;文本属于固定集合
- 自由文本
5. 声纹识别的应用流程
声纹识别(VPR) ,生物识别技术的一种,也称为说话人识别 ,是从说话人发出的语音信号中提取声纹信息,从应用上看,可分为:
- 说话人辨认(Speaker Identification):用以判断某段语音是若干人中的哪一个所说的,是“多选一”问题;
- 说话人确认(Speaker Verification):用以确认某段语音是否是指定的某个人所说的,是“一对一判别”问题。
声纹识别在应用中分注册和验证两个主流程,根据不同的应用中,部分处理流程会存在差异,一般的声纹识别应用流程如下图所示:

三、语音技术
几大模块及之间的关系:
- 语音唤醒模块 (Wake up)
- 声纹识别模块 (Voice Print)
- 语音识别模块 (ASR)
- 语义理解模块 (NLP)
- 对话管理模块 (DM)
- 语音合成模块 (TTS)

语音识别流程:

ASR评价标准:


语音输入前指标(检查):

语音可能存在丢音,截幅,音量过小
声学匹配

文本匹配
四、声纹识别算法、资源与应用

一、算法
Speaker recognition以2012年为分水岭,由statistics-based machine learning,跨到了以deep learning为主线的算法。随后,bottleneck feature、d-vector、x-vector、j-vector等DNN-based的系统陆续出现,随后attention mechanism、Learning to rank等思想被用于改良训练过程。
对这些算法按照3类分别做简要阐述:
- 1)iVector-based;
- 2)dnn-based;
- 3)基于attention mechanism、Learning to rank等思想的改良算法。

1.1. iVector-based
2011年,第十一届全国人机语音通讯学术会议(NCMMSC2011)上,大神邓力给伙计们开了小灶,分享了他在微软DNN-based speech recognition研究结果(30% relative improvement),群情激奋。就在前一年,ABC(Agnitio/BUT/CRIM)在NIST SRE 2010 workshop上分享了JFA(Joint Factor Analysis,联合因子分析)的改良版(即iVector[1][16]),群情激奋。
iVector中Total Variability的做法(M = m + Tw),将JFA复杂的训练过程以及对语料的复杂要求,瞬间降到了极致,尤其是将Length-Variable Speech映射到了一个fixed- and low-dimension的vector(identity vector,即iVector)上。于是,机器学习爱好者群情激奋,所有机器学习的算法都可以用来解决声纹识别的问题了。
PLDA(Probabilistic Linear Discriminant Analysis,概率形式的LDA[17])是生成型模型(generated model),被用于对iVector进行建模、分类,实验证明其效果最好。PLDA是一种信道补偿算法,因为iVector中,既包含说话人的信息,也包含信道信息,而我们只关心说话人信息,所以才需要做信道补偿。在声纹识别训练过程中,我们假设训练语音由I个说话人的语音组成,其中每个说话人有J段不一样的语音,并且我们定义第i个说话人的第j段语音为Xij。那么,我们定义Xij的生成模型为:
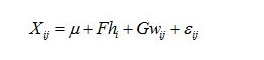
F、G是矩阵,包含了各自假想变量空间中的基本因子,这些因子可以看做是各自空间的基底(basis)。 F的每一列,相当于类间空间的特征向量;G的每一列,相当于类内空间的特征向量。而向量Hi和Wij可以看做是该语音分别在各自空间的特征表示。如果两条语音的hi特征相同的似然度越大,那么它们来自同一个说话人的可能性就越大。
PLDA的模型参数包括4个,mean、F和G、sigma,采用EM算法迭代训练而成。通常,我们采用简化版的PLDA模型,忽略类内特征空间矩阵的训练[18],只训练类间特征空间矩阵F。即:
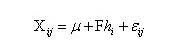
打分过程可以参考文献[17]。
1.2. DNN-based
早期DNN-based Speaker Recognition,用DNN代替GMM去计算Posterior Statistics,延续了DNN-based Speech Recognition的研究成果。2014年,Google提出d-vector[3]后,一系列的DNN-based方法被提出,如x-vector、j-vector等[2][8][9]。下面分别介绍下此类算法的基本思路。
- d-vector
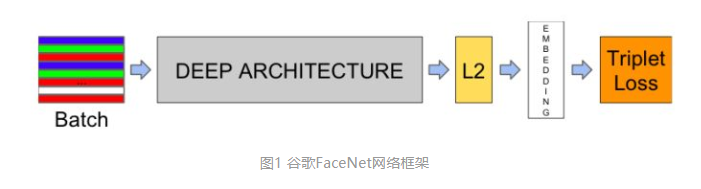
DNN训练好后,提取每一帧语音的Filterbank Energy 特征作为DNN输入,从Last Hidden Layer提取Activations,L2正则化,然后将其累加起来,得到的向量就被称为d-vector。如果一个人有多条Enroll语音,那么所有这些d-vectors做平均,就是这个人的Representation。DNN的网络结构如图1.2所示。

因为d-vector是从Last Hidden Layer提取的,通过移除Softmax Layer,可以缩减Model Size。而且,这也可以让我们在不改变Model Size的情况下,在训练过程中使用更多的说话人数据来做训练(因为Softmax Layer被移除了,不用考虑Softmax Layer的节点数)。DNN的训练过程,可以详细阅读参考文献[3]。 - x-vector
x-vector是Daniel Povey教授在论文[13]中提出的概念,用于描述从TDNN网络中提取的embeddings特征,如图1.3所示。

上面的网络结构中,有一个Statistics Pooling Layer,负责将Frame-level Layer,Map到Segment-Level Layer,计算frame-level Layer的Mean和standard deviation。TDNN是时延架构,Output Layer可以学习到Long-Time特征,所以x-vector可以利用短短的10s左右的语音,捕捉到用户声纹信息,在短语音上拥有更强的鲁棒性。TDNN的训练方式可以参考文献[13]。
提取x-vector,LDA降维,然后以PLDA作为back-end,便可以做Verification。
开源代码:https://github.com/kaldi-asr/kaldi/tree/master/egs/sre16/v2
- j-vector
提取i-vector依赖于较长(数十秒到数分钟)的语音,而Text-Dependent Speaker Verification任务中,语音很短(甚至只有1秒左右),所以i-vector不适用于Text-Dependent Speaker Verification。Text-Dependent Speaker Verification属于Multi-task,既要验证身份,又要验证语音内容。j-vector[8]就是为了解决Text-Dependent Speaker Verification而提出的,如图1.4所示,j-vector从Last Hidden Layer提取。
论文[8]中指出,相比于Cosine Similarity、Joint PLDA,使用Joint Gaussian Discriminant Function作为back-end时,实验效果最佳。

[1] Niko Brümmer, Doris Baum, Patrick Kenny, et al., “ABC System description for NIST SRE 2010”, NIST SRE 2010.
[2] David Snyder, Pegah Ghahremani, Daniel Povey, “Deep Neural Network-based Speaker Embeddings for END-TO-END Speaker Verification”, Spoken Language Technology Workshop , 2017 :165-170.
[3] Variani, Ehsan, et al. “Deep neural networks for small footprint text-dependent speaker verification.” Acoustics, Speech and Signal Processing (ICASSP), 2014 IEEE International Conference on. IEEE, 2014.
[4] Liu, Yuan, et al., “Deep feature for text-dependent speaker verification.” Speech Communication 73 (2015): 1-13.
[5] Heigold, Georg, et al., “End-to-end text-dependent speaker verification.” Acoustics, Speech and Signal Processing (ICASSP), 2016 IEEE International Conference on. IEEE, 2016.
[6] Zhang Chunlei, and Kazuhito Koishida. “End-to-End Text-Independent Speaker Verification with Triplet Loss on Short Utterances.” Proc. InterSpeech 2017 (2017): 1487-1491.
[7] Li Chao, et al., “Deep Speaker: an End-to-End Neural Speaker Embedding System.” arXiv preprint arXiv:1705.02304 (2017).
[8] Nanxin Chen, Yanmin Qian, and Kai Yu, “Multi-task learning for text-dependent speaker verificaion,” in INTERSPEECH, 2015.
[9] Ziqiang Shi, Mengjiao Wang, Liu Liu, et al., “A DOUBLE JOINT BAYESIAN APPROACH FOR J-VECTOR BASED TEXT-DEPENDENT SPEAKER VERIFICATION”,
[10] FARR Chowdhury,Q Wang, IL Moreno, L Wan“Attention-Based Models for Text-Dependent Speaker Verification”, Submitted to ICASSP 2018.
[11] C Zhang, K Koishida, “End-to-End Text-Independent Speaker Verification with Triplet Loss on Short Utterances”, Interspeech, 2017.
[12] Arsha Nagrani, “VoxCeleb: a large-scale speaker identification dataset”
[13] D Snyder, D Garcia-Romero, D Povey, S Khudanpur, “Deep Neural Network Embeddings for Text-Independent Speaker Verification”, Interspeech , 2017 :999-1003.
[14] T. Fu, Y. Qian, Y. Liu, and K. Yu, “Tandem deep features for textdependent speaker verification”, Proc. InterSpeech, 2014.
[15] Hervé Bredin, “TristouNet: Triplet Loss for Speaker Turn Embedding”, ICASSP 2017.
[16] Najim Dehak, Reda Dehak, et al., “Support Vector Machines versus Fast Scoring in the Low-Dimensional Total Variability Space for Speaker Verification”, InterSpeech, 2009.
[17] SJD Prince, JH Elder, “Probabilistic Linear Discriminant Analysis for Inferences About Identity”, Proceedings, 2007 :1-8.
[18] Y Jiang, AL Kong, L Wang, “PLDA in the i-supervector space for text-independent speaker verification”, Hindawi Publishing Corp. , 2014 , 2014 (1) :29.
二、资源
1. Kaldi
最流行的语音技术研究平台,没有之一。代码运行鲁棒性强、架构良好,便于算法修改、定制。
- 如果你是高校科研人员,工程实现能力有限,那么没关系,你只要懂点Shell、Python或Perl脚本,即可顺利开展实验。
- 如果你是工业界人士,完全可直接拿来商用,KALDI遵循Apache licence。
- 如果你是自由开发者,完全可以基于KALDI做一些开发,为企业提供语音服务。
源码地址:https://github.com/kaldi-asr/kaldi
语料集合:http://cn-mirror.openslr.org/

2. TensorFlow-based Deep Speaker
实现ResNet网络上的TE2E(Tuple-base end-to-end)Loss function训练方式。安装TensorFlow、Python3和FFMPEG(文件格式转换工具)后,准备好数据,即可一键训练。只可惜验证部分还没做,而且GRU没实现、tensor实现部分也不严谨,可详细阅读代码和论文,并贡献下您的代码。
源码地址:https://github.com/philipperemy/deep-speaker
论文地址:https://link.zhihu.com/?target=https%3A//arxiv.org/pdf/1705.02304.pdf
数据集合:http://www.robots.ox.ac.uk/~vgg/data/voxceleb/
3. PyTorch-based Deep Speaker
基于百度论文[1],实现了ResNet + Triplet Loss。不过在 牛津大学的Voxceleb库上,EER比论文[2]所宣称的(7.8%)要高不少,看来实现还是有改进空间。Owner在求助了,大家帮帮忙contribute。
源码地址:https://github.com/qqueing/DeepSpeaker-pytorch
论文地址:https://arxiv.org/pdf/1705.02304.pdf
4. TristouNet from pyannote-audio
一个音频处理工具箱,包括Speech change detection, feature extraction, speaker embeddings extraction以及speech activity detection。其中speaker embeddings extraction部分,包括TristouNet的实现。
源码地址:https://github.com/pyannote/pyannote-audio
论文地址:https://arxiv.org/pdf/1609.04301.pdf
5. CNN-based Speaker verification5. CNN-based Speaker verification
Convolutional Neural Networks(卷积神经网络)在声纹识别上的试验,一个不错的尝试,可以与TDNN/x-vector做下对比。
源码地址:https://github.com/astorfi/3D-convolutional-speaker-recognition
论文地址:https://arxiv.org/pdf/1705.09422.pdf
数据集合:https://biic.wvu.edu/data-sets/multimodal-dataset
三、Triplet Loss
2015年,谷歌的FaceNet[4]使用Triplet Loss在大规模人脸识别中取得了很大的成功。受此启发,在声纹识别领域,也有不少的文章使用Triplet loss,比如Zhang[3]、Baidu Deep Speaker[5]、Bredin[6]等 。它的优点是,直接使用embeddings之间的相似度作为优化的成本函数(Loss Function),最大化【anchor】和【positive】的相似度,同时最小化【anchor】和【negative】的相似度。这样,在提取了说话者的embedding之后,声纹验证和声纹识别任务就可以简单地通过相似度计算实现。
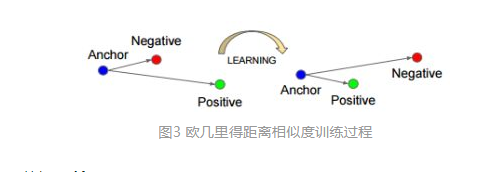
Triplet Loss基本思路是:构造一个三元组,由anchor(锚,可以理解为一个参考语音)、positive(相对anchor而言)和negative(相对anchor而言)组成。然后,用大量标注好的三元组作为网络输入,来学习DNN参数。其中,anchor和positive是来自于同一个人的不同声音,anchor和negative是来自不同的人的声音。通过DNN获取各自的embeddings后,计算anchor和positive的相似度,以及anchor和negative的相似度,然后最大化ap(anchor与positive)的相似度,最小化an(anchor与negative)的相似度。
计算相似度有两种方法,一种是cosine相似度,值越大,相似度越高,正如Baidu Deep Speaker所采用的;一种是使用欧几里得距离,和FaceNet所使用的一样,值越小,相似度越高。
cosine相似度的训练过程如图2所示:

其成本函数如下所示:
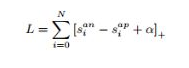
欧几里得距离相似度的训练过程如图3所示:
其成本函数如下所示:
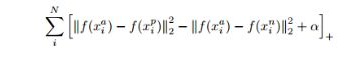
四、改良算法篇之GE2E Loss
End-to-End Speaker Recognition往往是data-driven的,需要海量标注数据才能取得预期效果。无论是Google d-vector,还是x-vector、Baidu Deep Speaker,其训练速度和有效利用data的程度,仍然有较大改进空间,文献[1], [2], [3]就是朝着这些方向所做的尝试。
GE2E Loss
Generalized end-to-end (GE2E) loss是谷歌在论文[4]中提出的新损失函数,还是比较有创意的。与TE2E loss和Triplet loss相比,它每次更新都和多个人相比,因此号称能使训练时间更短,说话人验证精度更高。
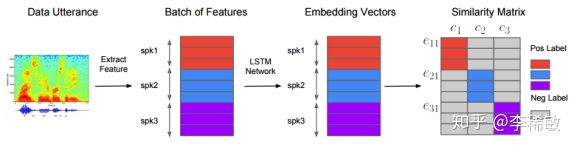
其基本思路如图1所示,挑选 N 个人,每人M句话,通过图示的顺序排列组成Batch,接着通过LSTM神经网络提取N*M句话的embeddings,然后求取每个embedding和每个人平均embedding的相似度,得到一个相似度矩阵。最后通过最小化GE2E loss使得相似矩阵中有颜色的相似度尽可能大,灰色的相似度尽可能小,即本人的embedding应该和本人每句话的embedding尽可能相近,和其他人的embedding尽可能远离,从而训练LSTM网络。

相似度矩阵的定义如下公式所示:
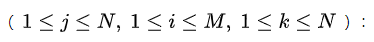
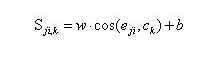
其eij中表示第人第句话对应的embedding,w和b是要训练的参数(约束 w>0 ), Ck是第 k 人的embedding,由M句话的embeddings求平均得到,即:
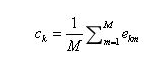
为了使得相似度矩阵中有颜色的相似度尽可能大,灰色的相似度尽可能小,有两种损失函数,第一种是softmax loss,即:
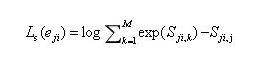
或者写成
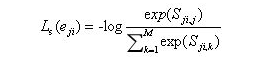
上式中(和论文不一样,本人认为应该加个负号),最小化损失函数 Ls(eji) , Sji,j就要尽可能大,即优化使得本人和本人的每一句话都比较相似。
 上式中,最小化损失函数,](https://img-blog.csdnimg.cn/20191121154524954.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80Mjc4ODA3OA==,size_16,color_FFFFFF,t_70)
五 参考文章+学习资源:
小白声纹识别(说话人识别)探索
声纹识别的应用实践
AI老司机带你认识声音黑科技:声纹识别
百度语音识别视频两节
知乎声纹识别大佬Leon晋
声纹识别训练营1+声纹识别训练营2
论文:
- d-vector
《Deep Neural Network Embeddings for Text-Independent Speaker Verification》
《ROBUST DNN EMBEDDINGS FOR SPEAKER RECOGNITION》 - 端到端系统 Deep Speaker
《Deep Speaker: an End-to-End Neural Speaker Embedding System》
d-vector:
https://github.com/rajathkmp/speaker-verification
https://github.com/wangleiai/dVectorSpeakerRecognition
E2E,Deep Speaker:
tensorflow版本
pytorch版本