声纹识别的发展综述
- 综述
- 声纹概念与用于识别的优势
- 声纹识别工作方式
- 声纹识别三大部分:特征,模型,得分
- 语音特征介绍
- 声纹模型的演进
- 基于深度学习的声纹技术
- 其他语音技术介绍
综述
声纹概念与用于识别的优势
声纹的概念:声音就是一段波,声纹就是携带了信息的声波频谱。
为什么可以用于识别?
- 声纹不仅具有特定性,而且有相对稳定性的特点。成年以后,人的声音可保持长期相对稳定不变,因此,它同指纹一样,独特的生物学特征,可用于身份识别。

- 声纹特征对比其他生物学特征更有优势。

声纹识别工作方式
声纹识别在产品上的本质主要就是以下两种工作方式: 1比1 和 1比N

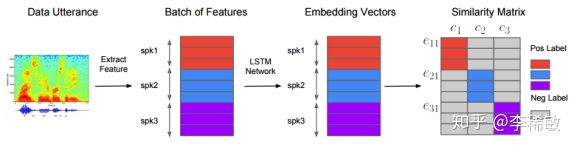
工作流程大致如下:
- 提取语音,预处理,提取特征
- 利用训练好的模型,计算该语音对应的声纹模型或者声纹特征
- 最后进行相似度打分,得到结果

由此我们可以看出声纹识别主要就是三大部分:特征,模型,得分。下面根据这三大要素分别阐述
声纹识别三大部分:特征,模型,得分
首先看下这三大部分的整体技术流派和技术发展路线

语音特征介绍




声纹模型的演进
传统的声纹识别 主要是基于统计思想和概率论,结合声学,信号学,机器学习等算法
2012年,跨入了以deep learning 为主线的算法,DNN-based系统陆续出现,并基于深度学习领域的新思想持续改良
近两年发展起来的End-to-End 端到端系统,代表:2018年谷歌百度的相关论文







基于深度学习的声纹技术



上面的网络结构中,有一个Statistics Pooling Layer,负责将Frame-level Layer,Map到Segment-Level Layer,计算frame-level Layer的Mean和standard deviation。TDNN是时延架构,Output Layer可以学习到Long-Time特征,所以x-vector可以利用短短的10s左右的语音,捕捉到用户声纹信息,在短语音上拥有更强的鲁棒性。

其他语音技术介绍


摘自知乎“巧克力工厂的查理”,用作学习总结。