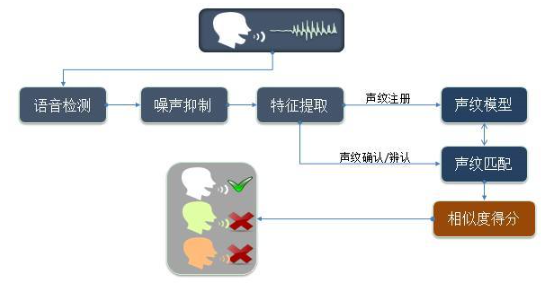
说话人识别(Speaker Recognition,SR),又称声纹识别(Voiceprint Recognition,VPR),顾名思义,即通过声音来识别出来“谁在说话”,是根据语音信号中的说话人个性信息来识别说话人身份的一项生物特征识别技术。便于比较,语音识别(Automatic Speech Recognition,ASR)是通过声音识别出来“在说什么”。为了简便,后文统一称为VPR。
传统的VPR系统多是采用MFCC特征以及GMM模型框架,效果相当不错。后续也出现了基于i-vector,深度神经网络的等更多的算法框架。
【持续更新……】
基础
声纹识别的理论基础是每一个声音都具有独特的特征,通过该特征能将不同人的声音进行有效的区分。
这种独特的特征主要由两个因素决定,第一个是声腔的尺寸,具体包括咽喉、鼻腔和口腔等,这些器官的形状、尺寸和位置决定了声带张力的大小和声音频率的范围。因此不同的人虽然说同样的话,但是声音的频率分布是不同的,听起来有的低沉有的洪亮。每个人的发声腔都是不同的,就像指纹一样,每个人的声音也就有独特的特征。
第二个决定声音特征的因素是发声器官被操纵的方式,发声器官包括唇、齿、舌、软腭及腭肌肉等,他们之间相互作用就会产生清晰的语音。而他们之间的协作方式是人通过后天与周围人的交流中随机学习到的。人在学习说话的过程中,通过模拟周围不同人的说话方式,就会逐渐形成自己的声纹特征。
因此,理论上来说,声纹就像指纹一样,很少会有两个人具有相同的声纹特征。
美国研究机构已经表明在某些特点的环境下声纹可以用来作为有效的证据。并且美国联邦调查局对2000例与声纹相关的案件进行统计,利用声纹作为证据只有0.31%的错误率。目前利用声纹来区分不同人这项技术已经被广泛认可,并且在各个领域中都有应用。
目前来看,声纹识别常用的方法包括模板匹配法、最近邻方法、神经元网络方法,VQ聚类法等。
语谱图是声音信号的一种图像化的表示方式,它的横轴代表时间,纵轴代表频率,语音在各个频率点的幅值大小用颜色来区分。说话人的声音的基频及谐频在语谱图上表现为一条一条的亮线,再通过不同的处理手段就可以得到不同语谱图之间的相似度,最终达到声纹识别的目的。
目前公安部声纹鉴别就采用类似方法,而且语谱图还是用的灰度来表示。主要抽取说话人声音的基音频谱及包络、基音帧的能量、基音共振峰的出现频率及其轨迹等参数表征,然后再与模式识别等传统匹配方法结合进行声纹识别。
美国和国内都有不少企业生产声纹识别的设备,公安部为采购这些设备还正式颁布了《安防声纹识别应用系统技术要求》的行业标准。
但是这种方法是一种静态检测的方法,存在很大的弊端,实时性不好,动态检测声纹的需求实际上更大。
经过数十年的研究,说话人识别系统取得了不俗的性能表现,现已被广泛应用于包括安防、金融、社保等不同领域中。然而,受各种不确定性因素的制约,当前说话人识别系统仍难言可靠!这些不确定性因素包括非限定的自由文本、各种各样的传输信道、复杂多变的背景噪音、说话人自身的生理波动等等。这些不确定性因素对说话人识别系统提出了巨大的挑战。
原理特性
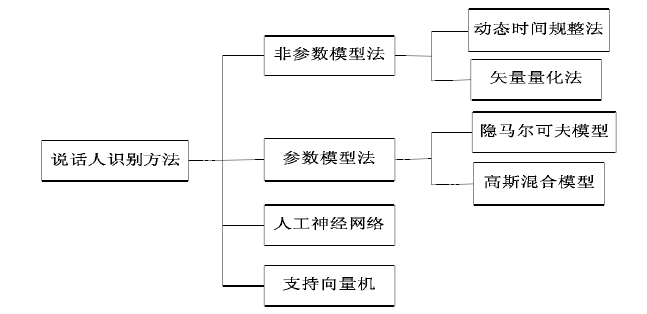
典型的声纹识别模型可以分为两种:template model和 stochastic model,即模板模型和随机模型。也称作非参数模型和参数模型。
模板模型(非参数模型)将训练特征参数和测试的特征参数进行比较,两者之间的失真(distortion)作为相似度。例如VQ(Vector quantization矢量量化)模型和动态时间规整法DTW(dynamic time warping)模型。
DTW 通过将输入待识别的特征矢量序列与训练时提取的特征矢量进行比较,通过最优路径匹配的方法来进行识别。而 VQ 方法则是通过聚类、量化的方法生成码本,识别时对测试数据进行量化编码,以失真度的大小作为判决的标准。
随机模型(参数模型)用一个概率密度函数来模拟说话人,训练过程用于预测概率密度函数的参数,匹配过程通过计算相应模型的测试语句的相似度来完成。(参数模型采用某种概率密度函数来描述说话人的语音特征空间的分布情况,并以该概率密度函数的一组参数作为说话人的模型。)例如(GMM和HMM)高斯混合模型和隐马尔科夫模型。

模型和特征
参考:声纹识别算法、资源与应用(一) - 知乎 (zhihu.com)
Speaker recognition以2012年为分水岭,由statistics-based machine learning,跨到了以deep learning为主线的算法。随后,bottleneck feature、d-vector、x-vector、j-vector等DNN-based的系统陆续出现,随后attention mechanism、Learning to rank等思想被用于改良训练过程。
End-to-End Speaker Recognition往往是data-driven的,需要海量marked data才能取得预期效果。无论是Google d-vector,还是Daniel x-vector、Baidu Deep Speaker,其迭代速度和有效利用data的程度,仍然有较大改进空间。
概述
参考:清微智能SRE19大赛两项全球前十 算法团队技术分享
从1995年开始,混合高斯模型的统计模式识别技术被引入说话人识别,2000年Reynolds提出的GMM-UBM模型成为声纹识别领域最重要的基石。2008年kenny提出联合因子分析(JFA)将GMM均值超矢量空间划分为本征空间,信道空间,残差空间,分别对说话人和信道空间建模。由于JFA进行信道补偿时不可避免的包含说话人信息,并且存在空间掩盖和空间重叠的问题,因此不能对说话人和信道进行准确建模和区分,于是在2010年Najim Dehak等人提出使用全局差异空间代替本征空间和信道空间,即I-vector对说话人进行建模。随着数据和计算资源的丰富,基于深度学习的声纹识别带来了性能的进一步提升。2018年X-vector在D-vector的基础进行改进,通过在帧级特征上池化映射获得可以表示说话人特性的段级向量,成为state-of-the-art的框架。基于X-vector说话人建模的声纹识别系统主要包括语音特征提取,说话人建模和后端分类器进行信道补偿及似然度打分三个部分。
GMM-UBM
部分参考:闻声识人——声纹识别技术简介
高斯混合模型仍然是与文本无关的说话人识别中效果最好也是最常用的模型之一,因为在说话人识别系统中,如何将语音特征很好地进行总结及测试语音如何与训练语音进行匹配都是非常复杂难解决的问题,而GMM将这些问题转为对于模型的操作及概率计算等问题,解决了这些问题。
高斯混合模型可以逼近任何一个连续的概率分布,因此它可以看做是连续型概率分布的万能逼近器。之所有要保证权重的和为1,是因为概率密度函数必须满足(+∞,-∞)在内的积分值为1。
从模式识别的相关定义上来说,GMM是一种参数化(Parameterized)的生成性模型(Generative Model),具备对实际数据极强的表征力;但反过来,GMM规模越庞大,表征力越强,其负面效应也会越明显:参数规模也会等比例的膨胀,需要更多的数据来驱动GMM的参数训练才能得到一个更加通用(或称泛化)的GMM模型。虽然GMM在小规模的文本无关数据集合上表现出了超越传统技术框架的性能,但它却远远无法满足实际场景下的需求。
虽然GMM模型作为一种通用的概率模型,对说话人识别的效果很好,但是实际上,我们经常会遇到训练语音比较短、或者语料比较少的情况,这样就不能训练出好的GMM模型,从而使识别率变低。所以2000年前后,在GMM模型的基础上,Reynolds等人提出了高斯混合模型-全局背景模型(GMM-UBM):既然没法从目标用户那里收集到足够的语音,那就换一种思路,可以从其他地方收集到大量非目标用户的声音,积少成多,我们将这些非目标用户数据(声纹识别领域称为背景数据)混合起来充分训练出一个GMM,这个GMM可以看作是对语音的表征,但是又由于它是从大量身份的混杂数据中训练而成,它又不具备表征具体身份的能力。
通用背景模型(Universal Background Model,UBM),可以看作是某一个具体说话人模型的先验模型。UBM的一个重要的优势在于它是通过最大后验估计(Maximum A Posterior,MAP)的算法对模型参数进行估计,避免了过拟合的发生。MAP算法的另外一个优势是我们不必再去调整目标用户GMM的所有参数(权重,均值,方差)只需要对各个高斯成分的均值参数进行估计,就能实现最好的识别性能。 这下子待估的参数一下子减少了一半还多,越少的参数也意味着更快的收敛,不需要那么多的目标用户数据即可模型的良好训练。
而GMM-UBM系统利用大量的说话人语音训练出一个全局背景模型(UBM),因此在较小的训练集情况下仍然可获得较为精确的模型,识别性能及鲁棒性都很好。
所谓全局背景模型,就是采用许多人的语音,包括所有目标的语音一起训练而成的一个高阶通过利用UBM模型,由于训练语音有限而不能覆盖到的所有说话人特征的部分就可以通过UBM来自适应得到。UBM模型就是一个大型的GMM模型,所以UBM模型也可以利用EM算法来训练,并且UBM模型只需要训练一次,在后面便可反复利用。在训练过程中,通过MAP自适应,可得到毎个说话人的GMM模型。加入UBM后的系统流程如下图所示。
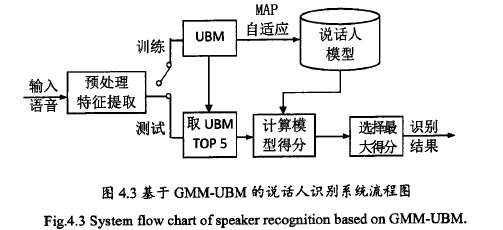
在计算每个说话人的声纹模型时,我们采用最大后验概率MAP算法。
实验表明,在其他参数都相同的条件下,采用GMM-UBM模型进行识别的结果要优于普通的GMM模型,并且在实验过程中还可发现,虽然训练UBM模型较为费时但自适应时却非常迅速,总体时间比依次训练GMM模型所花费的时间要少。
GMM模型是一个有监督的训练过程。它的基本思想就是利用已知的样本结果来反推最有可能(也就是最大概率)导致该个结果的参数值,在这个原则之下,GMM通常采用最大期望算法(EM)模型进行迭代直到收敛来确定参数。
对于高斯混合模型,也可以使用最大似然估计确定模型的参数,但每个样本属于哪个高斯分布是未知的,而计算高斯分布的参数时需要用到这个信息;反过来,样本属于哪个高斯分布又是由高斯分布的参数确定的。因此存在循环依赖,解决此问题的办法是打破此循环依赖,从高斯分布的一个不准确的初始猜测值开始,计算样本属于每个高斯分布的概率,然后又根据这个概率更新每个高斯分布的参数。这就是EM算法求解时的做法。
EM算法是一种迭代算法,因为现实的数据经常会有一些含有隐变量或者数据不完整等问题,很难求出极大似然函数,所以利用EM法来解决。
CMN / CMVN / VTLN
cepstrum mean normalization (CMN) ,倒谱均值归一化,说话人特征归一化方法的一种。顾名思义。
CMVN,倒谱平均值和方差归一化,包括对原始cepstra的平均值和方差进行归一化,通常以发音(utterance)或每个说话人为基础,给出零均值,单位方差的cepstra。
vocal tract length normalization (VTLN),声道长度归一化,声道中的共振峰位置大体上是按照说话人的声道长度单调的变化的,所以VTLN通过引入扭曲因子来实现声道长度归一化。
i-vector
| i-vector 的前世今生 |
| 在MAP框架下,我们都是单独去调整GMM的每一个高斯分量,参数太多太累了,那有没有办法同时调整一串高斯分量呢?希望借助因子分析(Factor Analysis,FA)的算法框架的降维思想。 加拿大蒙特利尔研究所(Computer Research Institute of Montreal,CRIM)的科学家兼公式推导帝Patrick Kenny在2005年左右提出了一个设想,既然声纹信息可以用一个低秩的超向量子空间来表示,那噪声和其他信道效应是不是也能用一个不相关的超向量子空间进行表达呢? 基于这个假设,Kenny提出了联合因子分析(Joint Factor Analysis,JFA)的理论分析框架,将说话人所处的空间和信道所处的空间做了独立不相关的假设,在JFA的假设下,与声纹相关的信息全部可以由特征音空间(Eigenvoice)进行表达,并且同一个说话人的多段语音在这个特征音空间上都能得到相同的参数映射,之所以实际的GMM模型参数有差异,都是由特征信道(Eigenchannel),即信道效应的干扰导致的,我们只需要同时估计出一段语音在特征音空间上的映射和特征信道上的映射,然后去除特征信道上的干扰就可以实现更好的声纹环境鲁棒性。 现实世界中,尽管任何数据都存在冗余,即数据之间都具有相关性,但绝对的独立同分布的假设又是一个过于强的假设,这种独立同分布的假设往往为数学的推导提供了便利,但却限制了模型的泛化能力。 2009年,Kenny的学生,N.Dehak,提出了一个更加宽松的假设:既然声纹信息与信道信息不能做到完全独立,那干脆就用一个超向量子空间对两种信息同时建模;正交独立性没有办法满足,那干脆用一个子空间同时描述说话人信息和信道信息如何? 这时候,同一个说话人,不管怎么采集语音,采集了多少段语音,在这个子空间上的映射坐标都会有差异,这也更符合实际的情况。这个既模拟说话人差异性又模拟信道差异性的空间称为全因子空间(Total Factor Matrix),每段语音在这个空间上的映射坐标称作身份向量(Identity Vector,i-vector),i-vector向量通常维度不会太高,一般在400-600左右。 i-vector的出现使得说话人识别的研究一下子简化抽象为了一个数值分析与数据分析的问题:任意的一段音频,不管长度怎样,内容如何,最后都会被映射为一段低维度的定长i-vector。 只需要找到一些优化手段与测量方法,在海量数据中能够将同一个说话人的几段i-vector尽可能分类得近一些,将不同说话人的i-vector尽可能分得远一些。 并且Dehak在实验中还发现i-vector具有良好的空间方向区分性,即便上SVM做区分,也只需要选择一个简单的余弦核就能实现非常好的区分性。 不久之前,i-vector在大多数情况下仍然是文本无关声纹识别中表现性能最好的建模框架,学者们后续的改进都是基于对i-vector进行优化,包括线性区分分析(Linear Discriminant Analysis, LDA),基于概率的线性预测区分分析(probabilistic linear discriminant analysis,PLDA)甚至是度量学习(Metric Learning)等。 |
| 推荐阅读:Kenny, Patrick. "Joint factor analysis of speaker and session variability: Theory and algorithms." CRIM, Montreal,(Report) CRIM-06/08-13 (2005). |
传统的联合因子分析建模过程主要是基于两个不同的空间:由本征音空间矩阵定义的说话人空间,由本征信道空间矩阵定义的信道空间。受联合因子分析理论的启发, Dehak提出了从GMM均值超矢量中提取一个更紧凑的矢量,称为i-vector。这里的i是身份(Identity)的意思,出于自然的理解,i-vector相当于说话人的身份标识。
i-vector方法采用一个空间来代替这两个空间,这个新的空间可以成为全局差异空间,它即包含了说话者之间的差异又包含了信道间的差异。所以i-vector的建模过程在GMM均值超矢量中不严格区分话者的影响和信道的影响。这一建模方法的动机来源于Dehak的又一研究: JFA建模后的信道因子不仅包含了信道效应也夹杂着说话人的信息。
现在,主要用的特征是i-vector。这是通过高斯超向量基于因子分析而得到的。是基于单一空间的跨信道算法,该空间既包含了说话人空间的信息也包含了信道空间信息。相当于用因子分析方法将语音从高位空间投影到低维。
可以把i-vector看做是一种特征,也可以看做是简单的模型。最后,在测试阶段,我们只要计算测试语音i-vector和模型的i-vector之间的consine距离,就可以作为最后的得分。这种方法也通常被作为基于i-vector说话人识别系统的基线系统。
因为i-vector简洁的背后是它舍弃了太多的东西,其中就包括了文本差异性,在文本无关识别中,因为注册和训练的语音在内容上的差异性比较大,因此我们需要抑制这种差异性。但在文本相关识别中,我们又需要放大训练和识别语音在内容上的相似性,这时候牵一发而动全身的i-vector就显得不是那么合适了。虽然i-vector在文本无关声纹识别上表现非常好,但在看似更简单的文本相关声纹识别任务上,i-vector表现得却并不比传统的GMM-UBM框架更好。
在文本相关识别应用中,安全性最高的仍然是随机数字串声纹识别。
TVM-i-vector
i-vector的建模方式称为全局差异空间建模(Total Variability Modeling, TVM),采用该方法提取的i-vector记为TVM-i-vector。

在基于TVM-i-vector的声纹识别系统中,我们一般可以分为三个步骤。第一步是统计量的提取,第二步是提取i-vector,第三步是进行信道补偿技术。统计量的提取是指将语音数据的特征序列,比如MFCC特征序列,用统计量来进行描述,提取的统计量属于高维特征,然后经过TVM建模,投影至低维空间中得到i-vector。
在TVM-i-vector建模中,统计量的提取是以UBM为基础的,根据UBM的均值及方差进行相应统计量的计算。
基于DNN的说话人识别的基本思想是取代TVM中的UBM产生帧级后验概率。即采用DNN进行帧级对齐的工作,继而计算训练数据的统计量,进行全局差异空间的训练以及i-vector的提取。
最近使用神经网络来进行声纹识别的论文已经改进了传统的i-vector方法(参考Interspeech教程的原始论文或者幻灯片)。i-vector方法认为说话内容可以被分为两个部分,一个部分依赖于说话者和信道可变性,另一个部分依赖于其它的相关因素。i-vector声纹识别是一个多步过程,其涉及到使用不同说话者的数据来估计一个通用的背景模型(通常是高斯混合模型),收集充分的统计数据,提取i-vector,最后使用一个分类器来进行识别任务。
一些论文用神经网络代替了i-vector流水线的方法。其它研究者要么训练了一个文本相关(使用者必须说同样的话)的端对端语者识别系统,要么训练了文本独立(这个模型与说话内容不相关)的端对端语者识别系统。
目前没有详细证据证明深度神经网络或组合i-vector的深度神经网络性能一定优于i-vector方法,可能原因是说话人识别中信道干扰较多,难以搜集足够数据训练深度神经网络。
j-vector [文本相关]
提取i-vector依赖于较长(数十秒到数分钟)的语音,而Text-Dependent Speaker Verification任务中,语音很短(甚至只有1秒左右),所以i-vector不适用于Text-Dependent Speaker Verification。Text-Dependent Speaker Verification属于Multi-task,既要验证身份,又要验证语音内容。j-vector就是为了解决Text-Dependent Speaker Verification而提出的,如图所示,j-vector从Last Hidden Layer提取。由INTERSPEECH 2015文章《Multi-task learning for text-dependent speaker verificaion》提出。
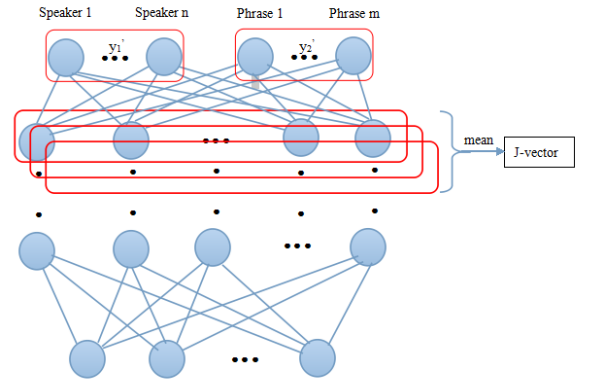
论文中指出,相比于Cosine Similarity、Joint PLDA,使用Joint Gaussian Discriminant Function作为back-end时,实验效果最佳。
d-vector
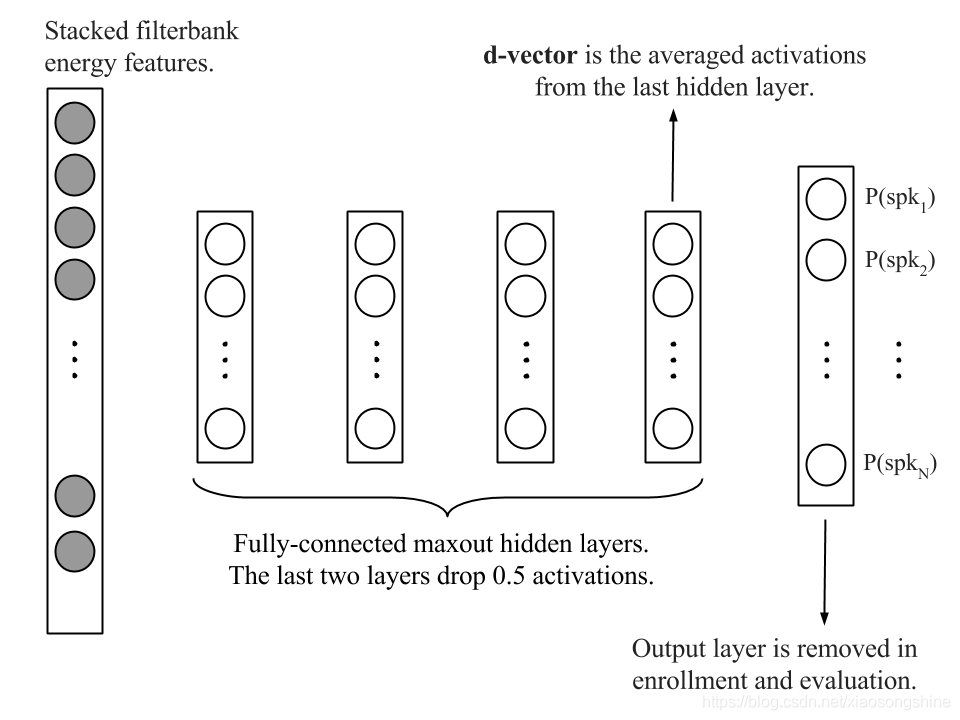
ICASSP 2014年的论文《Deep neural networks for small footprint text-dependent speaker verification 》研究了深度神经网络(DNNs)在小型文本相关的说话者验证任务的应用。
在开发阶段,DNN经过训练,可以在帧级别对说话人进行分类。在说话人录入阶段,使用训练好的的DNN用于提取来自最后隐藏层的语音特征。这些说话人特征或平均值,即d-vector,用作说话人特征模型。在评估阶段,为每个话语提取d-vector与录入的说话人模型相比较,进行验证。实验结果表明基于DNN的说话人验证与常用的i-vector相比,系统在一个小的声音文本相关的说话人验证任务实现了良好的性能表现。
深度网络的特征提取层(隐藏层)输出帧级别的说话人特征,将其以合并平均的方式得到句子级别的表示,这种utterance-level的表示即深度说话人向量,简称d-vector。计算两个d-vectors之间的余弦距离,得到判决打分。类似主流的概率统计模型i-vector,可以通过引入一些正则化方法 (线性判别分析 LDA、概率线性判别分析 PLDA等),以提高 d-vector 的说话人区分性。
此外,基于DNN的系统对添加的噪声更加稳健,并且在低错误拒绝操作点上优于i-vector系统。最后,组合系统在进行安静和嘈杂的条件分别优于i-vector系统以14%和25%的相对错误率(EER)。
参考:[论文品读]·d-vector解读(Deep Neural Networks for Small Footprint Text-Dependent Speaker Verification)。
 【SV背景DNN模型】【非CNN】【监督学习】
【SV背景DNN模型】【非CNN】【监督学习】
简而言之,DNN训练好后,提取每一帧语音的Filterbank Energy 特征作为DNN输入,从Last Hidden Layer提取Activations,L2正则化(对于两个向量的l2-norm进行点积,就可以得到这两个向量的余弦相似性),然后将其累加起来,得到的向量就被称为d-vector。如果一个人有多条Enroll语音,那么所有这些d-vectors做平均,就是这个人的Representation。
因为d-vector是从Last Hidden Layer提取的,通过移除Softmax Layer,可以缩减Model Size。这也可以在不改变Model Size的情况下,在训练过程中使用更多的说话人数据来做训练(因为Softmax Layer被移除了,不用考虑Softmax Layer的节点数)。
x-vector
参考论文《X-VECTORS: ROBUST DNN EMBEDDINGS FOR SPEAKER RECOGNITION》【ICASSP 2018】
x-vector的训练速度很快,识别率高。
文章使用数据增广来提高深度神经网络(DNN)embedding对于说话人识别的性能。经过训练以区分说话者的DNN将可变长度的语料映射到我们称为x-vector的固定维度embedding。
采用PLDA比较pairs of embeddings。【PLDA(Probabilistic Linear Discriminant Analysis)是一种信道补偿算法,号称概率形式的LDA算法,PLDA算法的信道补偿能力比LDA更好,已经成为目前最好的信道补偿算法。】
关于PLDA参考:【声纹识别之PLDA算法描述】以及【Kaldi说话人识别:基于x-vector 的plda自适应】
得益于其网络中的statistics pooling层,X-VECTORS可接受任意长度的输入,转化为固定长度的特征表达;此外,在训练中引入了包含噪声和混响在内的数据增强策略,使得模型对于噪声和混响等干扰更加鲁棒。
之前的研究发现,embedding比i-vector更好地利用大规模训练数据集。然而,收集大量用于训练的标记数据可能具有挑战性,因此使用数据增广,包括增加噪声和混响,作为一种廉价的方法来增加训练数据的数量并提高鲁棒性。
将x-vector与wild和NIST SRE 2016 Cantonese中的i-vector基线进行比较。我们发现虽然增强在PLDA分类器中是有益的,但它对于i-vector提取器没有帮助。然而,由于其受监督的训练,x-vector DNN有效地利用了数据增加。因此,x-vector在评估数据集上实现了卓越的性能。
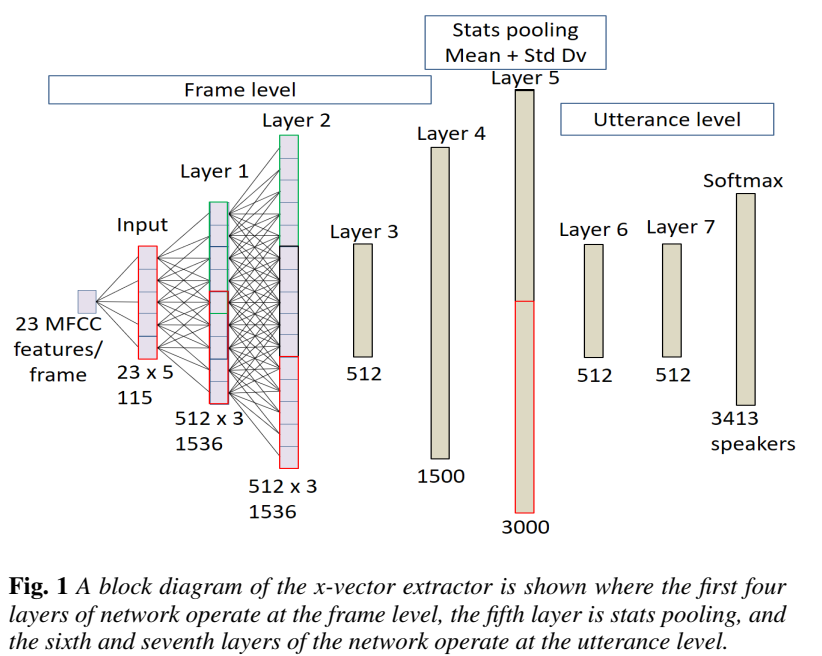
下图中的左图为X-vector的网络结构,前5层是帧级别,然后做了池化后插入两层段级别的embedding,使用segment6这层作为提取x-vector特征,该特征可以当做i-vector进行plda打分,最后一层是softmax层对于训练集中所有的说话人目标。比起BNF特征提取要容易的多,BNF需要训练基于音素的声学模型,而且提取后的特征又需要进行UBM-i-vector过程,相当耗时。
下图中的右图,网络结构中,有一个Statistics Pooling Layer,负责将Frame-level Layer,Map到Segment-Level Layer,计算frame-level Layer的Mean和standard deviation。TDNN是时延架构,Output Layer可以学习到Long-Time特征,所以x-vector可以利用短短的10s左右的语音,捕捉到用户声纹信息,在短语音上拥有更强的鲁棒性。提取x-vector,LDA降维,然后以PLDA作为back-end,便可以做Verification。
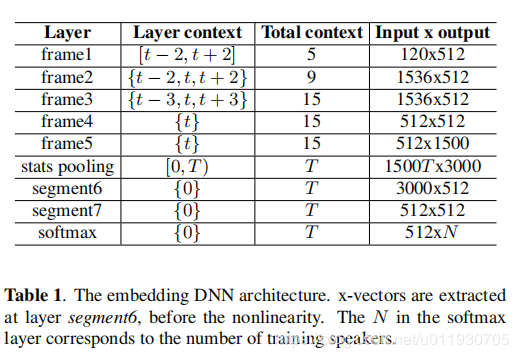
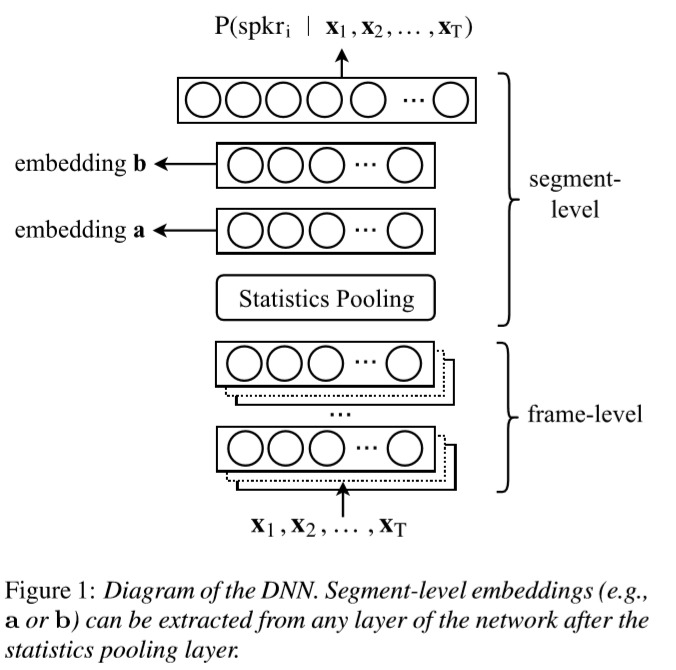
参考论文《A Study on Pairwise LDA for X-vector based Speaker Recognition》,下图展示了x-vector的提取流程图:
神经网络并不仅仅是一个分类器,而是一个特征提取器和分类器的结合,每一层都有极强的特征提取能力。因此可以将模型的一部分作为特征提取器,也就是embeddings。
当前(2019-2020年)属于embedding的时代,尤其是x-vector已经成为了几乎所有的Challenges和papers的新baseline。ASV spoof 2019上的ASV部分默认使用x-vector进行。
可参考【声纹识别X-Vector】。
损失函数
非系统性总结,持续更新……
AM-Softmax-Loss
参考:
【论文笔记】Additive Margin Softmax for Face Verification
softmax loss加margin系列:增大类间距离
Softmax理解之margin
softmax loss是我们最熟悉的loss之一了,分类任务中使用它,分割任务中依然使用它。softmax loss实际上是由softmax和cross-entropy loss组合而成,两者放一起数值计算更加稳定。
L-Softmax, A-Softmax引入了角间距的概念,用于改进传统的softmax loss函数,使得人脸特征具有更大的类间距和更小的类内距。IEEE SPL 2018上,作者在这些方法的启发下,提出了一种更直观和更易解释的additive margin Softmax (AM-Softmax)。

就是把L-Softmax的乘法改成了减法,同时加上了尺度因子s。作者这样改变之后前向后向传播变得更加简单。其中W和f都是归一化过的,作者在论文中将m设为0.35,尺度因子s设为30。(值得注意的是,normalization是收敛到好的点的保证,同时,必须加上scale层,scale的尺度在文中被固定设置为30)
角度距离与余弦距离的关系:Asoftmax是用m乘以θ,而AMSoftmax是用cosθ减去m,这是两者的最大不同之处:一个是角度距离,一个是余弦距离。之所以选择cosθ-m而不是cos(θ-m),这是因为我们从网络中得到的是W和f的内积,如果要优化cos(θ-m)那么会涉及到arccos操作,计算量过大。
Triplet-Loss
参考:声纹识别算法、资源与应用(三) - 知乎 (zhihu.com)
2015年,谷歌的FaceNet使用Triplet Loss在大规模人脸识别中取得了很大的成功。受此启发,在声纹识别领域,也有不少的文章使用Triplet loss。它的优点是,直接使用embeddings之间的相似度作为优化的成本函数(Loss Function),最大化【anchor】和【positive】的相似度,同时最小化【anchor】和【negative】的相似度。这样,在提取了说话者的embedding之后,声纹验证和声纹识别任务就可以简单地通过相似度计算实现。
Triplet Loss基本思路是:构造一个三元组,由anchor(锚,可以理解为一个参考语音)、positive(相对anchor而言)和negative(相对anchor而言)组成。然后,用大量标注好的三元组作为网络输入,来学习DNN参数。其中,anchor和positive是来自于同一个人的不同声音,anchor和negative是来自不同的人的声音。通过DNN获取各自的embeddings后,计算anchor和positive的相似度,以及anchor和negative的相似度,然后最大化ap(anchor与positive)的相似度,最小化an(anchor与negative)的相似度。
计算相似度有两种方法,一种是cosine相似度,值越大,相似度越高,正如Baidu Deep Speaker所采用的;一种是使用欧几里得距离,和FaceNet所使用的一样,值越小,相似度越高。
GE2E-loss
参考:<解析>speaker verification模型中的GE2E损失函数 - dynmi - 博客园 (cnblogs.com)
GE2E loss 全称为Generalized end to end loss function。它聚焦于embedding的差异性,比TE2E(tuple-based endto-end loss function)损失函数更有效。
Generalized end-to-end (GE2E) loss是谷歌在论文《Wan L, Wang Q, Papir A, et al. "Generalized End-to-End Loss for Speaker Verification", ICASSP 2018》中提出的新损失函数,还是比较有创意的。与TE2E loss和Triplet loss相比,它每次更新都和多个人相比,因此号称能使训练时间更短,说话人验证精度更高。
其基本思路如下图所示,挑选 个人,每人 句话,通过图示的顺序排列组成Batch,接着通过LSTM神经网络提取 句话的embeddings,然后求取每个embedding和每个人平均embedding的相似度,得到一个相似度矩阵。最后通过最小化GE2E loss使得相似矩阵中有颜色的相似度尽可能大,灰色的相似度尽可能小,即本人的embedding应该和本人每句话的embedding尽可能相近,和其他人的embedding尽可能远离,从而训练LSTM网络。
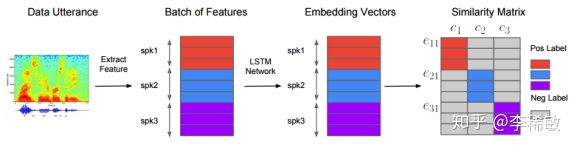 GE2E系统架构(不同的颜色表示不同的说话者)
GE2E系统架构(不同的颜色表示不同的说话者)
此外,为了训练的稳定性,论文中建议在计算本人和本人某句话相似度的时候,不要让该句话的embedding来参与计算本人的embedding。
业界研究
非系统性整理,持续更新……
Deep-Speaker
参考:论文速递:Deep Speaker: an End-to-End Neural Speaker Embedding System
源码:https://github.com/philipperemy/deep-speaker
论文:Deep Speaker: an End-to-End Neural Speaker Embedding System
数据:VoxCeleb:A large scale audio-visual dataset of human speech
百度于2017年提出,一个新的,端到端的,基于深度学习的speaker embedding系统。该系统将语音句子映射到一个超平面,然后通过cosine similarity计算说话人之间的相似度。由该Deep Speaker所生成的embeddings 可以被用作多任务,包括说话人识别、验证和聚类。
文章提出了一个深度残差CNN模型(ResCNN),灵感来自于残差网络resnets,我们也融合了GRU层作为一个可选择的帧级特征提取方法(由于它被证明在语音提取应用中是有效的)。【尽管深度网络比起浅层网络的能力更强,但是它们往往很难训练。ResNet的提出使得深度CNN的训练更容易一点。ResNet由一系列的残差块构成。每一个残差块都包含低层输出到高层输出直接相连的线。】
文章通过ResCNN和GRU模型提取音频特征,然后做一个平均池化去产生句子级别的speaker embeddings,然后以cosine similarity为基础,使用triplet loss损失函数训练模型(这能够最小化相同说话人embedding之间的距离,最大化不同说话人的embedding之间的距离)。预训练使用了一个softmax层和交叉熵通过固定的说话人提高模型的性能。
在三个不同数据库上的实验表明,Deep Speaker系统比基于DNN的i-vector特征要好得多。例如,Deep Speaker系统在文本无关的数据集上将验证错误率(vertification error rate)降低了50%,将识别准确率(identification accuracy)提高了60%。结果表明,通过普通话对模型进行训练和调整可以提高英文说话者识别的准确率。
一些总结
上述方法中,GMM-UBM和GMM-i-vector都属于统计模型;d-vector和x-vector属于深度学习方法。
d-vector(深度神经网络最后一个隐藏层作为embeddings特征)、x-vector(从TDNN网络中提取embeddings特征)。
i-vector和x-vector都可以在kaldi中找到相关实验。
【知乎PUePN】GMM-UBM, i-vector, x-vector都是针对文本无关说话人识别提出来的,他们都有normalize phoneme 的隐式操作(average, pooling等等)。但是我们发现在文本相关任务上表现也还ok,但是还ok的前提是我们限定了训练数据,或者至少限定了plda的数据是文本相关的。
声纹识别的一些基础可参考:
https://www.cnblogs.com/Vanessa-Feng/p/7465352.html
声纹识别发展综述 - 知乎 (zhihu.com)
声纹识别的应用实践 - 知乎 (zhihu.com)
CSDN博客:声纹识别综述
CSDN博客:声纹识别知识整理
开源工具
更多参考:声纹识别算法、资源与应用(二) - 知乎 (zhihu.com) 【资源篇】
声纹识别主要的开源工具有:
1.MSR Identity Toolkit ,微软开源的工具箱,MATLAB版本,包含GMM-UBM和i-vector的demo,简单易用。
2.Alize,主要包括GMM-UBM、i-vector、JFA三种传统的方法,C++版,简单易用。
3.kaldi, 流行的语音识别工具包,也包括声纹识别:覆盖了主流的声纹识别算法(i-vector 、x-vector等),脚本语言,使用不易。