一、引言
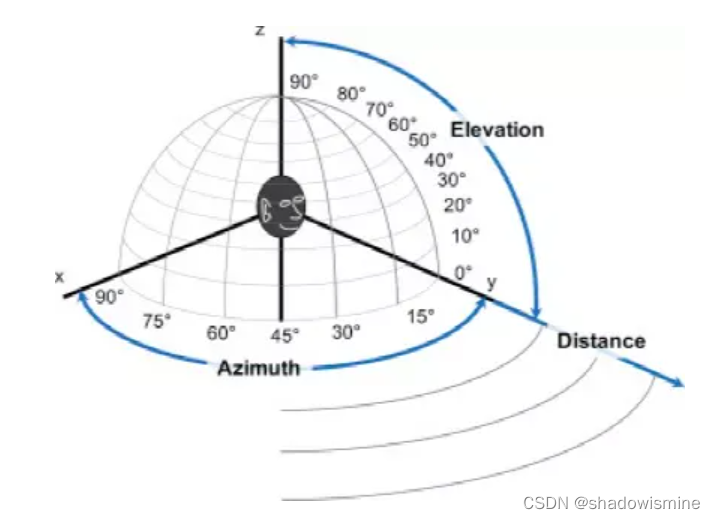
什么是声源定位(Sound Source Localization,SSL)技术?声源定位技术是指利用多个麦克风在环境不同位置点对声信号进行测量,由于声信号到达各麦克风的时间有不同程度的延迟,利用算法对测量到的声信号进行处理,由此获得声源点相对于麦克风的到达方向(包括方位角、俯仰角)和距离等。
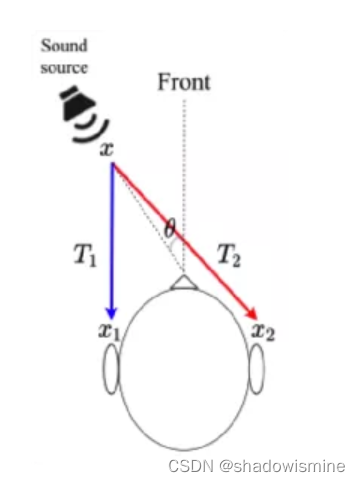
当谈及到声源定位,我们很容易联想到人耳定位,人的单耳和双耳都具有定位的能力。在单耳定位中,耳廓各部位会对入射声波进行反射,再进入耳道。由于与直达声波相位不同,两者在耳道出发生干涉,产生了特殊听觉效果,该效应称为耳廓效应,再配合人头转动因素,可以达到声源定位的目的。在双耳定位中,我们通过左耳和右耳接收到的信号会有时间差(Interaural Time Difference, ITD)和声级差(Interaural Level Difference, ILD),根据ITD和ILD对特定的声音进行定位,水平方位角的确定在数学上可以表述为一个二维声音方向估计问题,如下图1所示。ITD信息在中低频时的方位估计有更好的效果,而ILD信息在高频的方位估计有更好的效果。再加上耳廓效应、头部转动、优先效应等,我们会对角度、距离等信息有更进一步、更准确的认知。
什么是阵列麦克风?
麦克风阵列是由一定数目的麦克风组成,对声场的空间特性进行采样并滤波的系统。目前常用的麦克风阵列可以按布局形状分为:线性阵列,平面阵列,以及立体阵列。其几何构型是按设计已知,所有麦克风的频率响应一致,麦克风的采样时钟也是同步的。
麦克风阵列一般用于:声源定位,包括角度和距离的测量,抑制背景噪声、干扰、混响、回声,信号提取,信号分离。其中声源定位技术利用麦克风阵列计算声源距离阵列的角度和距离,实现对目标声源的跟踪。

环形6麦阵列 USB 4麦克风阵列
基于麦克风阵列的语音分离就是利用麦克风阵列或多个麦克风来模拟人耳,通过语音分离算法将麦克风采集到的相互干扰的混叠信号分离开来以获得感兴趣的信号。而基于麦克风阵列的声源定位也是首先利用麦克风阵列采集语音信号,然后利用数字信号处理的相关技术对采集的信号做分析处理,最后确定并对声源的空间位置(即声源在平面或空间中的坐标)进行跟踪。
二、声源定位技术
声源定位技术主要有以下两部分组成:
- 到达方向 (Direction-of-arrival, DOA) 估计,其中包括方位角与俯仰角。
- 距离估计。
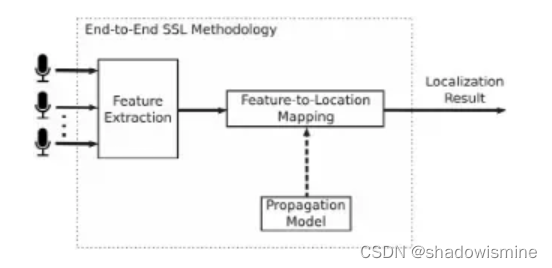
1. 端到端的模型
声源定位端到端的模型对采集到的声音信号进行特征提取,然后使用声音定位方法来获得输出,而该映射方法很大程度依赖于声学传播模型。
传播模型(Propagation Model)。声源定位的声学传播模型比较常见的是自由场模型和远场模型。在自由场中,声音只通过一条直达的路径到达麦克风,这也意味着声源与麦克风之间没有阻挡物,没有声音的反射(没有室内的混响),例如空旷的室外或者消音环境室中。在远场中,麦克风间的距离和声源到麦克风阵列的距离之间的关系,使得声波可以被认为是平面波。
特征(Feature)。在使用的声学定位方法中,使用了以下声学特征:到达时间差(Time difference of arrival, TDOA),麦克风间的能量差(Inter-microphone intensity difference, IID),频谱缺口(Spectral notches),MUSIC伪频谱(Pseudo-spectrum),以及波束形成可控响应(Beamforming steered-response)等。
映射方法(Mapping procedures)。声源定位中的映射方法是指将阵列信号中的特征映射为其位置信息。
2. 实现方法
(1)到达方向估计
基于相对时延估计的方法。由于阵列的几何结构,各个阵列接收到的信号都有不同程度的延时,而基于相对时延估计的方法通过互相关、广义互相关(Generalized Cross-Correlation, GCC)或相位差等来估计各个阵列信号之间的时延差,再结合阵列的几何结构来估算声源的方位角信息。
基于波束形成的方法。该算法通常对阵列的各阵元使用所有角度补偿相位,以实现对目标区域的扫描,然后对各信号进行加权求和,将波束输出功率最大的方向作为目标声源的方向。常见的基于波束形成的声源方位角估计算法有延迟相加(Delay and Sum, DS)算法,最小方差无失真响应(Minimum Variance Distortionless Response, MVDR)算法,可控响应功率相位变换法(Steered Response Power-Phase Transform, SRP-PHAT)等。
基于信号子空间的方法。这类算法一般可以分为相干子空间方法和非相干子空间方法,在非相干子空间算法中,最经典的算法为多信号分类(Multiple Signal Classification, MUSIC)算法,其思想是将信号的协方差进行特征提取,利用特征向量构建信号子空间和噪声子空间,再将噪声子空间构建高分辨率空间谱。由于声源信号是宽带信号,可以对声源信号使用傅立叶变换分解成多个窄带信号,再对每个窄带利用MUSIC算法定位,将各窄带估计得结果加权组合得宽带方位估计。而相干子空间方法是将窄带信号汇聚到某一参考频率,从而采用窄带子空间处理方法进行方位估计。
基于模态域的方法。上述方法皆是阵元域的处理方法,而模态域的一大特性是其波束和导向矢量的频率无关,依据此可以设计出具有低频指向型的波束形成器,也可以降低阵元域波束扫描的频点数。模态域的处理方法与阵元域相比,其波束形成多出一步模态展开的操作,模态展开可通过傅立叶变换实现,展开后的每阶模态都有与之对应的空间特征波束,对应于特定的波束响应,可以看作是组合成期望波束响应的一组基。理论上来讲,只要模态展开的阶数足够高,理论是可以组合逼近成任意的波束。模态域的方法目前应用在球型阵列和环型阵列上有比较好的结果。
基于机器学习(或深度学习)的方法。与传统基于模型的方法相比,基于机器学习的方法是数据驱动的,甚至无需定义传播模型。基于机器学习的方法将声源定位看作是一个多分类或者线性回归问题,利用其非常强的非线形拟合能力,直接将多通道数据特征映射成定位结果。基于机器学习的方法主要也发展成了两种方向,即基于网格的方法和无网格的方法,这两种方法在定位精度和估计声源个数上各有优势。
(2)距离估计
与DOA估计相比,声源距离的估计研究起步较晚。在得到DOA估计结果后,声源被定位在了由传声器和捕获信号之间的双曲线内,若采用多个传声器阵列对源信号进行DOA估计,则可通过每个传声器阵列的双曲线交点对声源进行定位。然而,该方法并不适用于远距离测距,许多研究也停留在室内的短距离声源测距上。
在室内条件下,当声源距离发生变化时,来自反射声的能量(如室内混响漫射声场)可以假定是保持不变,而来自直达声的能量会发生变化。这两种能量的比值被称为直达混响比(Direct-to-Reverberant ratio, DRR),该比值与声源距离的估计密切相关。理论上,信号的DRR可以通过声源到达传声器的房间冲激响应函数(Room Impulse Responses, RIRs)直接计算出。但声源距离的估计受多方因素的影响(如RIRs未知,近场与远场模型不匹配,混响能量会因距离的改变而改变等),这些方法并不成熟,无法得到很好的应用。
3. 评价指标
针对DOA估计和距离估计的方法,需要依靠一些指标来衡量声源定位的性能,常见的评价指标如下:
平均误差(Average error)。它衡量的是估计的误差,通常将估计值与真实值进行比较,将这些值的平均差异表现出来。具体实现的方法包括绝对误差、均方误差、均方根误差和最大误差等。
准确率(Accuracy)。这个指标通常用于DOA估计,我们假定如果估计值在真实值一定的误差范围内,则认定该估计是正确的,否之,认定为错误。它衡量了多少比例的检测是正确的。
查准率(Precision)、查准率(Recall)和F1分数(F1-score)。这些指标在机器学习分类任务中比较常见的。针对估计一个声源的位置,如果估计正确,则称为真正例(True positive);如果估计错误,则称为假反例(False negative)。假设该位置没有声源,如果估计的结果也是没有,则称为真反例(True negative);如果估计的结果是有声源,则称为假正例(False positive)。查全率衡量所检测正确的声源位置个数占所有声源的比例;查准率衡量所估计到的声源位置中,有多少位置估计是正确的比例。一般来说,查准率和查全率呈负相关关系,而F1分数为这两个指标的调和平均,提供它们之间的平衡。
声源的数量(Number of sources)。该指标衡量所能估计到声源的数量,而不在乎声源的具体位置。
还有一些其他的性能指标,如将某声源定位方法用在语音识别、声源分离、语音拾取任务的预处理,上述任务依赖于声源定位的效果,通过这些任务的性能表现来间接评价声源定位的性能。
三、语音分离与声源定位算法Steered Response Power Phase Transform(SRP-PHAT)+Degenerate Unmixing Estimation Technique(DUET)
相位变换加权的可控响应功率算法Steered Response Power Phase Transform(SRP-PHAT)是定位声源的一种重要的算法。对于多源扩展,可以使用Degenerate Unmixing Estimation Technique(DUET)来分离每个源,并将其传递给SRP-PHAT算法以实现多源跟踪
3D Multiple Sound Sources Localization (SSL)
GitHub - BrownsugarZeer/Multi_SSL: Combine sound source separation with SRP-PHAT to achieve multi-source localization.Combine sound source separation with SRP-PHAT to achieve multi-source localization. - GitHub - BrownsugarZeer/Multi_SSL: Combine sound source separation with SRP-PHAT to achieve multi-source localization. https://github.com/BrownsugarZeer/Multi_SSL
https://github.com/BrownsugarZeer/Multi_SSL
1
2
3