文章目录
- 第八章 多表查询
- 8.1 多表查询介绍
- 8.1.1 什么是多表查询
- 8.1.2 多表查询基本写法
- 8.1.3 笛卡尔积
- 8.1.4 连接查询条件限制
- 8.2 连接查询分类
- 8.2.1 内连接
- 8.2.2 外连接
- 8.2.3 全连接
- 8.2.4 自然连接
- 8.3 子查询
- 8.3.1 子查询简介
- 8.3.2 在where子句中
- 8.3.3 在from子句中
- 8.3.4 在having子句中
- 8.3.5 在select子句中
- 8.3.6 SQL完整的执行顺序
- 8.4 合并查询结果集
- 8.4.1 合并查询结果集概述
- 8.4.2 合并查询结果集语法
第八章 多表查询
8.1 多表查询介绍
8.1.1 什么是多表查询
有的时候,我们的业务需求的数据并不只是在一张表中,而是分布在两张或两张以上的表中,而这些表中通常都会存在着“有关系”的字段。那么此时的查询操作,我们需要从多张表中查询数据,我们称之为多表关联查询。或者叫做连接查询。
多表查询方式,在复杂、海量数据的场景下怎么应用?这些思维与技能其实就是我们大数据后续课程中的技巧与应用场景,所以打好SQL坚实基础,能极提升后续你对数据仓库(SQL为主)的见解。
8.1.2 多表查询基本写法
-- 从两张表中查询数据
select * from A, B;-- 从两张表中查询数据
select * from A join B;
TIPS:
其实,连接两张表进行查询,标准SQL采用的是join的语法。上述的select * from A, B;的写法,其实只是在MySQL中的“方言”,只在MySQL中生效,在其他的DBMS中就不一定能使用了。
select * from A, B; 其实是等价于 select * from A inner join B; 的。那么什么是inner join呢?后面会讲。
8.1.3 笛卡尔积
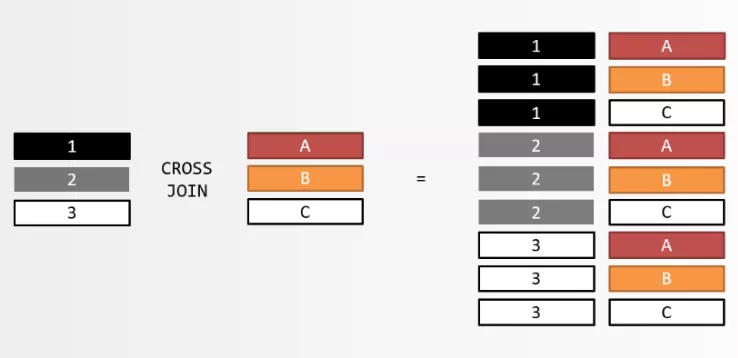
在做连接查询的时候,一张表中的每一行数据都会和另一张表中的每一行数据进行关联,形成笛卡尔积。
假如A表中有m行数据,B表中有n行数据,连接查询之后的结果就是m*n行数据,其中有太多的数据是我们不需要的了。
8.1.4 连接查询条件限制
通过上图,我们知道了在两张表进行连接查询的时候,会出现大量的无效的数据。因此,我们就需要通过一些操作,去除连接查询之后的无用的数据,只得到我们需要的数据!而这个过程是可以通过条件的限制来实现的:
-
MySQL的查询方言
-- 用where进行条件的过滤,得到满足条件的所有的数据。 select * from A, B where A.empno = B.mgr; -
标准SQL的语法
-- 用on的方式,进行连接查询的多余数据过滤 select * from A join B on A.empno = B.mgr;
8.2 连接查询分类
将两张表连接在一起查询的时候,通常情况下我们需要进行一定的条件限制,来达到去除查询结果笛卡尔积中多余的数据,保留我们需要的数据的目的。通常情况下,进行连接查询的多张表之间是有一定的逻辑关联的,具体表现为有一个相同的字段,在两张表中都会出现。因此,我们在进行连接查询的时候就会使用这个字段的值进行数据的过滤。
那么,连接查询就会出现这样的几种情况:
- A表中,通过关联的字段,可以在B表中查询到数据。
- A表中,通过关联的字段,无法在B表中查询到数据。
- B表中,通过关联的字段,无法的A表中查询到数据。
此时,根据所需的不同结果,可以将连接查询分为两类: 内连接、外连接
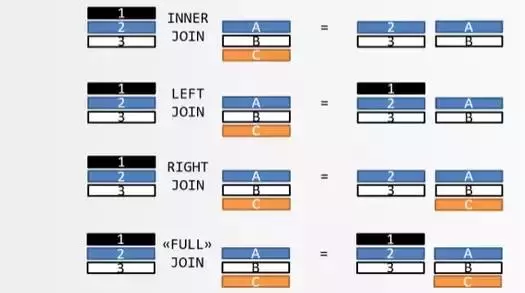
8.2.1 内连接
内连接,使用inner join来表示,在进行查询的时候,inner是可以省略的,因此通常情况下直接写join就是内连接。
所谓内连接,以左表为驱动表,右表为从动表。查询结果中保留A表的数据通过连接的字段,在B表中能够查询到的数据。
-- 查询员工的编号、职位、入职时间、部门编号、部门名称
select empno, job, hiredate, deptno, dname from emp join dept on emp.deptno = dept.deptno;-- 查询LOCATION在NEW YORK的员工数量
select count(*) from emp join dept on emp.deptno = dept.deptno where loc = 'NEW YORK';
8.2.2 外连接
外连接,使用outer join来表示,但是外连接还有更加明细的分类: 左外连接和右外连接。
- 左外连接: 以左表为驱动表,右表为从动表,查询结果中保留A表的数据通过连接的字段,在B表中能够查询到的数据。如果通过这个连接字段无法在B表中查询到数据,则B表与之关联的就是null数据。
- 右外连接: 以右表为驱动表,左表为从动表,查询结果中保留B表的数据通过连接的字段,在A表中能够查询到的数据。如果通过这个连接字段无法在A表中查询到数据,则A表与之关联的就是null数据。
总结来说
左外连接查询结果: 包含左表中的所有数据,右表与之关联的数据,如果在右表没有与之关联的数据,则用null填充。
右外连接查询结果: 包含右表中的所有数据,左表与之关联的数据,如果在左表没有与之关联的数据,则用null填充。
语法: 左外连接使用 left outer join来表示,右外连接使用 right outer join来表示。
而outer是可以省略不写的,也就是: 左外连接: left join,右外连接: right join
-- 查询所有的部门的人数
select deptno, dname, count(empno) from dept left join emp on dept.deptno = emp.deptno;
8.2.3 全连接
全连接,又叫全外连接。全连接的意义是保留两张表中的所有的数据。如果在另外一张表中没有与之连接的数据,使用null进行填充。也就是说,其实全连接就是将左外连接和右外连接的查询结果合并到一起并去除重复的数据。
MySQL不支持全连接!
虽然MySQL不支持全连接,但是可以使用其他的方式来间接实现:
将左外连接和右外连接的查询结果,使用union合并到一起即可。
8.2.4 自然连接
我们在进行连接查询的时候,通常会在需要连接的两张表中找到字段关联在一起,而绝大多数情况下我们所需要进行的是等值连接。在进行数据库和表的设计的时候,这样用来联系多张表之间的关系的字段,一般情况下命名是相同的。
所谓“自然连接“指的就是找到需要进行连接查询的两张表中名字相同、类型也相同的字段,自动的使用这个字段作为连接的字段。如果不存在这样的名字相同的字段,会有错误。
select * from emp natural join dept;
select * from emp natural right join dept;
8.3 子查询
8.3.1 子查询简介
有的时候,当一个查询语句A所需要的数据,不是直观在表中体现,而是由另外一个查询语句B查询出来的结果,那么查询语句A就是主查询语句,查询语句B就是子查询语句。这种查询我们称之为高级关联查询,也叫做子查询。
子查询语句的返回数据形式:
- 返回单行单列 => 可以被视为一个数值来使用
- 返回多行单列 => 可以被视为一个集合来使用
- 返回单行多列 => 可以被视为一个虚拟表使用
- 返回多行多列 => 可以被视为一个虚拟表使用
子查询语句的位置可以在以下几个子句中:
- 在where子句中: 子查询的结果可用作条件筛选时使用的值。
- 在from子句中: 子查询的结果可充当一张表或视图,需要使用表别名。
- 在having子句中: 子查询的结果可用作分组查询再次条件过滤时使用的值
- 在select子句中: 子查询的结果可充当一个字段。仅限子查询返回单行单列的情况。
8.3.2 在where子句中
# 需求:查询工资大于员工编号为7369这个员工的所有员工信息。
# 解析:
# 第一步:目的是查询工资大于某一个数num的所有员工信息
# select * from emp where sal>num
# 第二步:num的值7369员工的工资
# select sal from emp where empno = 7369;
# 第三步:将主查询中的代词使用子查询语句替换
select * from emp where sal>(select sal from emp where empno = 7369);# 需求:查询工资大于10号部门的平均工资的所有员工信息
select * from emp where sal>(select avg(ifnull(sal,0)) from emp where deptno=10);# 需求:查询工资大于10号部门的平均工资的非10号部门的员工信息。
select * from emp where sal>(select avg(ifnull(sal,0)) from emp where deptno=10) and deptno<>10;# 需求:查询与7369同部门的同事信息。
select * from emp where deptno=(select deptno from emp where empno=7369) and empno<>7369;
8.3.3 在from子句中
# 需求:查询员工的姓名,工资,及其部门的平均工资。
# 解析:
# 第一步:先查询每个部门的平均工资
# select deptno,avg(ifnull(sal,0)) from emp group by deptno;
# 第二步:将上一个查询语句的返回结果当成一张表,与员工表进行关联查询
select A.ename, A.sal, B.avg_sal
from emp A join (select deptno,avg(ifnull(sal,0)) avg_sal from emp group by deptno) B on A.deptno = B.deptno
8.3.4 在having子句中
# 需求:查询平均工资大于30号部门的平均工资的部门号,和平均工资
select deptno,avg(ifnull(sal,0)) from emp group by deptno having avg(ifnull(sal,0))>
(select avg(ifnull(sal,0)) from emp where deptno=30);
8.3.5 在select子句中
# 查询每个员工的信息及其部门的平均工资,工资之和,部门人数
select A.empno,A.ename,A.sal,
(select avg(ifnull(sal,0)) from emp B where B.deptno=A.deptno) avg_sal,
(select sum(sal) from emp C where C.deptno=A.deptno) sum_sal,
(select count(*) from emp D where D.deptno=A.deptno) count_
from emp A;
8.3.6 SQL完整的执行顺序
select distinct..from t1 [inner|left|right] join t2 on 条件
where...group by...having...order by...limit1. from t1
2. on 条件
3. [inner|left|right] join t2
4. where...
5. group by...
6. having...
7. select...
8. distinct...
9. order by...
10. limit....
8.4 合并查询结果集
8.4.1 合并查询结果集概述
合并结果集,就是将两次或者多次的查询结果,合并到一起,存入一张查询结果虚拟表中。
进行结果集合并的多张表,要求字段的数量是完全相同的。
A查询的结果有5个字段,B查询的结果有5个字段。此时是可以合并到一起的。
A查询的结果有5个字段,B查询的结果有3个字段。此时是无法合并到一起的。
8.4.2 合并查询结果集语法
- union: 对两次的查询结果进行合并,对最终的合并结果会进行去重的处理。
- union all : 对两次的查询结果的直接合并,没有进行去重的处理。