深度学习框架Tensorflow2系列
注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hive Flume等等~写的都是纯干货,各种顶会的论文解读,一起进步。
这个系列主要和大家分享深度学习框架Tensorflow2的各种api,从基础开始。
#博学谷IT学习技术支持#
文章目录
- 深度学习框架Tensorflow2系列
- 前言
- 一、文本分类任务实战
- 二、数据集介绍
- 三、RNN模型所需数据解读
- 四、实战代码
- 1.数据预处理
- 2.构建初始化embedding层
- 3.构建训练数据
- 4.自定义双层RNN网络模型
- 5.设置参数和训练策略
- 6.模型训练
- 总结
前言
通过代码案例实战,学习Tensorflow2的各种api。
一、文本分类任务实战
任务介绍:
数据集构建:影评数据集进行情感分析(分类任务)
词向量模型:加载训练好的词向量或者自己训练都可以
序列网络模型:训练RNN模型进行识别
二、数据集介绍
训练和测试集都是比较简单的电影评价数据集,标签为0和1的二分类,表示对电影的喜欢和不喜欢

三、RNN模型所需数据解读
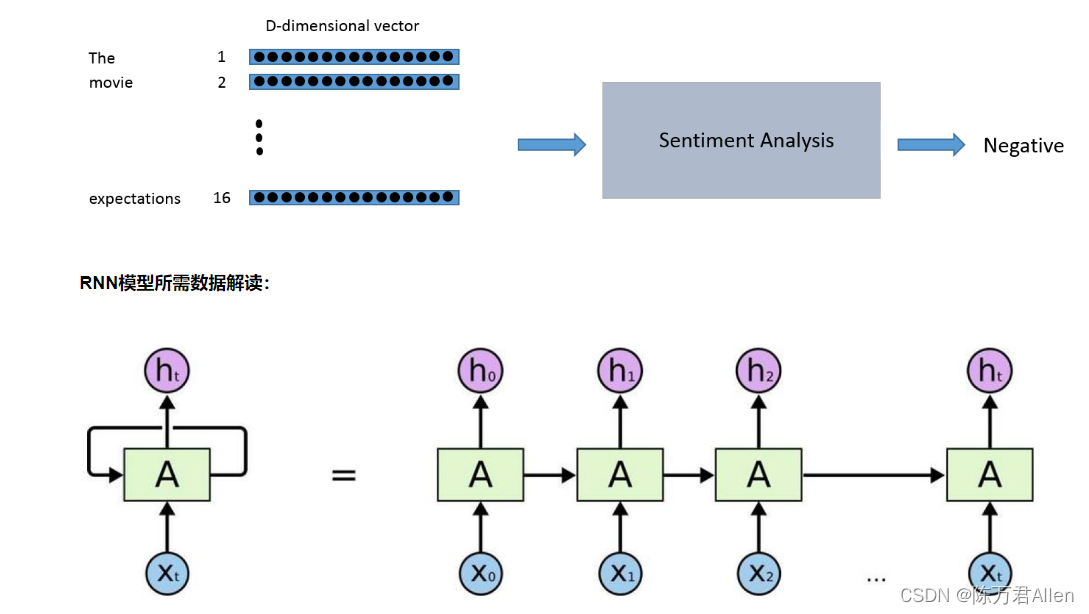
RNN是一个比较基础的序列化模型,其中输入的数据为[batch_size,max_len,feature_dim]
四、实战代码
1.数据预处理
import os
import warnings
warnings.filterwarnings("ignore")
import tensorflow as tf
import numpy as np
import pprint
import logging
import time
from collections import Counter
from pathlib import Path
from tqdm import tqdm# 构建语料表,基于词频来进行统计
counter = Counter()
with open('./data/train.txt',encoding='utf-8') as f:for line in f:line = line.rstrip()label, words = line.split('\t')words = words.split(' ')counter.update(words)words = ['<pad>'] + [w for w, freq in counter.most_common() if freq >= 10]
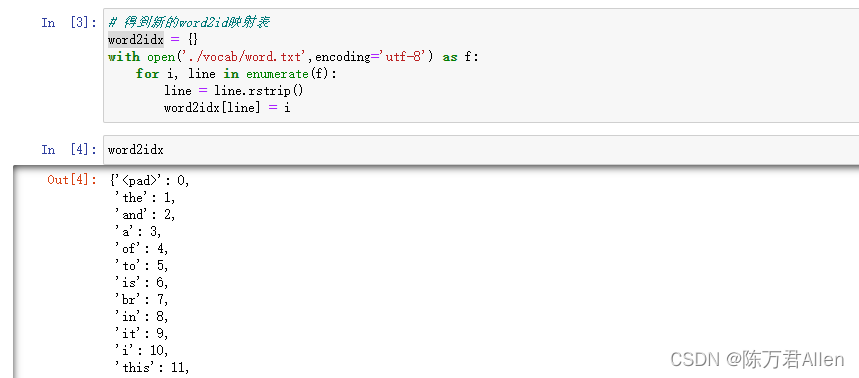
print('Vocab Size:', len(words))Path('./vocab').mkdir(exist_ok=True)with open('./vocab/word.txt', 'w',encoding='utf-8') as f:for w in words:f.write(w+'\n')# 得到word2id映射表
word2idx = {}
with open('./vocab/word.txt',encoding='utf-8') as f:for i, line in enumerate(f):line = line.rstrip()word2idx[line] = i
得到的结果如下
2.构建初始化embedding层
# 做了一个大表,里面有20598个不同的词,【20599*50】
embedding = np.zeros((len(word2idx)+1, 50)) # + 1 表示如果不在语料表中,就都是unknowwith open('./data/glove.6B.50d.txt',encoding='utf-8') as f: #下载好的count = 0for i, line in enumerate(f):if i % 100000 == 0:print('- At line {}'.format(i)) #打印处理了多少数据line = line.rstrip()sp = line.split(' ')word, vec = sp[0], sp[1:]if word in word2idx:count += 1embedding[word2idx[word]] = np.asarray(vec, dtype='float32') #将词转换成对应的向量# 保存结果
print("[%d / %d] words have found pre-trained values"%(count, len(word2idx)))
np.save('./vocab/word.npy', embedding)
print('Saved ./vocab/word.npy')
得到的结果如下:word.txt中的每个单词转换成对应的向量
3.构建训练数据
def data_generator(f_path, params):with open(f_path,encoding='utf-8') as f:print('Reading', f_path)for line in f:line = line.rstrip()label, text = line.split('\t')text = text.split(' ')x = [params['word2idx'].get(w, len(word2idx)) for w in text]#得到当前词所对应的IDif len(x) >= params['max_len']:#截断操作x = x[:params['max_len']]else:x += [0] * (params['max_len'] - len(x))#补齐操作y = int(label)yield x, ydef dataset(is_training, params):_shapes = ([params['max_len']], ())_types = (tf.int32, tf.int32)if is_training:ds = tf.data.Dataset.from_generator(lambda: data_generator(params['train_path'], params),output_shapes = _shapes,output_types = _types,)ds = ds.shuffle(params['num_samples'])ds = ds.batch(params['batch_size'])ds = ds.prefetch(tf.data.experimental.AUTOTUNE)#设置缓存序列,目的加速else:ds = tf.data.Dataset.from_generator(lambda: data_generator(params['test_path'], params),output_shapes = _shapes,output_types = _types,)ds = ds.batch(params['batch_size'])ds = ds.prefetch(tf.data.experimental.AUTOTUNE)return ds
4.自定义双层RNN网络模型
class Model(tf.keras.Model):def __init__(self, params):super().__init__()self.embedding = tf.Variable(np.load('./vocab/word.npy'),dtype=tf.float32,name='pretrained_embedding',trainable=False,)self.drop1 = tf.keras.layers.Dropout(params['dropout_rate'])self.drop2 = tf.keras.layers.Dropout(params['dropout_rate'])self.drop3 = tf.keras.layers.Dropout(params['dropout_rate'])self.rnn1 = tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(params['rnn_units'], return_sequences=True))self.rnn2 = tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(params['rnn_units'], return_sequences=True))self.rnn3 = tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(params['rnn_units'], return_sequences=False))self.drop_fc = tf.keras.layers.Dropout(params['dropout_rate'])self.fc = tf.keras.layers.Dense(2*params['rnn_units'], tf.nn.elu)self.out_linear = tf.keras.layers.Dense(2)def call(self, inputs, training=False):if inputs.dtype != tf.int32:inputs = tf.cast(inputs, tf.int32)batch_sz = tf.shape(inputs)[0]rnn_units = 2*params['rnn_units']x = tf.nn.embedding_lookup(self.embedding, inputs)x = self.drop1(x, training=training)x = self.rnn1(x)x = self.drop2(x, training=training)x = self.rnn2(x)x = self.drop3(x, training=training)x = self.rnn3(x)x = self.drop_fc(x, training=training)x = self.fc(x)x = self.out_linear(x)return x
5.设置参数和训练策略
params = {'vocab_path': './vocab/word.txt','train_path': './data/train.txt','test_path': './data/test.txt','num_samples': 25000,'num_labels': 2,'batch_size': 32,'max_len': 1000,'rnn_units': 200,'dropout_rate': 0.2,'clip_norm': 10.,'num_patience': 3,'lr': 3e-4,
}
def is_descending(history: list):history = history[-(params['num_patience']+1):]for i in range(1, len(history)):if history[i-1] <= history[i]:return Falsereturn True
word2idx = {}
with open(params['vocab_path'],encoding='utf-8') as f:for i, line in enumerate(f):line = line.rstrip()word2idx[line] = i
params['word2idx'] = word2idx
params['vocab_size'] = len(word2idx) + 1model = Model(params)
model.build(input_shape=(None, None))#设置输入的大小,或者fit时候也能自动找到decay_lr = tf.optimizers.schedules.ExponentialDecay(params['lr'], 1000, 0.95)#相当于加了一个指数衰减函数
optim = tf.optimizers.Adam(params['lr'])
global_step = 0history_acc = []
best_acc = .0t0 = time.time()
logger = logging.getLogger('tensorflow')
logger.setLevel(logging.INFO)
6.模型训练
while True:# 训练模型for texts, labels in dataset(is_training=True, params=params):with tf.GradientTape() as tape:#梯度带,记录所有在上下文中的操作,并且通过调用.gradient()获得任何上下文中计算得出的张量的梯度logits = model(texts, training=True)loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=labels, logits=logits)loss = tf.reduce_mean(loss)optim.lr.assign(decay_lr(global_step))grads = tape.gradient(loss, model.trainable_variables)grads, _ = tf.clip_by_global_norm(grads, params['clip_norm']) #将梯度限制一下,有的时候回更新太猛,防止过拟合optim.apply_gradients(zip(grads, model.trainable_variables))#更新梯度if global_step % 50 == 0:logger.info("Step {} | Loss: {:.4f} | Spent: {:.1f} secs | LR: {:.6f}".format(global_step, loss.numpy().item(), time.time()-t0, optim.lr.numpy().item()))t0 = time.time()global_step += 1# 验证集效果m = tf.keras.metrics.Accuracy()for texts, labels in dataset(is_training=False, params=params):logits = model(texts, training=False)y_pred = tf.argmax(logits, axis=-1)m.update_state(y_true=labels, y_pred=y_pred)acc = m.result().numpy()logger.info("Evaluation: Testing Accuracy: {:.3f}".format(acc))history_acc.append(acc)if acc > best_acc:best_acc = acclogger.info("Best Accuracy: {:.3f}".format(best_acc))if len(history_acc) > params['num_patience'] and is_descending(history_acc):logger.info("Testing Accuracy not improved over {} epochs, Early Stop".format(params['num_patience']))break
总结
通过RNN文本分类任务代码案例实战,学习Tensorflow2的各种api。