文章目录
- 前言
- MySQL的Server层
- MySQL的存储引擎
- 1)InnoDB 存储引擎
- 2)MyISAM 存储引擎
- 3)Memory 存储引擎
前言
在学习一种事务之前,我们需要先了解事物的基本组成结构,清楚了事物的基本组成结构之后,我们才能更深入的了解相关操作,那么今天我将为大家介绍MySQL的体系架构。
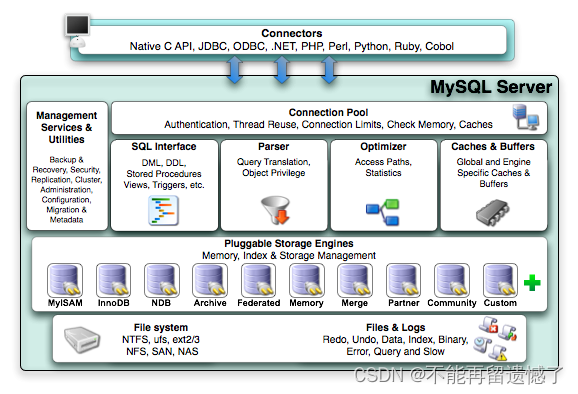
MySQL数据库的服务端主要分为Server层和存储引擎层,接下来我将以这两层为着重点为大家介绍MySQL的体系架构。
MySQL的Server层
MySQL的Server层照顾要有七个组件:
- MySQL 向外提供的交互接口(Connectors)
- 连接池组件(Connection Pool)
- 管理服务组件和工具组件(Management Service & Utilities)
- SQL 接口组件(SQL Interface)
- 查询分析器组件(Parser)
- 优化器组件(Optimizer)
- 查询缓存组件(Query Caches & Buffers)
1)MySQL向外提供的交互接口(Connectors)
Connectors 组件是 MySQL 向外提供的交互组件,如Java,.NET,PHP等语言可以通过该组件来操作 MySQL 语句,实现与 MySQL 的交互。建立连接之后,可以通过show processlist 语句来查看已经建立的连接。

如果客户端一段时间内没有活跃行为,那么连接器在默认的8个小时后会主动断开连接。加果在连接被断开之后,客户端再次发送请求的话,就会收到一个错误提醒:Lost connection to MySQL server during query。
客户端连接到MySQL数据库上时,根据连接时间的长短可以分为:短连接和长连接。短连接比较简单,指每次查询之后会断开,再次查询需要重新建立连接,因此使用短连接的成本较高;长连接指长时间连接到MySOL数据库上并执行数据库操作,因此长连接会导致出现内存溢出的问题从而使MySQL异常重启。
在使用长连接时,可以使用客户端函数mysql_reset_connection()来重新初始化连接资源。这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完时的状态。
2)连接池组件(Connection Pool)
负责监听客户端向MySQL服务器端的各种请求,接收请求、转发请求到目标模块。每个成功连接MySQL服务器端的客户请求都会被创建或分配一个线程,该线程负责客户端与MySQL服务器端的通信,接收客户端发送的命令,传递服务器端的结果信息等。
3)管理服务组件和工具组件(Management Service &Utilities)
提供对MySOL的集成管理,如备份(Backup)、恢复(Recovery)、安全管理(Security)等。
4)SQL接口组件(SQL Interface)
接收用户SQL命令,如DML、DDL和存储过程等,并将最终结果返回给用户。
5)查询分析器组件(Parser)
系统在执行输入语句之前,必须分析出语句想要干什么。例如:首先通过select关键字得知这是一条查询命令,还包括分析要查询的是哪张表以及查询条件是什么。同时,分析器必须分析输入语句的语法正确性。如果SQL中存在语法的错误,则查询分析器组件将返回提示信息“You have an error in your SQL syntax”。
6)优化器组件(Optimizer)
优化器是MySQL用来对输人语句在执行之前所做的最后一步优化。优化内容包括:是否选择索引、选择哪个索引、多表查询的联合顺序等。每一种执行方法的逻辑结果是一样的,但是执行的效率会有不同,而优化器的作用就是决定选择使用哪一种方案。
7)查询缓存组件(Query Caches & Buffers)
这个查询缓存是比较容易理解的。在每一次查询时,MySQL 都先去看看是否命中缓存,命中则直接返回,提高了系统的响应速度。但是这个功能有一个相当大的弊病,那就是一旦这个表中数据发生更改,那么这张表对应的所有缓存都会失效。
对于更新压力大的数据库来说,查询缓存的命中率会非常低。除非业务系统就只有一张静态表,很长时间才会更新一次。比如,一个系统配置表,那这张表上的查询才适合使用查询缓存。所以在生产系统中,建议关闭该功能。
在MySQL8.0版本之前,可以通过将参数“query_cachetype”设置成OFF,来关闭查询缓存的功能。但是在MySQL8.0版本之后,直接删掉了这部分的功能。
show variables like '% query_cache% ';
MySQL的存储引擎
MySQL 存储引擎层负责数据的存储和提取,其架构模式是插件式的,支持InnoDB、MyISAM、Memory、Archive、NDB Cluster等多个存储引擎。最常用的是InnoDB,我将为大家详细介绍InnoDb、MyISAM 和 Mymery 存储引擎。
我们可以使用 show create table 表名; 来查看创建表时使用的存储引擎。
create table test (id int);show create table test;

1)InnoDB 存储引擎
InnoDB是MySQL的默认存储引擎,它支持ACID(原子性、一致性、隔离性和持久性)事务,并提供了行级锁定、外键约束和崩溃恢复等功能。它适用于大多数应用场景,特别是需要事务支持和高并发读写操作的应用。
它具有以下特性:
- 事务支持:InnoDB引擎支持事务的ACID属性,确保了数据的原子性、一致性、隔离性和持久性。这意味着可以使用BEGIN、COMMIT和ROLLBACK语句来管理事务,保证数据的完整性和一致性。
- 行级锁定:InnoDB使用行级锁来处理并发访问和修改数据,而不是表级锁。这意味着多个事务可以同时访问同一表的不同行,提高了并发性能和并发控制。
- 外键约束:InnoDB支持外键约束,可以在数据库层面实现数据的一致性和完整性。它提供了CASCADE、RESTRICT和SET NULL等选项来处理外键关系。
- 崩溃恢复:InnoDB具有崩溃恢复的能力,即使在系统崩溃或电源故障的情况下,也可以保证数据的完整性。它通过事务日志(redo log)来恢复未完成的事务和恢复已提交的事务。
- 自动增长列:InnoDB支持自动增长列,可以为表中的某一列指定自动递增的整数值,简化了数据插入操作。
- 回滚段:InnoDB通过回滚段(Rollback Segment)来存储未提交事务的数据,以便在需要时进行回滚操作。
- 可以在线热备份:InnoDB引擎支持在线热备份,可以在不停止MySQL服务器的情况下备份数据库。
- 支持MVCC(多版本并发控制):InnoDB使用多版本并发控制来处理并发事务,在读操作的同时允许写操作,并通过行版本来实现数据的隔离性和一致性。
- 高性能:InnoDB引擎通过使用缓冲池(Buffer Pool)来缓存热门数据和索引,提高读取数据的性能。
2)MyISAM 存储引擎
MyISAM是MySQL的另一个常见的存储引擎,它不支持事务和行级锁定,但具有良好的性能。MyISAM适用于主要是读取操作的应用,如数据仓库、归档和非事务性的应用。
它具有以下特性:
- 快速读取速度:MyISAM存储引擎在读取数据时非常高效,对于主要是读取操作的应用性能表现较好。这是因为MyISAM表以表级锁定的方式处理并发,读操作可以并发执行,不会有行级锁定带来的争用。
- 支持全文索引:MyISAM存储引擎对全文索引提供了良好的支持,可以通过创建全文索引提供高效的文本搜索能力。
- 节省磁盘空间:相较于InnoDB存储引擎,MyISAM通常在磁盘占用方面更加节省空间,这是因为它不支持事务、行级锁定和崩溃恢复等功能,减少了存储额外的元数据和日志。
- 表级锁定:MyISAM存储引擎使用表级锁定,这意味着一个写操作锁定整个表,因此在写操作频繁的情况下可能会导致并发性能下降。
- 不支持事务和外键:MyISAM存储引擎不支持事务操作,也不支持外键约束。这意味着在使用MyISAM时,你无法使用BEGIN、COMMIT和ROLLBACK等事务操作,也无法定义外键约束来维护数据的完整性。
- 不支持崩溃恢复:MyISAM存储引擎没有崩溃恢复的能力,这意味着如果MySQL服务器在写操作过程中崩溃,可能会导致数据的不一致。
- 自动维护索引统计信息:MyISAM存储引擎会自动维护表的索引统计信息,这些统计信息用于优化查询执行计划。
- 多用途:MyISAM存储引擎适用于主要是读取操作的应用场景,如报表、日志分析和静态网站等。
我们可以在创建表的时候指定存储引擎。
create table 表名 ( ) engine = 存储引擎名
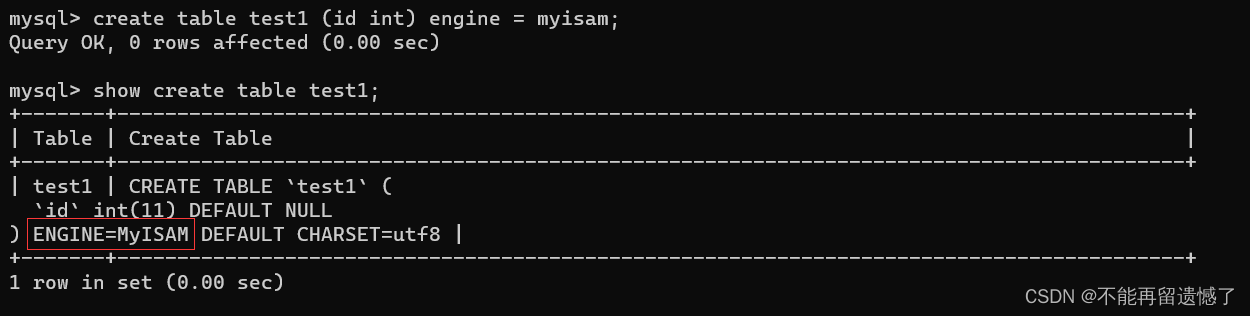
create table test1 (id int) engine = myisam;show create table test1;
正是因为 MyISAM 存储引擎的这些特性,它适合于以下场景:
- 不需要事务支持的场景
- 读多或者写多的单一业务场景,读写频繁的则不合适
- 读写并发访问较低的业务
- 数据修改相对较少的业务
- 以读为主的业务
- 对数据的一致性要求不是很高的业务
- 服务器硬件资源相对比较差的环境
3)Memory 存储引擎
Memeory 存储引擎将表中的数据存储在内存中,而不是磁盘上,也就是说如果重启MySQL 或者关闭,此时的数据将会丢失。
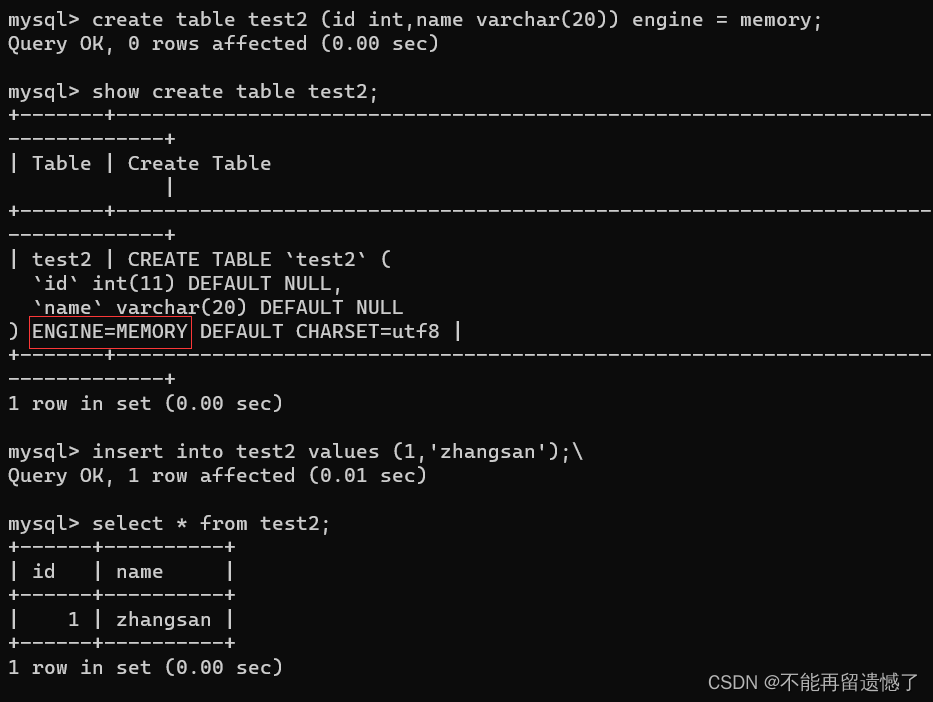
create table test2 (id int,name varchar(20)) engine = memory;
show create table test2;
insert into test2 values (1,'zhangsan');
select * from test2;
# 重启MySQL
systemctl restart mysqld
select * from test2;
输出信息
Empty set (0.00 sec)
Memory 存储引擎具有以下特点:
- 高速读写:由于数据存储在内存中,Memory 存储引擎提供非常快速的读取和写入性能。相比于其他存储引擎,它可以更快地执行查询和写入操作。
- 临时数据和缓存表:由于数据存储在内存中,Memory 存储引擎对于处理临时数据和缓存表非常有效。如果你需要在查询过程中创建一些临时数据,并且它们在查询结束后不再需要,那么 Memory 引擎是一个不错的选择。
- 高速缓存索引:Memory 存储引擎对索引查询非常快速,因为索引数据完全存储在内存中,减少了磁盘I/O的开销。
- 不持久化:Memory 引擎的数据不会持久化到磁盘上,一旦 MySQL 服务器重启或关闭,存储在 Memory 引擎中的数据就会丢失。因此,Memory 存储引擎适合于处理非持久化的数据,并且可以在服务器重新启动后重新加载数据。
- 适用于小规模数据:由于数据存储在内存中,Memory 存储引擎的容量受限于可用的内存大小。它不适合用于处理大规模数据集,因为内存可能会成为限制因素。
- 不支持事务和崩溃恢复:Memory 存储引擎不支持事务,也不支持崩溃恢复。因此,在使用 Memory 存储引擎时需要注意数据的一致性和持久性。