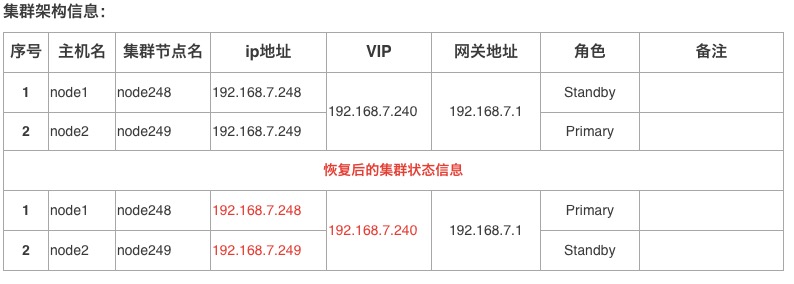
实际工作中,可能会碰到集群脑裂的情况,在脑裂时,会出现双 primary情况。这时,需要用户介入,人工判断哪个节点的数据最新,减少数据丢失。
一、测试环境信息
操作系统:
[kingbase@node1 bin]$ cat /etc/centos-release
CentOS Linux release 7.2.1511 (Core)
数据库:
[kingbase@node1 bin]$ ./ksql -U system test
ksql (V8.0)
Type "help" for help.
test=# select version();version
----------------------------------------------------------------------------------------KingbaseES V008R006C003B0010 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.1.2 20080704 (Red Hat 4.1.2-46), 64-bit
(1 row)
二、集群启动后“双主”故障
1、故障现象
[kingbase@node1 bin]$ ./sys_monitor.sh restart
2021-03-01 13:30:03 Ready to stop all DB ...
Service process "node_export" was killed at process 8253
Service process "postgres_ex" was killed at process 8254
Service process "node_export" was killed at process 8131
Service process "postgres_ex" was killed at process 8132
2021-03-01 13:30:09 begin to stop repmgrd on "[192.168.7.248]".
2021-03-01 13:30:10 repmgrd on "[192.168.7.248]" stop success.
2021-03-01 13:30:10 begin to stop repmgrd on "[192.168.7.249]".
2021-03-01 13:30:11 repmgrd on "[192.168.7.249]" stop success.
2021-03-01 13:30:11 begin to stop DB on "[192.168.7.249]".
waiting for server to shut down..... done
server stopped
2021-03-01 13:30:13 DB on "[192.168.7.249]" stop success.
2021-03-01 13:30:13 begin to stop DB on "[192.168.7.248]".
waiting for server to shut down.... done
server stopped
2021-03-01 13:30:14 DB on "[192.168.7.248]" stop success.
2021-03-01 13:30:14 Done.
2021-03-01 13:30:14 Ready to start all DB ...
2021-03-01 13:30:14 begin to start DB on "[192.168.7.248]".
waiting for server to start.... done
server started
2021-03-01 13:30:16 execute to start DB on "[192.168.7.248]" success, connect to check it.
2021-03-01 13:30:17 DB on "[192.168.7.248]" start success.
2021-03-01 13:30:17 Try to ping trusted_servers on host 192.168.7.248 ...
2021-03-01 13:30:19 Try to ping trusted_servers on host 192.168.7.249 ...
2021-03-01 13:30:22 begin to start DB on "[192.168.7.249]".
waiting for server to start.... done
server started
2021-03-01 13:30:23 execute to start DB on "[192.168.7.249]" success, connect to check it.
2021-03-01 13:30:24 DB on "[192.168.7.249]" start success.ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+---------+---------+-----------+----------+----------+----------+----------+-------1 | node248 | primary | * running | | default | 100 | 5 | host=192.168.7.248 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=32 | node249 | primary | ! running | | default | 100 | 4 | host=192.168.7.249 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
WARNING: following issues were detected- node "node249" (ID: 2) is running but the repmgr node record is inactive
2021-03-01 13:30:24 There are more than one primary DBs([2] DBs are running), will do nothing and exit
如上所示:集群在启动过程中,出现“双主”的故障,对于“双主”故障,需要人工参与,判断集群中那个节点是最新的主库,重新恢复集群。
2、查看原备库数据库服务
node2 (原主库):
[kingbase@node2 bin]$ ./repmgr cluster showID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+---------+---------+----------------------+----------+----------+----------+--------1 | node248 | standby | ! running as primary | | default | 100 | 5 | host=192.168.7.248 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=32 | node249 | primary | * running | | default | 100 | 4 | host=192.168.7.249 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
WARNING: following issues were detected- node "node248" (ID: 1) is running as primary but the repmgr node record is inactive
三、查看控制文件对比节点数据差异
node1:
[kingbase@node1 bin]$ ./sys_controldata -D ../data
sys_control version number: 1201
Catalog version number: 201909212
Database system identifier: 6950158917747347623
Database cluster state: in production
sys_control last modified: Mon 01 Mar 2021 01:35:16 PM CST
Latest checkpoint location: 1/F2008980
Latest checkpoint's REDO location: 1/F2008948
Latest checkpoint's REDO WAL file: 0000000500000001000000F2
Latest checkpoint's TimeLineID: 5
Latest checkpoint's PrevTimeLineID: 5
Latest checkpoint's full_page_writes: on
Latest checkpoint's NextXID: 0:8813
Latest checkpoint's NextOID: 32951
Latest checkpoint's NextMultiXactId: 1
Latest checkpoint's NextMultiOffset: 0
Latest checkpoint's oldestXID: 839
Latest checkpoint's oldestXID's DB: 1
Latest checkpoint's oldestActiveXID: 8813
Latest checkpoint's oldestMultiXid: 1
Latest checkpoint's oldestMulti's DB: 1
Latest checkpoint's oldestCommitTsXid:0
Latest checkpoint's newestCommitTsXid:0
Time of latest checkpoint: Mon 01 Mar 2021 01:35:16 PM CST
node2:
[kingbase@node2 bin]$ ./sys_controldata -D ../data
sys_control version number: 1201
Catalog version number: 201909212
Database system identifier: 6950158917747347623
Database cluster state: in production
sys_control last modified: Mon 01 Mar 2021 01:34:45 PM CST
Latest checkpoint location: 1/F2002AC0
Latest checkpoint's REDO location: 1/F2002A88
Latest checkpoint's REDO WAL file: 0000000400000001000000F2
Latest checkpoint's TimeLineID: 4
Latest checkpoint's PrevTimeLineID: 4
Latest checkpoint's full_page_writes: on
Latest checkpoint's NextXID: 0:8810
Latest checkpoint's NextOID: 32951
Latest checkpoint's NextMultiXactId: 1
Latest checkpoint's NextMultiOffset: 0
Latest checkpoint's oldestXID: 839
Latest checkpoint's oldestXID's DB: 1
Latest checkpoint's oldestActiveXID: 8810
Latest checkpoint's oldestMultiXid: 1
Latest checkpoint's oldestMulti's DB: 1
Latest checkpoint's oldestCommitTsXid:0
Latest checkpoint's newestCommitTsXid:0
Time of latest checkpoint: Mon 01 Mar 2021 01:34:45 PM CST
从control文件对比可以获知,新主库的timeline(5)高于原主库timeline(4),并且新主库的事务id:8813高于原主库事务id:8810,故选择新主库作为集群的primary节点,原主库被standby。
注意:对于选择主库的判断,最好能在启动数据库,连接到业务上进行判断,那个主机数据是最新的。
四、将原主库重新加入到集群
node2 rejoin 到集群:
[kingbase@node2 bin]$ ./sys_ctl stop -D ../data
waiting for server to shut down.... done
server stopped
[kingbase@node2 bin]$ ./repmgr node rejoin -h 192.168.7.248 -U esrep -d esrep
ERROR: this node cannot attach to rejoin target node 1
DETAIL: rejoin target server's timeline 5 forked off current database system timeline 4 before current recovery point 1/F2002B70
HINT: use --force-rewind to execute sys_rewind
[kingbase@node2 bin]$ ./repmgr node rejoin -h 192.168.7.248 -U esrep -d esrep --force-rewind
NOTICE: sys_rewind execution required for this node to attach to rejoin target node 1
DETAIL: rejoin target server's timeline 5 forked off current database system timeline 4 before current recovery point 1/F2002B70
NOTICE: executing sys_rewind
DETAIL: sys_rewind command is "/home/kingbase/cluster/R6HA/KHA/kingbase/bin/sys_rewind -D '/home/kingbase/cluster/R6HA/KHA/kingbase/data' --source-server='host=192.168.7.248 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3'"
sys_rewind: servers diverged at WAL location 1/F20000D8 on timeline 4
sys_rewind: rewinding from last common checkpoint at 1/F2000060 on timeline 4
sys_rewind: find last common checkpoint start time from 2021-03-01 14:06:28.539405 CST to 2021-03-01 14:06:28.577794 CST, in "0.038389" seconds.
sys_rewind: update the control file: minRecoveryPoint is '1/F2031590', minRecoveryPointTLI is '5', and database state is 'in archive recovery'
sys_rewind: we will remove the dir '/home/kingbase/cluster/R6HA/KHA/kingbase/data/sys_replslot/repmgr_slot_1.rewind' and all the file/dir in it.
sys_rewind: we will remove the dir '/home/kingbase/cluster/R6HA/KHA/kingbase/data/base/syssql_tmp.rewind' and all the file/dir in it.
sys_rewind: rewind start wal location 1/F2000060 (file 0000000400000001000000F2), end wal location 1/F2031590 (file 0000000500000001000000F2). time from 2021-03-01 14:06:28.539405 CST to 2021-03-01 14:06:44.221603 CST, in "15.682198" seconds.
sys_rewind: Done!
NOTICE: 0 files copied to /home/kingbase/cluster/R6HA/KHA/kingbase/data
NOTICE: setting node 2's upstream to node 1
WARNING: unable to ping "host=192.168.7.249 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3"
DETAIL: PQping() returned "PQPING_NO_RESPONSE"
NOTICE: begin to start server at 2021-03-01 14:06:44.800564
NOTICE: starting server using "/home/kingbase/cluster/R6HA/KHA/kingbase/bin/sys_ctl -w -t 90 -D '/home/kingbase/cluster/R6HA/KHA/kingbase/data' -l /home/kingbase/cluster/R6HA/KHA/kingbase/bin/logfile start"
NOTICE: start server finish at 2021-03-01 14:06:46.217825
NOTICE: NODE REJOIN successful
DETAIL: node 2 is now attached to node 1
查看集群节点状态:
[kingbase@node2 bin]$ ./repmgr cluster showID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+---------+---------+-----------+----------+----------+----------+----------+--------1 | node248 | primary | * running | | default | 100 | 5 | host=192.168.7.248 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=32 | node249 | standby | running | node248 | default | 100 | 4 | host=192.168.7.249 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
查看主备流复制状态:
[kingbase@node1 bin]$ ./ksql -U system test
ksql (V8.0)
Type "help" for help.
test=# select * from sys_stat_replication;pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_s
tart | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_la
g | replay_lag | sync_priority | sync_state | reply_time
-------+----------+---------+------------------+---------------+-----------------+-------22853 | 16384 | esrep | node249 | 192.168.7.249 | | 38638 | 2021-03-01 14:07:
24.293687+08 | | streaming | 1/F20357A8 | 1/F20357A8 | 1/F20357A8 | 1/F20357A8 | | | | 0 | async | 2021-03-01 14:07:57.851500+08
(1 row)
五、重新启动集群测试
[kingbase@node1 bin]$ ./sys_monitor.sh restart
2021-03-01 14:09:05 Ready to stop all DB ...
There is no service "node_export" running currently.
There is no service "postgres_ex" running currently.
There is no service "node_export" running currently.
There is no service "postgres_ex" running currently.
2021-03-01 14:09:10 begin to stop repmgrd on "[192.168.7.248]".
2021-03-01 14:09:11 repmgrd on "[192.168.7.248]" already stopped.
2021-03-01 14:09:11 begin to stop repmgrd on "[192.168.7.249]".
2021-03-01 14:09:11 repmgrd on "[192.168.7.249]" already stopped.
2021-03-01 14:09:11 begin to stop DB on "[192.168.7.249]".
waiting for server to shut down.... done
server stopped
2021-03-01 14:09:13 DB on "[192.168.7.249]" stop success.
2021-03-01 14:09:13 begin to stop DB on "[192.168.7.248]".
waiting for server to shut down...... done
server stopped
2021-03-01 14:09:16 DB on "[192.168.7.248]" stop success.
2021-03-01 14:09:16 Done.
2021-03-01 14:09:16 Ready to start all DB ...
2021-03-01 14:09:16 begin to start DB on "[192.168.7.248]".
waiting for server to start.... done
server started
2021-03-01 14:09:17 execute to start DB on "[192.168.7.248]" success, connect to check it.
2021-03-01 14:09:19 DB on "[192.168.7.248]" start success.
2021-03-01 14:09:19 Try to ping trusted_servers on host 192.168.7.248 ...
2021-03-01 14:09:21 Try to ping trusted_servers on host 192.168.7.249 ...
2021-03-01 14:09:24 begin to start DB on "[192.168.7.249]".
waiting for server to start.... done
server started
2021-03-01 14:09:25 execute to start DB on "[192.168.7.249]" success, connect to check it.
2021-03-01 14:09:26 DB on "[192.168.7.249]" start success.ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+---------+---------+-----------+----------+----------+----------+----------+-------1 | node248 | primary | * running | | default | 100 | 5 | host=192.168.7.248 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=32 | node249 | standby | running | node248 | default | 100 | 5 | host=192.168.7.249 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
2021-03-01 14:09:26 The primary DB is started.
2021-03-01 14:09:31 Success to load virtual ip [192.168.7.240/24] on primary host [192.168.7.248].
2021-03-01 14:09:31 Try to ping vip on host 192.168.7.248 ...
2021-03-01 14:09:33 Try to ping vip on host 192.168.7.249 ...
2021-03-01 14:09:36 begin to start repmgrd on "[192.168.7.248]".
[2021-03-01 14:09:37] [NOTICE] using provided configuration file "/home/kingbase/cluster/R6HA/KHA/kingbase/bin/../etc/repmgr.conf"
[2021-03-01 14:09:37] [NOTICE] redirecting logging output to "/home/kingbase/cluster/R6HA/KHA/kingbase/hamgr.log"
2021-03-01 14:09:37 repmgrd on "[192.168.7.248]" start success.
2021-03-01 14:09:37 begin to start repmgrd on "[192.168.7.249]".
[2021-03-01 14:09:00] [NOTICE] using provided configuration file "/home/kingbase/cluster/R6HA/KHA/kingbase/bin/../etc/repmgr.conf"
[2021-03-01 14:09:00] [NOTICE] redirecting logging output to "/home/kingbase/cluster/R6HA/KHA/kingbase/hamgr.log"
2021-03-01 14:09:38 repmgrd on "[192.168.7.249]" start success.ID | Name | Role | Status | Upstream | repmgrd | PID | Paused? | Upstream last seen
----+---------+---------+-----------+----------+---------+-------+---------+--------------------1 | node248 | primary | * running | | running | 24725 | no | n/a 2 | node249 | standby | running | node248 | running | 23587 | no | n/a
2021-03-01 14:09:46 Done.
查看集群节点状态:
[kingbase@node1 bin]$ ./repmgr cluster showID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+---------+---------+-----------+----------+----------+----------+----------+--------1 | node248 | primary | * running | | default | 100 | 5 | host=192.168.7.248 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=32 | node249 | standby | running | node248 | default | 100 | 5 | host=192.168.7.249 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3