今天遇到一个很奇怪的bug, 当今天跑covid_atlas数据集的时候,在123服务器总是报错,但是我记得在122服务器上是跑过没问题的
最终的测试结果如下
import scanpy as sc
import numpy as np
from QUEST import QUEST
from QUEST.utils import get_free_gpu
import torch dataset_path ="/home/DATA1/zhangjingxiao/yxk/datasets/covid_atlas/covid_atlas_raw.h5ad"
adata=sc.read(dataset_path)
print("....................................data preprocessing.............................................")
sc.pp.filter_genes(adata, min_counts=1)
sc.pp.filter_cells(adata, min_counts=1)
sc.pp.normalize_per_cell(adata,counts_per_cell_after=1e4)
adata.obs['size_factors'] = adata.obs.n_counts / np.median(adata.obs.n_counts)
sc.pp.log1p(adata)
sc.pp.highly_variable_genes(adata,n_top_genes=1000,subset=True,inplace=True)#
sc.pp.scale(adata,max_value=10.0)
sc.tl.pca(adata)# if torch.cuda.is_available():
# free_gpu_id = get_free_gpu()
# device = torch.device("cuda:"+str(free_gpu_id))
# else:
# device = torch.device("cpu")
# #print(free_gpu_id)
# #torch.cuda.set_device(free_gpu_id)
# #device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# quest=QUEST(adata,batch_name="BATCH",hidden_size=[64,32],num_epochs=10,batch_size = 256,save_dir="./Log/",device = device)
# quest.train()# adata0=quest.adata
# print(adata0)
# adata0.obsm["X_emb"]= adata.obsm["X_QUEST"].copy()
# sc.pp.neighbors(adata0, use_rep="X_QUEST")
# sc.tl.umap(adata0)
# #sc.tl.louvain(adata0,resolution=1.0)
# sc.pl.umap(adata0, color=["celltype","BATCH"],show=False)
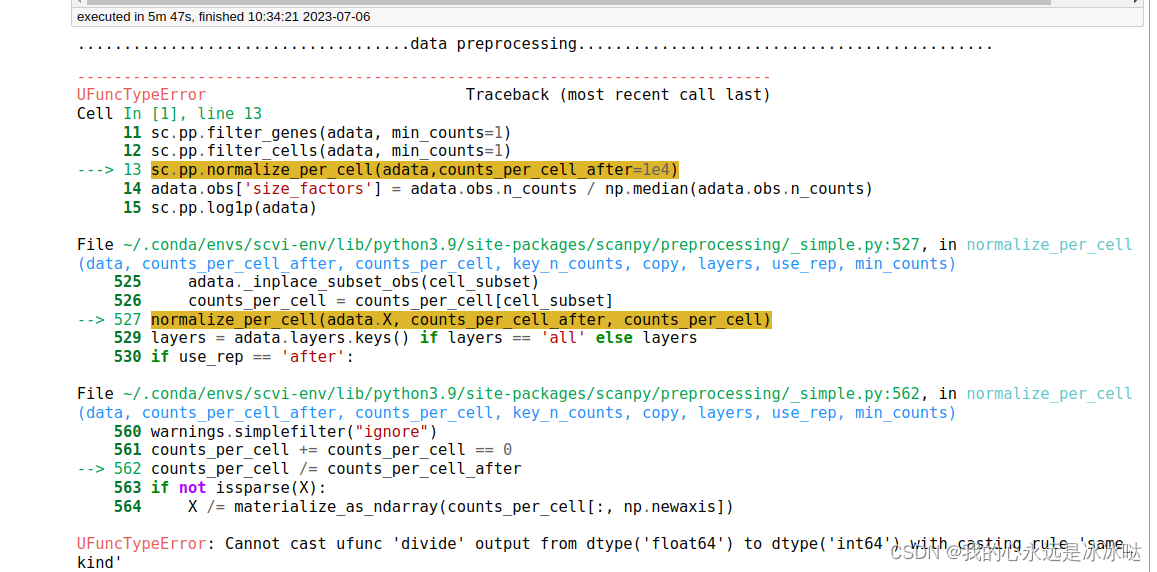
test dataset1
import scanpy as sc
import torch
import numpy as np
from scipy.sparse import issparse
import matplotlib.pyplot as plt
from QUEST.utils import seed_torch
from QUEST import QUEST
from QUEST.preprocess import read_dataset,normalize
from QUEST.utils import evaluation_batch_mixingdataset="covid_atlas"
datatype="multi" #dataset_path ="/home/DATA1/zhangjingxiao/yxk/datasets/covid_atlas/covid_atlas_raw.h5ad"
adata=sc.read(dataset_path)
#adata = sc.read("/DATA2/zhangjingxiao/yxk/dataset/covid_atlas/adata_clean.h5ad")
adata.obs["BATCH"] = adata.obs["sampleID"].copy()
sc.pp.normalize_total(adata,target_sum=1e4)
sc.pp.log1p(adata)
sc.pp.highly_variable_genes(adata,n_top_genes=1000,subset=True)
sc.pp.scale(adata)
sc.tl.pca(adata)print("calculate PCA done....")
结果如下
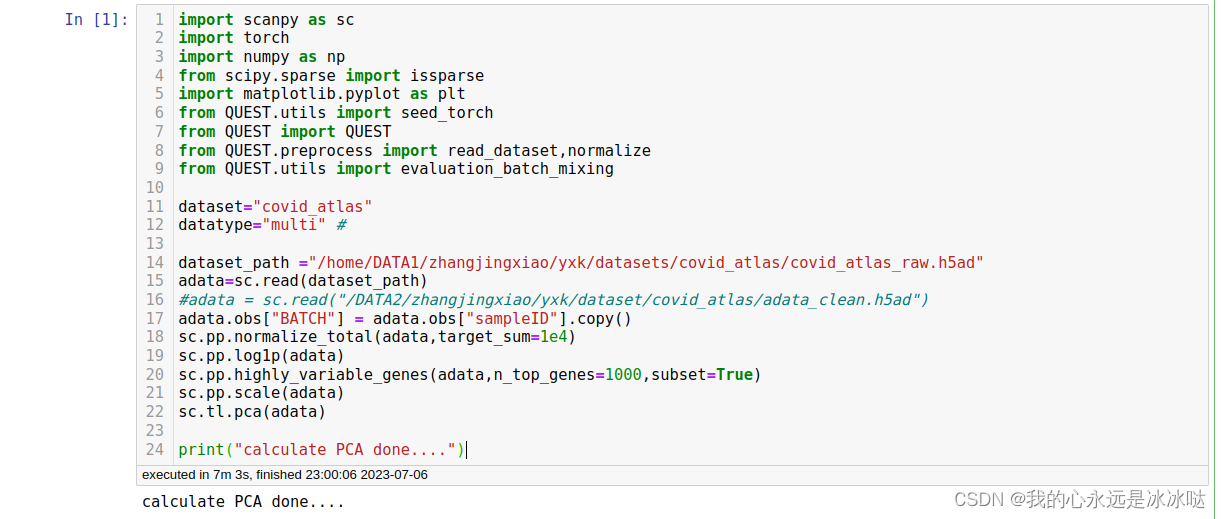
test dataset2
测试
sc.pp.filter_genes(adata, min_counts=1)
sc.pp.filter_cells(adata, min_counts=1)
import scanpy as sc
import torch
import numpy as np
from scipy.sparse import issparse
import matplotlib.pyplot as plt
from QUEST.utils import seed_torch
from QUEST import QUEST
from QUEST.preprocess import read_dataset,normalize
from QUEST.utils import evaluation_batch_mixingdataset="covid_atlas"
datatype="multi" #dataset_path ="/home/DATA1/zhangjingxiao/yxk/datasets/covid_atlas/covid_atlas_raw.h5ad"
adata=sc.read(dataset_path)
#adata = sc.read("/DATA2/zhangjingxiao/yxk/dataset/covid_atlas/adata_clean.h5ad")
adata.obs["BATCH"] = adata.obs["sampleID"].copy()
sc.pp.filter_genes(adata, min_counts=1)
sc.pp.filter_cells(adata, min_counts=1)sc.pp.normalize_total(adata,target_sum=1e4)
sc.pp.log1p(adata)
sc.pp.highly_variable_genes(adata,n_top_genes=1000,subset=True)
sc.pp.scale(adata)
sc.tl.pca(adata)print("calculate PCA done....")
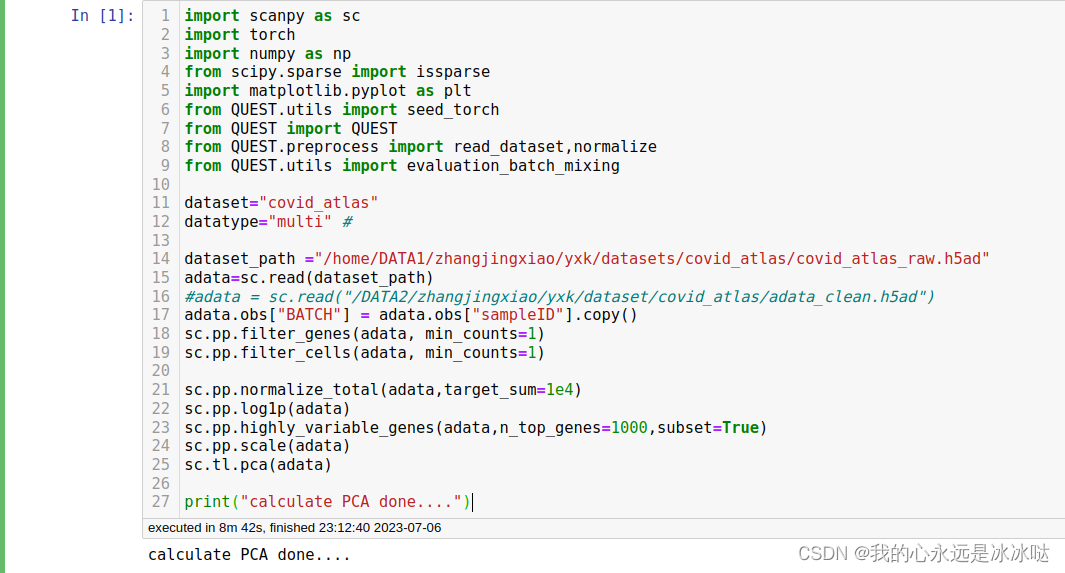
test dataset3((sc.pp.normalize_per_cell_))
import scanpy as sc
import torch
import numpy as np
from scipy.sparse import issparse
import matplotlib.pyplot as plt
from QUEST.utils import seed_torch
from QUEST import QUEST
from QUEST.preprocess import read_dataset,normalize
from QUEST.utils import evaluation_batch_mixingdataset="covid_atlas"
datatype="multi" #dataset_path ="/home/DATA1/zhangjingxiao/yxk/datasets/covid_atlas/covid_atlas_raw.h5ad"
adata=sc.read(dataset_path)
#adata = sc.read("/DATA2/zhangjingxiao/yxk/dataset/covid_atlas/adata_clean.h5ad")
adata.obs["BATCH"] = adata.obs["sampleID"].copy()
sc.pp.filter_genes(adata, min_counts=1)
sc.pp.filter_cells(adata, min_counts=1)sc.pp.normalize_per_cell(adata,counts_per_cell_after=1e4)
sc.pp.log1p(adata)
sc.pp.highly_variable_genes(adata,n_top_genes=1000,subset=True)
sc.pp.scale(adata)
sc.tl.pca(adata)print("calculate PCA done....")
结果如下
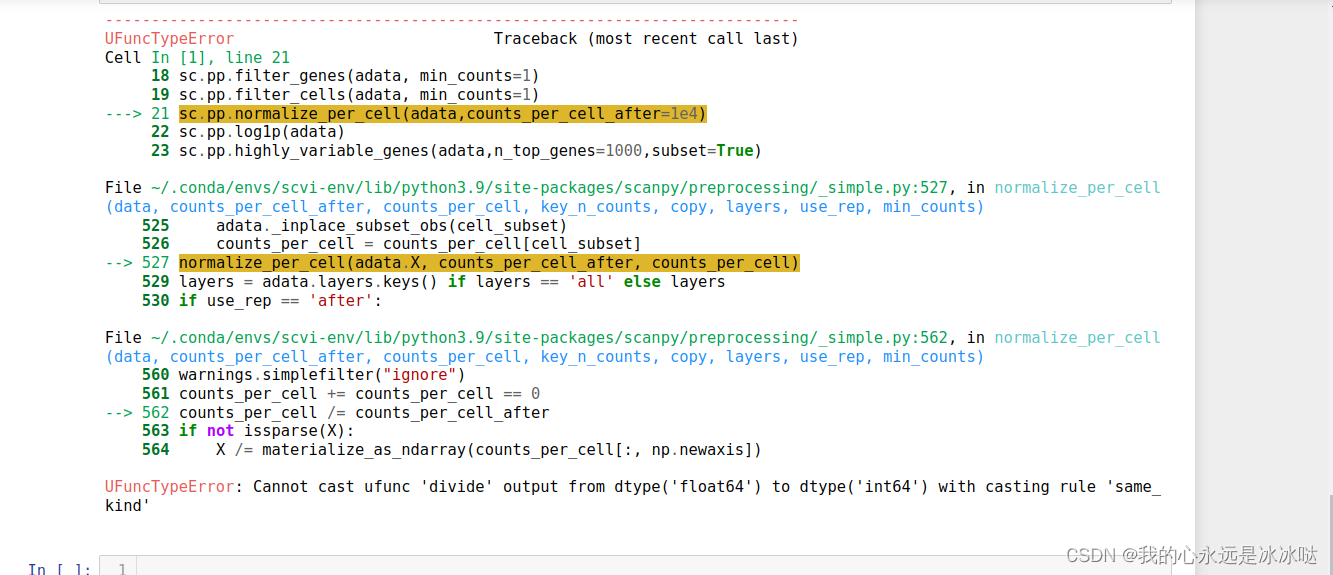
总而言之,最终的问题在于
sc.pp.normalize_total(adata,target_sum=1e4)
与
sc.pp.normalize_per_cell(adata,counts_per_cell_after=1e4)
其中使用
sc.pp.normalize_total(adata,target_sum=1e4)
不报错,但是使用
sc.pp.normalize_per_cell(adata,counts_per_cell_after=1e4)
就会报错,值得注意