Problem - 1234D - Codeforces
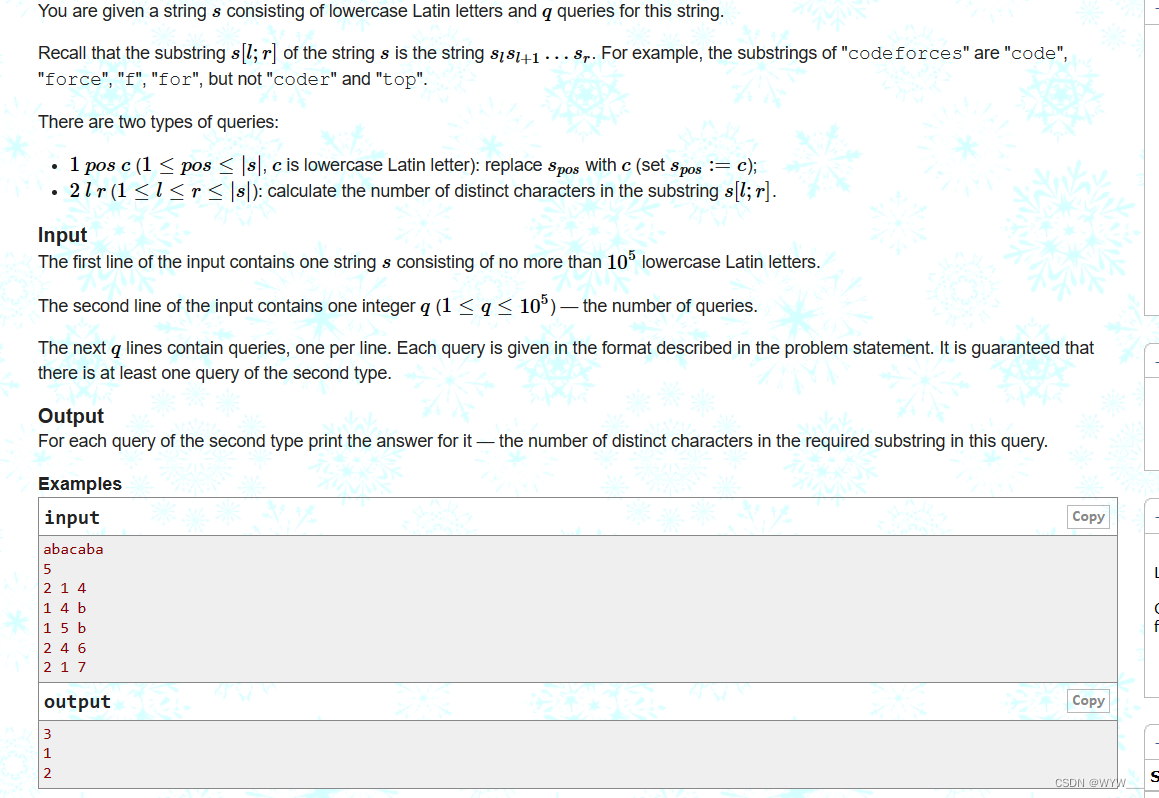
给你一个由小写拉丁字母组成的字符串s和对这个字符串的q个查询。
回顾一下,字符串s的子串s[l;r]就是字符串slsl+1...sr。例如,"codeforces "的子串是 "code"、"force"、"f"、"for",但不是 "coder "和 "top"。
有两种类型的查询。
1 pos c (1≤pos≤|s|,c为小写拉丁字母):用c替换 spos (set spos:=c)。
2 l r (1≤l≤r≤|s|):计算子串s[l;r]中不同字符的数量。
输入
输入的第一行包含一个由不超过105个小写拉丁字母组成的字符串s。
输入的第二行包含一个整数q(1≤q≤105)--查询的数量。
接下来的q行包含查询,每行一个。每个查询都是按照问题陈述中描述的格式给出的。保证至少有一个第二种类型的查询。
输出
对于每一个第二种类型的查询,打印出它的答案--在这个查询中所要求的子串中的明显字符数。
例子
inputCopy
abacaba
5
2 1 4
1 4 b
1 5 b
2 4 6
2 1 7
输出拷贝
3
1
2
输入拷贝
dfcbbcfeeedbaea
15
1 6 e
1 4 b
2 6 14
1 7 b
1 12 c
2 6 8
2 1 6
1 7 c
1 2 f
1 10 a
2 7 9
1 10 a
1 14 b
1 1 f
2 1 11
输出拷贝
5
2
5
2
6
题解:
用set存储每个字母的下标
每次要修改时就把当前s[i]的中的下标删去
再把要修改的字母把下标插入
更改此时的s[i] = c
如果要查询,我们直接进性26次二分找存储在当前字母中的下标是在l~r内
注意set.end()并不是存储数的最后一位
#include<iostream>
#include<algorithm>
#include<string>
#include<queue>
#include<vector>
#include<map>
#include<cstring>
#include<cmath>
#include<set>
using namespace std;
#define int long long
typedef pair<int,int> PII;
char a[200050];
set<int> st[27];
void solve()
{cin >> a+1;int n = strlen(a+1);for(int i =1;i <= n;i++){st[a[i]-'a'].insert(i);}int q;cin >> q;while(q--){int p ;cin >>p;if(p == 1){int x;char c;cin >> x >> c;st[a[x]-'a'].erase(x);st[c-'a'].insert(x);a[x] = c; }else{int l,r;cin >> l >> r;int s = 0;for(int j = 0;j < 26;j++){auto p = st[j].lower_bound(l);if(p!=st[j].end()&&*p <= r){s ++;}}cout << s<<"\n";}}
}
//cbc cbb
//7 3 1
//6 5 4
signed main(){
// ios::sync_with_stdio(false);
// cin.tie(0);
// cout.tie(0);int t = 1;
// cin >> t;while(t--){solve();}
}
//5
//2 4 6 8 10 7 9 5 3 1
//1 3 5 7 9 6 8 4 2
//2 4 1 3