sqlplus /nolog
conn / as sysdba
select TABLE_NAME from all_tables where TABLE_NAME LIKE ‘CISS_%’;
hadoop
jps
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
node1:50070
node1:8088
node1:19888
centos:7 hadoop 19888,8088,50070
hadoop:2.7.0 hive
ps -ef | grep hive
jps
beeline
!connect jdbc:hive2://hive.bigdata.cn:10000
root
123456
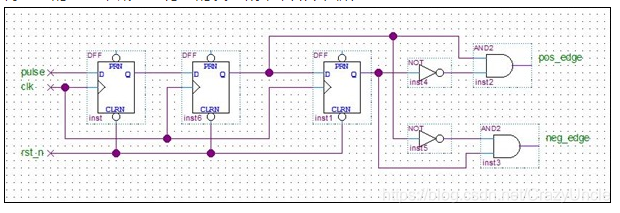
shuffle 三种场景
重分区: repartition: 分区个数有小变大
调用分区器对所有数据进行重新分区
rdd1: part0 part1
!quite
spark
jps
historyServer
sparksubmit
source /etc/profile
启动thrift server
start-thriftserver.sh --name sparksql-thrift-server --master yarn --deploy-mode client --driver-memory 1g --hiveconf hive.server2.thrift.http.port=10001 --num-executors 3 --executor-memory 1g --conf spark.sql.shuffle.partitions=2
beeline -u jdbc:hive2://spark.bigdata.cn:10001 -n root -p 123456
select explode(split(line,“\s+”)) from word1;
select count(1);
sparksql
hive
mysql
oracle
sqoop
docker exec -it sqoop bash
列举所有的库
sqoop list-databases --connect jdbc:oracle:thin:@oracle.bigdata.cn:1521:helowin
– username ciss --password 123456
hadoop:2.7.0 spark 7077 4040 8080 10001
hadoop:2.7.0 sqoop
hadoop:2.7.0 hive 10000:10000
centos:7 hodoop 50070 19888 8088
hive-2.1.0
hive-2.1.0-spark
hive: hiveserver2负责解析sql语句
hiveserver:作为meta store的客户端
Metastore作为HiveServer的服务端
sparkSQL:向meta Store服务(9083)
ThriftServer:负责解析sql语句转换为SparkCore程序
放入hive-site.xml 文件到Spark的conf目录的目的:
让SparkSQL能够访问Hive的元素据服务的服务地址:为了访问hive
启动ThriftServer
先启动hadoop
hive ->MetaStore提供给SparkSQL
spark
cs模式:先启动服务端,再启动客户端
find / -name hadoop-env.sh