总结:本节课讲解了一些会在lab2中使用到的go的多线程技巧,会给一些简单的demo,lab2中可能会借鉴这些demo。
详细的Lab2 raft算法实现源码,请参考我的个人仓库(记得点颗星星), 配合readme食用更佳。
MIT6.824
1 sync.WaitGroup (7.2的channel也能实现这个效果)
sync.WaitGroup用法:如果你有一个任务可以分解成多个子任务进行处理,同时每个子任务没有先后执行顺序的限制,等到全部子任务执行完毕后,再进行下一步处理。这时每个子任务的执行可以并发处理,这种情景下适合使用sync.WaitGroup。
1.1 demo1
1
循环中产生一堆线程的代码:
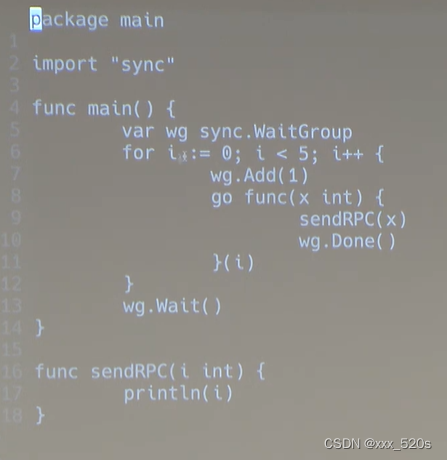
func main() {var wg sync.WaitGroupfor i := 0; i < 5; i++ {wg.Add(1)go func(x int) {sendRPC(x)wg.Done()}(i)}wg.Wait() // 这行代码决定了要等5个协程都执行完毕才能继续往下执行。和println("finished!")}
func sendRPC(i int) {println(i)
}
在rpc中的应用:
以上demo适合raft系统中某一个节点需要并行的向其他所有节点发rpc消息时非常管用。比如一个candidate想要给所有的followers节点发送请求投票的rpc调用,那么这个是很有用,因为投票是一个封锁作业,可能需要一段时间要求所有的followers并行投票。
另一个应用场景是leader节点要讲日志条目发送给所有的从节点(followers)者。
1.2 demo2
1.1中会碰到的坑
func main() {var wg sync.WaitGroupfor i := 0; i < 5; i++ {wg.Add(1)go func() {sendRPC(i)wg.Done()}()}wg.Wait()println("finished!")
}
此时代码运行结果是:
5
5
5
5
5
Q1:为什么呢?
答:首先看课上老师给出的解释:
This i may be mutated by the outer space and the time that the goroutine actually ends up executing the sendRPC method well while the for loop has already changed the value of i.
翻译过来就是这个i可能会被外部空间和协程实际运行完成的时间所改变。因为可能在协程执行到sendRPC的println(i)方法之前,i的值已经被loop所改变。
Q2:为什么外部的i会影响内部?
答:因为这里的i是相当于地址传递(go协程直接操作外部的资源),而1.1中的i作为协程的参数相当于值传递
2 定时任务
2.1 在5s内每隔1s打印一次tick
func main() {time.Sleep(1 * time.Second)println("started:")go periodic()time.Sleep(5 * time.Second) //等待击秒以便观察}func periodic() {for {println("tick:")time.Sleep(1 * time.Second)}
}
2.2 修改某事情
你可能想要定期做某件事情,直到发生某件事才停下来。比如你可能要启动一个raft然后定期发送心跳,但是当我们点击不发送按钮的时候就停止发送所有的心跳。
func main() {time.Sleep(1 * time.Second)println("started:")go periodic()time.Sleep(5 * time.Second) // #A 等待几秒以便观察tickmu.Lock()done = true // 这里可以替换成其他机制,停止发送心跳 // #A2mu.Unlock()println(done) println("canceled")time.Sleep(3 * time.Second) //observe no outputprintln("final")}func periodic() {for {println("tick:")time.Sleep(1 * time.Second)mu.Lock()if done {// #Bprint("done:")println(done)//mu.Unlock() //#Creturn}mu.Unlock()}
}
打印结果:
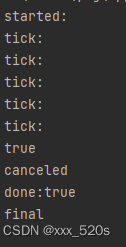
我们把#A代码行注释掉,就会发现打印结果如下:
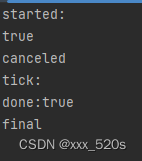
Q1:这是为什么呢?
答:因为主线程和协程是独立的,即使协程执行,主线程还是会继续往下执行不会堵住,#A的time.Sleep(5 * time.Second)实际上是主线程在顺序执行程序,所以会直到5个tick后才会有done=true,而一旦把#A代码行去掉,几乎是主线程和协程几乎同时执行任务,那么很快periodic中if的条件就会满足,所以此时打印的tick次数会减少。
Q2:为什么要对#B处的if代码块加锁和解锁(即对读取done的状态也加锁)?
答:因为如果不对#B处的代码加锁,则#B读取的可能是 #A2处修改之前的值,加锁之后就能确保读取的一定是修改完成的值,
Q3:有了写锁不就可以了吗,为什么还要把读操作给加锁?
答:视频里说的锁是high-level概念,必须使读和写共同加入到争夺锁的圈子内才能使得写操作和读操作都在锁下正常工作,如果只在写的地方加锁不在读的地方加锁,则对于读操作来说,因为他没有加入这个圈子,锁是束缚不了他们的。
这里很类似"select … for update"和普通的select语句的区别,如果对某一行数据写的时候使用了"update…into…"(这是自带for update写锁的),如果是普通的“select…”语句,则会不受update语句的影响,在update的同时读取这行修改的数据,但是对于加了读锁的"select … for update"语句则会被阻塞住。
Q3:为什么return之后的#C行代码可以注释掉,那么当if条件满足时谁来解锁?
答:因为程序已经完成,所以不会再有后续的协程要来使用这个变量,所以在return之前解锁与否不重要,但是为了程序的简洁把这个给去掉
Q4:对于periodic方法,有没有更简单的版本呢?
func periodic() {for !rf.killed { // 当一个实例被包裹时,实例还没有死,你想定期处理一些问题,这里的rf.killed就是rf实例对应的状态println("tick:")time.Sleep(1 * time.Second)}
}
2.3 会产生死锁的版本
func main() {time.Sleep(1 * time.Second)println("started:")go periodic()time.Sleep(5 * time.Second) //#A等待几秒以便观察tickmu.Lock()done = truemu.Unlock()println(done)println("canceled")time.Sleep(3 * time.Second) //observe no outputprintln("final")}func periodic() {for {println("tick:")time.Sleep(1 * time.Second)mu.Lock()if !done { // #Bprint("done:") println(done)return}mu.Unlock()}
}
这个版本仅仅与2.2的版本差在#B行上,为什么这里会导致死锁呢?
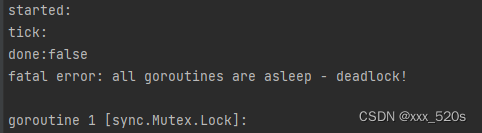
答:因为在
3 不同的解锁方式
3.1 正常的解锁方式
var cnt int
func main() {for i := 0; i < 1000; i++ {go func() {mu.Lock()cnt++mu.Unlock()}()}time.Sleep(1 * time.Second)println(cnt)}
这种解锁方式有什么缺点:
1 当加的锁很麻烦且层级嵌套时,可能会忘记解锁或者解锁的地方不对
3.2 defer关键字解锁
var cnt int
func main() {for i := 0; i < 1000; i++ {go func() {mu.Lock()defer mu.Unlock()cnt++}()}time.Sleep(1 * time.Second)println(cnt)}
1 除了简化资源回收,还有什么好处呢?
答:主要指安全相关的

4 由转账时的不变性延伸至锁的粒度(或者说一致性范围,或者说确定不变量)
4.1 缺陷代码
确定锁需要保护的不变量是确定锁粒度的关键。
下面是一个Alice给Bob转账的程序,在转账之后:
func main() {alice := 10000bob := 10000var mu sync.Mutextotal := alice + bob// go1go func() {for i := 0; i < 1000; i++ {mu.Lock()alice -= 1mu.Unlock()// #Amu.Lock()bob += 1mu.Unlock()}}()// go2go func() {for i := 0; i < 1000; i++ {mu.Lock()bob -= 1mu.Unlock()// #Bmu.Lock()alice += 1mu.Unlock()}}()// 观测协程,用于Alice和Bob的协程在转账时观测他们的账户总额是否不变start := time.Now()for time.Since(start) < 1*time.Second {mu.Lock()if alice+bob != total {fmt.Printf("observed variable, alice=%v, bob=%v, sum=%v\n", alice, bob, bob+alice)}mu.Unlock()}fmt.Printf("final observed variable, alice=%v, bob=%v, sum=%v\n", alice, bob, bob+alice)
}
打印结果:
observed variable, alice=9999, bob=10000, sum=19999
observed variable, alice=9999, bob=10000, sum=19999
observed variable, alice=9999, bob=10000, sum=19999
observed variable, alice=9999, bob=10000, sum=19999
.... //省略中间的一些数据
....
....
observed variable, alice=10401, bob=9598, sum=19999
observed variable, alice=10401, bob=9598, sum=19999
observed variable, alice=10401, bob=9598, sum=19999
observed variable, alice=10401, bob=9598, sum=19999
observed variable, alice=10401, bob=9598, sum=19999
observed variable, alice=10401, bob=9598, sum=19999
observed variable, alice=10401, bob=9598, sum=19999
observed variable, alice=10401, bob=9598, sum=19999
observed variable, alice=10401, bob=9598, sum=19999
observed variable, alice=10401, bob=9598, sum=19999
observed variable, alice=10401, bob=9598, sum=19999
observed variable, alice=10401, bob=9598, sum=19999
observed variable, alice=10401, bob=9598, sum=19999final observed variable, alice=10000, bob=10000, sum=20000分析:通过以上的打印结果可知,虽然最终能保证bob和alice的账户余额都是不变且总和相加也不变,但是在观测过程中发现这是有问题的,你会发现他们的账户余额之和要么是19999,要么是19998
Q1:为什么呢?
答:因为有可能当Alice给Bob转账协程运行到#A处,Alice账户的余额有9999,但是Bob的账户余额还没有更新,这时go2运行起来,并且读取到Bob的账户还有1w,于是数据不一致就产生了
Q2:解决方案:
答:将整个转账过程使用锁框住,这样在Alice给Bob转账期间,Bob给Alice转账的操作会被锁住,请看4.2
4.2 改进代码
func main() {alice := 10000bob := 10000var mu sync.Mutextotal := alice + bobgo func() {for i := 0; i < 1000; i++ {mu.Lock()alice -= 1//mu.Unlock()//mu.Lock()bob += 1mu.Unlock()}}()go func() {for i := 0; i < 1000; i++ {mu.Lock()bob -= 1//mu.Unlock()//mu.Lock()alice += 1mu.Unlock()}}()start := time.Now()for time.Since(start) < 1*time.Second {mu.Lock()if alice+bob != total {fmt.Printf("observed variable, alice=%v, bob=%v, sum=%v\n", alice, bob, bob+alice)}mu.Unlock()}fmt.Printf("final observed variable, alice=%v, bob=%v, sum=%v\n", alice, bob, bob+alice)}
5 一个可以用于汇总响应计算票数的demo
如果一个candidate向所有的followers发送RequestVote RPC,那么有一个复杂的问题,当candidate并行询问其他的followers时并不希望整个raft系统等待一定时间直到所有的节点在下定决心推举leader之前得到所有人的响应,因为如果有一个candidate节点获得多数票无需这样的等待,此次选举可以结束。
5.1 有协程安全问题的代码段
func main() {rand.Seed(time.Now().UnixNano())count := 0 // 赞成票数为0并且完成为0finished := 0for i := 0; i < 10; i++ { // #Ago func() {vote := requestVote() // 是否获得赞成票if vote {count++}finished++ //计算完成的票数}()}for count < 5 && finished != 10 {// 阻塞住 直到得票数过半或者所有节点都投票完成了但是本节点得票数不足半(也可以过半)}// 计算投票数if count >= 5 {println("received 5+ votes!")} else {println("lost!")}
}
Q1: 以上代码段有没有并发问题?
答:count和finished变量应该受到保护,我们都知道#A处的for循环会开启10个对count自增操作的协程,结合第4部分的分析可知这count会产生并发问题。
5.2 没有并发问题的方法
func main() {var mu sync.Mutexrand.Seed(time.Now().UnixNano())count := 0 // 赞成票数为0并且完成为0finished := 0for i := 0; i < 10; i++ {go func() {vote := requestVote() // 是否获得赞成票mu.Lock()defer mu.Unlock() // 这里相当于#Bif vote {count++}finished++ //计算完成的票数//mu.Unlock() // #B}()}for { // #C// 阻塞住 直到得票数过半或者所有节点都投票完成了但是本节点得票数不足半(也可以过半)mu.Lock()if count >= 5 || finished == 10 {break}mu.Unlock()}if count >= 5 {println("received 5+ votes!")} else {println("lost!")}mu.Unlock()
}
1 这段正确的代码有没有性能上的问题?
答:有,因为在#C处,可能处于忙等状态,会占据一个cpu百分之百的时间
2 有没有改进的代码?
答:请看5.3
5.3 解决忙等问题
1 解决方案一:
如果cpu发现投票还没有结束且自己也没有获得多数票,就当前的协程睡眠一段时间,协程停止工作,这样cpu就会多出一部分空闲时间给予其他协程,这是一个可行的方案
func main() {var mu sync.Mutexrand.Seed(time.Now().UnixNano())count := 0 // 赞成票数为0并且完成为0finished := 0for i := 0; i < 10; i++ {go func() {vote := requestVote() // 是否获得赞成票mu.Lock()defer mu.Unlock() // 这里相当于#Bif vote {count++}finished++ //计算完成的票数//mu.Unlock() // #B}()}for {// 阻塞住 直到得票数过半或者所有节点都投票完成了但是本节点得票数不足半(也可以过半)mu.Lock()if count >= 5 || finished == 10 {break}mu.Unlock()time.Sleep(50 * time.Millisecond) // }if count >= 5 {println("received 5+ votes!")} else {println("lost!")}mu.Unlock()}
Q: 上面代码还有其他问题吗?
答:能解决忙等问题,但是cpu仍然每过50ms就要进行轮询并进行协程切换操作,这仍然是比较花时间的,有没有一种办法能够使得 "只有当自己获得了足够的票数或者已经知道所有的followers节点都投过票"后才进行判断操作呢?答案就是条件变量,可以参考5.4
5.4 基于条件变量彻底解决忙等和轮询问题
以下代码中:如果raft集群有10个followers,则#C到#D之间的代码行10次,这里的cond.Broadcast()相当于java的notifyAll()方法,会唤醒所有该等待队列中的线程,可以看到 sync.NewCond(&mu)的条件是基于mutex锁的,被唤醒的线程会继续执行被该mutex锁锁住的代码块(此代码块要包含wait()方法)
func main() {var mu sync.Mutex // 锁cond := sync.NewCond(&mu) // 条件变量rand.Seed(time.Now().UnixNano())count := 0 // 赞成票数为0并且完成为0finished := 0for i := 0; i < 10; i++ {go func() {vote := requestVote() // 是否获得赞成票mu.Lock()defer mu.Unlock() // 这里相当于#B行if vote {count++}finished++ //计算完成的票数//mu.Unlock() // #Bcond.Broadcast()}()}// #Cmu.Lock()for count < 5 && finished != 10 {cond.Wait() }if count >= 5 {println("received 5+ votes!")} else {println("lost!")}mu.Unlock()// #D
}
Q: 如果requestVote()响应丢失了怎么办呢?此时count计数可能有误
答:这是操作系统层面的问题
5.5 条件变量使用的基本模板

Q:何时使用广播,何时使用信号量?
答:使用信号量的地方都可以使用广播代替,但是信号量效率低
6 go语言的channel
go的通道是一个同步队列,队列中的数据必须另一个被消费了,发送数据的协程才能向通道中写数据然后继续往下执行,否则就会阻塞住写操作。同样必须有另一个协程往通道中发送数据了,接收数据的协程才能执行接收操作并且不被阻塞住。
6.1 会产生deadlock的用法
1 deadlock1
func main() {c := make(chan bool)c <- true<-c
}
说明:往通道c发送数据将一直阻塞直到有别的协程接收
2 deadlock2
func main() {c := make(chan bool)<-cc <- true说明:从c通道中接受数据会一直阻塞直到有别的协程发送数据
从上面两个死锁的case中可以知道,在一个协程中使用通道毫无意义,必须用在多协程环境下,一个协程为了发送后能够继续向下执行,就必须有另一个协程执行接收动作。
6.2 使用通道写一个简单的deadlock 检测器
func main() {go func() {for {}}()c := make(chan bool)c <- true<-c
运行此程序,既不会显示正常结束,也不会显示 “检测到死锁”,看起来就像是挂起来一样
6.3 不会产生deadlock的case
func main() {c := make(chan bool)go func() { // #Atime.Sleep(1 * time.Second)<-c}()start := time.Now()c <- true// 在这行代码执行后,主协程会被阻塞,channel中的数据需要协程#A消费后才能继续向下执行fmt.Printf("send took %v \n", time.Since(start))
}7 通道在raft中的应用
注:在这个raft系统尽量少用channel,可以用共享内存,互斥锁和条件变量来实现会更好
7.1 消息队列
channel的经典场景是生产者和消费者队列,跟操作系统中的一种进程通信方式-消息队列非常像。
func main() {c := make(chan int)for i := 0; i < 4; i++ {// 这四个协程向通道c中写数据的时候是互斥关系,同时间只能有一个向通道中写数据go doWork(c)}//主协程充当消费者,不断从通道中提取数据for {v := <-cprintln(v)}
}
func doWork(c chan int) {for {time.Sleep(time.Duration(rand.Intn(1000)) * time.Millisecond)c <- rand.Int()}
}
7.2 实现waitGroup(1.1的demo)
func main() {finished := make(chan bool)for i := 0; i < 5; i++ {// 这四个协程向通道c中写数据的时候是互斥关系,同时间只能有一个向通道中写数据go func(x int) {sendRpc(x)finished <- true}(i)}//主协程充当消费者,不断从缓冲区中提取数据for i := 0; i < 5; i++ {<-finished}
}
打印结果:
4
0
3
2
1
7.3 通过设置通道大小的方式实现waitGroup
但是不建议这么做,如果对通道不是很了解的话这样很容易产生其他的问题
8 会产生问题的请求投票过程
8.1 会产生死锁的代码(待解决)
package mainimport ("log""sync"_ "sync"
)// 定义基本类型别名
type State stringconst (Follower State = "follower"Candidate = "candidate"Leader = "leader"
)type Raft struct {mu sync.Mutexme intpeers []intstate StatecurrentTerm intvotedFor int
}/*
一个raft实例企图发起一次选举
*/
func (rf *Raft) AttemptElection() {rf.mu.Lock()rf.state = Candidaterf.currentTerm++rf.votedFor = rf.melog.Printf("[%d] attempting an election at term %d...", rf.me, rf.currentTerm)rf.mu.Unlock()for _, server := range rf.peers {if server == rf.me {continue}// 以协程并发式的向peers节点发送rpc调用go func(server int) {voteGranted := rf.callRequestVote(server)if !voteGranted {return}// record the votes}(server)}}func (rf *Raft) callRequestVote(server int) bool {rf.mu.Lock()defer rf.mu.Unlock()log.Printf("[%d] sneding request vote to %d", rf.me, server)args := RequestVoteArgs{Term: rf.currentTerm,CandidateId: rf.me,}var reply RequestVoteReplyok := rf.sendRequestVote(server, &args, &reply)log.Printf("[%d] finish sending request vote to %d", rf.me, server)if !ok {return false}return true
}// example RequestVote RPC arguments structure.
// field names must start with capital letters!
type RequestVoteArgs struct {// Your data here (2A, 2B).
}// example RequestVote RPC reply structure.
// field names must start with capital letters!
type RequestVoteReply struct {// Your data here (2A).
}// example code to send a RequestVote RPC to a server.
// server is the index of the target server in rf.peers[].
// expects RPC arguments in args.
// fills in *reply with RPC reply, so caller should
// pass &reply.
// the types of the args and reply passed to Call() must be
// the same as the types of the arguments declared in the
// handler function (including whether they are pointers).
//
// The labrpc package simulates a lossy network, in which servers
// may be unreachable, and in which requests and replies may be lost.
// Call() sends a request and waits for a reply. If a reply arrives
// within a timeout interval, Call() returns true; otherwise
// Call() returns false. Thus Call() may not return for a while.
// A false return can be caused by a dead server, a live server that
// can't be reached, a lost request, or a lost reply.
//
// Call() is guaranteed to return (perhaps after a delay) *except* if the
// handler function on the server side does not return. Thus there
// is no need to implement your own timeouts around Call().
//
// look at the comments in ../labrpc/labrpc.go for more details.
//
// if you're having trouble getting RPC to work, check that you've
// capitalized all field names in structs passed over RPC, and
// that the caller passes the address of the reply struct with &, not
// the struct itself.
func (rf *Raft) sendRequestVote(server int, args *RequestVoteArgs, reply *RequestVoteReply) bool {ok := rf.peers[server].Call("Raft.RequestVote", args, reply)return ok
}
Q1 为什么会产生死锁呢?
答:官方给的解释大概就是s0和s1分别获取自身锁lock0和lock1之后都尝试发送rpc调用到对方,当s1收到s0的requestVote请求后会给自己再次上锁,前面我们已经知道s1在发送的时候已经,他们会再次尝试获取锁(获取的是什么锁呢),但是他们不能,因为他们已经在获取锁中了并且试图发送rpc调用,这就是为什么出现了死锁。

Q2: s0和s1互相发送rpc时会发生死锁,但是一个Candidate会向所有的Follower节点发送RequestVote,为什么节点s2就没有产生心跳呢?
答:因为有可能s2的选举周期足够长,在s2决定进行一次选举Leader操作之前,它已经收到了节点s0和s1的RequestVote rpc并且做出响应,这意味着在s2发出rpc调用之前已经释放了锁
Q3:每一个raft实例自身都带有一个锁(为什么每一个实例自身都要带一个锁变量呢,目的是什么?)
答:(待定,还得是再看一下sendRequestVote的内部方法)因为raft实例本身就属于资源,有可能开启多个协程并发修改某一个raft实例的参数,这样的就需要raft实例本身自带的锁进行加锁操作,另外要注意sync.Mutex是非重入锁,所以在第二次使用这个锁(handler)之前必须先解锁否则会造成死锁。
Q4:s0.handler和s1.handler是公用同一把锁吗?
答:显然不是,s0和s1的handler分别争用自身的锁
8.2 会在同一时期产生两名leader的选举代码
以下是代码:
/*
一个raft实例企图发起一次选举
*/
func (rf *Raft) AttemptElection() {rf.mu.Lock()rf.state = Candidaterf.currentTerm++rf.votedFor = rf.melog.Printf("[%d] attempting an election at term %d...", rf.me, rf.currentTerm)votes := 1done := falseterm := rf.currentTermrf.mu.Unlock()for _, server := range rf.peers {if server == rf.me {continue}// 以协程并发式的向peers节点发送rpc调用go func(server int) {voteGranted := rf.callRequestVote(server, term)if !voteGranted {return}rf.mu.Lock()defer rf.mu.Unlock()// record the votesvotes++fmt.Printf("[%d] got value from %d", rf.me, server)if done || votes <= len(rf.peers)/2 {return}done = truefmt.Printf("[%d] we got enough votes, we are now the leader(currentTerm=%d)!", rf.me, rf.currentTerm)rf.state = Leader}(server)}
}
分析:从下图跑的结果可以看出,共3个节点,在第一轮选举中,节点0就获取了多数票,但是可能因为网络环境不好,节点1和2的投票结果没有返回给节点0,所以超时后节点1就开启了新一轮的选举,此时term=2,然后在这个任期内,term=1任期的丢失消息又成功到达了节点0,这个时候节点0发现自己已经获得了足够的票数,于是将自己设置成leader节点,但是第二个任期节点1获得了多数票,于是两个leader节点被选出
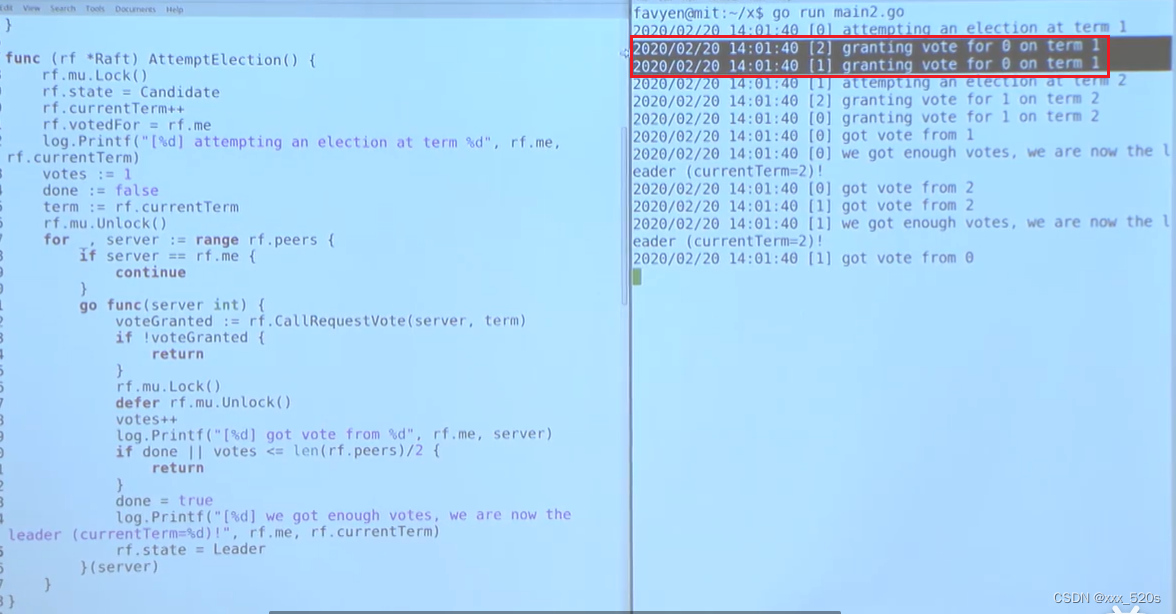
解决方法:
在准备将自己设置成leader前再判断一次自己所出的任期是不是最新的,并且自己的身份是不是candidate
/*
一个raft实例企图发起一次选举
*/
func (rf *Raft) AttemptElection() {rf.mu.Lock()rf.state = Candidaterf.currentTerm++rf.votedFor = rf.melog.Printf("[%d] attempting an election at term %d...", rf.me, rf.currentTerm)votes := 1done := falseterm := rf.currentTermrf.mu.Unlock()for _, server := range rf.peers {if server == rf.me {continue}// 以协程并发式的向peers节点发送rpc调用go func(server int) {voteGranted := rf.callRequestVote(server, term)if !voteGranted {return}rf.mu.Lock()defer rf.mu.Unlock()// record the votesvotes++fmt.Printf("[%d] got value from %d", rf.me, server)if done || votes <= len(rf.peers)/2 {return}done = true// 解决出现多leader问题的判断语句if rf.state != Candidate || rf.currentTerm != term {return}fmt.Printf("[%d] we got enough votes, we are now the leader(currentTerm=%d, state=%v)!", rf.me, rf.currentTerm, rf.state)rf.state = Leader}(server)}}