目录
1、正交化的概念
2、单一数字评估指标(Single number evaluation metric)
3、训练/开发/测试集划分
4、迁移学习
5、多任务学习
6、端到端深度学习
1、正交化的概念
正交化是机器学习中一种常用的数据预处理技术,用于减少特征之间的相关性。在机器学习中,特征之间的相关性可能会导致模型过拟合或者降低模型的性能。正交化的主要目标是通过线性变换将特征向量转化为正交或近似正交的向量。通过正交化,我们可以得到一组新的特征向量,这些特征向量之间是正交的或者近似正交的。这样做可以减少特征之间的相关性,提高模型的性能和稳定性。正交化方法可以通过以下步骤实现:
(1)、中心化:将特征向量的均值移动到原点,这样可以消除特征之间的偏差
(2)、标准化:将特征向量的方差缩放到单位方差,这样可以消除特征之间的尺度差异
(3)、特征向量的协方差矩阵:计算特征向量的协方差矩阵,该矩阵描述了特征之间的相关性
(4)、特征向量的正交化:使用特征向量的协方差矩阵进行特征值分解,得到特征向量的正交基。这些正交基可以作为新的特征向量,用于替换原始的特征向量
2、单一数字评估指标(Single number evaluation metric)
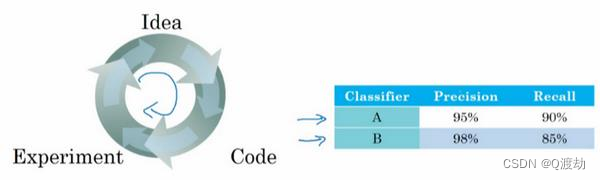
- 𝐴有 95%的查准率,这意味着你的分类器说这图有猫的时候,有 95%的机会是猫
- 查全率 就是,对于所有真猫的图片,你的分类器正确识别出了多少百分比。实际为猫的图片中,有多少被系统识别出来?如果分类器 𝐴 查全率是 90% ,这意味着对于所有的图像,比如说你的开发集都是真的猫图,分类器 𝐴 准确地分辨出了其中的 90%
- 但使用查准率和查全率作为评估指标的时候,有个问题,如果分类器𝐴在查全率上表现更好,分类器𝐵在查准率上表现更好,就无法判断哪个分类器更好,所以此时要找出一个新的评估指标

- 在数学中,这个函数叫做查准率𝑃和查全率𝑅的调和平均数。但非正式来说,你可以将 它看成是某种查准率和查全率的平均值,只不过你算的不是直接的算术平均,而是用这个公式定义的调和平均。这个指标在权衡查准率和查全率时有一些优势

- 但在这个例子中,你可以马上看出,分类器𝐴的𝐹1分数更高。假设𝐹1分数是结合查准率和查全率的合理方式,你可以快速选出分类器𝐴,淘汰分类器𝐵
3、训练/开发/测试集划分
- 开发集和测试集为什么必须来自同一分布
- 如果训练集和测试集来自不同的分布,可能会导致以下问题:
(1)、偏差(Bias):如果训练集和测试集的数据分布不同,模型可能会在测试集上产生较高的
偏差。这意味着模型无法捕捉到测试集中的真实模式和规律
(2)、方差(Variance):如果训练集和测试集的数据分布不同,模型可能会在测试集上产生较
高的方差。这意味着模型过于敏感,无法泛化到测试集中的新样本
(3)、隐含偏见(Implicit Bias):如果训练集和测试集的数据分布不同,模型可能学习到训练集
特有的偏见和规律,而无法适应测试集中的数据
4、迁移学习
- 迁移学习(Transfer Learning)是一种机器学习技术,它利用已经在一个任务上学习到的知识来改善在另一个相关任务上的学习表现。 在深度学习中,迁移学习可以通过复用预训练的神经网络模型的特征层来加速新任务的训练过程。通常情况下,预训练的模型是在大规模的数据集上进行训练的,因此它们可以捕捉到通用的特征表达。通过将这些通用特征应用于新任务,可以避免从头开始训练一个新的深度神经网络,从而节省时间和计算资源。迁移学习在许多应用中都非常有用,尤其是当新任务的数据集较小或者类别之间具有相似性时
- 迁移学习的作用
(1)、加速训练过程:通过利用预训练模型的参数或特征,可以缩短新任务的训练时间,因为预训练模型已经学习到了通用的特征表达
(2)、解决数据不足问题:当新任务的数据集较小或者标注困难时,可以利用预训练模型的知识来提升模型的泛化能力和性能
(3)、避免过拟合:当新任务的数据集较小,如果从零开始训练一个深度神经网络,很容易导致过拟合。而迁移学习可以通过利用预训练模型的参数和特征来减少过拟合的风险
(4)、处理领域转移:当新任务与预训练模型的任务存在一定的相似性时,迁移学习可以将已学习到的知识应用到新任务中,从而提升模型性能
(5)、 提高模型的泛化能力:通过迁移学习,模型可以从大规模数据集中学习到通用的特征表达,使得模型具有更好的泛化能力,可以适应不同的任务和领域
5、多任务学习
(1)、多任务学习(multi-task learning)是一种机器学习方法,通过同时学习多个相关任务来提高整体学习性能。在多任务学习中,模型通过共享底层的特征表示来学习多个任务之间的相关性,从而使得每个任务的学习过程可以互相促进和辅助
(2)、传统的机器学习方法通常只针对单个任务进行建模和训练,但实际问题中往往存在多个相关的任务。多任务学习的目标是通过同时学习多个任务,从中获取更多的信息和知识,提高模型的泛化能力和性能
(3)、多任务学习的优势在于可以通过共享特征学习来提高模型的学习效率和数据利用率。当不同任务之间存在相关性时,多任务学习可以通过共享底层特征的方式进行知识迁移,从而减少对大量标注数据的需求
(4)、多任务学习有多种形式,包括硬共享(hard sharing)、软共享(soft sharing)和共享子空间(shared subspace)等。硬共享指的是多个任务共享相同的底层特征表示,而软共享则是在共享的底层特征表示上学习不同的任务特定的表示。共享子空间则是通过降维的方式将多个任务映射到同一个低维子空间中进行学习
(5)、多任务学习在自然语言处理、计算机视觉、语音识别等领域广泛应用,并取得了很好的效果。它为解决复杂任务提供了一种有效的学习策略,能够充分利用不同任务之间的相关性,提高模型的泛化能力和性能
6、端到端深度学习
(1)、端到端学习(end-to-end learning)是一种机器学习方法,可以直接从原始输入数据到最终输出结果进行学习,省去了手工设计的特征工程步骤。在端到端学习中,模型可以直接从原始数据中学习到高级抽象特征,并通过后续的处理步骤直接输出最终的结果,而无需人为介入
(2)、传统的机器学习方法通常需要手动提取和选择特征,这个过程需要专业知识和大量的人工努力。而端到端学习通过神经网络等深度学习模型的使用,可以自动地从原始数据中学习到适合任务的特征表示。这种端到端的学习方式可以更好地利用数据中的信息,减少了特征工程的复杂性和主观性
(3)、端到端学习的优势在于它能够直接从原始数据中学习到抽象级别较高的特征,从而能够更好地适应不同的任务和数据分布。它可以减少人工设计特征的工作量,并且可以更好地处理复杂任务,如语音识别、图像识别、自然语言处理等
(4)、然而,端到端学习也存在一些挑战。由于模型需要从原始数据中学习到所有的特征表示和模式,模型的复杂度较高,需要更多的训练数据和计算资源。此外,端到端学习可能难以解释学习过程中的特征和决策规则,缺乏可解释性
(5)、尽管存在挑战,端到端学习已经在许多领域取得了重要的突破,成为现代机器学习的一种重要方法。它为解决复杂任务提供了一种直接从数据中学习的方式,使得机器学习更具智能和自动化