本篇是「详解低延时高音质系列」的第四篇技术分享。我们在高音质的基础上,聊聊如何定义好的声音,空间音效是怎样的原理,以及如何在实时场景下利用软件算法实现声音美化、空间音效。最后还有一些音频场景相关的小 Demo,大家可以自行试玩。
随着 5G 的普及和编解码技术的更新,声音的高保真传输已经不再是问题。但随着越来越多的沟通被搬到线上,人们对音频的需求已经从传统的听得到向好听、场景空间还原等更高的需求转变。这次我们聊一聊在实时互动的场景里我们如何让声音更好听、更有空间感。
实时美声:如何炼成好声音?
在日常的生活中我们经常听到人们说“这个男人的声音好有磁性”或者“这个女生的声音好甜美”这样的对好听的声音的赞美。但如果不是“天生丽质“或者经过专业的训练的声优或者播音员,很难把平时说话的声音改变为这些”好听“的感觉。而在平时的聊天、娱乐中,大家又想有个好声音来让大家更愿意甚至乐于听你说话或者唱歌。为了让用户的声音更好听,同时又不会改变原有的声音辨识度,声网Agora 首创了实时美声功能。在原有低延时、高音质的基础上,我们在该功能背后融合了更多声音美化的技术。
首先,为了捕捉到到“好的声音”,我们组建了一个好声音猎手团队,通过对声优、播音演员、歌唱演员、主播等大量好声音数据的特征分析,结合大众对好声音的审美取向和应用场景,对好声音进行了系统的分析。从语音声波产生的声学原理、空间声波传输的空间混响模型;心理学感知模型;韵律、人群差异的语言学等多个角度对什么是好声音、好声音的数学描述特征指标,进行了多个维度的分析并总结出不同种类好声音的一般规律。例如男性的磁性的声音一般在低频和高频能量较高、中频能量较低,温柔的声音往往会具备节奏缓慢、pitch 变化小、咬字模糊等特性。
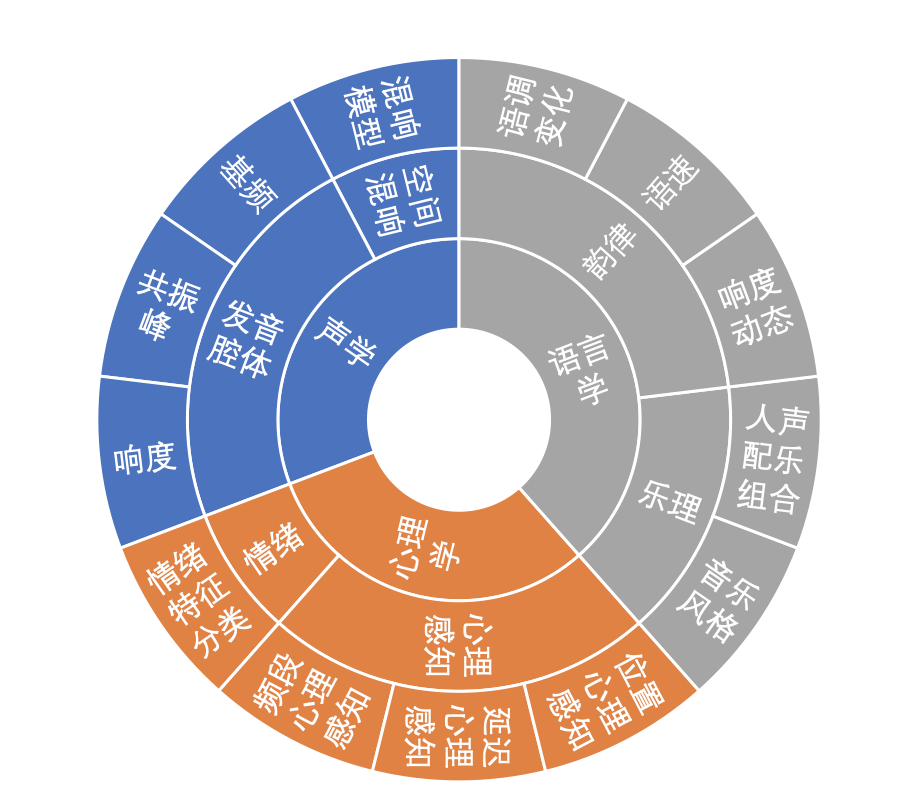
图1:好声音维度图
对于不同的场景,我们提供了针对性的优化。例如,歌唱过程中人们往往希望人声和伴奏的空间感相同,从而使歌声融入伴奏之中,所以需要多种可选的混响效果来对人声做处理。而在平时的聊天中,过度的混响会造成声音浑浊,音效可懂度下降。
再例如,性别的差异。男性声带较长、较宽、较厚,所以振动时频率低,发出的音调也低。女性声带较短、较薄、较窄,所以振动时频率高,发出的音调也高。男女发音生理条件的先天差别决定了发声比例的不同。同时,大众对男女的先入为主的审美也不同,大体上没有人希望男声温婉如玉,女声声如洪钟,所以生理和先入为主的审美决定了男女美声调校方向需要进行差异化处理。
我们把美声的功能分为以下几个方向:
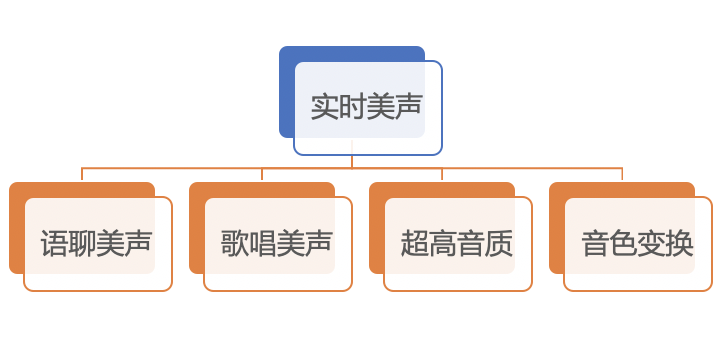
图2:美声分类
语聊美声:适用于语聊场景,实现对声音的美化,同时又不改变原声的辨识度。
歌唱美声:适用于歌唱场景,多维度地对歌声进行调整,使歌声更动听、更契合伴奏,同时又能保留歌手声音原有的特点。
超高音质:更清晰丰富的高音质效果,更加通用并且兼容各种场景,根据心理声学和掩蔽效应,调节声音频率分布,提升听觉体验。
音色变换:在语聊和歌唱场景下,让你的音色朝特定的方向改变。可根据不同的听众,选择不同的效果;或根据自己声音的特点,选择最适合自己的效果。
我们提供了在线试听的美声 Demo,大家可以在线体验到各种美声、音效????https://www.agora.io/cn/audio-demo
实时互动中的空间音效
所谓的空间音效,其实大家在很多场景下都体验过。例如在“吃鸡”一类的游戏中,我们戴上耳机,可以利用声音带来的方位感来判断队友的位置;又或者是在听音乐、在线会议或 VR 应用中,空间音效可以让我们更有身临其境的感觉。
从声学角度讲,空间音效的原理也很简单。人们在现实生活中因为“双耳效应”(依靠双耳间的音量差、时间差和音色差判别声音方位的效应。声音强弱不同时,可感受出声源与听音者之间的距离)可以感知声源的所在的位置。
首先是双耳时差(Interaural time differences, ITD),人耳通过声音到达左右耳的时间差来判断低频声源与人的相对水平位置。声源与左耳或右耳的距离越远,双耳时间差越大。
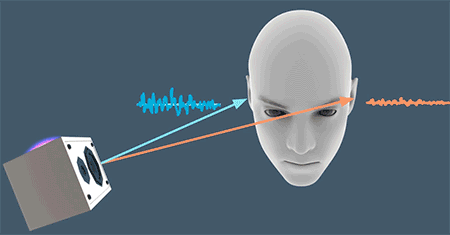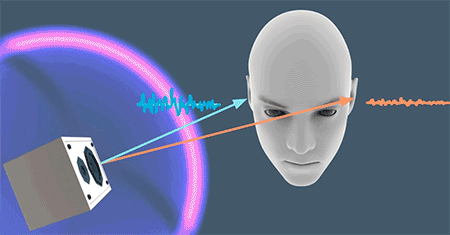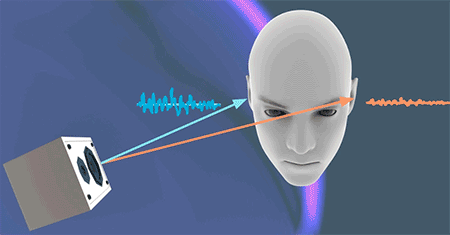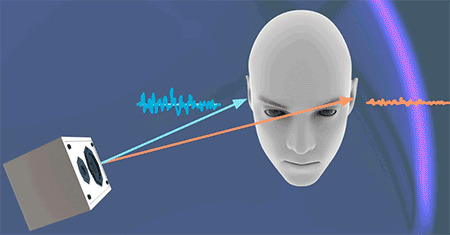
仅仅是通过双耳时差(ITD)还无法判断高频声源的位置,这是因为一些高频的声音会被由于物体遮挡而无法继续传递、扩散,比如人的头部。如上图的情况,左耳能听到的高频的声音就不如右耳“丰富”。这就是双耳水平差(Interaural level differences, ILD)。由于头部带来的声学屏障(acoustic shadow),会让左右耳听到的声音大小与频率产生差别,由此大脑会判断出声源方位。
另外,还有频谱效应(Spectral effects)。声音在到达后会因外耳结构而形成反射,从不同方向来的声音,反射效果也不同,大脑可以根据它来判断声源在垂直方向上的相对方位。
有了双耳时差和双耳水平差判断声源水平位置,然后利用耳廓的反射可以判断声源垂直的位置,大脑就可以判断声音在三维空间中的位置了。
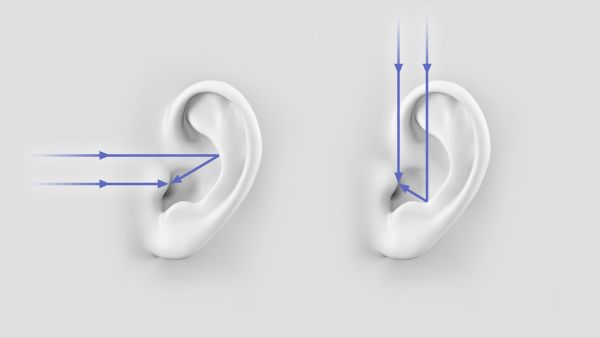
而在实时互动场景中,比如在线会议中,受到音频采集、编解码、以及播放能力的约束,人们只能听清楚远端人在说什么,却无法判断对方在会议室中的位置。如果有多个声源同时发生,比如乐器和人声同时出现,或多人语聊等场景,现场的空间感会显得十分狭小,感觉所有声音都是从一个方向发出来的,无法还原远场原有的听感。长久地听这种没有空间感的声音,人也更容易疲劳,所以有了空间音效来弥补。
空间音频背后的技术可以分成两种:高保真度立体声像复制(Ambisonics)和虚拟立体声(Virtual Stereo)。前者主要利用硬件设备从采集层面实现声场的复刻,再利用播放设备实现声场还原,而后者是将原来采集层面不具备的条件的音频(例如单通道音频)依靠软件算法在播放端来模拟和还原空间感。
首先高保真度立体声像复制 Ambisonics,即将远端中能听到的声音通过立体声录制比如 Ambisonics 话筒(由四个完全相同的话筒单元构成一个立方体阵列)的方式复制下来。如下图,所示的话筒。

图3:一些常见的 Ambisonics 话筒
原始的采集数据我们叫 A-format ,它是无法直接播放的,通过多通道转码成“多通道数据”(B-format),然后经过网络传输到远端,就可以通过耳机或者多声道的播放设备将其播放出来。目前声网的音频编解码传输就已支持 Ambisonics,同时我们对音频的高保真压缩,可把数据压缩在合理的带宽范围之内,又不会影响音质体验。
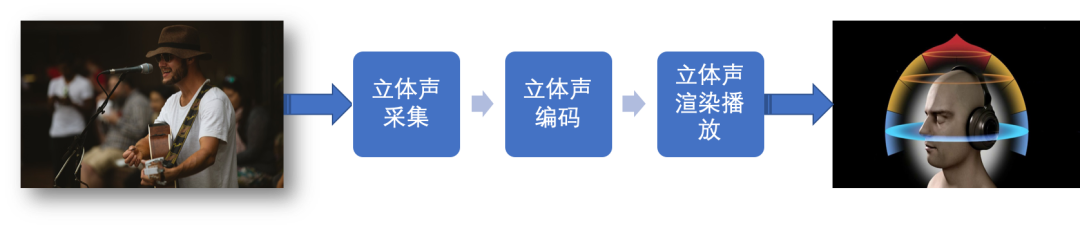
图4:基于高保真度立体声像复制 Ambisonics 的 RTE 技术
基于这一套技术基本可以做到完整的声场还原,身临其境。但有些场景受限于采集设备、场景等,使得我们在采集的时候,可能只有单通道采集或者非立体声采集。换句话说,就是没有办法使用图 3 中的专业话筒,可能只能使用电脑自带麦克风或普通麦克风。但我们想体验会议室、演唱会、开 party 的“济济一堂”或者游戏中的“听音辨位,虚拟现实”,这时就需要虚拟立体声(Virtual Stereo)来实现了。
最简单的双声道虚拟立体声可以利用 Amplitude panning 技术,即通过调节左右声道的音量大小来实现。根据一个给定的虚拟音源的位置和距离人头的相对位置来调节左右声道的声波幅值,从而实现一个二维平面空间的立体声听感。
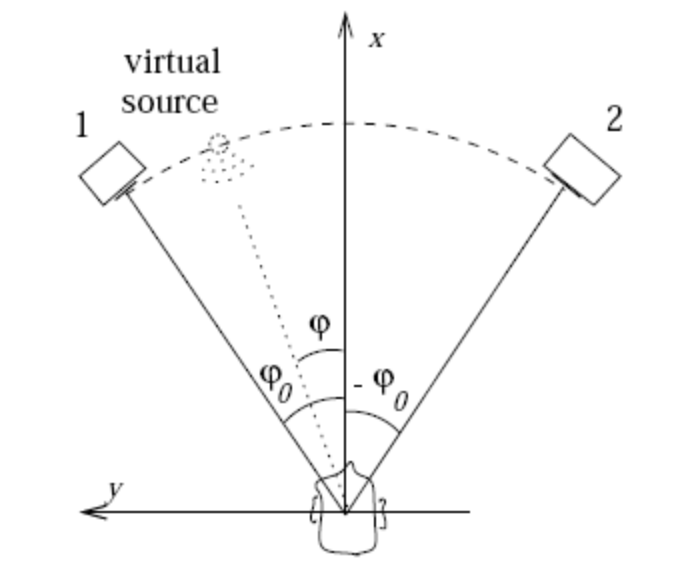
图5:Amplitude panning
Amplitude panning 没有考虑人耳形状带来遮蔽效果,也没有考虑声音传播的音色变化,所以实际使用时虽然可以判定出大致音源的方向和距离,但离真实听感差距比较大。为了达到更好的听感,声网的虚拟立体声采用了 HRTF(Head-related transfer function)技术,对音源到达双耳的传递函数进行建模 ,并结合真实采集的 HRIR(Head Related Impulse Responses)来准确的还原不同音源位置对实际听感的区别。使用 HRTF 技术的虚拟立体声更真实,对距离、角度的听力判断更准确。

图6:HRIR 的收集
利用虚拟立体声,我们只需要在参数中设定声源的角度和距离,就可以决定声源的位置,而且声源的位置可供我们随意编辑。这样我们就可以在多人在线互动场景模拟出“身临其境”的感觉,例如会议场景中,大家坐在不同的位置,你能清楚的听到每个人都在你的不同方位,再辅以图像就可以模拟真实的互动感,轻松让沟通更高效、更有趣。
如果是使用 Agora SDK,那么我们可以在加入频道前调用 enableSoundPositionIndication 方法开启远端用户的语音立体声后,使用 setRemoteVoicePosition() 方法来设定远端声源的参数,实现空间音效。如果你感兴趣,想快速体验一番,可以基于我们官方开源的这些 Demo ,上手试试看:
互动播客 Demo:
https://github.com/AgoraIO-Usecase/Livecast
在线会议 Demo:
https://github.com/AgoraIO-Usecase/AgoraMeeting
语音聊天室 Demo:
https://github.com/AgoraIO-Usecase/Chatroom
同时,我们还将在近期举行一场小型的开发者体验会,现场会有我们音频组的技术专家带着大家一起玩转空间音效、实时美声、变声等,让你的应用更“声”动有趣!扫码或点击「阅读原文」,报名一起来体验吧。
声网开发者音频 SDK 线下体验会
时间:2021 年 4 月 2 日 14:00 - 16:00
地址:上海市杨浦区淞沪路 333 号创智天地 12 号楼 声网公司
活动介绍
本次音频 SDK 体验活动,将由声网的资深音频工程师进行音频 SDK 相关的技术内容现场闭门分享,并协助参与活动的开发者现场实际操作,体验声网音频 SDK 的集成,以及如何调用调试美声、空间音效等进阶功能。
注:
1. 因场地限制,本次活动席位有限,敬请谅解。
2. 本次活动涉及简单的动手实操,需报名者自带电脑设备,在各自最熟悉的开发环境下实现自己想要的音频效果。

相关阅读
详解低延时高音质:编解码篇
详解低延时高音质:回声消除与降噪篇
详解低延时高音质:丢包、抖动与 last mile 优化那些事儿
END