系列文章目录
Linux 内核设计与实现
深入理解 Linux 内核(一)
深入理解 Linux 内核(二)
Linux 设备驱动程序(一)
Linux 设备驱动程序(二)
Linux 设备驱动程序(三)
Linux设备驱动开发详解
文章目录
- 系列文章目录
- 第十五章 内存映射和DMA
- 1、 Linux的内存管理
- (1)地址类型
- (2)物理地址和页
- (3)高端与低端内存
- (4)内存映射和页结构
- (5)页表
- (6)虚拟内存区
- (a)vm_area_struct 结构
- (7)内存映射处理
- 2、mmap 设备操作
- (1)使用 remap_pfn_range
- (2)一个简单的实现
- (3)为 VMA 添加操作
- (4)使用 nopage 映射内存
- (5)重映射特定的 I/O 区域
- (6)重新映射 RAM
- (a)使用 nopage 方法重映射 RAM
- (7)重新映射内核虚拟地址
- 3、执行直接 I/O 访问
- (1)异步 I/O
- (a)异步 I/O 例子
- 4、 直接内存访问
第十五章 内存映射和DMA
1、 Linux的内存管理
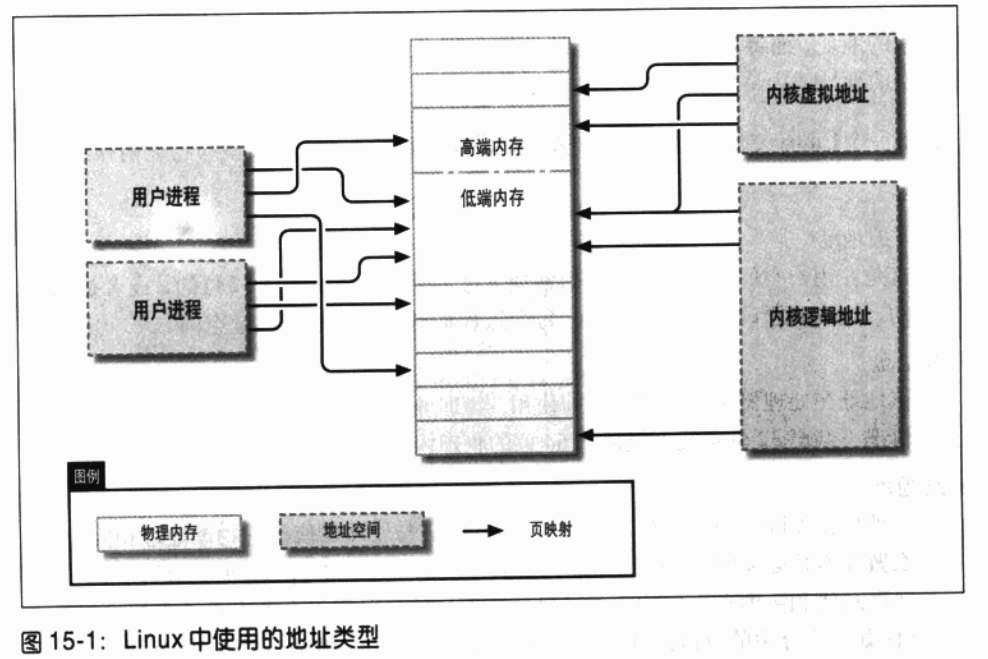
(1)地址类型
-
用户虚拟地址
这是在用户空间程序所能看到的常规地址。用户地址或者是 32 位的,或者是 64 位的,这取决于硬件的体系架构。每个进程都有自己的虚拟地址空间。 -
物理地址
该地址在处理器和系统内存之间使用。物理地址也是 32 位或者 64 位长的,在某些情况下甚至 32 位系统也能使用 64 位的物理内存。 -
总线地址
该地址在外围总线和内存之间使用。通常它们与处理器使用的物理地址相同,但这么做并不是必需的。一些计算机体系架构提供了 I/O 内存管理单元(IOMMU),它实现总线和主内存之间的重新映射。IOMMU 可以用很多种方式让事情变得简单(比如使内存中的分散缓冲区对设备来说是连续的),但是当设置 DMA 操作时,编写 IOMMU 相关的代码是一个必需的额外步骤。当然总线地址是与体系架构密切相关的。 -
内核逻辑地址
内核逻辑地址组成了内核的常规地址空间。该地址映射了部分(或者全部)内存,并经常被视为物理地址。在大多数体系架构中,逻辑地址和与其相关联的物理地址的不同,仅仅是在它们之间存在一个固定的偏多量。逻辑地址使用硬件内建的指针大小,因此在安装了大量内存的 32 位系统中,它无法寻址全部的物理地址。逻辑地址通常保存在 unsigned long 或者 void * 这样类型的变量中。kmalloc 返回的内存就是内核逻辑地址。 -
内核虚拟地址
内核虚拟地址和逻辑地址的相同之处在于,它们都将内核空间的地址映射到物理地址上。内核虚拟地址与物理地址的映射不必是线性的和一对一的,而这是逻辑地址空间的特点。所有的逻辑地址都是内核虚拟地址,但是许多内核虚拟地址不是逻辑地址。举个例子,vmalloc 分配的内存具有一个虚拟地址(但并不存在直接的物理映射)。kmap 函数(在本章后面论述)也返回一个虚拟地址。虚拟地址通常保存在指针变量中。
如果有一个逻辑地址,宏 __pa()(在 <asm/page.h> 中定义)返回其对应的物理地址;使用宏 __va() 也能将物理地址逆向映射到逻辑地址,但这只对低端内存页有效。
不同的内核函数需要不同类型的地址。如果在 C 中已经定义好了不同的类型,那么需要的地址类型将很明确,但现实不是这样的。在本章中,将明确表述在何处使用何种类型的地址。
(2)物理地址和页
物理地址被分成离散的单元,称之为页。系统内部许多对内存的操作都是基于单个页的。每个页的大小随体系架构的不同而不同,但是目前大多数系统都使用每页 4096 个字节。
常量 PAGE_SIZE(在 <asm/page.h> 中定义)给出了在任何指定体系架构下的页大小。
仔细观察内存地址,无论是虚拟的还是物理的,它们都被分为页号和一个页内的偏移量。
举个例子,如果使用每页 4096 个字节,那么最后的 12 位是偏移量,而剩余的高位则指
定了页号。如果忽略了地址偏移量,并将除去偏移量的剩余位移到右端、称该结果为页。
核数。移动位以在页顿数和地址间进行转换是一个常用操作;宏 PAGE_SHIFT 将告诉
程序员,必须移动多少位才能完成这个转换。
(3)高端与低端内存
在装有大量内存的 32 位系统中,逻辑和内核虚拟地址的不同将非常突出。使用32 位只
能在 4GB 的内存中寻址。由于这种建立虚拟地址空间的问题,直到最近,32 位系统的
Linux 仍被限制使用少于 4GB 的内存。
内核(在 x86 体系架构中,这是默认的设置)将4GB 的虚拟地址空间分割为用户空间和
内核空间;在二者的上下文中使用同样的映射。一个典型的分割是将3GB 分配给用户空
间,1GB 分配给内核空间(注 1)。内核代码和数据结构必须与这样的空间相匹配,但是
占用内核地址空间最大的部分是物理内存的虚拟映射。内核无法直接操作没有映射到内
核地址空间的内存。换句话说,内核对任何内存的访问,都需要使用自己的虚拟地址。
因此许多年来,由内核所能处理的最大物理内存数量,就是将映射至虚拟地址空间内核
部分的大小,再减去内核代码自身所占用的空间。因此,基于 x86 的 Linux 系统所能使
用的最大物理内存,会比 1GB 小一点。
为了应对商业压力,在不破坏32位应用程序和系统兼容性的情况下,为了能使用更多的
内存,处理器制造厂家为他们的产品增添了"地址扩展"特性。其结果是在许多情况下,
即使 32 位的处理器都可以在大于 4GB 的物理地址空间寻址。然而有多少内存可以直接
映射到逻辑地址的限制依然存在。只有内存的低端部分(依赖与硬件和内核的设置,一
般为 1 到 2GB)拥有有逻辑地址(注 2);剩余的部分(高端内存)是没有的。在访问特定
的高端内存页前,内核必须建立明确的虚拟映射,使该页可在内核地址空间中被访问。
因此,许多内核数据结构必须被放置在低端内存中;而高端内存更趋向于为用户空间进
•程页所保留。
注 1: 许多非x86 的体系架构不需需要这里描述的内核 / 用户空间分割即可有效工作,因此,这些
体系架构在 32 位系统上就能获得 4GB 的内核地址空间。但是,这一小节描述的限制对
安装有多于 4GB 内存的系统仍然适用。
注 2: 2.6 内核通过一个补丁可在 x86 硬件上支持"4G/4G"模式,它可以让内核和用户虚拟地
址空间变大,但会引入做小的性能代价。
术语"高端内存"可能对一些人来说理解起来比较困难、特别是在 PC 世界中,它还有
着其他的含义。因此为了弄清这个问题,这里先对它进行定义:
低端内存
存在于内核空间上的逻辑地址内存。几乎所有现在读者遇到的系统,它全部的内存
都是低端内存。
高端内存
是指那些不存在逻辑地址的内存,这是因为它们处于内核虚拟地址之上。
在i386系统中,虽然在内核配置的时候能够改变低端内存和高端内存的界限,但是通常
将该界限设置为小于 1GB。这个界限与早期PC 中的 640K限制没有任何关系,并且它的
设置也与硬件无关。相反它是由内核设置的,把32位地址空间分割成内核空间与用户空。
间。
在后面的部分中,将指出使用高端内存的限制。
(4)内存映射和页结构
由于历史的关系,内核使用逻辑地址来引用物理内存中的页。然而由于支持了高端内存,
就暴露出一个明显的问题— 在高端内存中将无法使用逻辑地址。因此内核中处理内
存的函数趋向使用指向 page 结构的指针(E <linux/mm.h> 中定义)。该数据结构用来
保存内核需要知道的所有物理内存信息;对系统中每个物理页,都有一个 page 结构相
对应。下面介绍该结构中包含的几个成员:
atomic_t count;
对该页的访问计数。当计数值为 0 时,该页将返回给空闲链表。
void *virtual;
如果页面被映射,则指向页的内核虚拟地址;如果未被映射则为NULL。低端内存
页总是被映射;而高端内存页通常不被映射。并不是在所有体系架构中都有该成
员;只有在页的内核虚拟地址不容易被计算时,它才被编译。如果要访问该成员,
正确的方法是使用下面讲述的 page_address 宏。
unsigned long flags;
描述页状态的一系列标志。其中,PG_locked 表示内存中的页已经被锁住,而
PG_reserved 表示禁止内存管理系统访问该页。
在page 结构中还包含了许多信息,但这是深层次内存管理所关心的问题,而驱动程序
作者不必要了解。
内核维护了一个或者多个page结构数组,用来跟踪系统中的物理内存。在一些系统中,
有一个单独的数组称之为 mem_map。在另外一些系统中,情况将会复杂很多。非一致
性内存访问(Nonuniform Memory Access,NUMA)系统和有大量不连续物理内存的
系统会有多个内存映射数组,因此从可移植性考虑,代码不要直接访问那些数组。幸运
的是,通常只需要使用 page 结构的指针,而不需要了解它们是怎么来的。
有一些函数和宏用来在 page 结构指针与虚拟地址之间进行转换:
struct page *virt_to_page(void *kaddr);
该宏在<asmlpage.h>中定义,负责将内核逻辑地址转换为相应的 page结构指针。
由于它需要一个逻辑地址 因此它不能操作 vmalloc 生成的地址以及高端内存。
struct page *pfn_to_page(int pfn);
针对给定的页顿号,返回 p a ge 结构指针。如果需要的话,在将页顿号传递给
pfn_to_page 前,使用 pfn_valid 检查页赖号的合法性。
void *page_address(struct page *page);
如果地址存在的话,则返回页的内核虚拟地址。对于高端内存来说,只有当内存页。
被映射后该地址才存在。该函数定义在 <linux/mm.h> 中。在大多数情况下,要使
用 kmap 而不是 page_address。
#include <linux/highmem.h>
void *kmap(struct page *page);
void kunmap(struct page *page);
kmap为系统中的页返回内核虚拟地址。对于低端内存页来说,它只返回页的逻辑
地址;对于高端内存,kmap在专用的内核地址空间创建特殊的映射。由kmap创建
的映射需要用 kunmap释放;对该种映射的数量是有限的,因此不要持有映射过长
的时间。kmap 调用维护了一个计数器,因此如果两个或是多个函数对同一页调用
kmap,操作也是正常的。请注意当没有映射的时候,kmap 将会休眠。
#include <linux/highmem.h>
#include <asm/kmap_types.h>
void *kmap_atomic(struct page *page, enum km_type type);
void kunmap_atomic(void *addr, enum km_type type);
kmap_atomic是kmap的高性能版本。每个体系架构都为原子的kmap维护着一个槽
(专用页表入口)的列表;kmap_atomic 的调用者必须告诉系统,type 参数使用的
是哪个槽。对驱动程序有意义的槽只有 KM_USER0 和 KM_USER1(针对在用户空
间中直接运行的代码),KM_IRQ0 和 KM_IRQ1(针对中断处理程序)。要注意的是
原子的kmap必须原子地处理,也就是说,在拥有它的时候,代码不能进入睡眠状态。还要注意的是在内核中,没有任何机制能防止这两个函数使用相同的槽,以及
防止它们之间的相互干涉(虽然对每个 CPU 都有一套特定的槽)。在实际情况中、
对原子的 kmap 槽的争夺并不会引起什么问题。
在研究例子代码时,以及在本章及后面的章节中,读者会看到如何使用这些面数。
(5)页表
在任何现代的系统中,处理器必须使用某种机制、将虚拟地址转换为相应的物理地址。
这种机制被称为页表;它基本上是一个多层树形结构,结构化的数组中包含了虚拟地址
到物理地址的映射和相关的标志位。即使在不直接使用这种页表的体系架构中,Linux
内核也维护了一系列的页表。
设备驱动程序执行了大量操作,用来处理页表。幸运的是,对驱动程序作者来说,在2.6
版内核中删除了对页表直接操作的需求。因此这里不对它们做详细讲解;富有好奇心的
读者可以阅读Daniel P. Bovet和Marco Cesati编写的《Understanding The Linux Kernel》
(O’Reilly)一书了解详细情况。
(6)虚拟内存区
虚拟内存区(VMA)用于管理进程地址空间中不同区域的内核数据结构。一个 VMA 表
示在进程的虚拟内存中的一个同类区域: 拥有同样权限标志位和被同样对象(一个文件
或者交换空间)备份的一个连续的虚拟内存地址范围。它符合更宽泛的"段"的概念,
但是把其描述成"拥有自身属性的内存对象"更为贴切。进程的内存映射(至少)包含
下面这些区域:
程序的可执行代码(通常称为 text)区域。
多个数据区,其中包含初始化数据(在开始执行的时候就拥有明确的值)、非初始
化数据(BSS,注 3)以及程序堆栈。
与每个活动的内存映射对应的区域。
查看/proc/<pid/maps>(其中的 pid要替换为具体的进程 ID)文件就能了解进程的内存
区域。/proclself是一个特殊的文件,因为它始终指向当前进程。下面是多个内存映射的。
例子(注释以斜体的方式给出):
注 3: BSS 这一名称是一个历史遗物、来自一条老的汇编操作称为"block started by symbol
(将号定义的块)"。可执行文件的 BSS段并不会存储在磁盘上,而是由内核将本页映射
到 BSS 地址范围。
每行都是用下面的形式表示的:
start-end perm offset major:minor inode image
在/proc/*/maps中的每个成员(除映像名外)都与’vm_area_struct结构中的一个成
员相对应:
start
end
该内存区域的起始处和结束处的虚拟地址。
perm
内存区域的读、写和执行权限的位掩码。该成员描述了允许什么样的进程能访问属
于该区域的页。该成员的最后一个字母或者是 p 表示私有,或者是 s 表示共享。
offset
表示内存区域在映射文件中的起始位置。偏移量为0表示内存区域的起始位置映射
到文件的开始位置。
major
minor
拥有映射文件的设备的主设备号和次设备号。对于设备映射来说,主设备号和次设
备号指的是包含设备特殊文件的磁盘分区,该文件由用户而非设备自身打开。
inode
被映射的文件的索引节点号。
image
被映射文件(通常是一个可执行映像)的名称。
(a)vm_area_struct 结构
当用户空间进程调用mmap、将设备内存映射到它的地址空间时、系统通过创建一个表
示该映射的新 VMA 作为响应。支持 mmap 的驱动程序(当然要实现 mmap 方法)需要
帮助进程完成 VMA 的初始化。因此驱动程序作者为了能支持 mmap,需要对 VMA 有所
了解。
现在来学习 vm_area_struct 结构(在 clinux/mm.h> 中定义)中最重要的成员。在设备
驱动程序对mmap的实现中会使用到这些成员。请注意,为优化查找方法,内核维护了
VMA的链表和树型结构,而 vm_area_struct中的许多成员都是用来维护这个结构的。
因此驱动程序不能任意创建 VMA,或者打破这种组织结构。VMA的主要成员如下所示。
(请注意这些成员和刚才看到的 /proc 文件输出之间的区别):
unsigned long vm_start;
unsigned long vm_end;
该 VMA 所覆盖的虚拟地址范围。这是 /proc/*/maps 中最前面的两个成员。
struct file *vm_file;
指向与该区域(如果存在的话)相关联的 file 结构指针。
unsigned long vm_pgoff;
以页为单位,文件中该区域的偏移量。当映射一个文件或者设备时,它是该区域中
被映射的第一页在文件中的位置。
unsigned long vm_flags;
描述该区域的一套标志。驱动程序最感兴趣的标志是 VM_IO 和 VM_RESERVED。
VM_IO将 VMA 设置成一个内存映射I/O区域。VM_IO会阻止系统将该区域包含在
进程的核心转储中。VM_RESERVED 告诉内存管理系统不要将该 VMA 交换出去;
大多数设备映射中都设置该标志。
struct vm_operations_struct *vm_ops;
内核能调用的一套函数,用来对该内存区进行操作。它的存在表示内存区域是一个。
内核"对象",这点和在本书中使用的 file 结构很相似。
void *vm_private_data;
驱动程序用来保存自身信息的成员。
与vm_area_struct结构类似,vm_operations_struct结构也定义在<linuxlmm.h>中,
其中包含了下面列出的函数。这些操作只是用来处理进程的内存需求,并按照声明的顺
序将它们列了出来。在本章后面的部分、将介绍如何实现其中的几个函数。
void (*open)(struct vm_area_struct *vma);
内核调用 open函数,以允许实现 VMA 的子系统初始化该区域。当对 VMA 产生一
个新的引用时(比如fork 进程时),则调用这个函数。唯一的例外发生在 mmap 第
一次创建 VMA 时;在这种情况下下,需要调用驱动程序的 mmap 方法。
void (*close)(struct vm_area_struct *vma);
当销毁一个区域时,内核将调用 close 操作。请注意由于 VMA 没有使用相应的计。
数,所以每个使用区域的进程都只能打开和关闭它一次。
struct page *(*nopage) (struct vm_area_struct *vma, unsigned long address, int
*type);
当一个进程要访问属于合法 VMA的页,但该页又不在内存中时,则为相关区域调
用nopage函数(如果定义了的话话)。在将物理页从辅助存储器中读人后,该函数返
回指向物理页的 page 结构指针。如果在该区域没有定义 nopage 函数,则内核将。
为其分配一个空页。
int (*populate)(struct vm_area_struct *vm, unsigned long address, unsigned
long len, pgprot_t prot, unsigned long pgoff, int nonblock);
在用户空间访问页前,该函数允许内核将这些页预先装入内存。一般来说,驱动程
序不必实现 populate 方法。
(7)内存映射处理
最后一个内存管理难题是处理内存映射结构,它负责整合所有其他的数据结构。在系统
中的每个进程(除了内核空间的一些辅助线程外)都拥有一个 structmm_struct结
构(在 <linux/sched.h> 中定义),其中包含了虚拟内存区域链表、页表以及其他大量内
存管理信息,还包含一个信号灯(mmap_sea)和一个自旋锁(page_table_lock)。
在task 结构中能找到该结构的指针;在少数情况下当驱动程序需要访问它时,常用的办
法是使用 current->mm。请注意,多个进程可以共享内存管理结构,Linux 就是用这
种方法实现线程的。
为了能对Linux 内存管理数据结构有一个通盘的了解,现在首先看看mmap系统调用是
如何实现的。
2、mmap 设备操作
在现代Unix系统中,内存映射是最吸引人的特征。对于驱动程序来说,内存映射可以提
供给用户程序直接访问设备内存的能力。
使用 mmap 的一个例子是看一下 X Window 系统服务器的部分虚拟内存区域:
cat /proc/731/maps
000a0000-000c0000 rwxs 000a0000 03:01 282652
000f0000-00100000 r-xs 000f0000 03:01 282652
00400000-005c0000 r-xp 00000000 03 :01 1366927
006bf000-006f7000 rw-p 001bf000 03:01 1366927
/dev/mem
/dev/mem
/usr/X11R6/bin/Xorg
/usr/X11R6/bin/Xorg
2a95828000-2a958a8000 rw-s fcc00000 03:01 282652 /dev/mem
2а958a8000-2a9d8a8000 rw-s e8000000 03:01 282652 /dev/mem
X服务器完整的VMA的清单很长,但这里对其中的大部分内容都不感兴趣。可以看到,
有四个独立的/dev/mem的映射,它为我们揭示了 X 服务器如何使用显示卡工作的内幕。
第一个映射开始位置是 a0000,这是在 640KB ISA 结构中显示 RAM 的标准位置。往下
可以看到更大的一块映射区域 e8000000,其地址位于系统最大 RAM 地址之上。这是
对显示适配器中显存的直接映射。
在 /procliomem 中也可以看到:
000a0000-000bffff : Video RAM area
000c0000-000ccfff : Video ROM
000d1000-000dlfff : Adapter ROM
000f0000-000fffff : System ROM
d7f00000-f7efffff : PCI Bus #01
e8000000-efffffff : 0000:01:00.0
fc700000-fccfffff : PCI Bus #01
fcc00000-fcc0ffff : 0000:01:00.0
映射一个设备意味着将用户空间的一段内存与设备内存关联起来。无论何时当程序在分
配的地址范围内读写时,实际上访问的就是设备。在在 X 服务器例子中,使用 mmap 就能
迅速而便捷地访问显卡内存。对于那些与此类似、性能要求背刻的应用程序,直接访问
能显著提高性能。
正如读者怀疑的那样,不是所有的设备都能进行mmap抽象的。比如像串口和其他面向
流的设备就不能做这样的抽象。对mmap的另外一个限制是:必须以 PAGE_SIZE为单
位进行映射。内核只能在页表一级上对虚拟地址进行管理,因此那些被映射的区域必须是 PAGE_SIZE的整数倍,并且在物理内存中的起始地址也要求是 PAGE_SIZE的整数
倍。如果区域的大小不是页的整数倍,则内核强制指定比区域稍大一点的尺寸作为映射
的粒度。
对于驱动程序来说这些限制并不是什么大问题,因为访问设备的程序都是与设备相关的。
由于程序必须知道设备的工作过程,因此程序员不会被诸如页边界之类的需求所困扰。
在某些非 x86 平台上工作的 ISA 设备面临更大的制约,因为它们的 ISA 硬件视图是不连。
续的。比如一些 Alpha 计算机视 ISA 内存为不可直接映射的 8 位、16 位或者 32 位的离
散项的集合。在这种情况下,根本无法使用 mmap。无法将 ISA 地址直接映射到 Alpha
地址,是由于这两种系统间,存在着不兼容的数据传输规则。虽然早期的 Alpha 处理器
只能解决 32 位和 64 位内存访问问题,但是对于 ISA 来说只能进行 8 位和 16 位的传输,
没有办法透明地将一个协议映射到另外一个协议上。
当灵活使用mmap 时,它具有很大的优势。比如在 X 服务器例子中,它负责和显存间读。
写大量数据;与使用/seek/write相比,将图形显示映射到用户空间极大地提高了吞吐量。
另外一个典型例子是控制 PCI 设备的程序。大多数 PCI 外围设备将它们的控制寄存器映
射到内存地址中、高性能的应用程序更愿意直接访问寄存器,而不是不停的调用ioctl去
获得需要的信息。
mmap 方法是 file_operations结构的一部分,并且执行mmap系统调用时将调用该方
法。使用mmap,内核在调用实际函数之前,就能完成大量的工作,因此该方法的原型
与系统调用有着很大的不同。它也与诸如ioctl和poll不同,内核在调用那些函数前不用。
做什么工作。
系统调用有着以下声明(在 mmap(2)手册页中描述):
mmap (caddr_t addr, size_t len, int prot, int flags, int fd, off_t offset)
但是文件操作声明如下:
int (*mmap) (struct file *filp, struct vm_area_struct *vma);
该函数中的 filp参数与第三章中介绍的一样,vma 包含了用于访问设备的虚拟地址的
信息。因此大量的工作由内核完成;为了执行mmap,驱动程序只需要为该地址范围建
立合适的页表,并将 vma->vm_ops 替换为一系列的新操作就可以了。
有两种建立页表的方法:使用remap_pfn_range函数一次全部建立,或者通过nopage
VMA 方法每次建立一个页表。这两种方法有它各自的优势和局限性。这里首先介绍一
次全部建立的方法,因为它最简单。从这开始,将会为实际的实现方法逐晰增加其复杂
性:
(1)使用 remap_pfn_range
remap_pfn_range 和 io_remap_page_range 负责为一段物理地址建立新的页表,它们有
着如下的原型:
int remap_pfn_range(struct vm_area_struct *vma,
unsigned long virt_addr, unsigned long pfn,
unsigned long size, pgprot_t prot);
int io_remap_page_range(struct vm_area_struct *vma,
unsigned long virt_addr, unsigned long phys_addr,
unsigned long size, pgprot_t prot);
通常函数的返回值是 0,或者是个负的错误码。现在来看看各参数的含义:
vma
虚拟内存区域、在一定范围内的页将被映射到该区域内。
virt_addr
重新映射时的起始用户虚拟地址。该函为处于virt_addr和virt_addr+size之
间的虚拟地址建立页表。
pfn
与物理内存对应的页顿号,虚拟内存将要被映射到该物理内存上。页赖号只是将书
理地址右移 PAGE_SHIFT 位。在多数情况下,VMA 结构中的 vm_pgof f 成员包
含了用户需要的值。该函数对处于(pfn<<PAGE_SHIFT)到(p f n<<PAGE_
SHIFT)+size之间的物理地址有效。
size
以字节为单位,被重新映射的区域大小。
prot
新 V MA 要求的"保护(prot e c ti on)"属性。驱动程序能够(也应该)使用
vma->vm_page_prot 中的值。
remap_Pfn_range 函数的参数非常简单,当调用 mmap 函数的时候,它们中大部分的值
在 V M A 中 提 供 。 也 许 读 者 会 奇 怪 , 为 什 么 会 有 两 个 函 数 呢? 第 一 个 函数
(remap_pfn_range)是在pfn指向实际系统RAM的时候使用,而io_remap_page_range
是在 phys_addr 指向 I/O 内存的时候使用。在实际应用中,除了 SPARC 外,对每个体
系架构这两个函数是等价的,而在大多数情况下会使用remap_pfn_range函数。对于有
可移植性要求的驱动程序,要使用与特定情形相符的 remap_pfn_range 变种。
另外复杂性也表现在缓存上: 对设备内存的引用通常不能被处理器所缓存。系统的BIOS
会正确设置缓存,但是也可以通过 protection 成员禁止缓存特定的 VMA。不幸的是,在这个层面上的禁止缓存是与处理器高度相关的。好奇的读者可以参考drivers/charimem.c
中的 p8prot_noncached 函数以了解其中细节。本书不对这个主题进行讨论。
(2)一个简单的实现
如果驱动程序要将设备内存线性地映射到用户地址空间中,程序员基本上就只需要调用
remap_pfn_range函数。下面的代码来自 drivers/charlmem.c,并且揭示了在一个被称为
simple(Simple Implementation Mapping Pages with Little Enthusiasm)的典型模块中,
该任务是如何被完成的:
static int simple_remap_mmap(struct file *filp, struct vm_area_struct *vma)
if (remap_pfn_range(vma, vma->vm_start, vm->vm_pgoff,
vma->vm_end - vma->vm_start,
vma->vm_page_prot))
return -EAGAIN;
vma->vm_ops = &simple_remap_vm_ops;
simple_vma_open(vma);
return 0;
可见,重新映射内存就是调用 remap_pfn_range 函数创建所需的页表。
(3)为 VMA 添加操作
如上所述,vm_area_struct 结构包含了一系列针对 VMA 的操作。现在来看看如何
简单实现这些函数。本节提供了针对 VMA 的 open 和 close 操作。当进程打开或者关闭
VMA时,会调用这些操作;特别是当fork 进程或者创建一个新的对VMA 引用时,随时
都会调用 open函数。对 VMA 函数 open 和 close 的调用由内核处理,因此它们没有必要
重复内核中的工作。它们存在的意义在于为驱动程序处理其他所需要的事情。
除此之外,一个诸如simple这样的简单驱动程序不需再做什么特别的事情了。这里创建
了open和 close 函数,它们负责向系统日志中输入信息,告诉系统它们被调用了。此外
没有其他特殊用途了,不过它能告诉读者: 如何提供这些函数以及何时调用它们。
因此,代码中用调用 printk 的新操作,覆盖了默认的 vma->vm_ops:
void simple_vma_open(struct vm_area_struct *vma)
printk(KERN_NOTICE "Simple VMA open, virt 81x, phys 81x\n*,
vma->vm_start, vma->vm_pgoff << PAGE_SHIFT);
void simple_vma_close(struct vm_area_struct *vma)
printk(KERN_NOTICE "Simple VMA close.\n");
static struct vm_operations_struct simple_remap_vm_ops =
.open =
simple_yma_open,
.close - simple_vma_close,
】;
为了使这些操作对特定的映射有效,需要在相关 VMA 的 v m_op s 成员中保存指向
simple_remap_vm_ops 的指针。这通常在 mmap 方法中完成。如果回过头去看
simple_remap_mmap 示例,能看到如下代码:
vma->vm_ops = &simple_remap_vm_ops;
simple_vma_open(vma);
请注意对 simple_vma_open函数的显式调用。由于在原来的 mmap 中没有调用 open
数,因此必须显式调用它才能使其正常运行。
(4)使用 nopage 映射内存
虽然 remap_page_range 在许多情况下工作良好,但并不能适应大多数的情况。有时驱
动程序对mmap的实现必须具有更好的灵活性。在这种情形下,提倡使用VMA的nopage
方法实现内存映射。
当应用程序要改变一个映射区域所绑定的地址时,会使用mremap 系统调用,此时是使
用 nopage 映射的最好的时机。当它发生时,内核并不直接告诉驱动动程序什么时候
mremap 改变了映射 VMA。如果 VMA 的尺寸变小了,内核将会刷新不必要的页,而不
通知驱动程序。相反,如果 VMA 尺寸变大了,当调用 nopage 时为新页进行设置时,驱
动程序最终会发现这个情况,因此没有必要做额外的通知工作。如果要支持 mremap系
统调用,就必须实现 nopage 函数。这里提供了设备中 nopage 的一个简单实现。
пopage 函数具有以下原型:
struct page *(*nopage)(struct vm_area_struct *vma,
unsigned long address, int *type);
当用户要访问 VMA 中的页,而该页又不在内存中时,将调用相关的 nopage 函数。
address 参数包含了引起错误的虚拟地址,它已经被向下圆整到页的开始位置。nopage
函数必须定位并返回指向用户所需要页的 page 结构指针。该函数还调用 get_page 宏,
用来增加返回的内存页的使用计数:
get_page(struct page *pageptr);
该步骤对于保证映射页引用计数的正确性是非常必要的。内核为每个内存页都维护了该
计数;当计数值为 0 时,内核将把该页放到空闲列表中。当 VMA 解除映射时,内核为
区域内的每个内存页减小使用计数。如果驱动程序向区域添加内存页时不增加使用计数,
则使用的计数值永远为 0,这将破坏系统的完整性。
Nopage 方法还能在 type 参数所指定的位置中保存错误的类型 但是只有在 type参
数不为 NULL 的时候才行。在 设备 驱动程序中,type 的正确值应该总是 VM_FAULT_
MINOR。
如果使用了 nopage,在调用 mmap 的时候,通常只需做一点点工作。示例代码如下:
static int simple_nopage_mmap(struct file *filp, struct vm_area_struct *vma)
unsigned long offset = vma->vm_pgoff << PAGE_SHIFT;
if (offset >= _ _pa(high_memory) || (filp->f_flags & O_SYNC))
vma->vm_flags |= VM_IO;
vma->vm_flags |= VM_RESERVED;
vma->vm_ops = &simple_nopage_vm_ops;
simple_vma_open(vma);
return 0;
mmap函数的主要工作是将默认的 vm_ops 指针替换为自己的操作。然后nopage函数小。
心地每次"重新映射"一页,并且返回它的 page 结构指针。因为在这里实现了一个物
理内存的窗口,重新映射的步骤非常简单: 只是为需要的地址定位并返回了 page结构
的指针。nopage 函数的例子程序如下:
struct page *simple_vma_nopage(struct vm_area_struct *vma,
unsigned long address, int *type)
struct page *pageptr;
unsigned long offset = vma->vm_pgoff << PAGE_SHIFT;
unsigned long physaddr = address - vma->vm_start + offset;
unsigned long pageframe = physaddidr >> PAGE_SHIFT;
if (!pfn_valid(pageframe))
return NOPAGE_SIGBUS;
pageptr = pfn_to_page(pageframe);
get_page(pageptr);
if (type)
*type = VM_FAULT_MINOR;
return pageptr;
再一次强调、这里只是简单映射了主内存、nopage函数需要为失效地址查找正确的page
结构,并且增加它的引用计数。因此所需要的步骤顺序是:首先计算物理地址,然后通过右移 PAGE_SHIFT 位,将它转换成页顿号。由于用户空间能为用户提供它所拥有的
任何地址,因此必须保证所用的页顿号合法:pfn_valid函数可以做这件事。如果地址超
出了范围,将返回 NOPAGE_SIGBUS,这会导致向调用进程发送一个总线信号。否则
pfn_to_page 函数获得所需要的 page 结构指针,这时,我们可以增加它的引用计数(使
用 get_page 函数)并将其返回。
通常nopage方法返回一个指向 page结构的指针。如果出于某些原因,不能返回一个正
常的页(比如请求的地址超过了设备的内存区域),将返回NOPAGE_SIGBUS表示错误;
这就是上面代码所做的事。nopage 还能返回 NOPAGE_OOM,表示由于资源紧张而造成
的错误。
请注意,这个实现对 ISA 内存区域工作正常,但是不能在 PCI 总线上工作。PCI 内存被
映射到系统内存最高端之上,因此在系统内存映射中没有这些地址的人口。因为无法返
回一个指向 page 结构的指针,所以 nopage 不能用于此种情形;在这种情况下,必须使
用remap_page_range.
如果nopage函数是NULL,则负责处理页错误的内核代码将把零内存页映射到失效虚拟
地址上。零内存页是一个写拷贝内存页,读它时会返回 0,它被用于映射 BSS 段。任何
一个引用零内存页的进程都会看到:一个充满了零的内存页。如果进程对内存页进行写
操作,将最终修改私有拷贝。因此,如果一个进程调用 mremap扩充一个映射区域,而
驱动程序没有实现nopage,则进程将最终得到一块全是零的内存,而不会产生段故障错
误。
(5)重映射特定的 I/O 区域
这今为止,所有例子都是对/dev/mem的再次实现;它们把物理内存重新映射到用户空间
中。一个典型的驱动程序只映射与其外围设备相关的一小段地址,而不是映射全部地址。
为了向用户空间只映射部分内存的需要,驱动程序只需要使用偏移量即可。下面的代码
揭示了驱动程序如何对起始于物理地址 simple_region_start(页对齐)、大小为
simple_region_size字节的区域进行映射的工作过程:
unsigned long off = vma->vm_pgoff << PAGE_SHIFT;
unsigned long physical = simple_region_start + off;
unsigned long vsize = vma->vm_end - vma->vm_start;
unsigned long psize = simple_region_size - off;
if (vsize > psize)
return -EINVAL; /* 跨度过大 */
remap_pfn_range(vma, vma_>vm_start, physical, vsize, vma->vm_page_prot);
当应用程序要映射比目标设备可用 I/O 区域大的内存时,除了计算偏移量,代码还检查
参数的合法性并报告错误。在代码中,psize是偏移了指定距离后,剩下的物理 I/O 大
小,vsize是虚拟内存需要的大小;该函数拒绝映射超出许可内存范围的地址。
请注意:用户进程总是使用mremap 对映射进行扩展、有可能超过了物理内存区域的尾
部。如果驱动程序没有定义一个 пopage函数,它将不会获得这个扩展的通知,并且多出。
的区域将被映射到零内存页上。作为驱动程序作者,应该尽量避免这种情况的发生;将
零内存页映射到区域的末端并非一件坏事,但是程序员也不愿意看到这种现象。
为防止扩展映射最简单的办法是实现一个简单的nopage方法,它会产生一个总线信号传。
递给故障进程。该函数有着类似于下面的形式:
struct page *simple_nopage(struct vm_area_struct *vma,
unsigned long address, int *type);
{ return NOPAGE_SIGBUS; /* 发送 SIGBUS * /}
如上所示,只有当进程抛弃那些存在于已知 VMA 中,但没有当前合法页表人口的地址
时,才会调用 nopage函数。如果使用 remap_pfn_range映射全部的设备区域,将会为超
过该区域的部分调用上面的 nopage 函数。因此它能安全返回 NOPAGE_SIGBUS,通知
错误的发生。当然一个更为彻底的nopage函数的实现会检查失效的地址是否在设备区域
内,如果在设备区域内,它会执行重新映射。再强调一次,nopage函数不能对PCI 内存
进行操作,因此对 PCI 映射的扩展是不可能实现的。
(6)重新映射 RAM
对remap_pfn_range函数的一个限制是:它只能访问保留页和超出物理内存的物理地址。
在 Linux 中,在内存映射时,物理地址页被标记为"保留的"(reserved),表示内存管
理对其不起作用。比如在 PC 中,在 640KB 和11MB 之间的内存被标记为保留的,因为这
个范围位于内核自身代码的内部。保留页在内存中被锁住,并且是唯一可安全映射到用。
户空间的内存页;这个限制是保证系统稳定性的基本需求。
因此remap_pfn_range不允许重新映射常规地址,这包括调用get_free_page函数所获得
的地址。相反它能映射零内存页。进程能访问私有的、零填充的内存页,而不是访问所
期望的重新映射的 RAM,除了这点外,一切工作正常。虽然如此,该函数还是做了大多
数硬件设备驱动程序需要做的事,因为它能重新映射高端 PCI 缓冲区和ISA 内存。
能够通过运行 mapper 看到对 remap_page_range 的限制,它是 O’Reilly FTP 服务器上
misc-progs目录中的一个例子程序。mapper是一个用来快速检测mmap系统调用的易用
工具;它根据命令行选项映射一个文件中的只读部分,并把映射区域的内容列在标准输出上。比如在下面的会话中,显示了 Idev/mem 没有映射在 64KB 处的物理页,而是看到
了一个全是零的内存页(运行该例子程序的主机是台PC,但在其他硬件平台上运行的结
果应该一样):
morgana.root# ./mapper /dev/mem 0x10000 0x1000 | od -Ax -t x1
mapped “/dev/mem” from 65536 to 69632
000000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
001000
remap_pfn_range 函数无法 处理 RAM 表明 : 像 scull 这样基于内存的设备无法简单地实。
现 mmap,因为它的设备内存是通用的 RAM,而不是 I/O 内存。幸运的是,对任何需要
将 RAM 映射到用户空间的驱动程序来说,有一种简单的方法可以达到目的,这就是前
面介绍过的 nopage 函数。
(a)使用 nopage 方法重映射 RAM
将实际的 RAM 映射到用户空间的方法是:使用 vm_ops->nopage 一次处理一个页错
误。在第八章的 scullp 模块中,有一个实现该功能的例子。
scullp是一个面向内存页的字符设备。由于是面向内存页的,因此能对内存执行mmap。
在执行内存映射的代码中,使用了在"Linux 中的内存管理"一节中介绍的一些概念。
在学习代码前,先来看看影响 scullp 中 mmap 实现的一些设计选择:
只要映射了设备,scullp就不会释放设备内存。与其说是需求,还不如说是一种机
制,这使得scull和其他类似设备有着很大的不同,因为打开它们进行写操作时,会
把它们的长度截短为 0。禁止释放一个被映射的 scullp 设备,使得-个进程改写被
另外一个进程映射的区域成为可能,因此可以看到进程和设备内存是如何互动的。
为了避免释放一个被映射的设备,驱动动程序必须保存活动映射的计数;在device结
构中的 vmas成员的作用就是完成这一功能。
只有当 scullp 的 order 参数(在加载模块时设置)为 0 的时候,才执行内存映射。
该参数控制了对__get_free_pages 的调用(参看第八章中"get_free_page 及相关
函数"一节)。在 scullp 使用的分配函数–__get_free_pages 函数内部实现体现
了0 都次的限制(它强制每次只分配一个内存页,而不是一组)。为使分配性能最
大化,Linux内核为每一个分配幕次维护了一个闲置页列表,而且只有族中的第一
个页的页计数可以由get_free_pages 增加,并由free_pages减少。如果分配幕次大
于0,则对scullp 设备禁止使用mmap函数。因为 nopage 只处理单页而不处理一族
页面。scullp不知道如何为内存页正确管理引用计数,这是更高分配幕次的一部分(如果需要复习一下 scullp和内存分配幕次的值,可以返回到第八章的"使用一整
页的 scull: sculip"一节)。
0 邪次的限制尽可能地简化了代码。通过处理页的使用计数,也有可能为多页分配正确
地实现 mmap,但是这会增加例子的复杂性,却不能引入任何有趣的信息。
如果代码想要按照上面描述的规则来映射RAM,就需要实现 open、close 和 nopage 等
VMA 方法,它也需要访问内存映像来调整页的使用计数。
scullp_mmap 的实现很是简短,因为它依赖 nopage 函数来完成所有的工作:
int scullp_mmap(struct file *filp, struct vm_area_struct *vma)
struct inode *inode = filp->f_dentry->d_inode;
/* 如果幕次不是 0,则禁止映射 */
if (scullp_devices[iminor(inode)].order)
return -ENODEV;
/* 这里不做任何事情,"nopage"将填补这个空白 */
vma->vm_ops = &scullp_vm_ops;
vma->vm_flags |= VM_RESERVED;
vma->vm_private_data = filp->private_data;
scullp_vma_open(vma);
return 0;
if 语句的目的是为了了避免映射分配事次不为 0 的设备。scullp 的操作被存储在vm_ops
成员中,而且一个指向 device 结构的指针被存储在 vm_private_data成员中。最后
vm_ops->open 被调用,以更新模块的使用计数和设备的活动映射计数。
open和 close 函数只是简单地跟踪这些计数,其定义如下:
void scullp_vma_open(struct vm_area_struct *vma)
struct scullp_dev *dev = vma->vm_private_data;
dev->vmas++;
void scullp_vma_close(struct vm_area_struct *vma)
(
struct scullp_dev *dev = vma->vm_private_data;
dev->vmas--;
大部分工作由 nopage函数完成。在 scullp 的实现中,nopage的 address 参数用来计算
设备里的偏移量、然后使用该编移量在 scullp 的内存树中查找正确的页:
struct page *scullp_vma_nopage(struct vm_area_struct *vma,
unsigned long address, int *type)
unsigned long offset;
struct scullp_dev *ptr, *dev = vma->vm_private_data;
struct page *page = NOPAGE_SIGBUS;
void *pageptr = NULL;/* 默认值是"没有" */
down.(&dev->sem);
offset = (address - vma->vm_start) + (vma->vm_pgoff << PAGE_SHIFT);
if (offset >= dev->size) goto out; /* 超出范围 */
/*
• 现在从链表中获得了 scullp 设备以及内存页。
• 如果设备有空白区,当进程访问这些空白区时,进程会收到 SIGBUS。
offset >>= PAGE_SHIFT; /* offset 是页号 */
for (ptr = dev; ptr && offset >= dev->qset;) 【{
ptr = ptr->next;
offset -= dev->qset;
if (ptr && ptr->data) pageptr = ptr->data[offset];
if (ipageptr) goto out; /* 空白区或者是文件末尾 * /
page = virt_to_page(pageptr);
/* 获得该值,现在可以增加计数了 */
get_page (page);
if(type)
*type = VM_FAULT_MINOR;
out:
up(&dev->sem);
return page:
scullp 使用了由 get_free_pages 函数获得的内存。该内存使用逻辑地址寻址,因此
scullp_nopage 要做的全部工作就是调用 virt_to_page 来获得 page 结构的指针。
scullp 设备现在如预期的那样工作了,下面是 mapper 工具的输出。这里发送一个 /dev
(很长)目录清单给 scullp 设备,然后使用 mapper 工具查看mmap 生成的清单片段:
morganas -1 /dev > /dev/scullp
morganas ./mapper /dev/scullp 0 140
mapped “/dev/scullp” from 0 (0x00000000) to 140 (0×0000008c)
total 232
crw–
1 root
root
10, 10 Sep 15 07:40 adlbmouse
crw-r–r–
1 root
root
10, 175 Sep 15 07:40 agpgart
morganat ./mapper /dev/scullp 8192 200
mapped “/dev/scullp” from 8192 (0x00002000) to 8392 (0x000020c8)
d0h1494
brw-rw–
1 root
floppy
2, 92 Sep 15 07:40 fd0h1660
brw-rw–
brw-rw—
1 root
1 root
floppy
floppy
2, 20 Sep 15 07:40 fd0h360
2, 12 Sep 15 07:40 fd0H360
(7)重新映射内核虚拟地址
虽然很少需要重新映射内核虚拟地址,但是知道驱动程序是如何使用mmap 将内核虚拟
地址映射到用户空间的,也是一件有趣的事。- 个 真 正的内核虚拟地址 , 就是 诸 如
vmalloc 这样的函数返回的地址-
-也就是说,是一个映射到内核页表的虚拟地址。本
节中的代码是从 scullv 中抽取出来的、scullv 是一个与 scullp 类似的模块,但它是通过
vmalloc 分配存储空间的。
除了不需要检查控制内存分配的 order参数之外,scullv中的大多数实现与前面讨论的
scullp中的一样。这是因为 vmalloc 每次只分配一个内存页、而单页分配比多页分配成功。
的可能性更高一些,因此分配的幕次问题在 vmalloc 所分配的空间中不存在。
除了上述部分,只有 scullp 和 scullv 所实现的 nopage 函数是不一样的。请记住 scullp 一
且发现了感兴趣的页,将调用 virt_to_page 获得相应的 page 结构指针。但是该函数不
能在内核虚拟空间中使用,因此必须使用 vmalloc_to_page替换它。scullv版本的 nopage
函数的最后部分如下:
在 scullv 查找之后,"page"现在是当前进程所需要的页地址。
• 由于它是一个 vmalloc 返回的地址,将其转化为一个 page 结构。
*/
page = vmalloc_to_page(pageptr);
/* 获得该值,现在增加它的计数 */
get_page(page);
if (type)
*type = VM_FAULT_MINOR;
out:
up(&dev->sem);
return page;
出于对上述讨论内容的考虑,读者可能想要将 ioremap 返回的地址映射到用户空间上。
但这么做是错误的,这是因为 ioremap返回的地址比较特殊,不能把它当作普通的内核
虚拟地址,应该使用 remap_pfn_range 函数将 I/O 内存重新映射到用户空间上。
3、执行直接 I/O 访问
内核缓冲了大多数 I/O 操作。对内核空间缓冲区的使用,在一定程度上分隔了用户空间
和实际设备;这种分隔在许多情况下使得程序更容易实现,并且提高了性能。然而有些
时候,直接对用户空间缓冲区执行 I/O 操作效果也是很好的。如果需要传输的数据量非。
常大,直接进行数据传输,而不需要额外地从内核空间拷贝数据操作的参与,这将会大
大提高速度。在2.6 内核中一个使用直接I/O 操作的例子是 SCSI 磁带机驱动程序。数据磁带会把大量
数据传递给系统,而磁带的传输通常是面向记录的,因此在内核中缓冲数据的收益非常
小。因此当条件成熟(比如用户空间缓冲区很大)的时候,SCSI 磁带机驱动程序不通过
数据拷贝,直接执行它的 I/O 操作。
然而必须要清醒的认识到,直接 I/O 并不能像人们期望的那样、总是能提供性能上的飞
跃。设置直接 I/O(这包括减少和约束相关的用户页)的开销非常巨大,而又没有使用
缓存 I/O 的优势。比如,使用直接 I/O 需要 write 系统调用同步执行;否则应用程序将会
不知道什么时候能再次使用它的I/O缓冲区。在每个写操作完成之前不能停止应用程序,
这样会导致关闭程序缓慢,这就是为什么使用直接 I/O 的应用程序也使用异步 I/O 的原
因。
无论如何,在字符设备中执行直接 I/O 是不可行的,也是有害的。只有确定设置缓冲
I/O 的开销特别巨大,才使用直接I/O。请注意块设备和网络设备根本不用担心实现直接
I/O 的问题;在这两种情况中,内核中高层代码设置和使用了直接I/O,而驱动程序级的
代码甚至不需要知道已经执行了直接 I/O。
在2.6内核中,实现直接I/O的关键是名为get_user_pages的函数,它定义在<linux/mm.h>
中、并有以下原型:
int get_user_pages(struct task_struct *tsk,
struct mm_struct *mm,
unsigned long start,
int len,
int write,
int force,
struct page **pages,
struct vm_area_struct **vmas);
该函数有许多参数:
tsk
指向执行 I/O 的任务指针;它的主要目的是告诉内核,当设置缓冲区时,谁负责解
决页错误的问题。该参数几乎总是 current。
指向描述被映射地址空间的内存管理结构的指针.mm_stract 结构用来聚合进程
虚拟地址空间中的 VMA。对驱动程序来说,该参数总是 current->mm。
start
1en
start 是用户空间缓冲区的地址(页对齐),len是页内的缓冲区长度。
write
force
如果write非零,对映射的页有写权限(意味着用户空间执行了读操作)。force。
标志告诉get_user_pages函数不要考虑对指定内存页页的保护,直接提供所请求的访
问;驱动程序对该参数总是设置为 0。
pages
vmas
输出参数。如果调用成功,pages中包含了一个描述用户空间缓冲区page结构的
指针列表,vmas 包含了相应 VMA 的指针。显然这些参数指向的数组至少包含了
1en 个指针。这两个参数都可以为 NULL,但至少 page结构指针要对缓冲区进行
实际的操作。
get_user_pages 函数是一个底层内存管理函数,使用了比较复杂的接口。它还需要在调
用前,将 mmap 为获得地址空间的读取者 / 写人者信号量设置为读模式。因此,对
get_user_pages 的调用有类似以下的代码:
down_read(¤t ->mm->mmap_sem);
result = get_user_pages(current, current->mm, -..);
up_read(¤t->mm->mmap_sem);
返回的值是实际被映射的页数,它可能会比请求的数量少(但是大于 0)。
如果调用成功,调用者就会拥有一个指向用户空间缓冲区的页数组,它将被锁在内存中。
为了能直接操作缓冲区,内核空间的代码必须用 kmap 或者 kmap_atomic 函数将每个
page 结构指针转换成内核虚拟地址。使用直接 I/O 的设备通常使用 DMA 操作,因此驱
动程序要从page结构指针数组中创建一个分散/聚集链表。我们将在"分散/聚集映射"
一节中对其进行详细讲述。
一旦直接 I/O 操作完成,就必须释放用户内存页。在释放前,如果改变了这些页中的内
容,则必须通知内核,否则内核会认为这些页是"干净"的,也就是说,内核会认为它
们与交换设备中的拷贝是匹配的,因此,无需回存就能释放它们。因此,如果改变了页
(响应用户空间的读取请求),则必须使用下面的函数标记出每个被改变的页:
void SetPageDirty(struct page *page);
这个宏定义在<linuxlpage-flags.h> 中。执行该操作的大多数代码首先要检查页,以确保
该页不在内存映射的保留区内,因为这个区的页是不会被交换出去的,因此有如下代码:
if (! PageReserved (page))
SetPageDirty(page);
由于用户空间内存通常不会被标记为保留,因此这个检查并不是严格要求的。但是,在
对内存管理子系统有更深人的了解前,最好谨慎和细致些。
不管页是否被改变,它们都必须从页缓存中释放,否则它们会永远存在在那里。所需要
使用的函数是:
void page_cache_release(struct page *page);
当然,如果需要的话,在页被标记为改变(dirty)后,应该执行该调用。
(1)异步 I/O
添加到 2.6 内核中的一个 新特性是异步 I/O。异步 I/O 允许用户空间初始化操作,但不必
等待它们完成,这样,当 I/O 在执行时,应用程序可以进行其他的操作。一个复杂的、高
性能的应用程序也能使用异步 I/O,让多个操作同时进行。
异步 I/O 的实现是可选的,只有少数驱动程序作者需要考虑这个问题,大多数设备并不
能从异步操作中获得好处。在后面的几章中,块设备和网络设备驱动程序是完全异步操
作的,因此只有字符设备驱动程序需要清楚地表示需要异步 I/O 的支持。如果有恰当的
理由需要在同一时刻执行多于一个的 I/O 操作,则字符设备将会从异步 I/O 中受益。一
个良好的例子是磁带机驱动程序,如果它的 I/O 操作不能以足够快的速度执行,则驱动
器会显著变慢。一个为了获得该驱动器最优性能的应用程序应该使用异步 I/O,同时准
备执行多个操作。
针对于少数需要实现异步 I/O 的驱动程序作者 ,我们这 里对异步 I/O 的工作过程做一个。
简要的介绍。在本章中讲述异步I/O 的原因,是由于它的实现总是包含直接I/O 操作(如
果在内核中缓冲数据,则可以实现异步操作,而不给用户空间增加复杂程度)。
支持 异 步 I/O 的 驱 动程 序 应 该 包 含 <linuxl ai o .h > 。 有三个用于实现异步 I/O 的
file_operations 方法:
ssize_t (*aio_read) (struct kiocb *iocb, char *buffer,
size_t count, loff_t offset);
ssize_t (*aio_write) (struct kiocb *iocb, const char *buffer,
size_t count, loff_t offset);
int (*aio_fsync) (struct kiocb *iocb, int datasync);
aio_fsync 操作只对文件系统有意义,因此不作深入讨论。另外两个函数,aio_read 和
aio_write 与常用的 read 和 write 函数非常类似,但是也有一些不同。其中一个不同是:
传递的 offset 参数是一个值;异步操作从不改变文件的位置,因此没有必要向它传递
指针。这两个函数都使用 iocb(I/O 控制块, I/O control block)参数,一会将讨论它。
aio_read和aio_write函数的目的是初始化读和写操作,在这两个函数完成时,读写操作
可能已经完成,也可能尚未完成。如果操作立刻完成,则函数将返回常规状态:传输的
字节数或者是负的错误码。因此如果驱动程序作者自己的 read函数称为 my_read,下面
的 aio_read 函数就是完全正确的(虽然是无意义的):
static ssize_t my_aio_read(struct kiocb *iocb, char *buffer,
ssize_t count, loff_t offset)
《
return my_read(iocb->ki_filp, buffer, count, &offset);
请注意 file 结构指针保存在 kiocb 结构中的 ki_filp 成员里。
如果支持异步 I/O,则必须知道一个事实:内核有时会创建"同步 IOCB"。也就是说异
步操作实际上必须同步执行。读者也许会问:为什么会这样?但最好还是适应内核的要
求。同步操作会在 IOCB 中标识,因此,驱动程序应该使用下面的函数进行查询:
int is_sync_kiocb(struct kiocb *iocb);
如果该函数返回非零值,则驱动程序必须执行同步操作。
最后的关键点是如何允许异步操作。如果驱动程序可以开始操作(或者简单点,将操作
压人队列,等待未来某个时刻执行),它必须做两件事:记住与操作相关的所有信息、并
且返回 -EIOCBQUEUED 给调用者。记住操作的信息包括了安排对用户空间缓冲区的访
问;一旦返回,因为要运行在调用进程的上下文中,所以将不能再访问这个缓冲区。通
常这 意味 着 建 立 直 接 的 内 核 映 射 (使 用 g e t _ u s e r _ p a g e s ) 或者 D M A 映 射 。
-EIOCBQUEUED 错误码表明操作还没有完成,它最终的状态将在未来某个时刻公布。
当未来 某 个 时 刻到 来时 ,驱 动 程序 必须 通 知内 核 操作 已 经完 成。 这 需要使 用
aio_complete 函数:
int aio_complete(struct kiocb *iocb, long res, long res2);
这里,iocb 与最初传递给我们的 IOCB 相同,res 是操作的结果状态,res2 是返回给
用户空间的第二状态码,大多数异步 I/O 会将res2 设置为0。一旦调用了aio_complete,
就不能再访问 IOCB 或者用户缓冲区了。
(a)异步 I/O 例子
在例子源代码中,面向内存页的 scullp 驱动程序实现了异步 I/O。该实现非常简单,但
对于揭示异步操作是如何进行的,就已经足够了。
aio_read 和 aio_write 函数实际上没做什么事:
static ssize_t scullp_aio_read(struct kiocb *iocb, char *buf, size_t count,
loff_t pos)
return scullp_defer_op(0, iocb, buf, count, pos);
static ssize_t scullp_aio_write(struct kiocb *iocb, const char *buf,
size_t count, loff_t pos)
【
return scullp_defer_op(1, iocb, (char *) buf, count, pos);
)
这些函数只是简单地调用了一个常用函数:
struct async_work {
struct kiocb *iocb;
int result;
struct work_struct work;
j;
static int scullp_defer_op(int write, struct kiocb *iocb, char *buf,
size_t count, loff_t pos)
struct async_work *stuff;
int result;
/* 虽然可以访问缓冲区,但现在要进行拷贝操作 */
if (write)
result = scullp_write(iocb->ki_filp, buf, count, &pos);
else
result = scullp_read(iocb->ki_filp, buf, count, &pos);
/* 如果这是一个同步的 IOCB,则现在返回状态值 */
if (is_sync_kiocb(iocb))
return result;
/* 否则把完成操作向后推迟几毫秒 */
stuff = kmalloc (sizeof (*stuff), GFP_KERNEL);
if (stuff = = NULL)
return result;
/* 没有可用内存了,使之完成 */
stuff->iocb = iocb;
stuff->result result;
INIT_WORK(&stuff->work, scullp_do_deferred_op, stuff);
schedule_delayed_work(&stuff->work, HZ/100);
return -EIOCBQUEUED;
一个更完整的实现应该使用 get_user_pages 函数,以便将用户缓冲区映射到内核空间,
为了简单起见,这里只是从起始位置拷贝了数据。然后调用is_sync_kiocb函数检查操作
是否必须以同步方式完成。如果是,返回结果状态;如果不是,将相关信息保存在一个
小结构中,然后安排作业队列,接着返回 -EIOCBQUEUED。