目录
- 线性回归基本介绍
- 常用的op
- 自实现线性回归预测
- tensorflow 变量作用域
线性回归基本介绍
线性回归: w 1 ∗ x 1 + w 2 ∗ x 2 + w 3 ∗ x 3 + . . . + w n ∗ x n + b i a s w_1 * x_1 + w_2 * x_2 + w_3 * x_3 + ...+ w_n * x_n + bias w1∗x1+w2∗x2+w3∗x3+...+wn∗xn+bias
1:准备好1特征1目标值(都为100行1列)
y = x ∗ 0.7 + 0.8 y = x * 0.7 + 0.8 y=x∗0.7+0.8
2: 建立模型 随机初始化准备一个权重w,一个向量b
y p r e d i c t = x ∗ w + b y_{predict} = x * w + b ypredict=x∗w+b
3:求损失函数,误差
loss 均方误差: ( y 1 − y 1 ′ ) 2 + ( y 2 − y 2 ′ ) 2 + ( y 3 − y 3 ′ ) 2 + . . . + ( y 100 − y 100 ′ ) 2 (y_1-y_1^{'})^2 + (y_2-y_2^{'})^2 + (y_3-y_3^{'})^2 + ... + (y_{100}-y_{100}^{'})^2 (y1−y1′)2+(y2−y2′)2+(y3−y3′)2+...+(y100−y100′)2
4:梯度下降优化
矩阵相乘:
(m行,n行) * (n行,1)(m行,1)
常用的op
矩阵运算:
tf.matmul(x,w)
平方:
tf.square(error)
均值:
tf.reduce_mean(error)
梯度下降优化:
tf.train.GradientDescentOptimizer(learning_rate)- learning_rate:学习率- method:minize(loss)- return:梯度下降op
自实现线性回归预测
import tensorflow as tf
# 1.准备数据 x:特征值 [100,1] y 目标值[100]
x = tf.random_normal([100,1], mean = 1.75, stddev = 0.5,name = "x_data")# 矩阵相乘必须是二维的
y_ture = tf.matmul(x,[[0.7]]) + 0.8# 2.建立线性回归模型,1个特征,1个权重,一个偏置 y = xw + b
# 随机给一个权重和p偏置的值,计算损失,然后在当前状态下优化
# 用变量定义才能优化weight = tf.Variable(tf.random_normal([1,1],mean = 0.0,stddev = 1.0),name = "w")
bias = tf.Variable(0.0,name = "b")y_predict = tf.matmul(x,weight) + bias# 3.建立损失函数,均方误差
loss = tf.reduce_mean(tf.square(y_ture - y_predict))# 4.梯度下降优化损失 leaning_rate:0.01,0.03,0.1,0.3,......
train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)# 定义一个初始化变量的op
init_op = tf.global_variables_initializer()# 通过会话运行程序
with tf.Session() as sess:# 初始化变量sess.run(init_op)# 打印随机最先初始化的权重和偏置print("随机初始化的参数权重为:%f, 偏置为:%f" %(weight.eval(),bias.eval()))# 循环运行优化for i in range(200):sess.run(train_op)print("第%d次优化的参数权重为:%f, 偏置为:%f" % (i,weight.eval(),bias.eval()))随机初始化的参数权重为:-1.260226, 偏置为:0.000000
第0次优化的参数权重为:0.349570, 偏置为:0.856385
第1次优化的参数权重为:0.554503, 偏置为:0.966013
第2次优化的参数权重为:0.590992, 偏置为:0.982879
第3次优化的参数权重为:0.600176, 偏置为:0.984269
第4次优化的参数权重为:0.602949, 偏置为:0.982530
第5次优化的参数权重为:0.603653, 偏置为:0.980223
第6次优化的参数权重为:0.602477, 偏置为:0.976848
第7次优化的参数权重为:0.604590, 偏置为:0.975368
......
第193次优化的参数权重为:0.689427, 偏置为:0.819917
第194次优化的参数权重为:0.689293, 偏置为:0.819553
第195次优化的参数权重为:0.689415, 偏置为:0.819265
第196次优化的参数权重为:0.689980, 偏置为:0.819289
第197次优化的参数权重为:0.690093, 偏置为:0.819089
第198次优化的参数权重为:0.689954, 偏置为:0.818728
第199次优化的参数权重为:0.689771, 偏置为:0.818355
tensorflow 变量作用域
tf.variable_scope(<scope_name>):创建指定名字的变量作用域
import tensorflow as tf
with tf.variable_scope("data"):x = tf.random_normal([100,1], mean = 1.75, stddev = 0.5,name = "x_data")# 矩阵相乘必须保持数据是二维的y_ture = tf.matmul(x,[[0.7]]) + 0.8with tf.variable_scope("model"):# 随机给一个权重和p偏置的值,计算损失,然后在当前状态下优化# 用变量定义才能优化# trainable参数:指定这个变量能顺着梯度下降一起优化weight = tf.Variable(tf.random_normal([1,1],mean = 0.0,stddev = 1.0),name = "w")bias = tf.Variable(0.0,name = "b")y_predict = tf.matmul(x,weight) + biaswith tf.variable_scope("loss"):# 3.建立损失函数,均方误差loss = tf.reduce_mean(tf.square(y_ture - y_predict))with tf.variable_scope("optimizer"):# 4.梯度下降优化损失 leaning_rate:0.01,0.03,0.1,0.3,......train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)# 定义一个初始化变量的op
init_op = tf.global_variables_initializer()# 通过会话运行程序
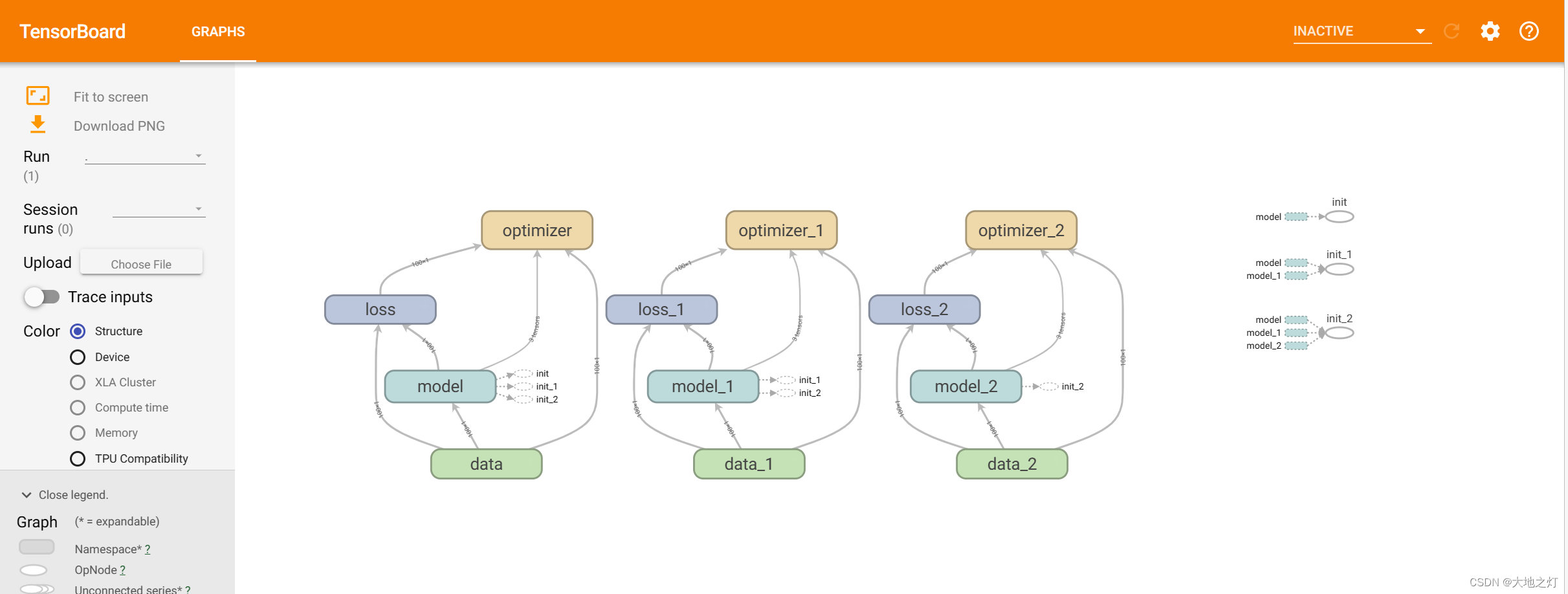
with tf.Session() as sess:# 初始化变量sess.run(init_op)# 打印随机最先初始化的权重和偏置print("随机初始化的参数权重为:%f, 偏置为:%f" %(weight.eval(),bias.eval()))# 把图结构写入事件文件filewriter = tf.summary.FileWriter("./tmp/summary/test2",graph = sess.graph)# 循环运行优化for i in range(200):sess.run(train_op)print("第%d次优化的参数权重为:%f, 偏置为:%f" % (i,weight.eval(),bias.eval()))
随机初始化的参数权重为:-0.364948, 偏置为:0.000000
第0次优化的参数权重为:0.660532, 偏置为:0.544167
第1次优化的参数权重为:0.773921, 偏置为:0.608918
第2次优化的参数权重为:0.791829, 偏置为:0.620703
第3次优化的参数权重为:0.793604, 偏置为:0.624149
第4次优化的参数权重为:0.788609, 偏置为:0.624627
第5次优化的参数权重为:0.791536, 偏置为:0.627871
第6次优化的参数权重为:0.789608, 偏置为:0.629258
第7次优化的参数权重为:0.789247, 偏置为:0.631952
第8次优化的参数权重为:0.790944, 偏置为:0.635684
......
第194次优化的参数权重为:0.709682, 偏置为:0.782486
第195次优化的参数权重为:0.709192, 偏置为:0.782562
第196次优化的参数权重为:0.709601, 偏置为:0.783022
第197次优化的参数权重为:0.709102, 偏置为:0.782941
第198次优化的参数权重为:0.709275, 偏置为:0.783254
第199次优化的参数权重为:0.709096, 偏置为:0.783376
体现在tensorboard上: