什么是页?什么是数据页?
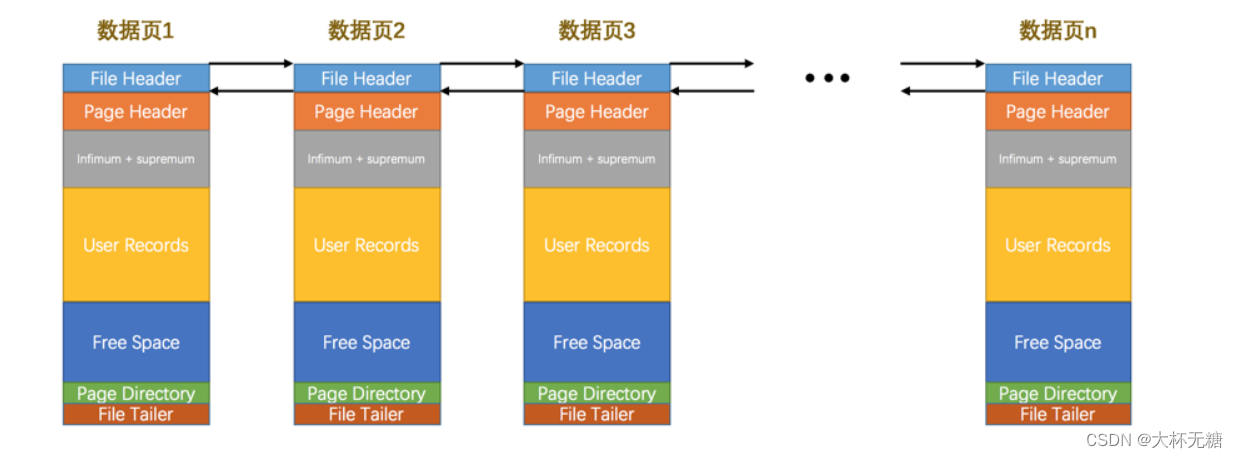
页是InnoDB管理存储空间的基本单元,一个页的大小一般是16k。
InnoDB有许多不同的页,有存放表空间头部信息的页,INODE信息的页,当然还有存放我们记录信息的页,这个页叫做索引页,也可以叫做数据页。
数据页的结构有哪些?不同的结构分别对应什么功能?
File Header : 页的通用信息
Page Header: 数据页专有的信息
Infimum + supermum : 两个虚拟的行记录
User Records :存储用户的实际记录,最开始为空,每当我们插入一条记录,都会从Free Space中申请空间划分到此处,然后记录以compact行格式进行存放。
Free Space: 页中尚未使用的空间Page Dictionary :页中某些记录的相对位置
File Tailer : 用来检验页是否完整
为了更好的管理User Records中的记录,InnoDB是怎么操作的?难道不是直接把记录按照指定的格式一条一条简单的摆放在User Records中的吗? compact记录头信息中的那一部分到底做了什么事情?
记录头信息到底做了什么?记录头信息的结构是什么?不同的结构对应的功能是什么?

预留位置一,二:没有使用
delete_mask :标记该记录是否被删除,占用一个二进制位。 被标记为1的记录被删除掉了,但是还在页面中,被标记为1的记录会组成一个垃圾链表,这个链表被占用的空间被称之为所谓的可重用空间,如果之后有新的记录插入到表中的话,被删除的记录占用的存储空间会被覆盖掉。
min_rec_mask :标记 B+树每层的非叶子节点中的最小记录 (具体什么作用还不清晰)
n_owned: 表示当前记录拥有的记录数量 (具体什么作用还不清晰)
heap_no :表示当前记录在记录堆中的位置信息 ,也可以说是在当前记录页中的位置。 记录之间通过主键可以比大小; 我们插入的数据都是从 2 开始的,0 和 1 分别代表最小记录和最大记录,这两条记录的构造十分简单,都是由5字节大小的记录头信息和8字节大小的一个固定的部分组成的。
record_type :表示当前记录的类型,0代表普通记录,1代表B+树非叶子节点,2代表最小记录,3代表最大记录。
next_record:表示下一条记录的相对位置。
总上所述,记录头信息的作用是:就是把一条一条的记录按照一定的规则联系了起来,而不是我们想的那样只是简单的将用户的记录堆放在User Records中。
next_record这个指针有点儿怪,为什么要指向记录头信息和真实数据之间的位置呢?为什么不干脆指向整条记录的开头位置,也就是记录的额外信息开头的位置呢?
因为这个位置刚刚好,向左读取就是记录头信息,向右读取就是真实数据。我们前面还说过变长字段长度列表、NULL值列表中的信息都是逆序存放,这样可以使记录中位置靠前的字段和它们对应的字段长度信息在内存中的距离更近,可能会提高高速缓存的命中率。
删除一条中间的用户记录会发生哪些变化?
1.该记录没有从存储空间中移除,而是把这条记录的delete_mask值设置为1
2. 该条记录的next_record值变成了0,意味着该条记录并没有下一条记录了
3.该条记录的前一个记录的next_record指向了该条记录的后一个记录
4. 最大记录只n_owned值从5变成了4
页目录(page Directory)是什么?是为了解决什么问题?
在页中,所有的记录是通过单链表的形式连接在一起,如果我们想要查询下面的记录,c1是主键
SELECT * FROM page_demo WHERE c1 = 3;最笨的方法是从Infimum记录开始,然后沿着单链表一直查下去,直到查出来符合条件的结果,或者直接查不出来。 如果表中的数据特别多的话,再这样一条一条记录的查找就不行了。
我们可以设置一个目录,然后我们如果想要查找某一条记录的时候,先看一下目录,然后查找内容。
InnoDB也做了一个类似的目录:
1. 将所有的记录(不包括被删除的记录)分为几个组。
2. 每个组的最后一条记录,也就是组内最大的那条记录 的头信息中的n_owned属性表示该条记录中拥有多少记录,也就是组内有多少条记录。
3. 把组内最后一条记录的地址偏移量单独提取出来按照顺序存储在靠近页的尾部的地方,这个地方就是 Page Directiory,也就是页目录。
页面中的目录的地址偏移量被称为槽,页目录也就是槽组成的。
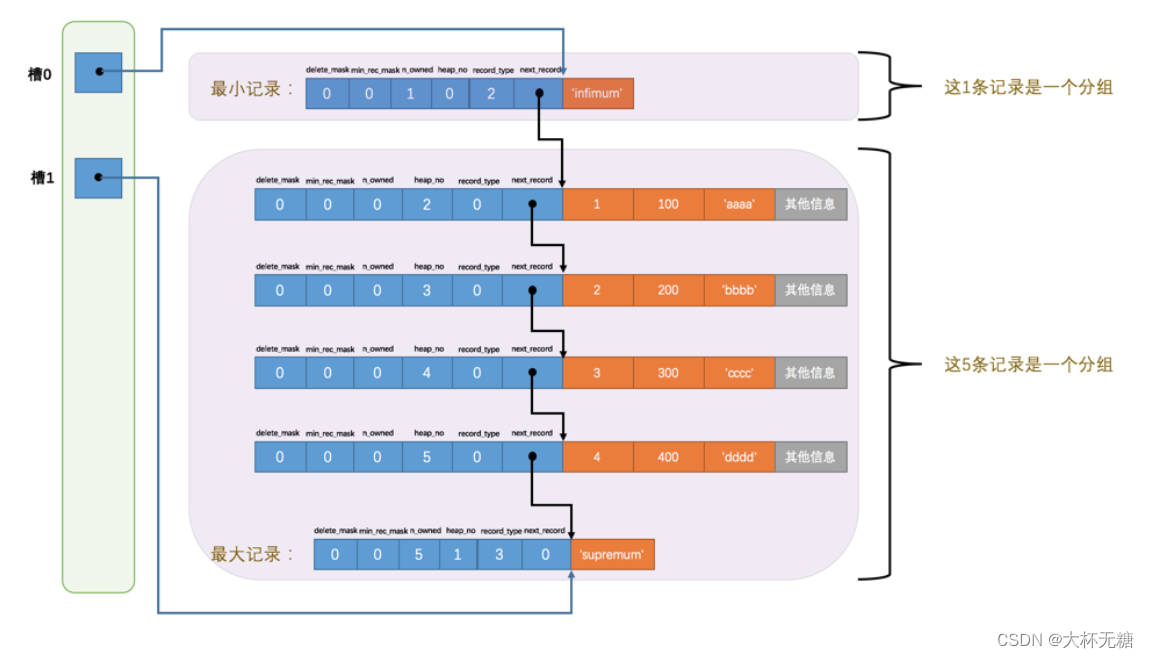
上面的图中,为什么最小记录的n_owned的值为1,而最大记录的n_owned的记录是5呢?
InnoDB对于每个组的记录条数是有规定的:对于最小记录所在的分组只能有一个记录,最大记录所在的分组可以有1-8条记录,剩下的分组中的记录条数只能是4-8 条之间。
具体分组是按照下面的步骤进行的:
初始情况只有两组,每组中只有一条记录,分别是最小记录和最大记录。
之后每次插入一条数据,都会页目录中找到主键值比本记录的主键值大,并且差值最小的槽,然后把该槽的对应的记录的n_owned记录值+1 ,表示本组内添加了一条记录,直到改组中的记录数量等于8 个。
在一个组中的记录数量等于8后,再插入一条数据,那个这个组将被拆分为两个组,一个组四条记录,一个组是五条记录,这个过程会在页目录中新增一个槽来记录这个新增分组的最大的那条记录的偏移量。

不要忘记,我们最初都是为了通过主键来定位一条数据。现在我们有了页目录,我们开始定位这条数据了。
假如说我们想要定位主键是6的数据,我们需要进行如下操作
设置low 为0 ,high 是4
先找到中间槽对应的主键:中间槽是(0+4)/ 2 = 2 ,槽2 对应的主键是8 ,8 > 6 ,设置high = 2 ,low不变
然后再计算中间槽 (0 + 2) = 1 ,槽1对应的主键是4 , 4 < 6 ,设置low = 1
此时higt - low 的值是1 ,所以 该主键就是在第high个组内 ,也就是槽2中 。 然后我们只需要找到槽2中主键最小的那条记录,然后沿着单向链表遍历槽2即可找到数据。
还有一个问题是我们现在知道该条记录是在槽2中的,同时我们也知道了槽2的最大主键记录,但是我们其实是从槽2的最小记录开始遍历,这个时候该怎么找到槽2的最小记录呢?
正确做法是,我们可以先拿到刚才记录出来的槽1,然后拿到槽1的最大记录,槽1和槽2是互相紧邻的,然后往后一下,就是槽2的最小记录了。
总结一下,在一个数据页中查找主键值的记录的过程分为两步:
1. 通过二分法确定该记录所在的槽的位置,并找到该槽中主键值最小的那条记录。
2. 通过next_record 属性遍历该槽所在的组中的各个记录。
综上所述,目录页的作用就是把User Record中分组的数据安装索引一一对应起来,方便通过主键进行数据的查找。
Page Header(页面头部)是干什么的?
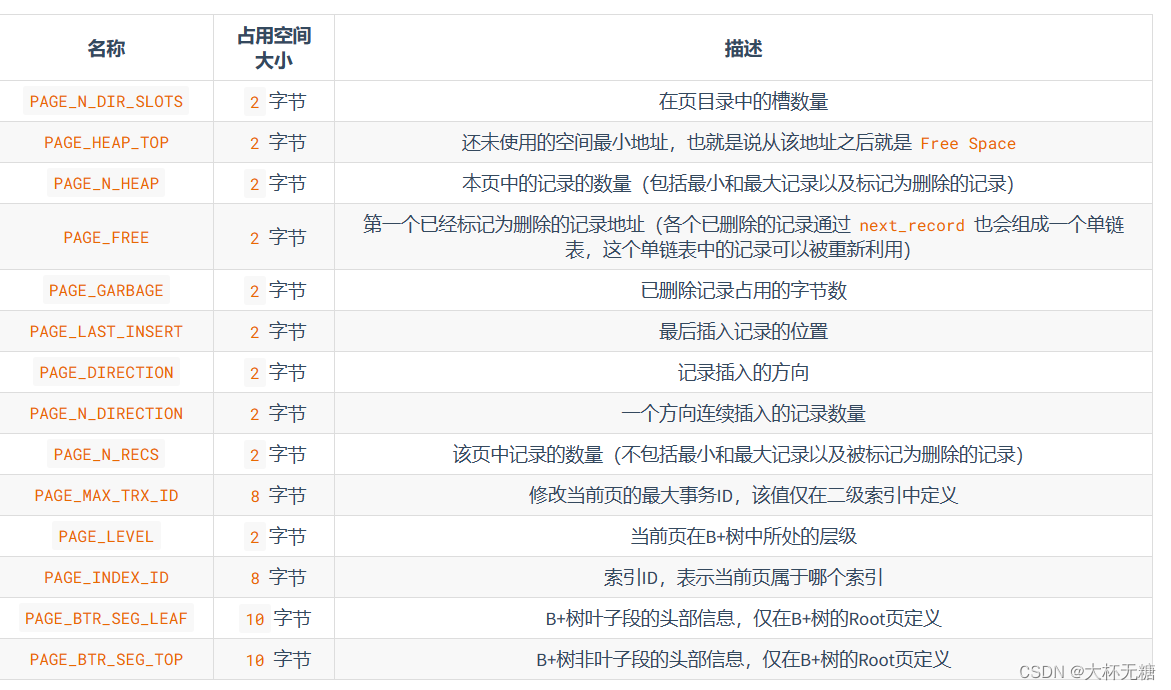
记录数据页中存储的记录的状态信息,比如说本页中存储了多少条记录,第一条记录的地址是什么? 页目录中存储了多少个槽 ? Page Header也页的第二部分,占用固定的56个字节。
File Header (文件头部)是干什么的?
之前介绍的Page Header是专门针对数据页的,不是所有页特有的,现在的File Header文件头部是公有的,也就是说,不同类型的页都会有个File Header 部分,并且作为第一组成部分,File Header记录是一些针对各种页都通用的信息,比如说,此页的编号,他的上一个页,下一个页是谁等等,固定38个字节。

FIL_PAGE_SPACE_OR_CHKSUM 是页面的校验和,用来把长的字符串通过一定的算法转化成比较短的值,到时候比较的时候,不再直接把字符串进行比较,而是使用校验和来进行比较,从而提升性能。
Fil_PAGE_OFFSET:页的号码,就像身份中一样,通过页号定位一个页。
FIL_PAGE_TYPE : 页的类型,除了我们上面一直说的索引页(也叫数据页),还有其他好多类型
FIL_PAGE_PREV 和 FIL_PAGE_NEXT ,数据非常多的时候,是被存储在不同的页中,页在物理空间上并不相邻,这个时候InnoDB是同过双向链表把页给连接起来的,这个两个字段就是连接的字段。
File Trailer
用来检验页面是否完整。