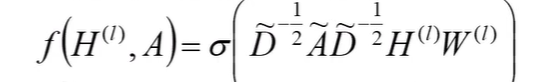GraphGAN: Graph Representation Learning with GAN
- 1、Introduction
- 2、GraphGAN Framework
- 2.1 Optimization
- Discriminator Optimization
- Generator Optimization
- Graph Softmax for Generator
1、Introduction
网络表示学习方法可以分成两个类别。
-
Generative model假定对于每一个顶点 v c v_c vc ,在图中存在一个潜在的、真实的连续性分布 P t r u e ( v ∣ v c ) P_{true}(v|v_c) Ptrue(v∣vc), 图中的每条边都可以看作是从 P t r u e P_{true} Ptrue里采样的一些样本,暗示着节点 v c v_c vc 在整个网络中的连接偏好,因此网络中的边,其实也可以被看作是这些条件分布概率的观测样本,因此这些生成式表示学习算法的目的就是最大化网络中边的似然生成式方法都试图将边的似然概率最大化,来学习vertex embedding。例如DeepWalk (KDD 2014) and node2vec (KDD 2016)。
-
Discriminative Model 将两顶点联合作为 f e a t u r e feature feature,预测两点之间存在边的概率。判别式模型认为边不是条件分布得到的,而是直接通过训练学习一个判别器来直接预测两两节点之间,是否存在会存在边。典型的判别式模型,就是将网络中的训练集上的每两个节点 v i v_i vi 和 v j v_j vj 都看作是特征,然后预测两点之间存在边的概率 p ( e d a g e ∣ ( v i , v j ) ) p(edage|(v_{i},v_{j})) p(edage∣(vi,vj)) 。例如SDNE (KDD 2016) and PPNE (DASFAA, 2017)。
本文创新点:
1、GraphGAN 结合非常popular的GAN设计了一个 game-theoretical minimax game 将两者结合。
2、graph softmax 克服了传统的softmax函数的局限性,证明该函数满足规范化、图结构感知和计算效率的要求。
- s o f t m a x softmax softmax对给定顶点的图中所有其他顶点都是平等的,没有考虑图的结构和邻近信息
- s o f t m a x softmax softmax的计算涉及到图中的所有顶点,这既耗时又效率低下
- 提出了一种基于随机游走的生成器在线生成策略,该策略符合图 s o f t m a x softmax softmax的定义,可以大大降低计算复杂度。
2、GraphGAN Framework

在GraphGAN中,主要有两个模型:

对于 G G G来说,它的目标是生成与 v c v_c vc 真实连接的邻居节点相似的点,来骗过判别器 D D D;而对于 D D D,它的目标是判别这些节点哪些是 v c v_c vc的真实邻居,哪些是它的对手 G G G生成的节点。因此,两个对手的一个 m i n i m a x minimax minimax游戏的目标函数 ( 1 ) (1) (1)为:



理解了公式 ( 1 ) (1) (1)就基本理解了 G r a p h G A N GraphGAN GraphGAN的内在原理,上图给出 G r a p h G A N GraphGAN GraphGAN工作的流程。 θ D θ_D θD和 θ G θ_G θG可以通过交替最小化和最大化 V ( G , D ) V(G,D) V(G,D)函数来迭代更新得到。每次迭代,我们从 P t r u e P_{true} Ptrue 中 抽样一些跟 V c V_c Vc 真实相邻的绿点,从 G G G 中又生成了一些跟 V c V_c Vc接近的蓝点。我们将绿点作为正样本,将蓝点作为负样本来训练 D D D,在得到 D D D 之后,再用 D D D 中的信号,通过 p o l i c y g r a d i e n t policy\ gradient policy gradient去反过来训练 G G G。不断重复这个过程,直到生成器 G G G 和 P t r u e P_{true} Ptrue极为接近。在刚开始的时候, G G G 相对比较差,因此对于给定的 V c V_c Vc 而言, G s a m p l e G\ sample G sample 的点都是一些离 V c V_c Vc 很远的点。随着训练的不断进行, G s a m p l e G\ sample G sample 的点会逐渐向 V c V_c Vc 接近,到最后 G G G 抽样的点几乎都变成了真正跟 V c V_c Vc 相邻的点,也就是 G G G 和 P t r u e P_{true} Ptrue 已经很难被区分了
生成器和判别器的参数是不断地交替训练进行更新的。每一次迭代,判别器 D D D通过来自 P t r u e ( v ∣ v c ) P_{true}(v|v_c) Ptrue(v∣vc)的正样本(图例中所示的绿色节点)和来自 G G G的负样本(图例中为蓝条纹节点)进行训练;生成器 G G G则通过 D D D的指导,按照梯度策略进行更新。
2.1 Optimization
Discriminator Optimization

Generator Optimization



Graph Softmax for Generator







证明:

- 对于每个叶子节点 v v v,其只有一个父节点,故 p c ( v r m − 1 ∣ v r m ) = p c ( v r m − 1 ∣ v ) = 1 p_{c}(v_{r_{m-1}}|v_{r_{m}})=p_{c}(v_{r_{m-1}}|v)=1 pc(vrm−1∣vrm)=pc(vrm−1∣v)=1

- 对于每个非叶子节点 v v v,我们定义 C c ( v ) C_{c}(v) Cc(v)为节点 v v v的孩子节点的集合,每个孩子节点 v k ∈ C c ( v ) v_{k} \in C_{c}(v) vk∈Cc(v)


论文链接:GraphGAN
代码链接:https://github.com/hwwang55