本文来自CS-NOTES
https://cyc2018.github.io/CS-Notes/#/
面试考察的知识点多而杂,要完全掌握需要花费大量的时间和精力。但是面试中经常被问到的知识点却没有多少,你完全可以用 20% 的时间去掌握 80% 常问的知识点。
本文虽然来自CS-NOTES中,但是觉得里面有些地方解释的不够清楚,不够通俗易懂,所以写了本篇文章。
另外再附赠一份java面试题以及答案,内容也还不错,偏向于java基础。
链接:https://pan.baidu.com/s/1Ff7cP5xAll4jtbS3OTkmqA
提取码:ka1n
首先是九大复习重点

CSDN出现了问题,不知道怎么的,这段空白删除不了!!!!!!
目录
一. 算法
1.1 排序:大部分要求能手写,并分析时间空间复杂度,以及稳定性。
1.2 树:红黑树的原理以及再JDK中的使用。B+树以及在数据库索引中的使用。
1.3 图:拓扑排序,并查集。最短路径。最小生成树。
1.4 散列表:实现原理,以及在JDK中的使用。
1.5 字符串:KMP。AC自动机。Trie树。
二. 操作系统
2.1 基础
2.1.1★★★ 进程与线程的本质区别、以及各自的使用场景。
2.1.2 ★★★ 进程调度算法的特点以及使用场景。
2.1.3 ★★☆ 常见进程同步问题。
2.1.4 ★★★ 进程通信方法的特点以及使用场景。
2.1.5 ★★★ 死锁必要条件、解决死锁策略,能写出和分析死锁的代码,能说明在数据库管理系统或者 Java 中如何解决死锁。
2.1.6 ★★★ 虚拟内存的作用,分页系统实现虚拟内存原理。
2.1.7 ★★★ 页面置换算法的原理
2.1.8 ★★★ 比较分页与分段的区别。
2.2 Linux
2.2.1 ★★☆ 文件系统的原理,特别是 inode 和 block。
2.2.2 ★★★ 硬链接与软链接的区别。
2.2.3 ★★☆ 能够使用常用的命令,比如 cat 文件内容查看、find 搜索文件,以及 cut、sort 等管线命令。了解 grep 和 awk 的作用。
2.2.4 ★★★ 僵尸进程与孤儿进程的区别
三. 网络
3.1 基础
3.1.1 ★★★ 各层协议的作用,以及 TCP/IP 协议的特点。
3.1.2 ★★☆ 以太网的特点,以及帧结构。
3.1.3 ★★☆ 集线器、交换机、路由器的作用,以及所属的网络层。
3.1.4 ★★☆ IP 数据数据报常见字段的作用。
3.1.5 ★★★ 理解三次握手以及四次挥手具体过程,三次握手的原因、四次挥手原因、TIME_WAIT 的作用。
3.1.6 ★★☆ TCP 拥塞控制的作用,理解具体原理。
3.2 HTTP
3.2.1 ★★★ GET 与 POST 比较:作用、参数、安全性、幂等性、可缓存。
3.2.2 ★★☆ HTTP 状态码。
3.2.3 ★★★ Cookie 作用、安全性问题、和 Session 的比较。
3.2.4 ★★☆ 缓存 的Cache-Control 字段,特别是 Expires 和 max-age 的区别。
3.2.5 ★★★ 长连接与短连接原理以及使用场景,流水线。
3.2.6 ★★★ HTTP 存在的安全性问题,以及 HTTPs 的加密、认证和完整性保护作用。
3.3 Socket
3.3.1★★☆ 五种 IO 模型的特点以及比较。
3.3.2 ★★★ select、poll、epoll使用场景;
四. 数据库
4.1 SQL
4.1.1★★☆ 手写 SQL 语句,特别是连接查询与分组查询。
4.2 系统原理
4.2.1 ★★★ ACID 的作用以及实现原理。
4.2.2 ★★★ 四大隔离级别,以及不可重复读和幻影读的出现原因。
4.2.3 ★★☆ 封锁粒度
4.2.4 ★★★ 乐观锁与悲观锁。
4.2.5 ★★☆ 范式理论。
4.2.6 ★★★ SQL 与 NoSQL 的比较。
4.3 MySQL
4.3.1 ★★★ B+ Tree 原理,与其它查找树的比较。
4.3.2 ★★★ MySQL 索引以及优化。
4.3.3 ★★★ 查询优化。
4.3.4 ★★★ InnoDB 与 MyISAM 比较。
4.3.5 ★★☆ 水平切分与垂直切分。
4.3.6 ★★☆ 主从复制原理、作用、实现。
4.4 Redis
4.4.1 ★★☆ 跳跃表原理分析。
4.4.2 ★★★ Redis使用场景。
加油!
加油!
加油!
加油!
加油!
加油!
加油!
加油!
加油!
加油!
加油!
加油!
加油!
加油!
加油!
加油!
4.2.3 ★★★ Redis与 Memchached 的比较。
4.2.4 ★★☆ RDB 和 AOF 持久化机制。
4.2.5 ★★☆ 事件驱动模型。
4.2.6 ★★★ 集群与分布式。
4.2.7 ★★☆ 事务原理。
五. 面向对象
5.1 思想
5.1.1 ★★★ 面向对象三大特性
5.1.2 ★☆☆ 设计原则
5.2 设计模式
5.2.1★★★ 手写单例模式
5.2.2 ★★★ 手写工厂模式。
5.2.3 ★★★ 理解 MVC
5.2.4 ★★★ 分析 JDK 中常用的设计模式。
六. 框架
6.1 spring boot
6.1.1 Json的使用
6.1.2 Spring Boot使用slf4j进行日志记录
一. 算法
1.1 排序:大部分要求能手写,并分析时间空间复杂度,以及稳定性。
public class test {public static void main(String[] strings){//Arrays.sort()对原始数据类型采用三向切分快速排序//对引用数据类型采用归并排序int[] array={2,5,1,4,7,3,20,11,0,30,3,3};//选择排序//selectSort(array);//冒泡排序//bubbleSort(array);//插入排序//insertSort(array);//希尔排序//shellSort(array);//归并排序//int[] temp=new int[array.length];//mergeSort(array,temp,0,array.length-1);//快速排序//quickSort(array,0,array.length-1);//快速选择//System.out.println(quickSelect(array,2));//三向切分快速排序threeWayQuickSort(array,0,array.length-1);for(int x:array){System.out.print(" "+x);}}//换位的函数public static void swap(int[] array,int i,int j){int temp=array[i];array[i]=array[j];array[j]=temp;}//选择排序,暴力解法,让当前和后面的每一个进行比较,找到最小的public static void selectSort(int[] array){for(int i=0;i<array.length-1;i++){for(int j=i+1;j<array.length;j++){if(array[i]>array[j]){swap(array,i,j);}}}}//冒泡排序,暴力解法,让最小的不断移动,一直移动到最上面public static void bubbleSort(int[] array){for(int i=array.length-1;i>0;i--){for(int j=0;j<i;j++){if(array[j]>array[j+1]){swap(array,j,j+1);}}}}//插入排序,不断遍历,将当前的插入到前面已经排序的数组中//时间复杂度与初始顺序有关public static void insertSort(int[] array){for(int i=1;i<array.length;i++){for(int j=i;j>0&&array[j]<array[j-1];j--){swap(array,j,j-1);}}}//希尔排序,和插入排序类似,只不过分组跳跃了一下,虽然比较的次数增多了,但是换位少了public static void shellSort(int[] array){int N=array.length;int h=1;while(h<N/3){h=h*3+1;//1,4,13......}while(h>=1) {for (int i = h; i < N; i++) {for (int j = i; j >= h && array[j] < array[j - h]; j -= h) {swap(array, j, j - h);}}h = h / 3;}}//归并排序,先递归,把他们全分开,然后再根据大小关系进行合并public static void mergeSort(int[] array,int[] temp,int left,int right){if(left>=right){return;}int mid=(left+right)/2;mergeSort(array,temp,left,mid);mergeSort(array,temp,mid+1,right);merge(array,temp,left,mid,right);}public static void merge(int[] array,int[] temp,int left,int mid,int right){int i=left;int j=mid+1;for(int k=left;k<=right;k++){temp[k]=array[k];}for(int k=left;k<=right;k++){if(i>mid){array[k]=temp[j++];}else if(j>right){array[k]=temp[i++];}else if(temp[i]<temp[j]){array[k]=temp[i++];}else if(temp[i]>=temp[j]){array[k]=temp[j++];}}}//快速排序,每次都选最左边的元素作为基准,然后,左侧寻找大于它的,右侧寻找小于它的,找到互换位置//这样就保证了左边的元素都比此值小,右边的都大//继续递归public static void quickSort(int[] array,int left,int right){if(right<=left){return;}int j=partition(array,left,right);quickSort(array,left,j-1);quickSort(array,j+1,right);}//切分public static int partition(int[] array,int left,int right){int val=array[left];int i=left;int j=right+1;while(true){while (array[++i]<val&&i!=right);while (array[--j]>=val&&j!=left);if(i>=j){break;}swap(array,i,j);}swap(array,left,j);return j;}//这里插入一个算法,就是基于切分的快速选择算法//我们不需要排序,选出第k个小的元素public static int quickSelect(int[] array,int k){int l=0;int r=array.length-1;while(l<r){int j=partition(array,l,r);if(j==k){return array[k];}else if(j>k){r=j-1;}else if(j<k){l=j+1;}}return array[k];}//三向切分快速排序,把重复的元素放到中间,小于它的在左边,大于它的在右边//适用于有大量重复元素的数组排序public static void threeWayQuickSort(int[] array,int left,int right){if(right<=left){return;}int l=left;int r=right;int i=left+1;int val=array[left];//有等号while(i<=r){if(array[i]<val){swap(array,i++,l++);}else if(array[i]>val){swap(array,i,r--);}else{i++;}}threeWayQuickSort(array,left,l-1);threeWayQuickSort(array,r+1,right);}
}
| 算法 | 稳定性 | 时间复杂度 | 空间复杂度 | 备注 |
|---|---|---|---|---|
| 选择排序 | × | N2 | 1 | |
| 冒泡排序 | √ | N2 | 1 | |
| 插入排序 | √ | N ~ N2 | 1 | 时间复杂度和初始顺序有关 |
| 希尔排序 | × | N 的若干倍乘于递增序列的长度 | 1 | 改进版插入排序 |
| 快速排序 | × | NlogN | logN | |
| 三向切分快速排序 | × | N ~ NlogN | logN | 适用于有大量重复主键 |
| 归并排序 | √ | NlogN | N | |
| 堆排序 | × | NlogN | 1 | 无法利用局部性原理 |
应用场景分析:
n比较小的时候选择排序和插入排序都可以。
原数组多数已经排序,冒泡排序和插入排序都可以。
n比较大的时候可以采用快速排序,堆排序归并排序。
快速排序是目前基于比较的内部排序中被认为是最好的方法,当待排序的关键字是随机分布时,快速排序的平均时间最短。
堆排序所需的辅助空间少于快速排序,并且不会出现快速排序可能出现的最坏情况。这两种排序都是不稳定的。
若要求排序稳定,则可选用归并排序。
快速排序最坏的情况?
每次都是和第一个数字进行比较,最好的情况可以实现二分,最坏的情况是分成一个和其他部分,有点退化成冒泡了。
稳定性分析:
通俗地讲就是能保证排序前2个相等的数其在序列的前后位置顺序和排序后它们两个的前后位置顺序相同。在简单形式化一下,如果Ai = Aj, Ai原来在位置前,排序后Ai还是要在Aj位置前。那么它就是稳定的。
1)冒泡排序
冒泡排序就是把小的元素往前调或者把大的元素往后调。比较是相邻的两个元素比较,交换也发生在这两个元素之间。所以,如果两个元素相等,我想你是不会再无聊地把他们俩交换一下的;如果两个相等的元素没有相邻,那么即使通过前面的两两交换把两个相邻起来,这时候也不会交换,所以相同元素的前后顺序并没有改 变,所以冒泡排序是一种稳定排序算法。
(2)选择排序
选择排序是给每个位置选择当前元素最小的,比如给第一个位置选择最小的,在剩余元素里面给第二个元素选择第二小的,依次类推,直到第n-1个元素,第n个 元素不用选择了,因为只剩下它一个最大的元素了。那么,在一趟选择,如果当前元素比一个元素小,而该小的元素又出现在一个和当前元素相等的元素后面,那么 交换后稳定性就被破坏了。比较拗口,举个例子,序列5 8 5 2 9, 我们知道第一遍选择第1个元素5会和2交换,那么原序列中2个5的相对前后顺序就被破坏了,所以选择排序不是一个稳定的排序算法。
(3)插入排序
插入排序是在一个已经有序的小序列的基础上,一次插入一个元素。当然,刚开始这个有序的小序列只有1个元素,就是第一个元素。比较是从有序序列的末尾开 始,也就是想要插入的元素和已经有序的最大者开始比起,如果比它大则直接插入在其后面,否则一直往前找直到找到它该插入的位置。如果碰见一个和插入元素相 等的,那么插入元素把想插入的元素放在相等元素的后面。所以,相等元素的前后顺序没有改变,从原无序序列出去的顺序就是排好序后的顺序,所以插入排序是稳 定的。
(4)快速排序
快速排序有两个方向,左边的i下标一直往右走,当a[i] <= a[center_index],其中center_index是中枢元素的数组下标,一般取为数组第0个元素。而右边的j下标一直往左走,当a[j] > a[center_index]。如果i和j都走不动了,i <= j, 交换a[i]和a[j],重复上面的过程,直到i>j。 交换a[j]和a[center_index],完成一趟快速排序。在中枢元素和a[j]交换的时候,很有可能把前面的元素的稳定性打乱,比如序列为 5 3 3 4 3 8 9 10 11, 现在中枢元素5和3(第5个元素,下标从1开始计)交换就会把元素3的稳定性打乱,所以快速排序是一个不稳定的排序算法,不稳定发生在中枢元素和a[j] 交换的时刻。
(5)归并排序
归并排序是把序列递归地分成短序列,递归出口是短序列只有1个元素(认为直接有序)或者2个序列(1次比较和交换),然后把各个有序的段序列合并成一个有 序的长序列,不断合并直到原序列全部排好序。可以发现,在1个或2个元素时,1个元素不会交换,2个元素如果大小相等也没有人故意交换,这不会破坏稳定 性。那么,在短的有序序列合并的过程中,稳定是否受到破坏?没有,合并过程中我们可以保证如果两个当前元素相等时,我们把处在前面的序列的元素保存在结 果序列的前面,这样就保证了稳定性。所以,归并排序也是稳定的排序算法。
(7)希尔排序(shell)
希尔排序是按照不同步长对元素进行插入排序,当刚开始元素很无序的时候,步长最大,所以插入排序的元素个数很少,速度很快;当元素基本有序了,步长很小, 插入排序对于有序的序列效率很高。所以,希尔排序的时间复杂度会比o(n^2)好一些。由于多次插入排序,我们知道一次插入排序是稳定的,不会改变相同元 素的相对顺序,但在不同的插入排序过程中,相同的元素可能在各自的插入排序中移动,最后其稳定性就会被打乱,所以shell排序是不稳定的。
(8)堆排序
我们知道堆的结构是节点i的孩子为2*i和2*i+1节点,大顶堆要求父节点大于等于其2个子节点,小顶堆要求父节点小于等于其2个子节点。在一个长为n 的序列,堆排序的过程是从第n/2开始和其子节点共3个值选择最大(大顶堆)或者最小(小顶堆),这3个元素之间的选择当然不会破坏稳定性。但当为n /2-1, n/2-2, ...1这些个父节点选择元素时,就会破坏稳定性。有可能第n/2个父节点交换把后面一个元素交换过去了,而第n/2-1个父节点把后面一个相同的元素没 有交换,那么这2个相同的元素之间的稳定性就被破坏了。所以,堆排序不是稳定的排序算法。
综上,得出结论: 选择排序、快速排序、希尔排序、堆排序不是稳定的排序算法,而冒泡排序、插入排序、归并排序和基数排序是稳定的排序算法。
1.2 树:红黑树的原理以及再JDK中的使用。B+树以及在数据库索引中的使用。
红黑树:参考https://blog.csdn.net/eson_15/article/details/51144079
B+树参考:https://blog.csdn.net/qq_26222859/article/details/80631121
B+树的特征:
1.每一个父节点的元素都出现在子节点上,是子节点的最大或者最小。
2.根节点的最大元素等同于整个B+树的最大元素。
3.父节点都出现在子节点中,所以叶子节点包含所有的信息。
4.叶子节点在同一层,且是一个有链表。
B+树的优势:
1.单一节点存储更多的元素,使得查询的IO次数更少。
2.所有查询都要查找到叶子节点,查询性能稳定。
3.所有叶子节点形成有序链表,便于范围查询。
1.3 图:拓扑排序,并查集。最短路径。最小生成树。
拓扑排序参考:
并查集:参考https://blog.csdn.net/niushuai666/article/details/6662911
看完之后的感受,太tm厉害了!!!!!!!!!!忍不住口吐芬芳了
例子就是杭电上的畅通工程:
http://acm.hdu.edu.cn/showproblem.php?pid=1232
首先在地图上给你若干个城镇,这些城镇都可以看作点,然后告诉你哪些对城镇之间是有道路直接相连的。最后要解决的是整幅图的连通性问题。比如随意给你两个点,让你判断它们是否连通,或者问你整幅图一共有几个连通分支,也就是被分成了几个互相独立的块。像畅通工程这题,问还需要修几条路,实质就是求有几个连通分支。
如果是1个连通分支,说明整幅图上的点都连起来了,不用再修路了;如果是2个连通分支,则只要再修1条路,从两个分支中各选一个点,把它们连起来,那么所有的点都是连起来的了;如果是3个连通分支,则只要再修两条路……
以下面这组数据输入数据来说明
4 2 1 3 4 3
第一行告诉你,一共有4个点,2条路。下面两行告诉你,1、3之间有条路,4、3之间有条路。那么整幅图就被分成了1-3-4和2两部分。只要再加一条路,把2和其他任意一个点连起来,畅通工程就实现了,那么这个这组数据的输出结果就是1。好了,现在编程实现这个功能吧,城镇有几百个,路有不知道多少条,而且可能有回路。 这可如何是好?
我以前也不会呀,自从用了并查集之后,嗨,效果还真好!我们全家都用它!并查集由一个整数型的数组和两个函数构成。数组pre[]记录了每个点的前导点是什么,函数find是查找,join是合并。
int pre[1010]; //存放第i个元素的父节点int unionsearch(int root) //查找根结点{int son, tmp;son = root;while(root != pre[root]) //寻找根结点root = pre[root];while(son != root) //路径压缩{tmp = pre[son];pre[son] = root;son = tmp;}return root;}void join(int root1, int root2) //判断是否连通,不连通就合并{int x, y;x = unionsearch(root1);y = unionsearch(root2);if(x != y) //如果不连通,就把它们所在的连通分支合并pre[x] = y;}
为了解释并查集的原理,我将举一个更有爱的例子。
话说江湖上散落着各式各样的大侠,有上千个之多。他们没有什么正当职业,整天背着剑在外面走来走去,碰到和自己不是一路人的,就免不了要打一架。但大侠们有一个优点就是讲义气,绝对不打自己的朋友。而且他们信奉“朋友的朋友就是我的朋友”,只要是能通过朋友关系串联起来的,不管拐了多少个弯,都认为是自己人。这样一来,江湖上就形成了一个一个的帮派,通过两两之间的朋友关系串联起来。而不在同一个帮派的人,无论如何都无法通过朋友关系连起来,于是就可以放心往死了打。但是两个原本互不相识的人,如何判断是否属于一个朋友圈呢?
我们可以在每个朋友圈内推举出一个比较有名望的人,作为该圈子的代表人物。这样,每个圈子就可以这样命名“中国同胞队”美国同胞队”……两人只要互相对一下自己的队长是不是同一个人,就可以确定敌友关系了。
但是还有问题啊,大侠们只知道自己直接的朋友是谁,很多人压根就不认识队长要判断自己的队长是谁,只能漫无目的的通过朋友的朋友关系问下去:“你是不是队长?你是不是队长?”这样,想打一架得先问个几十年,饿都饿死了,受不了。这样一来,队长面子上也挂不住了,不仅效率太低,还有可能陷入无限循环中。于是队长下令,重新组队。队内所有人实行分等级制度,形成树状结构,我队长就是根节点,下面分别是二级队员、三级队员。每个人只要记住自己的上级是谁就行了。遇到判断敌友的时候,只要一层层向上问,直到最高层,就可以在短时间内确定队长是谁了。由于我们关心的只是两个人之间是否是一个帮派的,至于他们是如何通过朋友关系相关联的,以及每个圈子内部的结构是怎样的,甚至队长是谁,都不重要了。所以我们可以放任队长随意重新组队,只要不搞错敌友关系就好了。于是,门派产生了。
下面我们来看并查集的实现。 int pre[1000]; 这个数组,记录了每个大侠的上级是谁。大侠们从1或者0开始编号(依据题意而定),pre[15]=3就表示15号大侠的上级是3号大侠。如果一个人的上级就是他自己,那说明他就是掌门人了,查找到此为止。也有孤家寡人自成一派的,比如欧阳锋,那么他的上级就是他自己。每个人都只认自己的上级。比如胡青牛同学只知道自己的上级是杨左使。张无忌是谁?不认识!要想知道自己的掌门是谁,只能一级级查上去。
find这个函数就是找掌门用的,意义再清楚不过了(路径压缩算法先不论,后面再说)。
int unionsearch(int root) //查找根结点{int son, tmp;son = root;while(root != pre[root]) //我的上级不是掌门root = pre[root];while(son != root) //我就找他的上级,直到掌门出现{tmp = pre[son];pre[son] = root;son = tmp;}return root; //掌门驾到~~}
再来看看join函数,就是在两个点之间连一条线,这样一来,原先它们所在的两个板块的所有点就都可以互通了。这在图上很好办,画条线就行了。但我们现在是用并查集来描述武林中的状况的,一共只有一个pre[]数组,该如何实现呢? 还是举江湖的例子,假设现在武林中的形势如图所示。虚竹帅锅与周芷若MM是我非常喜欢的两个人物,他们的终极boss分别是玄慈方丈和灭绝师太,那明显就是两个阵营了。我不希望他们互相打架,就对他俩说:“你们两位拉拉勾,做好朋友吧。”他们看在我的面子上,同意了。这一同意可非同小可,整个少林和峨眉派的人就不能打架了。这么重大的变化,可如何实现呀,要改动多少地方?其实非常简单,我对玄慈方丈说:“大师,麻烦你把你的上级改为灭绝师太吧。这样一来,两派原先的所有人员的终极boss都是师太,那还打个球啊!反正我们关心的只是连通性,门派内部的结构不要紧的。”玄慈一听肯定火大了:“我靠,凭什么是我变成她手下呀,怎么不反过来?我抗议!”于是,两人相约一战,杀的是天昏地暗,风云为之变色啊,但是啊,这场战争终究会有胜负,胜者为王。弱者就被吞并了。反正谁加入谁效果是一样的,门派就由两个变成一个了。这段函数的意思明白了吧?
void join(int root1, int root2) //虚竹和周芷若做朋友{int x, y;x = unionsearch(root1);//我老大是玄慈y = unionsearch(root2);//我老大是灭绝if(x != y) pre[x] = y; //打一仗,谁赢就当对方老大}
再来看看路径压缩算法。建立门派的过程是用join函数两个人两个人地连接起来的,谁当谁的手下完全随机。最后的树状结构会变成什么样,我也无法预知,一字长蛇阵也有可能。这样查找的效率就会比较低下。最理想的情况就是所有人的直接上级都是掌门,一共就两级结构,只要找一次就找到掌门了。哪怕不能完全做到,也最好尽量接近。这样就产生了路径压缩算法。
设想这样一个场景:两个互不相识的大侠碰面了,想知道能不能干一场。 于是赶紧打电话问自己的上级:“你是不是掌门?” 上级说:“我不是呀,我的上级是谁谁谁,你问问他看看。” 一路问下去,原来两人的最终boss都是东厂曹公公。 “哎呀呀,原来是自己人,有礼有礼,在下三营六组白面葫芦娃!” “幸会幸会,在下九营十八组仙子狗尾巴花!” 两人高高兴兴地手拉手喝酒去了。 “等等等等,两位大侠请留步,还有事情没完成呢!”我叫住他俩。 “哦,对了,还要做路径压缩。”两人醒悟。 白面葫芦娃打电话给他的上级六组长:“组长啊,我查过了,其实偶们的掌门是曹公公。不如偶们一起结拜在曹公公手下吧,省得级别太低,以后查找掌门麻烦。”
“唔,有道理。” 白面葫芦娃接着打电话给刚才拜访过的三营长……仙子狗尾巴花也做了同样的事情。 这样,查询中所有涉及到的人物都聚集在曹公公的直接领导下。每次查询都做了优化处理,所以整个门派树的层数都会维持在比较低的水平上。路径压缩的代码,看得懂很好,看不懂可以自己模拟一下,很简单的一个递归而已。总之它所实现的功能就是这么个意思。
于是,问题圆满解决。。。。。。。。。
代码如下:
#include<iostream>#include<cstdio>#include<cstring>#include<cmath>#include<algorithm>using namespace std;int pre[1010]; //里面全是掌门int unionsearch(int root){int son, tmp;son = root;while(root != pre[root]) //寻找掌门ing……root = pre[root];while(son != root) //路径压缩{tmp = pre[son];pre[son] = root;son = tmp;}return root; //掌门驾到~}int main(){int num, road, total, i, start, end, root1, root2;while(scanf("%d%d", &num, &road) && num){total = num - 1; //共num-1个门派for(i = 1; i <= num; ++i) //每条路都是掌门pre[i] = i;while(road--){scanf("%d%d", &start, &end); //他俩要结拜root1 = unionsearch(start);root2 = unionsearch(end);if(root1 != root2) //掌门不同?踢馆!~{pre[root1] = root2;total--; //门派少一个,敌人(要建的路)就少一个}}printf("%d\n", total);//天下局势:还剩几个门派}return 0;}
1.4 散列表:实现原理,以及在JDK中的使用。
参考https://blog.csdn.net/duan19920101/article/details/51579136?utm_source=distribute.pc_relevant.none-task
(1)什么是哈希表?
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
记录的存储位置=f(关键字)
这里的对应关系f称为散列函数,又称为哈希(Hash函数),采用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间称为散列表或哈希表(Hash table)。
哈希表hashtable(key,value) 就是把Key通过一个固定的算法函数既所谓的哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里。 而当使用哈希表进行查询的时候,就是再次使用哈希函数将key转换为对应的数组下标,并定位到该空间获取value,如此一来,就可以充分利用到数组的定位性能进行数据定位。
(2)结构
数组的特点是:寻址容易,插入和删除困难;
而链表的特点是:寻址困难,插入和删除容易。
那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是我们要提起的哈希表,哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法——拉链法,我们可以理解为“链表的数组”,如图:
左边很明显是个数组,数组的每个成员包括一个指针,指向一个链表的头,当然这个链表可能为空,也可能元素很多。我们根据元素的一些特征把元素分配到不同的链表中去,也是根据这些特征,找到正确的链表,再从链表中找出这个元素。
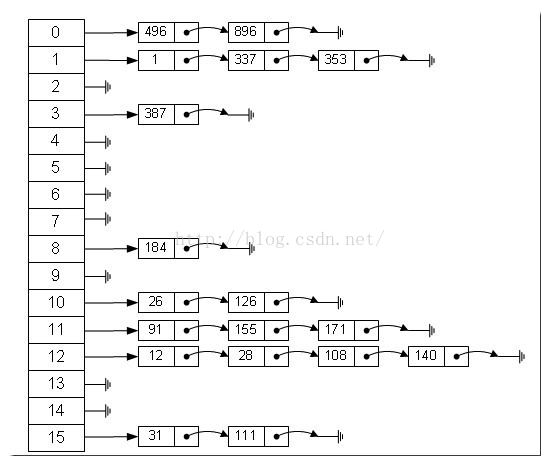
(3)散列表的查找步骤
当存储记录时,通过散列函数计算出记录的散列地址
当查找记录时,我们通过同样的是散列函数计算记录的散列地址,并按此散列地址访问该记录
(4)缺点
它是基于数组的,数组创建后难于扩展,某些哈希表被基本填满时,性能下降得非常严重,所以程序员必须要清楚表中将要存储多少数据(或者准备好定期地把数据转移到更大的哈希表中,这是个费时的过程)。
散列冲突:不同的关键字经过散列函数的计算得到了相同的散列地址。
(5)好的散列函数=计算简单+分布均匀(计算得到的散列地址分布均匀)
元素特征转变为数组下标的方法就是散列法。散列法当然不止一种,下面列出三种比较常用的:
1,除法散列法 最直观的一种,上图使用的就是这种散列法,公式: index = value % 16 学过汇编的都知道,求模数其实是通过一个除法运算得到的,所以叫“除法散列法”。
2,平方散列法 求index是非常频繁的操作,而乘法的运算要比除法来得省时(对现在的CPU来说,估计我们感觉不出来),所以我们考虑把除法换成乘法和一个位移操作。公式: index = (value * value) >> 28 (右移,除以2^28。记法:左移变大,是乘。右移变小,是除。)如果数值分配比较均匀的话这种方法能得到不错的结果,但我上面画的那个图的各个元素的值算出来的index都是0——非常失败。也许你还有个问题,value如果很大,value * value不会溢出吗?答案是会的,但我们这个乘法不关心溢出,因为我们根本不是为了获取相乘结果,而是为了获取index。
3,斐波那契(Fibonacci)散列法
平方散列法的缺点是显而易见的,所以我们能不能找出一个理想的乘数,而不是拿value本身当作乘数呢?答案是肯定的。
1,对于16位整数而言,这个乘数是40503 2,对于32位整数而言,这个乘数是2654435769 3,对于64位整数而言,这个乘数是11400714819323198485
这几个“理想乘数”是如何得出来的呢?这跟一个法则有关,叫黄金分割法则,而描述黄金分割法则的最经典表达式无疑就是著名的斐波那契数列,即如此形式的序列:0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233,377, 610,
987, 1597, 2584, 4181, 6765, 10946,…。另外,斐波那契数列的值和太阳系八大行星的轨道半径的比例出奇吻合。
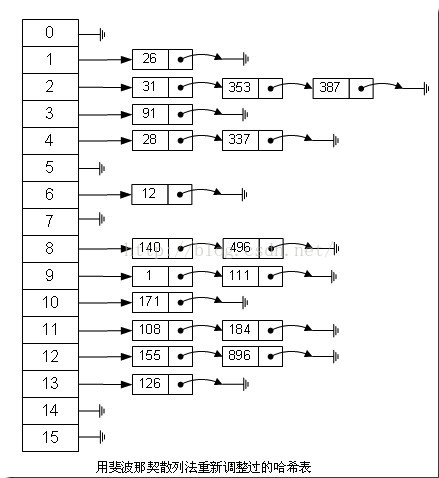
对我们常见的32位整数而言,公式: index = (value * 2654435769) >> 28
如果用这种斐波那契散列法的话,那上面的图就变成这样了:
注:用斐波那契散列法调整之后会比原来的取摸散列法好很多。
适用范围 快速查找,删除的基本数据结构,通常需要总数据量可以放入内存。
基本原理及要点 hash函数选择,针对字符串,整数,排列,具体相应的hash方法。 碰撞处理,一种是open hashing,也称为拉链法;另一种就是closed hashing,也称开地址法,opened addressing。
(6)
散列冲突的解决方案:
1.建立一个缓冲区,把凡是拼音重复的人放到缓冲区中。当我通过名字查找人时,发现找的不对,就在缓冲区里找。
2.进行再探测。就是在其他地方查找。探测的方法也可以有很多种。
(1)在找到查找位置的index的index-1,index+1位置查找,index-2,index+2查找,依次类推。这种方法称为线性再探测。
(2)在查找位置index周围随机的查找。称为随机在探测。
(3)再哈希。就是当冲突时,采用另外一种映射方式来查找。
这个程序中是通过取模来模拟查找到重复元素的过程。对待重复元素的方法就是再哈希:对当前key的位置+7。最后,可以通过全局变量来判断需要查找多少次。我这里通过依次查找26个英文字母的小写计算的出了总的查找次数。显然,当总的查找次数/查找的总元素数越接近1时,哈希表更接近于一一映射的函数,查找的效率更高。
1.5 字符串:KMP。AC自动机。Trie树。
KMP算法:参考https://blog.csdn.net/starstar1992/article/details/54913261
KMP算法求解什么类型问题
字符串匹配。给你两个字符串,寻找其中一个字符串是否包含另一个字符串,如果包含,返回包含的起始位置。
如下面两个字符串:
char *str = "bacbababadababacambabacaddababacasdsd";
char *ptr = "ababaca";12
str有两处包含ptr
分别在str的下标10,26处包含ptr。
“bacbababadababacambabacaddababacasdsd”;\
问题类型很简单,下面直接介绍算法
算法说明
一般匹配字符串时,我们从目标字符串str(假设长度为n)的第一个下标选取和ptr长度(长度为m)一样的子字符串进行比较,如果一样,就返回开始处的下标值,不一样,选取str下一个下标,同样选取长度为n的字符串进行比较,直到str的末尾(实际比较时,下标移动到n-m)。这样的时间复杂度是O(n*m)。
KMP算法:可以实现复杂度为O(m+n)
为何简化了时间复杂度:
充分利用了目标字符串ptr的性质(比如里面部分字符串的重复性,即使不存在重复字段,在比较时,实现最大的移动量)。
上面理不理解无所谓,我说的其实也没有深刻剖析里面的内部原因。
考察目标字符串ptr:
ababaca
这里我们要计算一个长度为m的转移函数next。
next数组的含义就是一个固定字符串的最长前缀和最长后缀相同的长度。
比如:abcjkdabc,那么这个数组的最长前缀和最长后缀相同必然是abc。
cbcbc,最长前缀和最长后缀相同是cbc。
abcbc,最长前缀和最长后缀相同是不存在的。
**注意最长前缀:是说以第一个字符开始,但是不包含最后一个字符。
比如aaaa相同的最长前缀和最长后缀是aaa。**
对于目标字符串ptr,ababaca,长度是7,所以next[0],next[1],next[2],next[3],next[4],next[5],next[6]分别计算的是
a,ab,aba,abab,ababa,ababac,ababaca的相同的最长前缀和最长后缀的长度。由于a,ab,aba,abab,ababa,ababac,ababaca的相同的最长前缀和最长后缀是“”,“”,“a”,“ab”,“aba”,“”,“a”,所以next数组的值是[-1,-1,0,1,2,-1,0],这里-1表示不存在,0表示存在长度为1,2表示存在长度为3。这是为了和代码相对应。
下图中的1,2,3,4是一样的。1-2之间的和3-4之间的也是一样的,我们发现A和B不一样;之前的算法是我把下面的字符串往前移动一个距离,重新从头开始比较,那必然存在很多重复的比较。现在的做法是,我把下面的字符串往前移动,使3和2对其,直接比较C和A是否一样。

代码解析
void cal_next(char *str, int *next, int len)
{
next[0] = -1;//next[0]初始化为-1,-1表示不存在相同的最大前缀和最大后缀
int k = -1;//k初始化为-1
for (int q = 1; q <= len-1; q++)
{
while (k > -1 && str[k + 1] != str[q])//如果下一个不同,那么k就变成next[k],注意next[k]是小于k的,无论k取任何值。
{
k = next[k];//往前回溯
}
if (str[k + 1] == str[q])//如果相同,k++
{
k = k + 1;
}
next[q] = k;//这个是把算的k的值(就是相同的最大前缀和最大后缀长)赋给next[q]
}
}
KMP
这个和next很像,具体就看代码,其实上面已经大概说完了整个匹配过程。
int KMP(char *str, int slen, char *ptr, int plen)
{
int *next = new int[plen];
cal_next(ptr, next, plen);//计算next数组
int k = -1;
for (int i = 0; i < slen; i++)
{
while (k >-1&& ptr[k + 1] != str[i])//ptr和str不匹配,且k>-1(表示ptr和str有部分匹配)
k = next[k];//往前回溯
if (ptr[k + 1] == str[i])
k = k + 1;
if (k == plen-1)//说明k移动到ptr的最末端
{
//cout << "在位置" << i-plen+1<< endl;
//k = -1;//重新初始化,寻找下一个
//i = i - plen + 1;//i定位到该位置,外层for循环i++可以继续找下一个(这里默认存在两个匹配字符串可以部分重叠),感谢评论中同学指出错误。
return i-plen+1;//返回相应的位置
}
}
return -1;
}
测试
char *str = "bacbababadababacambabacaddababacasdsd";
char *ptr = "ababaca";
int a = KMP(str, 36, ptr, 7);
return 0;1234
注意如果str里有多个匹配ptr的字符串,要想求出所有的满足要求的下标位置,在KMP算法需要稍微修改一下。见上面注释掉的代码。
复杂度分析
next函数计算复杂度是(m),开始以为是O(m^2),后来仔细想了想,cal__next里的while循环,以及外层for循环,利用均摊思想,其实是O(m),这个以后想好了再写上。
进一步说明
看了评论,大家对cal_next(..)函数和KMP()函数里的
while (k > -1 && str[k + 1] != str[q])
{
k = next[k];
}1234
和
while (k >-1&& ptr[k + 1] != str[i])
k = next[k];12
这个while循环和k=next[k]很疑惑!
确实啊,我开始看这几行代码,相当懵逼,这写的啥啊,为啥这样写;后来上机跑了一下,慢慢了解到为何这样写了。这几行代码,可谓是对KMP算法本质得了解非常清楚才能想到的。很牛逼!
直接看cal_next(..)函数:
首先我们看第一个while循环,它到底干了什么。
在此之前,我们先回到原程序。原程序里有一个大的for()循环,那这个for()循环是干嘛的?
这个for循环就是计算next[0],next[1],…next[q]…的值。
里面最后一句next[q]=k就是说明每次循环结束,我们已经计算了ptr的前(q+1)个字母组成的子串的“相同的最长前缀和最长后缀的长度”。(这句话前面已经解释了!) 这个“长度”就是k。
好,到此为止,假设循环进行到 第 q 次,即已经计算了next[q],我们是怎么计算next[q+1]呢?
比如我们已经知道ababab,q=4时,next[4]=2(k=2,表示该字符串的前5个字母组成的子串ababa存在相同的最长前缀和最长后缀的长度是3,所以k=2,next[4]=2。这个结果可以理解成我们自己观察算的,也可以理解成程序自己算的,这不是重点,重点是程序根据目前的结果怎么算next[5]的).,那么对于字符串ababab,我们计算next[5]的时候,此时q=5, k=2(上一步循环结束后的结果)。那么我们需要比较的是str[k+1]和str[q]是否相等,其实就是str[1]和str[5]是否相等!,为啥从k+1比较呢,因为上一次循环中,我们已经保证了str[k]和str[q](注意这个q是上次循环的q)是相等的(这句话自己想想,很容易理解),所以到本次循环,我们直接比较str[k+1]和str[q]是否相等(这个q是本次循环的q)。
如果相等,那么跳出while(),进入if(),k=k+1,接着next[q]=k。即对于ababab,我们会得出next[5]=3。 这是程序自己算的,和我们观察的是一样的。
如果不等,我们可以用”ababac“描述这种情况。 不等,进入while()里面,进行k=next[k],这句话是说,在str[k + 1] != str[q]的情况下,我们往前找一个k,使str[k + 1]==str[q],是往前一个一个找呢,还是有更快的找法呢? (一个一个找必然可以,即你把 k = next[k] 换成k- -也是完全能运行的(更正:这句话不对啊,把k=next[k]换成k–是不行的,评论25楼举了个反例)。但是程序给出了一种更快的找法,那就是 k = next[k]。 程序的意思是说,一旦str[k + 1] != str[q],即在后缀里面找不到时,我是可以直接跳过中间一段,跑到前缀里面找,next[k]就是相同的最长前缀和最长后缀的长度。所以,k=next[k]就变成,k=next[2],即k=0。此时再比较str[0+1]和str[5]是否相等,不等,则k=next[0]=-1。跳出循环。
(这个解释能懂不?)
以上就是这个cal_next()函数里的
while (k > -1 && str[k + 1] != str[q])
{
k = next[k];
}
AC自动机以及Trie树请参考:
https://blog.csdn.net/bestsort/article/details/82947639
https://blog.csdn.net/niushuai666/article/details/7002823
首先简要介绍一下AC自动机:Aho-Corasick automation,该算法在1975年产生于贝尔实验室,是著名的多模匹配算法之一。一个常见的例子就是给出n个单词,再给出一段包含m个字符的文章,让你找出有多少个单词在文章里出现过。要搞懂AC自动机,先得有字典树Trie和KMP模式匹配算法的基础知识。KMP算法是单模式串的字符匹配算法,AC自动机是多模式串的字符匹配算法。
简单的来说就是,给定一个字符串,KMP是匹配一个字符串,AC自动机是通过构建trie树来匹配多个字符串。
二. 操作系统
2.1 基础
2.1.1★★★ 进程与线程的本质区别、以及各自的使用场景。
什么是线程?线程是进程内部的一个执行流,也就是线程在进程的地址空间内运行,一个进程内的所有线程共享进程资源。创建,销毁一个线程相较创建,销毁一个进程成本要低。线程间的切换相比于进程间的切换容易的多。
什么是进程?进程是拥有一个执行流,或多个执行流的线程组。进程是一个能独立运行的基本单位,同时也是系统分配资源基本单位。进程间的相互制约,进程具有执行的间断性,进程按照各自独立不可预知的速度向前推进。
举例:比如电脑的资源管理器,ctrl+alt+点,可以打开任务管理器,里面有一个进程选项,下面会有若干个进程,每一个进程里面会有多个线程同时为这个进程工作。每一个进程都是独立的,进程不是同时进行的,只不过计算机在进行进程间的快速切换,切换的速度很快,让你以为就是各个进程是同时进行的。
进程间独立,线程间共享。
线程的应用场景:等待慢速I/O时,交给一个线程等待,接着做其他事情。通信,比较容易(注意加锁)
进程的应用场景:需要安全稳定时用进程,需要速度时用进程,既要速度又要安全。
其实吧,压力也没有那么大!
2.1.2 ★★★ 进程调度算法的特点以及使用场景。
不同环境的调度算法目标不同,因此需要针对不同环境来讨论调度算法。
批处理系统
批处理系统没有太多的用户操作,在该系统中,调度算法目标是保证吞吐量和周转时间(从提交到终止的时间)。
a. 先来先服务 first-come first-serverd(FCFS)
非抢占式的调度算法,按照请求的顺序进行调度。
有利于长作业,但不利于短作业,因为短作业必须一直等待前面的长作业执行完毕才能执行,而长作业又需要执行很长时间,造成了短作业等待时间过长。
总而言之,利长不利短
b. 短作业优先 shortest job first(SJF)
非抢占式的调度算法,按估计运行时间最短的顺序进行调度。
长作业有可能会饿死,处于一直等待短作业执行完毕的状态。因为如果一直有短作业到来,那么长作业永远得不到调度。
总而言之,利短不利长。
c. 最短剩余时间优先 shortest remaining time next(SRTN)
最短作业优先的抢占式版本,按剩余运行时间的顺序进行调度。 当一个新的作业到达时,其整个运行时间与当前进程的剩余时间作比较。如果新的进程需要的时间更少,则挂起当前进程,运行新的进程。否则新的进程等待。
交互式系统
交互式系统有大量的用户交互操作,在该系统中调度算法的目标是快速地进行响应。
a. 时间片轮转
将所有就绪进程按 FCFS 的原则排成一个队列,每次调度时,把 CPU 时间分配给队首进程,该进程可以执行一个时间片。当时间片用完时,由计时器发出时钟中断,调度程序便停止该进程的执行,并将它送往就绪队列的末尾,同时继续把 CPU 时间分配给队首的进程。
时间片轮转算法的效率和时间片的大小有很大关系:
- 因为进程切换都要保存进程的信息并且载入新进程的信息,如果时间片太小,会导致进程切换得太频繁,在进程切换上就会花过多时间。
- 而如果时间片过长,那么实时性就不能得到保证。
总而言之,就是时间轮转,让每一个都有执行时间,时间片不易过大或过小。
b. 优先级调度
为每个进程分配一个优先级,按优先级进行调度。
为了防止低优先级的进程永远等不到调度,可以随着时间的推移增加等待进程的优先级。
总而言之,按优先级来,等待久了还会增加优先级,保证实时性。
c. 多级反馈队列
一个进程需要执行 100 个时间片,如果采用时间片轮转调度算法,那么需要交换 100 次。
多级队列是为这种需要连续执行多个时间片的进程考虑,它设置了多个队列,每个队列时间片大小都不同,例如 1,2,4,8,..。进程在第一个队列没执行完,就会被移到下一个队列。这种方式下,之前的进程只需要交换 7 次。
每个队列优先权也不同,最上面的优先权最高。因此只有上一个队列没有进程在排队,才能调度当前队列上的进程。
总而言之,可以将这种调度算法看成是时间片轮转调度算法和优先级调度算法的结合。
实时系统
实时系统要求一个请求在一个确定时间内得到响应。
分为硬实时和软实时,前者必须满足绝对的截止时间,后者可以容忍一定的超时。
2.1.3 ★★☆ 常见进程同步问题。
什么是临界区?
对临界资源进行访问的那段代码称为临界区。
为了互斥访问临界资源,每个进程在进入临界区之前,需要先进行检查。
什么时同步与互斥?
同步:多个进程因为合作产生的直接制约关系,使得进程有一定的先后执行关系。
互斥:多个进程在同一时刻只有一个进程能进入临界区。
1.生产者消费者模型
使用一个缓冲区来保存物品,只有缓冲区没有满,生产者才可以放入物品;只有缓冲区不为空,消费者才可以拿走物品。
2.哲学家进餐模型
五个哲学家围着一张圆桌,每个哲学家面前放着食物。哲学家的生活有两种交替活动:吃饭以及思考。当一个哲学家吃饭时,需要先拿起自己左右两边的两根筷子,并且一次只能拿起一根筷子。
下面是一种错误的解法,如果所有哲学家同时拿起左手边的筷子,那么所有哲学家都在等待其它哲学家吃完并释放自己手中的筷子,导致死锁。
为了防止死锁的发生,可以设置两个条件:
必须同时拿起左右两根筷子;
只有在两个邻居都没有进餐的情况下才允许进餐。
2.1.4 ★★★ 进程通信方法的特点以及使用场景。
进程同步与进程通信很容易混淆,它们的区别在于:
进程同步:控制多个进程按一定顺序执行;
进程通信:进程间传输信息。
进程通信是一种手段,而进程同步是一种目的。也可以说,为了能够达到进程同步的目的,需要让进程进行通信,传输一些进程同步所需要的信息。
1.管道
只支持半双工通信(单向交替传输);
只能在父子进程或者兄弟进程中使用。
2.FIFO
也称为命名管道,去除了管道只能在父子进程中使用的限制。FIFO 常用于客户-服务器应用程序中,FIFO 用作汇聚点,在客户进程和服务器进程之间传递数据。
3.消息队列
相比于 FIFO,消息队列具有以下优点:
消息队列可以独立于读写进程存在,从而避免了 FIFO 中同步管道的打开和关闭时可能产生的困难;
避免了 FIFO 的同步阻塞问题,不需要进程自己提供同步方法;
读进程可以根据消息类型有选择地接收消息,而不像 FIFO 那样只能默认地接收。
4.信号量
它是一个计数器,用于为多个进程提供对共享数据对象的访问。
5.共享存储
6.套接字
用于不同机器间的进程通信。
2.1.5 ★★★ 死锁必要条件、解决死锁策略,能写出和分析死锁的代码,能说明在数据库管理系统或者 Java 中如何解决死锁。
什么是死锁?死锁是指两个或两个以上的线程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。
死锁产生的必要条件?(这个地方说的有点太书面了,不太好理解)互斥:每个资源要么已经分配给了一个进程,要么就是可用的。占有和等待:已经得到了某个资源的进程可以再请求新的资源。不可抢占:已经分配给一个进程的资源不能强制性地被抢占,它只能被占有它的进程显式地释放。环路等待:有两个或者两个以上的进程组成一条环路,该环路中的每个进程都在等待下一个进程所占有的资源。
解决死锁的策略?
鸵鸟策略
把头埋在沙子里,假装根本没发生问题。因为解决死锁问题的代价很高,因此鸵鸟策略这种不采取任务措施的方案会获得更高的性能。当发生死锁时不会对用户造成多大影响,或发生死锁的概率很低,可以采用鸵鸟策略。大多数操作系统,包括 Unix,Linux 和 Windows,处理死锁问题的办法仅仅是忽略它。
死锁检测与死锁恢复
不试图阻止死锁,而是当检测到死锁发生时,采取措施进行恢复。
死锁预防
在程序运行之前预防发生死锁。
死锁避免
在程序运行时避免发生死锁。
2.1.6 ★★★ 虚拟内存的作用,分页系统实现虚拟内存原理。
虚拟内存的目的是为了让物理内存扩充成更大的逻辑内存,从而让程序获得更多的可用内存。
为了更好的管理内存,操作系统将内存抽象成地址空间。每个程序拥有自己的地址空间,这个地址空间被分割成多个块,每一块称为一页。这些页被映射到物理内存,但不需要映射到连续的物理内存,也不需要所有页都必须在物理内存中。当程序引用到不在物理内存中的页时,由硬件执行必要的映射,将缺失的部分装入物理内存并重新执行失败的指令。
从上面的描述中可以看出,虚拟内存允许程序不用将地址空间中的每一页都映射到物理内存,也就是说一个程序不需要全部调入内存就可以运行,这使得有限的内存运行大程序成为可能。例如有一台计算机可以产生 16 位地址,那么一个程序的地址空间范围是 0~64K。该计算机只有 32KB 的物理内存,虚拟内存技术允许该计算机运行一个 64K 大小的程序。
2.1.7 ★★★ 页面置换算法的原理
在程序运行过程中,如果要访问的页面不在内存中,就发生缺页中断从而将该页调入内存中。此时如果内存已无空闲空间,系统必须从内存中调出一个页面到磁盘对换区中来腾出空间。
页面置换算法的主要目标是使页面置换频率最低(也可以说缺页率最低)。
具体哪一种算法先不了解了,主要有最佳,最近最久,先进先出,第二次机会算法,时钟。
2.1.8 ★★★ 比较分页与分段的区别。
- 对程序员的透明性:分页透明,但是分段需要程序员显式划分每个段。
- 地址空间的维度:分页是一维地址空间,分段是二维的。
- 大小是否可以改变:页的大小不可变,段的大小可以动态改变。
- 出现的原因:分页主要用于实现虚拟内存,从而获得更大的地址空间;分段主要是为了使程序和数据可以被划分为逻辑上独立的地址空间并且有助于共享和保护。
段页式存储:
- 程序的地址空间划分成多个拥有独立地址空间的段,每个段上的地址空间划分成大小相同的页。这样既拥有分段系统的共享和保护,又拥有分页系统的虚拟内存功能。
例子:
打个比方,比如说你去听课,带了一个纸质笔记本做笔记。笔记本有100张纸,课程有语文、数学、英语三门,对于这个笔记本的使用,为了便于以后复习方便,你可以有两种选择。
第一种是,你从本子的第一张纸开始用,并且事先在本子上做划分:第2张到第30张纸记语文笔记,第31到60张纸记数学笔记,第61到100张纸记英语笔记,最后在第一张纸做个列表,记录着三门笔记各自的范围。这就是分段管理,第一张纸叫段表。
第二种是,你从第二张纸开始做笔记,各种课的笔记是连在一起的:第2张纸是数学,第3张是语文,第4张英语……最后呢,你在第一张纸做了一个目录,记录着语文笔记在第3、7、14、15张纸……,数学笔记在第2、6、8、9、11……,英语笔记在第4、5、12……。这就是分页管理,第一张纸叫页表。
2.2 Linux
2.2.1 ★★☆ 文件系统的原理,特别是 inode 和 block。
组成
最主要的几个组成部分如下:
- inode:一个文件占用一个 inode,记录文件的属性,同时记录此文件的内容所在的 block 编号;
- block:记录文件的内容,文件太大时,会占用多个 block。
除此之外还包括:
- superblock:记录文件系统的整体信息,包括 inode 和 block 的总量、使用量、剩余量,以及文件系统的格式与相关信息等;
- block bitmap:记录 block 是否被使用的位图。
block
在 Ext2 文件系统中所支持的 block 大小有 1K,2K 及 4K 三种,不同的大小限制了单个文件和文件系统的最大大小。
| 大小 | 1KB | 2KB | 4KB |
|---|---|---|---|
| 最大单一文件 | 16GB | 256GB | 2TB |
| 最大文件系统 | 2TB | 8TB | 16TB |
一个 block 只能被一个文件所使用,未使用的部分直接浪费了。因此如果需要存储大量的小文件,那么最好选用比较小的 block。
inode
inode 具体包含以下信息:
- 权限 (read/write/excute);
- 拥有者与群组 (owner/group);
- 容量;
- 建立或状态改变的时间 (ctime);
- 最近读取时间 (atime);
- 最近修改时间 (mtime);
- 定义文件特性的旗标 (flag),如 SetUID...;
- 该文件真正内容的指向 (pointer)。
https://blog.csdn.net/qq_41901915/article/details/89458784
文件的各种属性见这个博客
inode 具有以下特点:
- 每个 inode 大小均固定为 128 bytes (新的 ext4 与 xfs 可设定到 256 bytes);
- 每个文件都仅会占用一个 inode。
inode 中记录了文件内容所在的 block 编号,但是每个 block 非常小,一个大文件随便都需要几十万的 block。而一个 inode 大小有限,无法直接引用这么多 block 编号。因此引入了间接、双间接、三间接引用。间接引用让 inode 记录的引用 block 块记录引用信息。
2.2.2 ★★★ 硬链接与软链接的区别。
什么是软链接?相当于快捷方式,只是一个链接,删除源文件这个快捷方式就不好使了。
什么是硬链接?相当于复制一份+同步更新,内容和大小完全和源文件一样,当修改源文件的内容时,硬链接的内容也会更改。
建立链接的语法:
软链接:ln -s 源文件 目标文件
硬链接:ln 源文件 目标文件
源文件:即你要对谁建立链接
2.2.3 ★★☆ 能够使用常用的命令,比如 cat 文件内容查看、find 搜索文件,以及 cut、sort 等管线命令。了解 grep 和 awk 的作用。
https://blog.csdn.net/qq_41901915/article/details/89551890
2.2.4 ★★★ 僵尸进程与孤儿进程的区别
什么是孤儿进程?一个父进程退出,而它的一个或多个子进程还在运行,那么这些子进程将成为孤儿进程。孤儿进程将被 init 进程(进程号为 1)所收养,并由 init 进程对它们完成状态收集工作。由于孤儿进程会被 init 进程收养,所以孤儿进程不会对系统造成危害。
什么是僵尸进程?子进程退出后留下的进程信息没有被收集,会导致占用的进程控制块PCB不被释放,形成僵尸进程。进程已经死去,但是进程资源没有被释放掉。
僵尸进程的解决:可以杀死父进程,这样僵尸会变成孤儿,从而被收养。
三. 网络
3.1 基础
3.1.1 ★★★ 各层协议的作用,以及 TCP/IP 协议的特点。
- 应用层 :为特定应用程序提供数据传输服务,例如 HTTP、DNS 等协议。数据单位为报文。
- 传输层 :为进程提供通用数据传输服务。由于应用层协议很多,定义通用的传输层协议就可以支持不断增多的应用层协议。运输层包括两种协议:传输控制协议 TCP,提供面向连接、可靠的数据传输服务,数据单位为报文段;用户数据报协议 UDP,提供无连接、尽最大努力的数据传输服务,数据单位为用户数据报。TCP 主要提供完整性服务,UDP 主要提供及时性服务。
- 网络层 :为主机提供数据传输服务。而传输层协议是为主机中的进程提供数据传输服务。网络层把传输层传递下来的报文段或者用户数据报封装成分组。
- 数据链路层 :网络层针对的还是主机之间的数据传输服务,而主机之间可以有很多链路,链路层协议就是为同一链路的主机提供数据传输服务。数据链路层把网络层传下来的分组封装成帧。
- 物理层 :考虑的是怎样在传输媒体上传输数据比特流,而不是指具体的传输媒体。物理层的作用是尽可能屏蔽传输媒体和通信手段的差异,使数据链路层感觉不到这些差异。
3.1.2 ★★☆ 以太网的特点,以及帧结构。
3.1.3 ★★☆ 集线器、交换机、路由器的作用,以及所属的网络层。
集线器:集线器工作在第一层(即物理层),它没有智能处理能力,对它来说,数据只是电流而已,当一个端口的电流传到集线器中时,它只是简单地将电流传送到其他端口,至于其他端口连接的计算机接收不接收这些数据,它就不管了。
交换机:交换机工作在第二层(即数据链路层),它要比集线器智能一些,对它来说,网络上的数据就是MAC地址的集合,它能分辨出帧中的源MAC地址和目的MAC地址,因此可以在任意两个端口间建立联系,但是交换机并不懂得IP地址,它只知道MAC地址。
路由器:路由器工作在第三层(即网络层),它比交换机还要“聪明”一些,它能理解数据中的IP地址,如果它接收到一个数据包,就检查其中的IP地址,如果目标地址是本地网络的就不理会,如果是其他网络的,就将数据包转发出本地网络。
3.1.4 ★★☆ IP 数据数据报常见字段的作用。
感觉这个地方没有背的必要,用的时候查一下就好了
3.1.5 ★★★ 理解三次握手以及四次挥手具体过程,三次握手的原因、四次挥手原因、TIME_WAIT 的作用。
三次握手是为了建立链接,四次挥手是为了断开链接。
确认 ACK :当 ACK=1 时确认号字段有效,否则无效。TCP 规定,在连接建立后所有传送的报文段都必须把 ACK 置 1。
同步 SYN :在连接建立时用来同步序号。当 SYN=1,ACK=0 时表示这是一个连接请求报文段。若对方同意建立连接,则响应报文中 SYN=1,ACK=1。
终止 FIN :用来释放一个连接,当 FIN=1 时,表示此报文段的发送方的数据已发送完毕,并要求释放连接。
三次握手的原因
第三次握手是为了防止失效的连接请求到达服务器,让服务器错误打开连接。
四次挥手的原因
这个状态是为了让服务器端发送还未传送完毕的数据。
TIME_WAIT
客户端接收到服务器端的 FIN 报文后进入此状态,此时并不是直接进入 CLOSED 状态,还需要等待一个时间计时器设置的时间 2MSL。这么做有两个理由:
确保最后一个确认报文能够到达。
等待一段时间是为了让所有旧的报文从网络中消失。
3.1.6 ★★☆ TCP 拥塞控制的作用,理解具体原理。
作用:防止过多的数据注入到网络当中,这样可以使网络中的路由器或链路不致过载。
慢开始:由于不知道现在网络状态是什么样的,所以一下子不可以那么大,要慢慢的变大。
拥塞避免:当达到门限的时候,就会执行拥塞避免,因为网络流量已经达到了一定的速度,再增长过快,很容易出现拥塞,所以要放慢速度。
快重传:等待重传的ACK时间可能很长,造成很多空闲时刻的浪费,所以规定客户端如果一连收到三个重复的ACK,那么不必等待重传计时器到期,尽早重传未被确认的报文段。
快恢复:由于发送方现在认为网络很可能没有发生阻塞,因此现在不执行慢启动算法,而是把cwnd值设置为慢启动门限减半后的值,然后开始执行拥塞避免算法,拥塞窗口cwnd值线性增大。
3.2 HTTP
3.2.1 ★★★ GET 与 POST 比较:作用、参数、安全性、幂等性、可缓存。
get把请求的数据放在url上,post把数据放在HTTP的包体内(requrest body)。
post比get更加安全。
get具有幂等性,post没有幂等性。
HTTP/1.1中对幂等性的定义是:一次和多次请求某一个资源对于资源本身应该具有同样的结果(网络超时等问题除外)。也就是说,其任意多次执行对资源本身所产生的影响均与一次执行的影响相同。
那么,post那么好为什么还用get?get效率高!
3.2.2 ★★☆ HTTP 状态码。
200 OK:表示从客户端发送给服务器的请求被正常处理并返回;
302 Found:临时性重定向,表示请求的资源被分配了新的URL,希望本次访问使用新的URL;
404 Not Found:表示服务器上无法找到请求的资源,除此之外,也可以在服务器拒绝请求但不想给拒绝原因时使用;
500 Inter Server Error:表示服务器在执行请求时发生了错误,也有可能是web应用存在的bug或某些临时的错误时;
3.2.3 ★★★ Cookie 作用、安全性问题、和 Session 的比较。
Cookie 是服务器发送到用户浏览器并保存在本地的一小块数据,一般用于客户端,session一般用于服务器端。
Cookie 只能存储 ASCII 码字符串,而 Session 则可以存储任何类型的数据,因此在考虑数据复杂性时首选 Session;
Cookie 存储在浏览器中,容易被恶意查看。如果非要将一些隐私数据存在 Cookie 中,可以将 Cookie 值进行加密,然后在服务器进行解密;
对于大型网站,如果用户所有的信息都存储在 Session 中,那么开销是非常大的,因此不建议将所有的用户信息都存储到 Session 中。
3.2.4 ★★☆ 缓存 的Cache-Control 字段,特别是 Expires 和 max-age 的区别。
max-age 指令出现在请求报文,并且缓存资源的缓存时间小于该指令指定的时间,那么就能接受该缓存。
max-age 指令出现在响应报文,表示缓存资源在缓存服务器中保存的时间。
Cache-Control: max-age=31536000Copy to clipboardErrorCopiedExpires 首部字段也可以用于告知缓存服务器该资源什么时候会过期。
Expires: Wed, 04 Jul 2012 08:26:05 GMTCopy to clipboardErrorCopied- 在 HTTP/1.1 中,会优先处理 max-age 指令;
3.2.5 ★★★ 长连接与短连接原理以及使用场景,流水线。
短链接:建立一次TCP链接,进行一次http通信。耗费资源但是安全。
长连接:建立一次TCP链接,进行多次http通信。不太安全但是节省资源。
权衡安全性和资源耗费性自然就有了他们各自的应用场景。
流水线:它是在同一条长连接上连续发出请求,而不用等待响应返回,这样可以减少延迟。
3.2.6 ★★★ HTTP 存在的安全性问题,以及 HTTPs 的加密、认证和完整性保护作用。
HTTP 有以下安全性问题:
使用明文进行通信,内容可能会被窃听;
不验证通信方的身份,通信方的身份有可能遭遇伪装;
无法证明报文的完整性,报文有可能遭篡改。
HTTPS 并不是新协议,而是让 HTTP 先和 SSL(Secure Sockets Layer)通信,再由 SSL 和 TCP 通信,也就是说 HTTPS 使用了隧道进行通信。
通过使用 SSL,HTTPS 具有了加密(防窃听)、认证(防伪装)和完整性保护(防篡改)。
3.3 Socket
3.3.1★★☆ 五种 IO 模型的特点以及比较。
I/O 模型
一个输入操作通常包括两个阶段:
- 等待数据准备好
- 从内核向进程复制数据
对于一个套接字上的输入操作,第一步通常涉及等待数据从网络中到达。当所等待数据到达时,它被复制到内核中的某个缓冲区。第二步就是把数据从内核缓冲区复制到应用进程缓冲区。
Unix 有五种 I/O 模型:
- 阻塞式 I/O
- 非阻塞式 I/O
- I/O 复用(select 和 poll)
- 信号驱动式 I/O(SIGIO)
- 异步 I/O(AIO)
阻塞式 I/O
应用进程被阻塞,直到数据从内核缓冲区复制到应用进程缓冲区中才返回。
应该注意到,在阻塞的过程中,其它应用进程还可以执行,因此阻塞不意味着整个操作系统都被阻塞。因为其它应用进程还可以执行,所以不消耗 CPU 时间,这种模型的 CPU 利用率会比较高。
下图中,recvfrom() 用于接收 Socket 传来的数据,并复制到应用进程的缓冲区 buf 中。这里把 recvfrom() 当成系统调用。
ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *src_addr, socklen_t *addrlen);Copy to clipboardErrorCopied
非阻塞式 I/O
应用进程执行系统调用之后,内核返回一个错误码。应用进程可以继续执行,但是需要不断的执行系统调用来获知 I/O 是否完成,这种方式称为轮询(polling)。
由于 CPU 要处理更多的系统调用,因此这种模型的 CPU 利用率比较低。
I/O 复用
使用 select 或者 poll 等待数据,并且可以等待多个套接字中的任何一个变为可读。这一过程会被阻塞,当某一个套接字可读时返回,之后再使用 recvfrom 把数据从内核复制到进程中。
它可以让单个进程具有处理多个 I/O 事件的能力。又被称为 Event Driven I/O,即事件驱动 I/O。
如果一个 Web 服务器没有 I/O 复用,那么每一个 Socket 连接都需要创建一个线程去处理。如果同时有几万个连接,那么就需要创建相同数量的线程。相比于多进程和多线程技术,I/O 复用不需要进程线程创建和切换的开销,系统开销更小。
信号驱动 I/O
应用进程使用 sigaction 系统调用,内核立即返回,应用进程可以继续执行,也就是说等待数据阶段应用进程是非阻塞的。内核在数据到达时向应用进程发送 SIGIO 信号,应用进程收到之后在信号处理程序中调用 recvfrom 将数据从内核复制到应用进程中。
相比于非阻塞式 I/O 的轮询方式,信号驱动 I/O 的 CPU 利用率更高。
异步 I/O
应用进程执行 aio_read 系统调用会立即返回,应用进程可以继续执行,不会被阻塞,内核会在所有操作完成之后向应用进程发送信号。
异步 I/O 与信号驱动 I/O 的区别在于,异步 I/O 的信号是通知应用进程 I/O 完成,而信号驱动 I/O 的信号是通知应用进程可以开始 I/O。
五大 I/O 模型比较
- 同步 I/O:将数据从内核缓冲区复制到应用进程缓冲区的阶段(第二阶段),应用进程会阻塞。
- 异步 I/O:第二阶段应用进程不会阻塞。
同步 I/O 包括阻塞式 I/O、非阻塞式 I/O、I/O 复用和信号驱动 I/O ,它们的主要区别在第一个阶段。
非阻塞式 I/O 、信号驱动 I/O 和异步 I/O 在第一阶段不会阻塞。
3.3.2 ★★★ select、poll、epoll使用场景;
select/poll/epoll 都是 I/O 多路复用的具体实现,select 出现的最早,之后是 poll,再是 epoll。
select 应用场景
select 的 timeout 参数精度为微秒,而 poll 和 epoll 为毫秒,因此 select 更加适用于实时性要求比较高的场景,比如核反应堆的控制。
select 可移植性更好,几乎被所有主流平台所支持。
poll 应用场景
poll 没有最大描述符数量的限制,如果平台支持并且对实时性要求不高,应该使用 poll 而不是 select。
epoll 应用场景
只需要运行在 Linux 平台上,有大量的描述符需要同时轮询,并且这些连接最好是长连接。
需要同时监控小于 1000 个描述符,就没有必要使用 epoll,因为这个应用场景下并不能体现 epoll 的优势。
需要监控的描述符状态变化多,而且都是非常短暂的,也没有必要使用 epoll。因为 epoll 中的所有描述符都存储在内核中,造成每次需要对描述符的状态改变都需要通过 epoll_ctl() 进行系统调用,频繁系统调用降低效率。并且 epoll 的描述符存储在内核,不容易调试。
四. 数据库
4.1 SQL
4.1.1★★☆ 手写 SQL 语句,特别是连接查询与分组查询。
https://blog.csdn.net/qq_41901915/article/details/82758909
4.2 系统原理
4.2.1 ★★★ ACID 的作用以及实现原理。
原子性(Atomicity,或称不可分割性)一致性(Consistency)隔离性(Isolation)持久性(Durability)
原子性:事务里面的操作单元不可切割,要么全部成功,要么全部失败 。
实现原理:实现原子性的关键,是当事务回滚时能够撤销所有已经成功执行的 sql 语句。基于undo log
一致性:事务执行前后,业务状态和其他业务状态保持一致.。
实现原理:事务追求的最终目标,一致性的实现既需要数据库层面的保障,也需要应用层面的保障。
隔离性:一个事务执行的时候最好不要受到其他事务的影响
实现原理:事务的四大隔离级别。
持久性:一旦事务提交或者回滚.这个状态都要持久化到数据库中
实现原理:redo log 采用的是 WAL(Write-ahead logging,预写式日志),所有修改先写入日志,再更新到 Buffer Pool,保证了数据不会因 MySQL 宕机而丢失,从而满足了持久性要求。
4.2.2 ★★★ 四大隔离级别,以及不可重复读和幻影读的出现原因。
什么是脏读?
在一个事务中读取到另一个事务没有提交的数据(针对未提交数据)
什么是不可重复读?
在一个事务中,两次查询的结果不一致(针对的update操作)
什么是虚幻读?
在一个事务中,两次查询的结果不一致(针对的insert操作)
通过设置数据库的隔离级别来避免上面的问题(四大隔离级别)
read uncommitted 读未提交 上面的三个问题都会出现
read committed 读已提交 可以避免脏读的发生
repeatable read 可重复读 可以避免脏读和不可重复读的发生
serializable 串行化 可以避免所有的问题
4.2.3 ★★☆ 封锁粒度
MySQL 中提供了两种封锁粒度:行级锁以及表级锁。
应该尽量只锁定需要修改的那部分数据,而不是所有的资源。锁定的数据量越少,发生锁争用的可能就越小,系统的并发程度就越高。
但是加锁需要消耗资源,锁的各种操作(包括获取锁、释放锁、以及检查锁状态)都会增加系统开销。因此封锁粒度越小,系统开销就越大。
在选择封锁粒度时,需要在锁开销和并发程度之间做一个权衡。
4.2.4 ★★★ 乐观锁与悲观锁。
什么是悲观锁?(适用于多写操作的系统)总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁。
什么是乐观锁?(适用于少写操作的系统)总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。
什么是CAS算法?即compare and swap(比较与交换),是一种有名的无锁算法。无锁编程,即不使用锁的情况下实现多线程之间的变量同步,也就是在没有线程被阻塞的情况下实现变量的同步,所以也叫非阻塞同步(Non-blocking Synchronization)。
4.2.5 ★★☆ 范式理论。
关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、第四范式(4NF)、第五范式(5NF)和第六范式(6NF)。满足最低要求的范式是第一范式(1NF)。在第一范式的基础上进一步满足更多要求的称为第二范式(2NF),其余范式以次类推。一般说来,数据库只需满足第三范式(3NF)就行了。
第一范式:在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。实体中的某个属性不能有多个值或者不能有重复的属性。每一行只包含一个实例的信息。
第二范式:满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或行必须可以被唯一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。
第三范式:属性不依赖于其它非主属性,紧紧依赖于主属性。
4.2.6 ★★★ SQL 与 NoSQL 的比较。
SQL (Structured Query Language) 数据库,指关系型数据库。主要代表:SQL Server,Oracle,MySQL,PostgreSQL。
NoSQL(Not Only SQL)泛指非关系型数据库。主要代表:MongoDB,Redis,CouchDB。
NoSQL的优点
1.简单的扩展:典型例子是Cassandra,由于其架构是类似于经典的P2P,所以能通过轻松地添加新的节点来扩展这个集群;
2.快速的读写:主要例子有Redis,由于其逻辑简单,而且纯内存操作,使得其性能非常出色,单节点每秒可以处理超过10万次读写操作;
3.低廉的成本:这是大多数分布式数据库共有的特点,因为主要都是开源软件,没有昂贵的License成本;
区别:
a 存储方式
SQL数据存在特定结构的表中;
而NoSQL则更加灵活和可扩展,存储方式可以是JSON文档、哈希表或者其他方式。
b 表/集合数据的关系
SQL中,必须定义好表和字段结构后才能添加数据,例如定义表的主键(primary key),索引(index),触发器(trigger),存储过程(stored procedure)等。表结构可以在被定义之后更新,但是如果有比较大的结构变更的话就会变得比较复杂。
在NoSQL中,数据可以在任何时候任何地方添加,不需要先定义表。
c 外部数据存储
SQL中如果需要增加外部关联数据的话,规范化做法是在原表中增加一个外键,关联外部数据表。
NoSQL中除了这种规范化的外部数据表做法以外,我们还能用如下的非规范化方式把外部数据直接放到原数据集中,以提高查询效率。缺点也比较明显,更新审核人数据的时候将会比较麻烦。
d SQL中的JOIN查询
SQL中可以使用JOIN表链接方式将多个关系数据表中的数据用一条简单的查询语句查询出来。
NoSQL未提供对多个数据集中的数据做查询。
e 数据耦合性
SQL中不允许删除已经被使用的外部数据,例如审核人表中的"熊三"已经被分配给了借阅人熊大,那么在审核人表中将不允许删除熊三这条数据,以保证数据完整性。
而NoSQL中则没有这种强耦合的概念,可以随时删除任何数据。
4.3 MySQL
4.3.1 ★★★ B+ Tree 原理,与其它查找树的比较。
参考:https://blog.csdn.net/qq_26222859/article/details/80631121
4.3.2 ★★★ MySQL 索引以及优化。
B+Tree 索引
是大多数 MySQL 存储引擎的默认索引类型。
因为不再需要进行全表扫描,只需要对树进行搜索即可,所以查找速度快很多。
因为 B+ Tree 的有序性,所以除了用于查找,还可以用于排序和分组。
可以指定多个列作为索引列,多个索引列共同组成键。
适用于全键值、键值范围和键前缀查找,其中键前缀查找只适用于最左前缀查找。如果不是按照索引列的顺序进行查找,则无法使用索引。
InnoDB 的 B+Tree 索引分为主索引和辅助索引。主索引的叶子节点 data 域记录着完整的数据记录,这种索引方式被称为聚簇索引。因为无法把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引。
辅助索引的叶子节点的 data 域记录着主键的值,因此在使用辅助索引进行查找时,需要先查找到主键值,然后再到主索引中进行查找。
索引优化
1. 独立的列
在进行查询时,索引列不能是表达式的一部分,也不能是函数的参数,否则无法使用索引。
例如下面的查询不能使用 actor_id 列的索引:
SELECT actor_id FROM sakila.actor WHERE actor_id + 1 = 5;Copy to clipboardErrorCopied2. 多列索引
在需要使用多个列作为条件进行查询时,使用多列索引比使用多个单列索引性能更好。例如下面的语句中,最好把 actor_id 和 film_id 设置为多列索引。
SELECT film_id, actor_ id FROM sakila.film_actor
WHERE actor_id = 1 AND film_id = 1;Copy to clipboardErrorCopied3. 索引列的顺序
让选择性最强的索引列放在前面。
索引的选择性是指:不重复的索引值和记录总数的比值。最大值为 1,此时每个记录都有唯一的索引与其对应。选择性越高,每个记录的区分度越高,查询效率也越高。
例如下面显示的结果中 customer_id 的选择性比 staff_id 更高,因此最好把 customer_id 列放在多列索引的前面。
SELECT COUNT(DISTINCT staff_id)/COUNT(*) AS staff_id_selectivity,
COUNT(DISTINCT customer_id)/COUNT(*) AS customer_id_selectivity,
COUNT(*)
FROM payment;Copy to clipboardErrorCopied staff_id_selectivity: 0.0001
customer_id_selectivity: 0.0373COUNT(*): 16049Copy to clipboardErrorCopied4. 前缀索引
对于 BLOB、TEXT 和 VARCHAR 类型的列,必须使用前缀索引,只索引开始的部分字符。
前缀长度的选取需要根据索引选择性来确定。
5. 覆盖索引
索引包含所有需要查询的字段的值。
具有以下优点:
- 索引通常远小于数据行的大小,只读取索引能大大减少数据访问量。
- 一些存储引擎(例如 MyISAM)在内存中只缓存索引,而数据依赖于操作系统来缓存。因此,只访问索引可以不使用系统调用(通常比较费时)。
- 对于 InnoDB 引擎,若辅助索引能够覆盖查询,则无需访问主索引。
4.3.3 ★★★ 查询优化。
使用 Explain 进行分析
Explain 用来分析 SELECT 查询语句,开发人员可以通过分析 Explain 结果来优化查询语句。
比较重要的字段有:
- select_type : 查询类型,有简单查询、联合查询、子查询等
- key : 使用的索引
- rows : 扫描的行数
优化数据访问
1. 减少请求的数据量
- 只返回必要的列:最好不要使用 SELECT * 语句。
- 只返回必要的行:使用 LIMIT 语句来限制返回的数据。
- 缓存重复查询的数据:使用缓存可以避免在数据库中进行查询,特别在要查询的数据经常被重复查询时,缓存带来的查询性能提升将会是非常明显的。
2. 减少服务器端扫描的行数
最有效的方式是使用索引来覆盖查询。
重构查询方式
1. 切分大查询
一个大查询如果一次性执行的话,可能一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但重要的查询。
DELETE FROM messages WHERE create < DATE_SUB(NOW(), INTERVAL 3 MONTH);Copy to clipboardErrorCopiedrows_affected = 0
do {rows_affected = do_query("DELETE FROM messages WHERE create < DATE_SUB(NOW(), INTERVAL 3 MONTH) LIMIT 10000")
} while rows_affected > 0Copy to clipboardErrorCopied2. 分解大连接查询
将一个大连接查询分解成对每一个表进行一次单表查询,然后在应用程序中进行关联,这样做的好处有:
- 让缓存更高效。对于连接查询,如果其中一个表发生变化,那么整个查询缓存就无法使用。而分解后的多个查询,即使其中一个表发生变化,对其它表的查询缓存依然可以使用。
- 分解成多个单表查询,这些单表查询的缓存结果更可能被其它查询使用到,从而减少冗余记录的查询。
- 减少锁竞争;
- 在应用层进行连接,可以更容易对数据库进行拆分,从而更容易做到高性能和可伸缩。
- 查询本身效率也可能会有所提升。例如下面的例子中,使用 IN() 代替连接查询,可以让 MySQL 按照 ID 顺序进行查询,这可能比随机的连接要更高效。
SELECT * FROM tag
JOIN tag_post ON tag_post.tag_id=tag.id
JOIN post ON tag_post.post_id=post.id
WHERE tag.tag='mysql';Copy to clipboardErrorCopiedSELECT * FROM tag WHERE tag='mysql';
SELECT * FROM tag_post WHERE tag_id=1234;
SELECT * FROM post WHERE post.id IN (123,456,567,9098,8904);4.3.4 ★★★ InnoDB 与 MyISAM 比较。
是 MySQL 默认的事务型存储引擎,只有在需要它不支持的特性时,才考虑使用其它存储引擎。
事务:InnoDB 是事务型的,可以使用 Commit 和 Rollback 语句。
并发:MyISAM 只支持表级锁,而 InnoDB 还支持行级锁。
外键:InnoDB 支持外键。
备份:InnoDB 支持在线热备份。
崩溃恢复:MyISAM 崩溃后发生损坏的概率比 InnoDB 高很多,而且恢复的速度也更慢。
其它特性:MyISAM 支持压缩表和空间数据索引。
4.3.5 ★★☆ 水平切分与垂直切分。
水平切分
水平切分又称为 Sharding,它是将同一个表中的记录拆分到多个结构相同的表中。
当一个表的数据不断增多时,Sharding 是必然的选择,它可以将数据分布到集群的不同节点上,从而缓存单个数据库的压力。
垂直切分
垂直切分是将一张表按列切分成多个表,通常是按照列的关系密集程度进行切分,也可以利用垂直切分将经常被使用的列和不经常被使用的列切分到不同的表中。
在数据库的层面使用垂直切分将按数据库中表的密集程度部署到不同的库中,例如将原来的电商数据库垂直切分成商品数据库、用户数据库等。
4.3.6 ★★☆ 主从复制原理、作用、实现。
这主要发生在集群当中,一个主服务器,多个从服务器,从服务器有着优先级,如果从服务器失效,直接通知主服务器去除掉该slave,如果主服务器失效,那么就按照优先级选择一个从服务器作为主服务器。
主要涉及三个线程:binlog 线程、I/O 线程和 SQL 线程。
- binlog 线程 :负责将主服务器上的数据更改写入二进制日志(Binary log)中。
- I/O 线程 :负责从主服务器上读取二进制日志,并写入从服务器的中继日志(Relay log)。
- SQL 线程 :负责读取中继日志,解析出主服务器已经执行的数据更改并在从服务器中重放(Replay)。
读写分离
主服务器处理写操作以及实时性要求比较高的读操作,而从服务器处理读操作。
任务分离
主从服务器任务分离,比如从服务器分担计算工作。
4.4 Redis
4.4.1 ★★☆ 跳跃表原理分析。
是有序集合的底层实现之一。
跳跃表是基于多指针有序链表实现的,可以看成多个有序链表。
在查找时,从上层指针开始查找,找到对应的区间之后再到下一层去查找。下图演示了查找 22 的过程。
与红黑树等平衡树相比,跳跃表具有以下优点:
- 插入速度非常快速,因为不需要进行旋转等操作来维护平衡性;
- 更容易实现;
- 支持无锁操作。
4.4.2 ★★★ Redis使用场景。
1、缓存
缓存现在几乎是所有中大型网站都在用的必杀技,合理的利用缓存不仅能够提升网站访问速度,还能大大降低数据库的压力。Redis提供了键过期功能,也提供了灵活的键淘汰策略,所以,现在Redis用在缓存的场合非常多。
2、排行榜
很多网站都有排行榜应用的,如京东的月度销量榜单、商品按时间的上新排行榜等。Redis提供的有序集合数据类构能实现各种复杂的排行榜应用。
3、计数器
什么是计数器,如电商网站商品的浏览量、视频网站视频的播放数等。为了保证数据实时效,每次浏览都得给+1,并发量高时如果每次都请求数据库操作无疑是种挑战和压力。Redis提供的incr命令来实现计数器功能,内存操作,性能非常好,非常适用于这些计数场景。
4、分布式会话
集群模式下,在应用不多的情况下一般使用容器自带的session复制功能就能满足,当应用增多相对复杂的系统中,一般都会搭建以Redis等内存数据库为中心的session服务,session不再由容器管理,而是由session服务及内存数据库管理。
5、分布式锁
在很多互联网公司中都使用了分布式技术,分布式技术带来的技术挑战是对同一个资源的并发访问,如全局ID、减库存、秒杀等场景,并发量不大的场景可以使用数据库的悲观锁、乐观锁来实现,但在并发量高的场合中,利用数据库锁来控制资源的并发访问是不太理想的,大大影响了数据库的性能。
加油!
加油!
加油!
加油!
加油!
加油!
加油!
加油!
加油!
加油!
加油!
加油!
加油!
加油!
加油!
加油!
4.2.3 ★★★ Redis与 Memchached 的比较。
1.性能:数据量小的时候redis好,数据量大的时候Memcached好。
2.所支持的数据类型:与Memcached仅支持简单的key-value结构的数据记录不同,Redis支持的数据类型要丰富得多。最为常用的数据类型主要由五种:String、Hash、List、Set和Sorted Set。Redis内部使用一个redisObject对象来表示所有的key和value。
3.数据备份恢复:memcached挂掉后,数据不可恢复;redis数据丢失后可以通过aof恢复。
4.数据存储:Redis和Memcached都是将数据存放在内存中,都是内存数据库。不过memcached还可用于缓存其他东西,例如图片、视频等等。memcached把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小;redis有部份存在硬盘上,这样能保证数据的持久性,支持数据的持久化(RDB、AOF),而Memcached不支持持久化。
4.2.4 ★★☆ RDB 和 AOF 持久化机制。
什么是RDB?
以一种快照的形式,将某个时间点的所有数据都存放到硬盘上。保存起来比较慢,但恢复的比较快。
什么AOF?
以一种日志的形式记录每一次的写命令,对文件的写入不是直接写入,而是先写入到日志当中,然后由操作系统决定什么时候写入到硬盘。记录的比较快,但恢复比较慢。这种方式需要设置同步选项。
| 选项 | 同步频率 |
|---|---|
| always | 每个写命令都同步 |
| everysec | 每秒同步一次 |
| no | 让操作系统来决定何时同步 |
always 选项会严重减低服务器的性能;
everysec 选项比较合适,可以保证系统崩溃时只会丢失一秒左右的数据,并且 Redis 每秒执行一次同步对服务器性能几乎没有任何影响;
no 选项并不能给服务器性能带来多大的提升,而且也会增加系统崩溃时数据丢失的数量。
4.2.5 ★★☆ 事件驱动模型。
Redis 服务器是一个事件驱动程序。
文件事件
服务器通过套接字与客户端或者其它服务器进行通信,文件事件就是对套接字操作的抽象。
Redis 基于 Reactor 模式开发了自己的网络事件处理器,使用 I/O 多路复用程序来同时监听多个套接字,并将到达的事件传送给文件事件分派器,分派器会根据套接字产生的事件类型调用相应的事件处理器。
时间事件
服务器有一些操作需要在给定的时间点执行,时间事件是对这类定时操作的抽象。
时间事件又分为:
- 定时事件:是让一段程序在指定的时间之内执行一次;
- 周期性事件:是让一段程序每隔指定时间就执行一次。
Redis 将所有时间事件都放在一个无序链表中,通过遍历整个链表查找出已到达的时间事件,并调用相应的事件处理器。
从事件处理的角度来看,服务器运行流程如下:
4.2.6 ★★★ 集群与分布式。
集群是个物理形态,分布式是个工作方式。
分布式:一个业务分拆多个子业务,部署在不同的服务器上
集群:同一个业务,部署在多个服务器上
分布式是以缩短单个任务的执行时间来提升效率的,而集群则是通过提高单位时间内执行的任务数来提升效率。
好的设计应该是分布式和集群的结合,先分布式再集群,具体实现就是业务拆分成很多子业务,然后针对每个子业务进行集群部署,这样每个子业务如果出了问题,整个系统完全不会受影响。
4.2.7 ★★☆ 事务原理。
一个事务包含了多个命令,服务器在执行事务期间,不会改去执行其它客户端的命令请求。
事务中的多个命令被一次性发送给服务器,而不是一条一条发送,这种方式被称为流水线,它可以减少客户端与服务器之间的网络通信次数从而提升性能。
Redis 最简单的事务实现方式是使用 MULTI 和 EXEC 命令将事务操作包围起来。
事务具有ACID四个特性。
五. 面向对象
5.1 思想
5.1.1 ★★★ 面向对象三大特性
封装,继承,多态。
5.1.2 ★☆☆ 设计原则
单一职责原则:专注降低类的复杂度,实现类要职责单一;
开放关闭原则:所有面向对象原则的核心,设计要对扩展开发,对修改关闭;
里式替换原则:实现开放关闭原则的重要方式之一,设计不要破坏继承关系;
依赖倒置原则:系统抽象化的具体实现,要求面向接口编程,是面向对象设计的主要实现机制之一;
接口隔离原则:要求接口的方法尽量少,接口尽量细化;
迪米特法则:降低系统的耦合度,使一个模块的修改尽量少的影响其他模块,扩展会相对容易;
5.2 设计模式
5.2.1★★★ 手写单例模式
//懒汉式线程不安全
public class singleton {//私有化一下,不让别的访问private static singleton instance;private singleton(){}//给别的一个访问的方法public static singleton getInstance(){if(instance==null){instance=new singleton();}return instance;}
}
//懒汉式线程安全,其实就是加了一个synchronized关键字
public class singleton {//私有化一下,不让别的访问private static singleton instance;private singleton(){}//给别的一个访问的方法public static synchronized singleton getInstance(){if(instance==null){instance=new singleton();}return instance;}
}
//饿汉式,推荐,线程安全
public class singleton {private static singleton instance=new singleton();private singleton(){}public static singleton getInstance(){return instance;}
}
//静态内部类,只不过把创建操作放在了静态内部类的里面,并且增加了final方法
public class singleton {private static class singletonHolder{private static final singleton instance=new singleton();}private singleton(){}public static final singleton getInstance(){return singletonHolder.instance;}
}
//双重校验锁
public class Singleton { private volatile static Singleton singleton; private Singleton (){} public static Singleton getSingleton() { if (singleton == null) { synchronized (Singleton.class) { if (singleton == null) { singleton = new Singleton(); } } } return singleton; }
}总结: 推荐使用饿汉式,对资源特别在意就使用静态内部类的方式,不推荐使用双重校验锁懒汉式。
5.2.2 ★★★ 手写工厂模式
参考:https://blog.csdn.net/jason0539/article/details/23020989?utm_source=distribute.pc_relevant.none-task
5.2.3 ★★★ 理解 MVC
即模型,视图和控制器,分别代表javabean,jsp和controller
5.2.4 ★★★ 分析 JDK 中常用的设计模式。
观察者模式
来自https://mp.weixin.qq.com/s?__biz=MzIwMTY0NDU3Nw==&mid=2651938221&idx=1&sn=9cb29d1eb0fdbdb5f976306b08d5bdcc&chksm=8d0f32e3ba78bbf547c6039038682706a2eaf83002158c58060d5eb57bdd83eb966a1e223ef6&scene=21#wechat_redirect
对象间一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
观察者模式UML图
看不懂图的人端着小板凳到这里来,给你举个栗子:假设有三个人,小美(女,22),小王和小李。小美很漂亮,小王和小李是两个程序猿,时刻关注着小美的一举一动。有一天,小美说了一句:“谁来陪我打游戏啊。”这句话被小王和小李听到了,结果乐坏了,蹭蹭蹭,没一会儿,小王就冲到小美家门口了,在这里,小美是被观察者,小王和小李是观察者,被观察者发出一条信息,然后观察者们进行相应的处理,看代码:
public interface Person {//小王和小李通过这个接口可以接收到小美发过来的消息void getMessage(String s);
}
这个接口相当于小王和小李的电话号码,小美发送通知的时候就会拨打getMessage这个电话,拨打电话就是调用接口,看不懂没关系,先往下看
public class LaoWang implements Person {private String name = "小王";public LaoWang() {}@Overridepublic void getMessage(String s) {System.out.println(name + "接到了小美打过来的电话,电话内容是:" + s);}}public class LaoLi implements Person {private String name = "小李";public LaoLi() {}@Overridepublic void getMessage(String s) {System.out.println(name + "接到了小美打过来的电话,电话内容是:->" + s);}}
代码很简单,我们再看看小美的代码:
public class XiaoMei {List<Person> list = new ArrayList<Person>();public XiaoMei(){}public void addPerson(Person person){list.add(person);}//遍历list,把自己的通知发送给所有暗恋自己的人public void notifyPerson() {for(Person person:list){person.getMessage("你们过来吧,谁先过来谁就能陪我一起玩儿游戏!");}}
}
我们写一个测试类来看一下结果对不对
public class Test {public static void main(String[] args) {XiaoMei xiao_mei = new XiaoMei();LaoWang lao_wang = new LaoWang();LaoLi lao_li = new LaoLi();//小王和小李在小美那里都注册了一下xiao_mei.addPerson(lao_wang);xiao_mei.addPerson(lao_li);//小美向小王和小李发送通知xiao_mei.notifyPerson();}
}装饰者模式
对已有的业务逻辑进一步的封装,使其增加额外的功能,如Java中的IO流就使用了装饰者模式,用户在使用的时候,可以任意组装,达到自己想要的效果。 举个栗子,我想吃三明治,首先我需要一根大大的香肠,我喜欢吃奶油,在香肠上面加一点奶油,再放一点蔬菜,最后再用两片面包夹一下,很丰盛的一顿午饭,营养又健康。(ps:不知道上海哪里有卖好吃的三明治的,求推荐~)那我们应该怎么来写代码呢? 首先,我们需要写一个Food类,让其他所有食物都来继承这个类,看代码:
public class Food {private String food_name;public Food() {}public Food(String food_name) {this.food_name = food_name;}public String make() {return food_name;};
}
代码很简单,我就不解释了,然后我们写几个子类继承它:
//面包类
public class Bread extends Food {private Food basic_food;public Bread(Food basic_food) {this.basic_food = basic_food;}public String make() {return basic_food.make()+"+面包";}
}//奶油类
public class Cream extends Food {private Food basic_food;public Cream(Food basic_food) {this.basic_food = basic_food;}public String make() {return basic_food.make()+"+奶油";}
}//蔬菜类
public class Vegetable extends Food {private Food basic_food;public Vegetable(Food basic_food) {this.basic_food = basic_food;}public String make() {return basic_food.make()+"+蔬菜";}}
这几个类都是差不多的,构造方法传入一个Food类型的参数,然后在make方法中加入一些自己的逻辑,如果你还是看不懂为什么这么写,不急,你看看我的Test类是怎么写的,一看你就明白了
public class Test {public static void main(String[] args) {Food food = new Bread(new Vegetable(new Cream(new Food("香肠"))));System.out.println(food.make());}
}
看到没有,一层一层封装,我们从里往外看:最里面我new了一个香肠,在香肠的外面我包裹了一层奶油,在奶油的外面我又加了一层蔬菜,最外面我放的是面包,是不是很形象,哈哈~ 这个设计模式简直跟现实生活中一摸一样,看懂了吗? 我们看看运行结果吧
运行结果
一个三明治就做好了~
适配器模式
将两种完全不同的事物联系到一起,就像现实生活中的变压器。假设一个手机充电器需要的电压是20V,但是正常的电压是220V,这时候就需要一个变压器,将220V的电压转换成20V的电压,这样,变压器就将20V的电压和手机联系起来了。
public class Test {public static void main(String[] args) {Phone phone = new Phone();VoltageAdapter adapter = new VoltageAdapter();phone.setAdapter(adapter);phone.charge();}
}// 手机类
class Phone {public static final int V = 220;// 正常电压220v,是一个常量private VoltageAdapter adapter;// 充电public void charge() {adapter.changeVoltage();}public void setAdapter(VoltageAdapter adapter) {this.adapter = adapter;}
}// 变压器
class VoltageAdapter {// 改变电压的功能public void changeVoltage() {System.out.println("正在充电...");System.out.println("原始电压:" + Phone.V + "V");System.out.println("经过变压器转换之后的电压:" + (Phone.V - 200) + "V");}
}
代理模式(proxy)
有两种,静态代理和动态代理。先说静态代理,很多理论性的东西我不讲,我就算讲了,你们也看不懂。什么真实角色,抽象角色,代理角色,委托角色。。。乱七八糟的,我是看不懂。之前学代理模式的时候,去网上翻一下,资料一大堆,打开链接一看,基本上都是给你分析有什么什么角色,理论一大堆,看起来很费劲,不信的话你们可以去看看,我是看不懂他们在说什么。咱不来虚的,直接用生活中的例子说话。(注意:我这里并不是否定理论知识,我只是觉得有时候理论知识晦涩难懂,喜欢挑刺的人一边去,你是来学习知识的,不是来挑刺的)
到了一定的年龄,我们就要结婚,结婚是一件很麻烦的事情,(包括那些被父母催婚的)。有钱的家庭可能会找司仪来主持婚礼,显得热闹,洋气~好了,现在婚庆公司的生意来了,我们只需要给钱,婚庆公司就会帮我们安排一整套结婚的流程。整个流程大概是这样的:家里人催婚->男女双方家庭商定结婚的黄道即日->找一家靠谱的婚庆公司->在约定的时间举行结婚仪式->结婚完毕
婚庆公司打算怎么安排婚礼的节目,在婚礼完毕以后婚庆公司会做什么,我们一概不知。。。别担心,不是黑中介,我们只要把钱给人家,人家会把事情给我们做好。所以,这里的婚庆公司相当于代理角色,现在明白什么是代理角色了吧。
代码实现请看:
//代理接口
public interface ProxyInterface {//需要代理的是结婚这件事,如果还有其他事情需要代理,比如吃饭睡觉上厕所,也可以写void marry();//代理吃饭(自己的饭,让别人吃去吧)//void eat();//代理拉屎,自己的屎,让别人拉去吧//void shit();
}
文明社会,代理吃饭,代理拉屎什么的我就不写了,有伤社会风化~~~能明白就好
好了,我们看看婚庆公司的代码:
public class WeddingCompany implements ProxyInterface {private ProxyInterface proxyInterface;public WeddingCompany(ProxyInterface proxyInterface) {this.proxyInterface = proxyInterface;}@Overridepublic void marry() {System.out.println("我们是婚庆公司的");System.out.println("我们在做结婚前的准备工作");System.out.println("节目彩排...");System.out.println("礼物购买...");System.out.println("工作人员分工...");System.out.println("可以开始结婚了");proxyInterface.marry();System.out.println("结婚完毕,我们需要做后续处理,你们可以回家了,其余的事情我们公司来做");}}
看到没有,婚庆公司需要做的事情很多,我们再看看结婚家庭的代码:
public class NormalHome implements ProxyInterface{@Overridepublic void marry() {System.out.println("我们结婚啦~");}}
这个已经很明显了,结婚家庭只需要结婚,而婚庆公司要包揽一切,前前后后的事情都是婚庆公司来做,听说现在婚庆公司很赚钱的,这就是原因,干的活多,能不赚钱吗?
来看看测试类代码:
public class Test {public static void main(String[] args) {ProxyInterface proxyInterface = new WeddingCompany(new NormalHome());proxyInterface.marry();}
}
运行结果如下:
六. 框架
6.1 spring boot
这部分参考公众号武哥聊编程中的spring boot学习资料
链接:https://pan.baidu.com/s/1M04BPRX53TKTsY8l8tjxbA
提取码:mum2
复制这段内容后打开百度网盘手机App,操作更方便哦
6.1.1 spring boot中json的使用
在项目开发中,接口与接口之间,前后端之间数据的传输都使用 Json 格式。
使用了 `@RestController` 注解即可将返回的数据结构转换成 Json 格式。
Spring Boot 中默认使用的 json 解析框架是 jackson。
JSON对空值的处理,新建一个 jackson 的配置类,将空值全转换为“”空字符串
import com.fasterxml.jackson.core.JsonGenerator;
import com.fasterxml.jackson.databind.JsonSerializer;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.SerializerProvider;
import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.http.converter.json.Jackson2ObjectMapperBuilder;import java.io.IOException;@Configuration
public class JacksonConfig {@Bean@Primary@ConditionalOnMissingBean(ObjectMapper.class)public ObjectMapper jacksonObjectMapper(Jackson2ObjectMapperBuilder builder) {ObjectMapper objectMapper = builder.createXmlMapper(false).build();objectMapper.getSerializerProvider().setNullValueSerializer(new JsonSerializer<Object>() {@Overridepublic void serialize(Object o, JsonGenerator jsonGenerator, SerializerProvider serializerProvider) throws IOException {
//在此处进行修改jsonGenerator.writeString("");}});return objectMapper;}
}阿里巴巴FastJson也很方便,感兴趣的也可以学一下。
6.1.2 Spring Boot使用slf4j进行日志记录
这里发现这个教程的方法还可以,可是没有说这些配置文件写在哪里,对初学者造成了一些误解,后来上网查了一下,用lombok插件进slf4j进行日志配置很容易,但是lombok又总是查找不到,很烦。