目录
数据集
1.查询地区编号
2.数据集的下载
编写MapReduce程序输入格式
输出格式
Mapper类
确定参数
代码
Reducer类
思路
代码
Runner类
运行结果
数据集
1.查询地区编号
NCDC是美国国家气象数据中心的缩写,是一个负责收集、存储和分发全球气象和气候数据的组织。
我们通过NCDC查询地区对应的编号,参考这里。
2.数据集的下载
打开资源管理器并输入路径:
ftp://ftp.ncdc.noaa.gov/pub/data/noaa/isd-lite/打开目录 "2022",查询编号(比如广州="592870"),找到文件 "592870-9999-20222.gz"复制到本地即可。
通过解压工具解压得到文件"592870-9999-20222",修改后缀为txt。
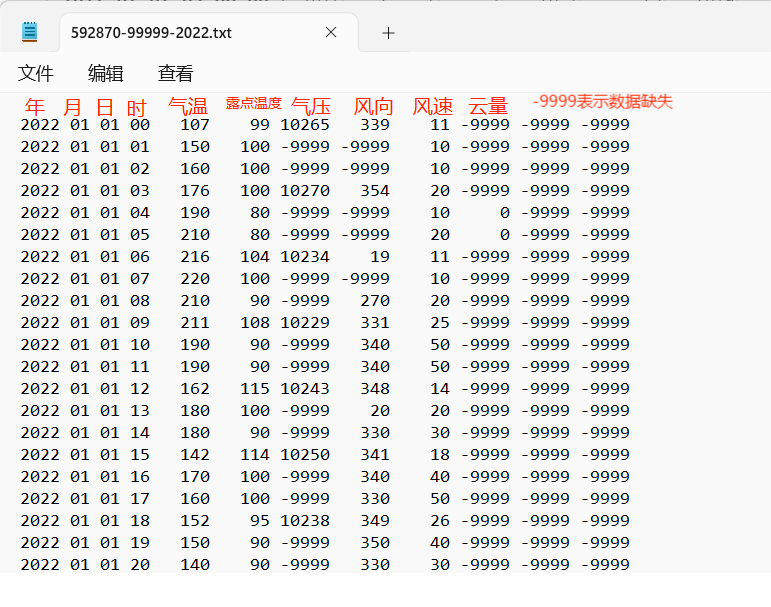
注意:这里的温度都是经过*10后的格式!
编写MapReduce程序
输入格式
2022 01 01 00 107 99 10265 339 11 -9999 -9999 -9999
2022 01 01 01 150 100 -9999 -9999 10 -9999 -9999 -9999
2022 01 01 02 160 100 -9999 -9999 10 -9999 -9999 -9999
2022 01 01 03 176 100 10270 354 20 -9999 -9999 -9999
2022 01 01 04 190 80 -9999 -9999 10 0 -9999 -9999
2022 01 01 05 210 80 -9999 -9999 20 0 -9999 -9999
2022 01 01 06 216 104 10234 19 11 -9999 -9999 -9999
2022 01 01 07 220 100 -9999 -9999 10 -9999 -9999 -9999
2022 01 01 08 210 90 -9999 270 20 -9999 -9999 -9999
2022 01 01 09 211 108 10229 331 25 -9999 -9999 -9999
2022 01 01 10 190 90 -9999 340 50 -9999 -9999 -9999
2022 01 01 11 190 90 -9999 340 50 -9999 -9999 -9999
...共8700行数据输出格式
01 260
02 360
03 310
...共12行数据
Mapper类
确定参数
- KEY_IN:使用默认的TextInputFormat,所以 KEY_IN 为每一行的字节偏移量 ,为LongWritable类型。
- VALUE_IN:使用默认的TextInputFormat,所以 VALUE_IN为对应的一行文本,为Text型。
- KEY_OUT:我们统计每个月的最高温度,所以以月份为map函数输出的键 KEY_IN,为Text型。
- VALUE_OUT:每一行数据中的温度作为map函数输出的值,为 IntWritable型。
代码
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.StringUtils;
import org.checkerframework.checker.units.qual.K;import java.io.IOException;public class MaxTempMapper extends Mapper<LongWritable, Text,Text, IntWritable> {private Text KEY_OUT = new Text();private IntWritable VALUE_OUT = new IntWritable();@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//获得数据行String line = value.toString();System.out.println(line);//转为数组String[] words = StringUtils.split(line,' ');//获取月份String month = words[1];//获取温度String temp = line.substring(16,19);temp = temp.trim();System.out.println(month+" "+temp);//设置输出的 键和值KEY_OUT.set(month);VALUE_OUT.set(Integer.parseInt(temp));//写出context.write(KEY_OUT,VALUE_OUT);}
}
Reducer类
map函数的输出键值对即为reduce函数的输入键值对,所以:4
KEY_IN:Text类型。
VALUE_IN:IntWritable型。
KEY_OUT:Text型。
VALUE_OUT:IntWritable型。
思路
因为每个reduce方法每次处理的都是同一KEY(同一个月)的键值对,我们只需要定义一个变量maxTmp来不断更新最大的温度值即可。
代码
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class MaxTempReducer extends Reducer<Text, IntWritable,Text,IntWritable> {private IntWritable OUT_VALUE = new IntWritable();@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int maxTemp = Integer.MIN_VALUE;for (IntWritable value : values) {maxTemp = Math.max(value.get(),maxTemp);}//设置输出值OUT_VALUE.set(maxTemp);//写出context.write(key,OUT_VALUE);}
}
Runner类
注意:输出目录不可存在!
import com.lyh.mapreduce.conbineTextInputFormat.WordCountMapper;
import com.lyh.mapreduce.conbineTextInputFormat.WordCountReducer;
import com.lyh.mapreduce.conbineTextInputFormat.WordCountRunner;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;public class MaxTempRunner extends Configured implements Tool {public static void main(String[] args) throws Exception {ToolRunner.run(new Configuration(),new MaxTempRunner(),args);}@Overridepublic int run(String[] args) throws Exception {//1.获取jobConfiguration conf = new Configuration();Job job = Job.getInstance(conf, "max temperature count");//2.配置jar包路径job.setJarByClass(MaxTempRunner.class);//3.关联mapper和reducerjob.setMapperClass(MaxTempMapper.class);job.setReducerClass(MaxTempReducer.class);//4.设置map、reduce输出的k、v类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);//5.设置统计文件输入的路径,将命令行的第一个参数作为输入文件的路径FileInputFormat.setInputPaths(job,new Path("D:\\MapReduce_Data_Test\\temperature\\input"));//6.设置结果数据存放路径,将命令行的第二个参数作为数据的输出路径FileOutputFormat.setOutputPath(job,new Path("D:\\MapReduce_Data_Test\\temperature\\output"));return job.waitForCompletion(true) ? 0 : 1;//verbose:是否监控并打印job的信息}
}
运行结果
01 260
02 260
03 310
04 330
05 350
06 370
07 400
08 380
09 370
10 370
11 320
12 220