文章目录
- 1、数据库 & 数据仓库
- 2、OLTP & OLAP
- 3、范式理论
- 4、维度表 & 事实表
- 4.1、维度表
- 4.2、事实表
- 5、星型模型、雪花模型、星座模型
- 6、数仓分层
- 6.1、命名规范
- 6.2、合并维度表 and 维度缩减(ODS=>DIM)
- 6.3、数据处理(ODS=>DWD)
- 6.4、维度建模(ODS+DIM=>DWD)
- 6.5、指标(DWD=>DWS=>ADS)
- 7、数据同步策略
- 8、示例表
1、数据库 & 数据仓库
| 中文名 | 英文名 | 说明 |
|---|---|---|
| 数据库 | Database | 按照数据结构来组织、存储和管理数据的仓库 |
| 数据仓库 | Data Warehouse | 为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合 |
数据仓库不是数据的终点,而是为数据的终点做准备

- 离线计算:延时的、周期性的、批处理的、海量的 数据计算
通常,离线计算周期是1天,就是每天批处理前1天的数据,俗称T+1 - 离线数仓:基于离线计算的数据仓库
目前 主流的 主要的 离线数仓工具 是 HIVE
2、OLTP & OLAP
| 在线数据处理分类 | 联机事务处理 | 联机分析处理 |
|---|---|---|
| 英文简称 | OLTP | OLAP |
| 英文全称 | Online Transaction Processing | Online Analytical Processing |
| 数据规模 | 小 | 大 |
| 延时 | 低 | 高 |
| 数据修改 | 灵活 | 不灵活,批量操作为主 |
| 数据表征 | 最新数据状态 | 随时间变化的历史状态 |
| 应用 | 事务处理 | 数据分析 |
| 场景 | 用户注册、商品交易、商品评价 | 商品销量、销售额、退单数、退单率… |
3、范式理论
- 范式
- 构造 关系数据库遵循的规则 优点
- 降低数据的 冗余性
保证数据 一致性(数据修改时,改一个表就行,不用改多个) 缺点 - 需要
join拼接数据,效率降低
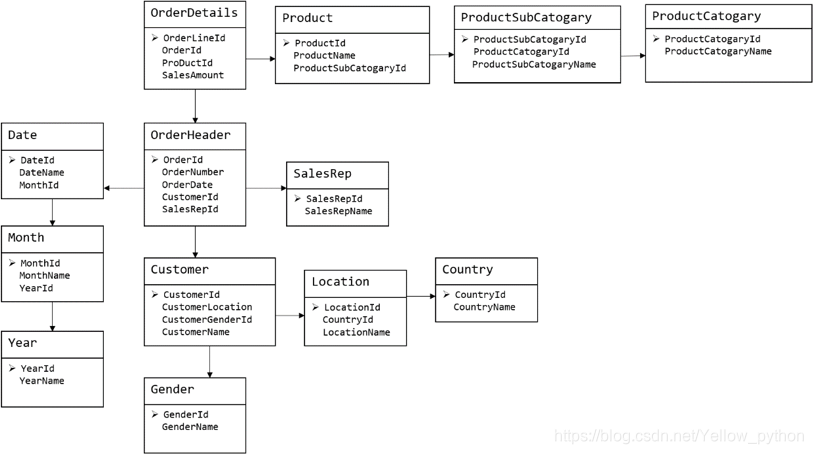
4、维度表 & 事实表
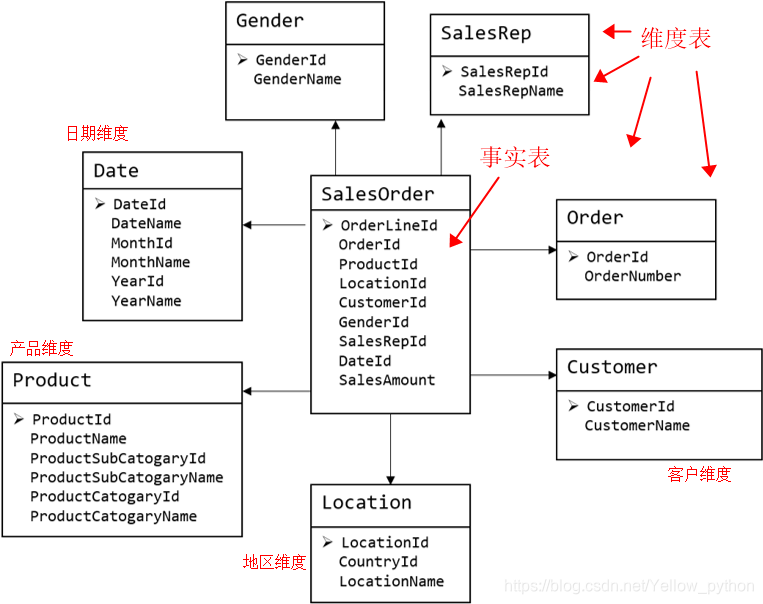
| 维度表 | 事实表 |
|---|---|
| 行数较少,列数较多 | 行数较多,列数较少 |
| 内容相对固定 | 每天很多新增 |
4.1、维度表
- 一般是对事实的描述信息,例如:用户、商品、日期、地区…
- 行数较少,列数较多
- 内容相对固定(编码表)
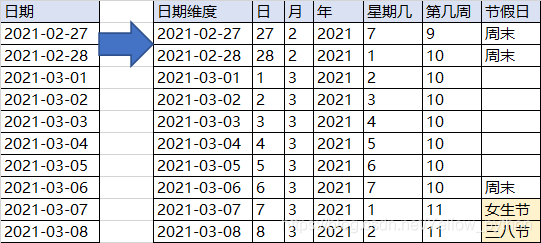
日期维度
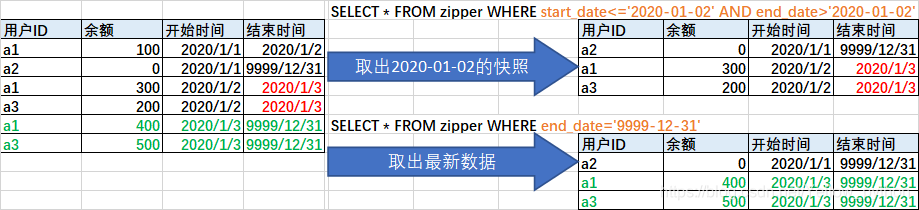
用户维度(拉链表)
从拉链表取出快照
4.2、事实表
- 每行数据代表一个业务事件,通常有很多外键(地区、用户、时间…)
- 业务事件可以是:下单、支付、退款、评价…
- 业务事件有数字度量,如:数量、金额、次数…
- 行数较多,列数较少
- 每天很多新增
| 分类 | 说明 | 特点 | 场景 |
|---|---|---|---|
| 事务型事实表 | 以每个事务为单位 | 数据只追加不修改 | 一个订单支付 一笔订单退款 |
| 周期型快照事实表 | 保留固定时间间隔的数据 | 不会保留所有数据 | 点赞数 |
| 累积型快照事实表 | 跟踪业务事实的变化 | 数据会修改 | 订单状态 |
| 数字度量 | 说明 | 示例 | 示例说明 |
|---|---|---|---|
| 可加事实 | 各个纬度可以相加 | 销售额 | 既可按日期相加,也可按地区相加 |
| 半可加事实 | 部分维度可以相加 | 库存 | 不可按日期相加,可按地区相加 |
| 不可加事实 | 各个维度不可相加 | 比例 |
5、星型模型、雪花模型、星座模型
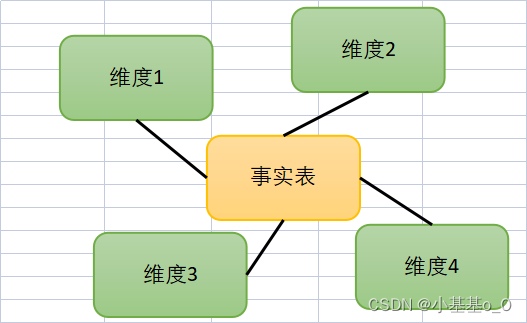
星型模型
适用于简单业务
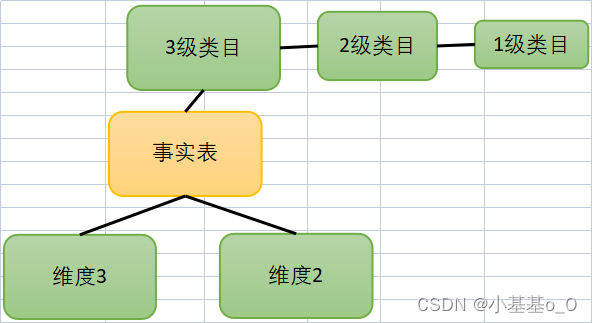
雪花模型
和星型模型相比,查询更慢,冗余更低,拓展性更好
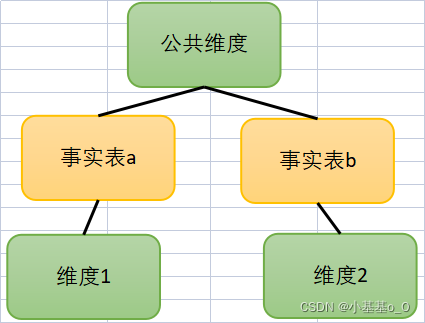
星座模型
存在共享维度
建议使用:星座模型+雪花模型
6、数仓分层
| 序 | 分层 | 全称 | 译名 | 说明 | 压缩 | 列式存储 | 分区 |
|---|---|---|---|---|---|---|---|
| 1 | ODS | Operation Data Store | 原始层 | 原始数据 | ✅ | ❌ | ✅ |
| 2 | DIM | Dimension | 维度层 | 合并维度表 | ✅ | ✅ | ✅ |
| 3 | DWD | Data Warehouse Detail | 明细层 | 数据处理、维度建模 | ✅ | ✅ | ✅ |
| 4 | DWS | Data Warehouse Service | 服务层 | 去主键聚合,得到原子指标 | ✅ | ✅ | ✅ |
| 5 | DWT | Data Warehouse Topic | 主题层 | 存放主题对象的累积行为 | ✅ | ✅ | ✅ |
| 6 | ADS | Application Data Store | 应用层 | 具体业务指标 | ❌ | ❌ | ❌ |
- 分层的好处
复杂问题拆解为多层
减少重复开发(可以去中间层取数,不用每次都去原始层)
隔离原始数据,例如:异常数据、敏感数据(用户电话…) - 数据存储策略
原始层保持数据原貌,不进行脱敏和清洗
创建分区表(例如:日期分区),防止全表扫描
数据压缩,减少磁盘占用(如:LZO、gzip、snappy)
列式存储提高查询效率(如:Parquet、ORC)
6.1、命名规范
库名:业务大类
表名:分层名_业务细类
临时表:temp_表名
备份表:bak_表名
视图:view_表名(场景:不共享的维度表、即席查询)
| 分层 | 命名规范 | 说明 | 例 |
|---|---|---|---|
ODS | ods+源类型+源表名+full/i | full:全量同步i:增量同步 | ods_postgresql_sku_fullods_mysql_order_detail_iods_frontend_log |
DIM | dim+维度+full/zip | full:全量表zip:拉链表日期维度表没有后缀 | dim_sku_fulldim_user_zipdim_date |
DWD | dwd+事实+full/i | full:全量事实i:增量事实 | |
DWS | dws+原子指标 | 时间粒度有1d、1h…1d:按1天1h:按1小时 | dws_page_visitor_1d |
DWT | dwt_消费者画像 | ||
ADS | ads+衍生指标/派生指标 |
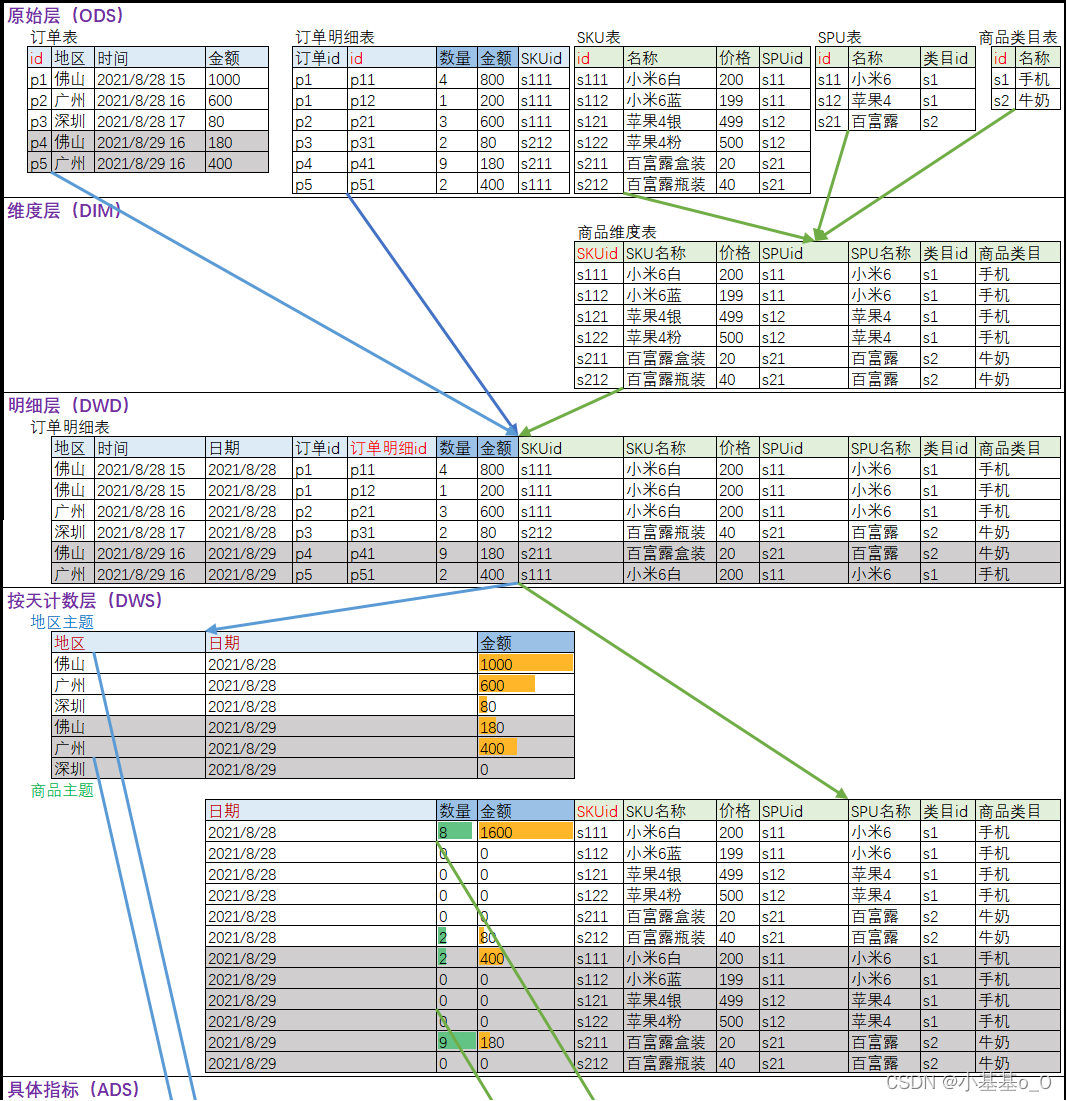
6.2、合并维度表 and 维度缩减(ODS=>DIM)
合并维度表
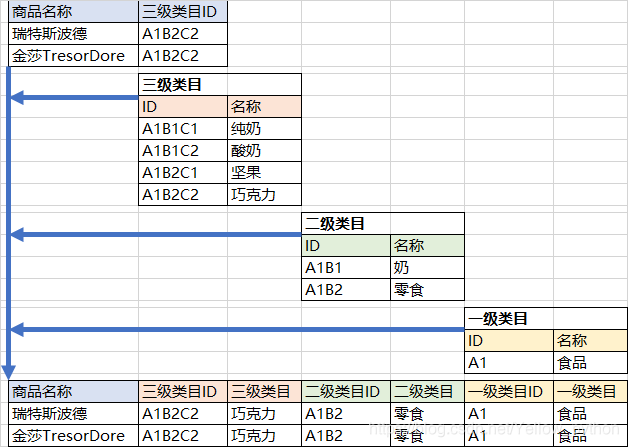
维度缩减:
情况1:字段很少的维度表 合并到事实表
情况2:非公共的维度表(该维度表只用在一个事实表)合并到事实表
6.3、数据处理(ODS=>DWD)
| 处理方式 | 说明 |
|---|---|
| JSON 解析 | {'A': {'a': 3, 'b': 4, 'c': 6}}=>{'Aa': 3, 'Ab': 4, 'Ac': 6} |
| 字段统一 | 将student_id和StudentId统一成student_id |
| 单位统一 | 2万元 => 20000元 |
| 名称统一 | 西红柿 => 番茄 番茄 => 番茄 tomato => 番茄 |
| 枚举转换 | 0 => 男 1 => 女 |
| 脱敏 | 电话:188xxxxxx79 |
| 去重 | 去除重复数据(避免笛卡尔乘积) |
| 过滤 | 清除无效数据 |
6.4、维度建模(ODS+DIM=>DWD)
- 选择业务过程,例如:用户、商品、订单、优惠券、评价…
- 声明粒度,例如:订单表的1行数据 代表了1次下单行为
- 确度维度:时间维度、地区维度、商品维度、用户维度、优惠券维度…
- 确定事实:点击、下单、支付、退款、评价…
- 度量值:次数、金额、个数…
- 构建 事实 × ( 维度 + 度量值 ) 事实 \times (维度+度量值) 事实×(维度+度量值)矩阵
| 事实\维度 | 时间 | 地区 | 用户 | 商品 | 优惠券 | … | 度量值 |
|---|---|---|---|---|---|---|---|
| 子订单 | 1 | 1 | 1 | 1 | 1 | 个数、金额 | |
| 退款 | 1 | 1 | 1 | 1 | 次数、金额 | ||
| 评价 | 1 | 1 | 1 | 1 | 次数 |
6.5、指标(DWD=>DWS=>ADS)
- 原子指标:业务定义中 不可拆解的指标
由DWD层聚合而来,存储到DWS层
| 原子指标 | 业务过程 | 度量值 | 聚合逻辑 |
|---|---|---|---|
| 订单数 | 订单 | order_id | count |
| 订单金额 | 订单 | order_amount | sum |
| 页面浏览量 | 页面浏览 | page_id | count |
| 每日 独立访客数 | 页面浏览 | user_id | count(distinct) |
| 每月 独立访客数 | 页面浏览 | user_id | count(distinct) |
- 派生指标:对 原子指标 进一步 聚合和筛选
由DWS层聚合而来,可存储到DWT层或ADS层
| 指标类型 | 原子指标 | 统计粒度(group by) | 业务限定(where) |
|---|---|---|---|
| 各省份 每天 手机类目 下单金额 | 下单金额 | 天、省份 | 手机类目 |
| 每月 各页面 流量 | 页面浏览量 | 月、页面 | 无 |
-
衍生指标:多个派生指标 复合运算而成,例如:比率
当天退单率 = 当天退单数 / 当天订单结束数 当天退单率=当天退单数/当天订单结束数 当天退单率=当天退单数/当天订单结束数
下单率 = 下单人数 / U V 下单率=下单人数/UV 下单率=下单人数/UV
存储到ADS层 -
画像:对维度表的字段进行分组
COUNT得到的统计值,并没有事实表参与
例如:用户画像、商品画像
统计值例如:对用户维度表COUNT(性别)得到男生人数和女生人数
这种统计值通常不完全可加的,例如昨天的男生人数不能和前天的男生人数相加
而每天算一次就可得到时间序列,例如男生人数按天统计的时间序列
7、数据同步策略
| 同步策略 | 周期 | 读数方式 | 写入方式 | 适用场景 | 示例 |
|---|---|---|---|---|---|
| 同步1次 | 长 | 全量 | 覆盖写入 | 源不变 | 日期表 |
| 全量同步 | 每天 | 全量 | 覆盖写入日期分区 | 源量小,有增改 | 品牌表 |
| 增量同步 | 每天 | 按日期新增 | 覆盖写入日期分区 | 源增量大 | 子订单表 |
| 增量变化同步 | 每天 | 按日期增量和变化 | 覆盖写入日期分区 | 源量大,有新改 | 父订单表、用户表 |
| 示例 | 表类型 | 源量 | 是否允许update | 是否允许delete | 同步策略 &增量标识 | 同步周期 &分区 |
|---|---|---|---|---|---|---|
| 商品信息 | 维度表 | 小 | 是 | 全量 | 按天 | |
| 用户信息 | 维度表 | 大 | 是 | 创建时间和更新时间 | 按天 | |
| 子订单流水 | 事务型事实表 | 大 | 创建时间 | 按天 | ||
| 商品收藏 | 周期型快照事实表 | 中 | 是 | 全量 | 按天 | |
| 订单状态 | 累积型快照事实表 | 大 | 是 | 创建时间和更新时间 | 按天 |
8、示例表