一、参考资料
C语言中文网
菜鸟教程 - C++教程
c-cpp.com
C++ interview
二、重要说明
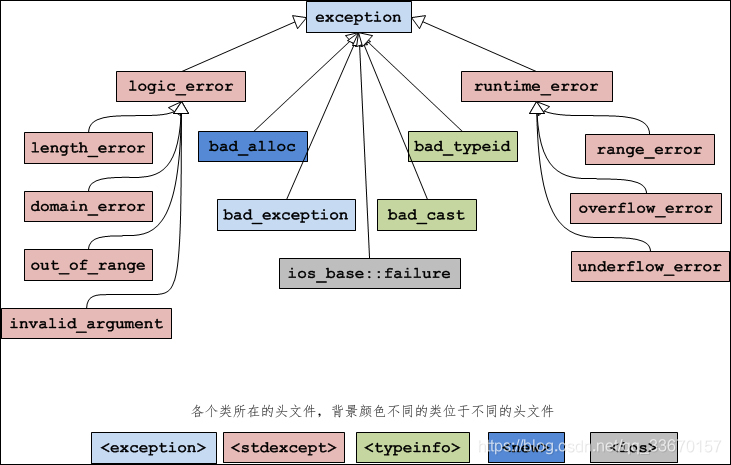
- 在C++中,尽量不使用try-catch异常处理,因为开销比较大。
三、重要知识点
1. 编译/链接
C语言源文件要经过编译、链接才能生成可执行程序:
-
**编译(Compile)**会将源文件(.c文件)转换成目标文件。对于VC/VS,目标文件后缀为
.obj;对于 GCC,目标文件后缀为.o。编译是针对单个源文件的,一次编译操作只能编译一个源文件,如果程序中有多个源文件,就需要多次编译操作。
-
**链接(Link)**是针对多个文件的,它会将多个目标文件以及系统中的库、组件等合并成一个可执行程序。
2. 预处理命令
预处理就是处理以 # 开头的命令,例如 #include <stdio.h> 等。预处理命令要放在所有函数之外,而且一般都放在源文件的前面。
编译器会将预处理的结果保存到和源文件同名的 .i 文件中,例如 main.c 的预处理结果在 main.i 中。和 .c 一样, .i 也是文本文件,可用编辑器打开查看内容。
问题由来
举个例子,假如现在开发一个C语言程序,让它暂停5s以后再输出内容,并且要求跨平台,在Windows和Linux下都能运行,怎么办呢?
不同平台下的暂停函数和头文件都不一样:
- Windows平台下的暂停函数的原型是
void Sleep(DWORD dwMilliseconds)(注意S是大写的),参数的单位是 “毫秒”,位于 <windows.h> 头文件。 - Linux平台下暂停函数的原型是
uunsigned int sleep (unsigned int seconds),参数的单位是 “秒”, 位于 <unistd.h> 头文件。
不同的平台下必须调用不同的函数,并引入不同的头文件,否则就会导致编译错误,因为 Windows 平台下没有 sleep() 函数,也没有 <unistd.h> 头文件,反之亦然。这就要求在编译之前,预处理阶段来解决这个问题。
#include <stdio.h>//不同的平台下引入不同的头文件
#ifdef _WIN64 //识别windows平台
#include <windows.h>
#elif __linux__ //识别linux平台
#include <unistd.h>
#endifint main() {//不同的平台下调用不同的函数#if _WIN64 //识别windows平台Sleep(5000);#elif __linux__ //识别linux平台sleep(5);#endifputs("http://c.biancheng.net/");return 0;
}
#if、#elif 、#endif 就是预处理命令,它们都是在编译之前由预处理程序来执行的。
对于 Windows 平台,预处理之后的代码变成:
#include <stdio.h>
#include <windows.h>int main() {Sleep(5000);puts("http://c.biancheng.net/");return 0;
}
对于 Linux 平台,预处理之后的代码变成:
#include <stdio.h>
#include <unistd.h>int main() {sleep(5);puts("http://c.biancheng.net/");return 0;
}
总结:在不同平台下,编译之前(预处理之后)的源代码都是不一样的。这就是预处理阶段的工作,它把代码当成普通文本,根据设定的条件进行一些简单的文本替换,将替换以后的结果再交给编译器处理。
3. 头文件和源文件
一般来说,头文件提供接口,源文件提供实现。
编译器规定源文件必须包含函数入口,即 main 函数。头文件专为源代码调用而写的 静态包含文件,可被源代码文件中 #include 编译预处理指令解释。如果将头文件完整拷贝到源代码的指令处,那么编译时相当于在源代码中插入 函数声明。
C++ 编译规则:头文件不会参与编译,每个cpp单独编译,每个cpp即为一个编译单元。编译期间,每个cpp不需要知道其他 cpp 存在,只有到链接阶段才会将编译期间生成的 obj 连接成一个 exe 或者 out 文件。
3.1 头文件
头文件用来写 类的声明(包括声明类的成员属性和成员方法)、函数原型、#define 常数等。
头文件的格式
#ifndef MYCLASS_H
#define MYCLASS_H
// code here
#endif
#ifndef MYCLASS_H 的意思是 if not define myclass.h如果引用这个头文件的源文件不存在 myclass.h 这个头文件,那么接下行 #define MYCALSS_H, 引入myclass.h。如果已经引入,直接跳到 #endif。
按照这种格式,目的是为了 防止头文件被重复引用。避免同一个头文件在同一个源文件中被 include 多次,这种错误称为“include嵌套”。例如,存在 cellphone.h 这个头文件引用了 #include “huawei.h”,之后又有 chain.cpp 源文件同时引用了 #include “cellphone.h” 和 #include “huawei.h”,此时 huawei.h 头文件在 chain.cpp 中被引用了两次。
理论上老说,MYCLASS_H 可以任意命名。但为了提高可读性,约定成俗地把头文件命名为 大写和下划线的形式。
#ifndef HUAWEI_H // 防止huawei.h被重复引用
#define HUAWEI_H
#include <cmath> // 引用标准库
#include "honor.h" // 引用非标准库头文件
...
void Function(); // 全局函数声明
class Mate20{ // 类声明public: Mate20(); // 构造函数声明~Mate20(); // 析构函数声明private:protected:
};
#endif
4. shared_ptr智能指针
智能指针——shared_ptr

class object
{
private:int value;
public:object(int x = 0) :value(x) {}~object() {}int& Value() { return value; }const int& Value( ) const { return value; }
};int main()
{shared_ptr<Object> apa(new object(10));shared_ptr<Object> apb = apa;return 0;
}

shared_ptr 是一种引用计数型智能指针(smart pointer),包含两个元素:指针、引用计数。所谓引用计数(reference counting),记录 有多少个 shared_ptrs 共同指向一个对象。一旦最后一个这样的指针被销毁,即 某个对象的引用计数为0,则这个对象会被自动删除,这在非环形数据结构中防止资源泄露是很有帮助的。
注意:如果多线程对同一个 shared_ptr 对象进行读和写,则必须加锁,否则容易造成“空悬指针”的后果。多线程读写 shared_ptr 所指向的对象,不管是相同的 shared_ptr 对象,还是不同的 shared_ptr 对象,都需要 加锁保护。
4.1 shared_ptr的线程安全性
- shared_ptr的引用计数本身是线程安全的,即引用计数是 原子操作;
- 多个线程同时读同一个 shared_ptr 对象是线程安全的;
4.2 (推荐使用)make_shared()
// 构造函数无参数
shared_ptr<CameraManager> pCameraManager = make_shared<CameraManager>();// 构造函数有参数
shared_ptr<BaseIoManager> pIoManager = make_shared<AppIoManager>(ioCardName);
shared_ptr<Object> apa(new object(10))需要为 Object 对象和 RefCnt 对象各分配一次内存。- 用 make_shared() 可以一次性分配一块足够大的内存,供 Object 对象和 RefCnt 对象使用。不过,Object 对象的构造函数所需参数需要传给 make_shared()。
5. printf与puts
5.1 printf
printf是 print format 的缩写,表示 “格式化打印”,即在屏幕上格式化输出(显示)。
printf 比 puts 更加强大,不仅可以输出字符串,还可以输出整型、小数、单个字符等,输出的格式也可以自定义,例如:
- 以十进制、八进制、十六进制格式输出;
- 要求输出的数字占n个字符;
- 控制小数的位数;
%d,d是 decimal 的缩写,表示十进制数,%d 表示以十进制整型的格式输出。
5.2 puts
在 puts 函数中,可以将一个较长的字符串分割成几个较短的字符串,这样使得长文本的格式更加整齐。
#include <stdio.h>
int main()
{puts("C语言中文网,一个学习C语言和C++的网站,他们坚持用工匠的精神来打磨每一套教程。""坚持做好一件事情,做到极致,让自己感动,让用户心动,这就是足以传世的作品!""C语言中文网的网址是:http://c.biancheng.net");return 0;
}
注意:这只是形式上的分割,编译器在编译阶段将会合并为一个字符串,并放在一块连续的内存中。
6. 数据类型
| 说明 | 字符型 | 字符串 | 短整型 | 整型 | 长整型 | 单精度浮点型 | 双精度浮点型 | 无类型 |
|---|---|---|---|---|---|---|---|---|
| 类型 | char | string | short | int | long | float | double | void |
| 长度 | 1 | ~ | 2 | 4 | 4 | 4 | 8 | |
| 输出 | %c | %s | ~ | %d | ~ | %f | ~ |
6.1 Buffer内存缓冲区
Buffer缓冲区是vector空指针容器类型,大小为size_t类型。
std::vector<void *> inputBuffers;
std::vector<size_t> inputSizes;
6.2 数据结构
bot即为bottom。
struct ObjDetectInfo {float leftTopX;float leftTopY;float rightBotX;float rightBotY;float confidence;float classId;
};
7. 头文件
7.1 头文件保护
#define,防止头文件被多重包含。#define头文件保护命名,全大写,例如:
#ifndef XJ_APP_SERVER_H
#define XJ_APP_SERVER_H
……
#endif // XJ_APP_SERVER_H
7.2 头文件包含次序
将头文件包含次序标准化,可增加可读性,次序如下:
C库头文件 ---》 QT/C++库头文件 ---》 其他库头的文件 ---》 项目内的头文件
8. 命名规范
C++命名规范
c++编程命名规范
C_C++变量命名规则
8.1 通用命名规定
- 避免使用缩写,避免使用无意义的名称;
- 命名由一个或多个单词组成,为了便于界定,每个单词的首字母要大写;
- 文件名、函数名、变量名命名应具有描述性;
8.2 类命名
类名是 名词,每个单词以大写字母开头,不包含下划线,且名称前加大写字母C,例如:
CXJAppServerCWebServer
8.3 函数名
-
函数名是 “动词” 或 “动词+名词”;
-
取值与设值函数与变量名匹配,例如:
int index_;int GetIndex(){returnindex_;};void SetIndex(int _index){index_ =_index;}; -
函数的名称由一个或多个单词组成,例如:“GetName()”,“SetValue()”;
-
回调函数结尾+CallBack,例如:NotifyCallBack();
-
事件函数结尾+Event,例如:ModifyEvent();
-
信号、槽函数:
signals:void askIndexSignal(); private slots:void setIndexSlot();
8.4 常量
全大写,单词间用_分开,例如:
const string MAX_FILENAME255;
8.5 宏命名
全大写,单词间用_分开,例如:
#define PI_RAUD3.14159265
8.6 变量
| 变量的命名 | 变量名由作用域前缀+类型前缀+一个或多个单词组成。为便于界定,每个单词的首字母要大写。 对于某些用途简单明了的局部变量,也可以使用简化的方式,如:i, j, k, x, y, z .... | ||||||||||||||||||||
| 作用域前缀 | 作用域前缀标明一个变量的可见范围。作用域可以有如下几种:
| ||||||||||||||||||||
| 类型前缀 | 类型前缀标明一个变量的类型,可以有如下几种:
| ||||||||||||||||||||
| 推荐的组成形式 | 变量的名字应当使用"名词"或者"形容词+名词"。例如:"nCode", "m_nState","nMaxWidth" .... |
8.7 文件名
.h 头文件对应的 .cpp 源文件有相同的文件名。
9. 信号处理
C++ 信号处理
信号是由操作系统传给进程的中断,会提早终止一个程序。在UNIX、Linux、Mac OX或 Windows系统上,通过按 Ctrl+C 产生中断。有些信号不能被程序捕获,但是下表所列信号可以在程序中捕获,并可以基于信号采取适当的动作,这些信号定义在 C++ 头文件 中。
| 信号 | 描述 |
|---|---|
| SIGABRT | 程序的异常终止,如调用 abort。 |
| SIGFPE | 错误的算术运算,比如除以零或导致溢出的操作。 |
| SIGILL | 检测非法指令。 |
| SIGINT | 程序终止(interrupt)信号。 |
| SIGSEGV | 非法访问内存。 |
| SIGTERM | 发送到程序的终止请求。 |
10. 容器
vector<pair<int, int>> ret;
ret.push_back(1,1)//会报错,因为没有构造一个临时对象
ret.push_back(pair(1,1))//不会报错,可以构成了一个pair对象
ret.emplace_back(1,1)//不会报错,可以直接在容器的尾部创建对象
10.1 push_back()
push_back():先向容器尾部添加一个右值元素(临时对象),然后调用 构造函数 构造出这个临时对象,最后调用 移动构造函数 将这个临时对象放入容器中,并释放这个临时对象。简单理解,分为两步:(1)构造临时对象,(2)移动临时对象。
最后调用的不是拷贝构造函数,而是 移动构造函数。因为需要释放临时对象,所以通过 std::move 进行移动构造,可以避免不必要的拷贝操作。
10.2 emplace_back()
emplace_back():在容器尾部添加一个元素,调用 构造函数 原地构造,不需要触发拷贝构造和移动构造,因此比 push_back() 更加高效。
10.3 push_back与emplace_back对比
push_back() 只接收一个传参,即 push_back只接受对象(实例);emplace_back() 接受一个参数列表,即 emplace_back() 除了接受对象,还能接受构造函数的参数。emplace_pack() 仅通过使用 构造参数 传入参数的时候更高效。
detectorThreads.emplace_back(&XJAppServer::startDetector, &xjServer, detectorIdx);
emplace_back():
1) 调用 有参构造函数push_back():
1) 调用 有参构造函数,创建临时对象;
2) 调用 移动构造函数,移动到 vector 中;
3) 调用 析构函数, 销毁临时对象
11.thread 线程
11.1 构造函数
| (1)默认构造函数 | thread() |
|---|---|
| (2)初始化构造函数 | template <class Fn, class… Args> |
| (3)拷贝构造函数 | thread(const thread&) = delete |
| (4)move构造函数 | thread(thread&& x) |
- 默认构造函数:创建一个空 thread 对象,该对象为非 joinable;
- 初始化构造函数:创建一个 thread 对象,该对象会调用 Fn 函数,Fn 函数的参数由 Args 指定,该对象是 joinable 的;
- 拷贝构造函数:被禁用,意味着 thread 对象不可拷贝构造;
- move构造函数:移动构造,执行成功之后x失效,即x的执行信息被移动到新产生的 thread 对象,该对象为非 joinable 的;
11.2 join()成员函数
当前线程阻塞,等待子线程结束。
11.3 detach()成员函数
当前线程和子线程分离,不必等待子线程结束,即子线程变成守护线程。
11.4 get_id()成员函数
获取线程id。
11.5 线程对象是否joinable
如果一个线程正在执行,那么它是 joinable 的。
下列任一情况,都是非 joinable 的:
- 默认构造函数其构造的;
- 通过移动构造函数获得的;
- 调用了 join 或 detach 方法后;
12. using
C++ 中using 的使用
using的作用:
- 引入命名空间;
- 指定别名;
- 在子类中引用基类的成员;
#include <iostream>using namespace std; // 引入命名空间class ClassOne
{
public:int w;
protected:int a;
};class ClassTwo
{
public:using ModuleType = ClassOne; // 指定别名
};template <typename ClassType>
class ClassThree : private ClassType
{
public:using typename ClassType::ModuleType; // 在子类中引用基类的成员ModuleType m;ClassThree() = default;virtual ~ClassThree() = default;
};void main()
{ClassThree<ClassTwo>::ModuleType a;
}
12.1 引入命名空间
using namespace std;
12.2 指定别名
指定别名,一般都是 using a = b 这样的形式
// ModuleType 是ClassOne的一个别名
using ModuleType = ClassOne;
// value_type 是_Ty的一个别名, `value_type a` 和 `_Ty a` 是同样的效果。
template<class _Ty,class _Alloc = allocator<_Ty>>class vector: public _Vector_alloc<_Vec_base_types<_Ty, _Alloc>>
{
public:using value_type = _Ty;using allocator_type = _Alloc;
}
12.3 在子类中引用基类的成员
在子类中引用基类的成员,一般都是 using CBase::a 的形式。
/*
因为类ClassThree是个模板类,它的基类是 ClassType,需要加 typename 修饰,
这个 typename 和 using 本身没什么关系。如果 ClassType不是模板类,这行代码可以写成:
using ClassType::ModuleType;
*/
using typename ClassType::ModuleType;
13. 命名空间
标准库里面的每个命名空间代表了一个的独立的概念。
14. chrono库
C++11计时器:chrono库介绍
chrono库是一个模板库,使用简单,功能强大,只需要理解三个概念:duration、time_point、clock。
#include <chrono>
using namespace std;
14.1 CLOCK 时钟
chrono库定义了三种不同的时钟:
// 依据系统的当前时间(不稳定)
std::chrono::system_clock;// 以统一的速率运行(不能被调整)
std::chrono::steady_clock;// 提供最高精度的计时周期
std::chrono::high_resolution_clock;
三种时钟的区别:
- system_clock:类似 Windows 系统右下角的时钟,是系统时间。这个时钟可以随意设置,明明是早上10点,却可以设置为下午3点。
- steady_clock:针对 system_clock 可以随意设置这个缺陷提出来的,表示时钟是不可设置的。
- high_resolution_clock:是一个高分辨率时钟。
ratio 时间比率
问题引入
时间精度,即时间分辨率。抛开 时间量纲 单论分辨率,就是一个比率。如:1000/1、10/1、1/1、1/10、1/1000。
这些比率加上距离量纲就变成了距离分辨率,加上时间量纲就变成了 时间分辨率。为此,C++11定义了 ration 模板类,用于表示比率,定义如下:
std::ratio<intmax_t N, intmax_t D> 表示时钟周期,时间单位为秒。
ratio 是一个分数类型的值,其中 N 表示分子(秒),D表示分母(周期)。
常用的时间单位
ratio<3600, 1> hours (3600秒为一个周期,表示一小时)
ratio<60, 1> minutes
ratio<1, 1> seconds
ratio<1, 1000> millisecond
ratio<1, 1000000> microseconds
ratio<1, 1000000000> nanosecons
14.2 duration 持续的时间
std::chrono::duration<int, ratio <60,1>>,表示持续的一段时间,单位是由 radio <60,1> 决定的,int 表示这段时间值的类型,函数返回的类型还是一个时间段 duration。
std::chrono::duration<int, ratio <60,1>>
std::chrono::duration<int, ratio <60,1>>
由于各种时间段 duration 表示不同,chrono库提供了 duration_cast 类型转换函数。
// 将 duration 转换成另一种类型的 duration
duration_cast();// 表示一段时间的长度
count();
#include<iostream>
#include<string.h>
#include<chrono>
using namespace std::chrono;
using namespace std;
int main()
{auto start = steady_clock::now();for(int i=0;i<100;i++)cout<<"nice"<<endl;auto end = steady_clock::now();auto tt = duration_cast<microseconds>(end - start);cout<<"程序用时="<<tt.count()<<"微秒"<<endl;return 0;
}
14.3 time_point 时间点
std::chrono::time_point() 表示一个具体时间,例如:上个世纪80年代,你的生日,今天下午,火车出发时间等。一个 time_point 必须有一个 clock 计时。
// 设置一个高精度时间点
time_point<high_resolution_clock> high_resolution_clock::now()
15. 函数模板
15.1 相关概念
在C++中,模板分为函数模板和类模板两种。熟练的C++程序员,在编写函数时都会考虑能否将其写成 函数模板,编写类时都会考虑能否将其写成 类模板,以便实现重用。
一般来说,数据的值 可以通过 函数参数传递。在函数定义时数据的值是未知的,只有 等到函数调用时接收到了实参才能确定其值,这就是 值的参数化。
在 C++ 中,数据的类型 也可以通过参数来传递,在函数定义时可以不指明具体的数据类型,当发生函数调用时,编译器可以 根据传入的实参自动判断数据类型,这就是 类型的参数化。值(Value)和类型(Type)是数据的两个主要特征,在C++中都可以被参数化。
函数模板,实际上是建立一个 通用函数,不具体指定所用到的数据类型(包括返回值类型、形参类型、局部变量类型),而是用一个 虚拟的类型 来代替(实际上用一个 标识符 来占位),等发生函数调用时,再根据传入的实参来逆推出真正的类型,这个通用函数就称为 函数模板(Function Template)。简单理解为,使用泛型参数的函数(functions with generic parameters)。
在函数模板中,数据的值和类型都被参数化了,发生函数调用时编译器会根据传入的实参来推演形参的 值 和 类型 。换个角度说,函数模板除了支持值的参数化,还支持类型的参数化。
15.2 声明函数模板的语法
template <typename 类型参数1 , typename 类型参数2 , ...>
返回值类型 函数名(形参列表){ //在函数体中可以使用类型参数
}
template<typename T> void Swap(T *a, T *b){T temp = *a;*a = *b;*b = temp;
}
说明:template 是定义函数模板的关键字,后面紧跟尖括号 <>,尖括号包围的是类型参数(虚拟的类型,即类型占位符)。typename 用来声明具体的类型参数,这里的类型参数就是 T。从整体上来看,template<typename T>被称为 模板头。模板头和函数头是一个不可分割的整体,可以换行,都中间不能有分号。
模板头中包含的参数可以用在函数定义的各个位置,包括:返回值、形参列表和函数体;本例在形参列表和函数体中都使用了类型参数 T。
函数模板被编译了两次:
- 没有实例化之前,检查函数模板代码的语法是否正确;
- 实例化期间,检查函数模板的调用是否合法;
15.3 举例说明
//交换 int 变量的值
void Swap(int *a, int *b){int temp = *a;*a = *b;*b = temp;
}//交换 float 变量的值
void Swap(float *a, float *b){float temp = *a;*a = *b;*b = temp;
}//交换 char 变量的值
void Swap(char *a, char *b){char temp = *a;*a = *b;*b = temp;
}//交换 bool 变量的值
void Swap(bool *a, bool *b){char temp = *a;*a = *b;*b = temp;
}
改成函数模板
#include <iostream>
using namespace std;template<typename T> void Swap(T *a, T *b){T temp = *a;*a = *b;*b = temp;
}int main(){//交换 int 变量的值int n1 = 100, n2 = 200;Swap(&n1, &n2);cout<<n1<<", "<<n2<<endl;//交换 float 变量的值float f1 = 12.5, f2 = 56.93;Swap(&f1, &f2);cout<<f1<<", "<<f2<<endl;//交换 char 变量的值char c1 = 'A', c2 = 'B';Swap(&c1, &c2);cout<<c1<<", "<<c2<<endl;//交换 bool 变量的值bool b1 = false, b2 = true;Swap(&b1, &b2);cout<<b1<<", "<<b2<<endl;return 0;
}
15.4 改进函数模板
引用 不但使得函数模板定义简洁明了,也使得调用函数方便很多,整体来看,引用让编码更加漂亮。
template<typename T> void Swap(T *a, T *b){T temp = *a;*a = *b;*b = temp;
}
改为
template<typename T> void Swap(T &a, T &b){T temp = a;a = b;b = temp;
}
#include <iostream>
using namespace std;template<typename T> void Swap(T &a, T &b){T temp = a;a = b;b = temp;
}int main(){//交换 int 变量的值int n1 = 100, n2 = 200;Swap(n1, n2);cout<<n1<<", "<<n2<<endl;//交换 float 变量的值float f1 = 12.5, f2 = 56.93;Swap(f1, f2);cout<<f1<<", "<<f2<<endl;//交换 char 变量的值char c1 = 'A', c2 = 'B';Swap(c1, c2);cout<<c1<<", "<<c2<<endl;//交换 bool 变量的值bool b1 = false, b2 = true;Swap(b1, b2);cout<<b1<<", "<<b2<<endl;return 0;
}
16 类模板
C++ 除了支持函数模板,还支持 类模板(Class Template),类模板是使用泛型参数的类(classes with generic parameters)。
16.1 声明类模板的语法
模板头和类头是一个不可分割的整体,可以换行,都中间不能有分号。
template<typename 类型参数1 , typename 类型参数2 , …>
class 类名{ //TODO:
};
在类外定义成员函数时,需要带上模板头,格式为:
template<typename 类型参数1 , typename 类型参数2 , …>
返回值类型 类名<类型参数1 , 类型参数2, ...>::函数名(形参列表){//TODO:
}
16.2 举例说明
类模板
template<typename T1, typename T2> //这里不能有分号
class Point{
public:Point(T1 x, T2 y): m_x(x), m_y(y){ }
public:T1 getX() const; //获取x坐标void setX(T1 x); //设置x坐标T2 getY() const; //获取y坐标void setY(T2 y); //设置y坐标
private:T1 m_x; //x坐标T2 m_y; //y坐标
};
类的成员函数
在类外定义成员函数时,template 后面的 类型参数 要和类声明时的一致。
template<typename T1, typename T2> //模板头
T1 Point<T1, T2>::getX() const /*函数头*/ {return m_x;
}template<typename T1, typename T2>
void Point<T1, T2>::setX(T1 x){m_x = x;
}template<typename T1, typename T2>
T2 Point<T1, T2>::getY() const{return m_y;
}template<typename T1, typename T2>
void Point<T1, T2>::setY(T2 y){m_y = y;
}
16.3 用类模板创建对象
与函数模板不同的是,类模板在实例化时必须显式地指明数据类型,编译器不能根据给定的数据推演出函数类型。
使用对象变量的方式来实例化
Point<int, int> p1(10, 20);
Point<int, float> p2(10, 15.5);
Point<float, char*> p3(12.4, "东经180度");
使用对象指针的方式实例化
Point<float, float> *p1 = new Point<float, float>(10.6, 109.3);
Point<char*, char*> *p = new Point<char*, char*>("东经180度", "北纬210度");
注意:赋值号两边都要指明具体的数据类型,且要保持一致。下面的写法是错误的:
//赋值号两边的数据类型不一致
Point<float, float> *p = new Point<float, int>(10.6, 109);//赋值号右边没有指明数据类型
Point<float, float> *p = new Point(10.6, 109);
17. 可变模板参数
泛化之美–C++11可变模版参数的妙用
18. 运算符重载
C++ 运算符重载的基本概念
18.1 问题引入
C++预定义的运算符,只能用于基本数据类型的运算,例如:int、char等,不能用于对象的运算。为了能在对象之间使用运算符,就需要重载运算符。例如,数学上两个复数可以直接进行 +、- 等运算,但在C++中,直接将 + 或 - 用于复数对象是不允许的,这时需要对运算符进行重载。
18.2 规则
- 重载为成员函数时,参数个数为运算符目数减一。例如,
c = a - b,等价于c = a.operator - (b); - 重载为普通函数时,参数个数为运算符目数,例如,
c = a + b,等价于c = operator + (a, b); - 当重载为普通函数时,在类中定义友元函数,使得友元函数能访问对象的私有成员,否则编译报错;
class Complex // 复数类
{
public:// 构造函数,如果不传参数,默认把实部和虚部初始化为0Complex(double r = 0.0, double i = 0.0):m_real(r),m_imag(i) { }// 重载-号运算符,属于成员函数Complex operator-(const Complex & c){// 返回一个临时对象return Complex(m_real - c.m_real, m_imag - c.m_imag);}// 打印复数void PrintComplex(){cout << m_real << "," << m_imag << endl;}// 将重载+号的普通函数,定义成友元函数// 目的是为了友元函数能访问对象的私有成员friend Complex operator+(const Complex &a, const Complex &b);private:double m_real; // 实部的值double m_imag; // 虚部的值
};// 重载+号运算符,属于普通函数,不是对象的成员函数
Complex operator+(const Complex &a, const Complex &b)
{// 返回一个临时对象return Complex(a.m_real + b.m_real, a.m_imag + b.m_imag);
}int main()
{Complex a(2,2);Complex b(1,1);Complex c;c = a + b; // 等价于c = operator+(a,b)c.PrintComplex();c = a - b; // 等价于 c = a.operator-(b)c.PrintComplex();return 0;
}
输出结果:
3,3
1,1
18.3 重载函数的参数列表和返回值
// 重载-号运算符,属于成员函数
Complex Complex::operator-(const Complex & c)
{// 返回一个临时对象return Complex(m_real - c.m_real, m_imag - c.m_imag);
}
值得思考的问题:
- 为什么运算符重载函数的参数列表的类型是
const Complex & c常引用类型,而不是Complex类型呢? - 为什么运算符重载函数的返回值类型是
Complex对象,而不是Complex &呢?
分析原因:
- 如果参数列表是
Complex普通对象类型,在入参的时候,就会调用默认的拷贝构造函数,产生一个临时对象,这会增大开销,所以采用引用的方式。同时,为了防止引用的对象被修改,所以定义成了const Complex & c常引用类型。 - 运算符重载函数执行之后,需要返回一个新的对象给左值,所以返回值类型为
Complex对象。
19. 泛型编程
所谓“泛型”,指的是算法只要 实现一遍,就能适用于多种数据类型,泛型的优势在于能够减少重复代码的编写。泛型程序设计(generic programming)是一种算法在实现时 不指定 具体要操作的 数据类型 的程序设计方法。
19.1 泛型与模板
泛型是一种编程思想,不依赖于具体的编程语言。大多数面向对象的语言都支持泛型编程,例如:C++,C#,Java等。
C++里的泛型,通过模板以及相关性质表现的。
19.2 特性(Traits)
问题引入:

模板类 SigmaTraits 叫做 traits template,它含有参数类型 T 的一个 特性(trait),即 ReturnType。
template <template T>
inline typename SigmaTraits<T>::ReturnType Sigma (const T const* start, const T const* end)
{typedef typename SigmaTraits<T>::ReturnType ReturnType;ReturnType s = ReturnType();while (start != end){s += *start++;}return s;
};
19.3 Traits实现
template <template T> class SigmaTraits {};
template <> class SigmaTraits<char> {public:typedef int ReturnType;
};
tempalte <> class SigmaTraits<short> {public: typedef int ReturnType;
};
tempalte <> class SigmaTraits<int> {public: typedef long ReturnType;
};
template <> class SigmaTraits<unsigned int> {public: typedef unsigned long ReturnType;
};
template <> class SigmaTraits<float> {public: typedef double ReturnType;
};

20. 迭代器
迭代器是泛化的指针(generalization of points)。在STL中迭代器是容器和算法之间的接口,算法通常以迭代器作为输入参数。
迭代器的基本思想:
- 分离算法和容器,使之不需要相互依赖;
- 粘合(stick)算法和容器,使一种算法能运用到多种容器中。
21. Vector容器
C++(笔记)浅析vector容器的实例
C++容器
Vector是一个封装了动态大小数组的顺序容器,简单理解为能够存放任意类型的动态数组。Vector支持动态空间大小调整,随着元素增加,Vector内部会自动扩充内存空间。
21.1 创建Vector

21.2 访问vector元素
-
vector::at();
进行边界检查,如果访问越界则抛出exception,访问效率不如 operator[]。
-
vector::operator[];
类似于数组操作,没有边界检查,访问效率高。
22. Deque容器
Deque是一个能够存放任意类型的双向队列。Deque提供的函数与Vector类似,新增了两个函数:
- push_front:在头部插入一个元素;
- pop_front:在头部弹出一个元素;
Deque采用了与Vector不同的内存管理方法:大块分配内存。
23. List容器
List是一个能够存放任意类型的 双向链表(double linked list)。
23.1 List优势
- 弹性(scalability)。可随意插入和删除元素,只需改变下一节的前项previous和后项Next的链接;
- 对于插入、删除和替换等需要重排序列的操作,效率极高;
- 对于两个list合并操作,实际上只改变list节点间的链接,没有发生元素复制;
23.2 List劣势
- 对于查找、随机存取等操作,效率低;
- 只能以连续的方式存取List中的元素,查找任意元素的平均时间和List的长度成线性比例;
- 每个元素节点上增加了一些较为严重的开销,即每个节点的前向和后向指针;
三、相关介绍
1. 构造函数
无参构造函数
在 C++ 中,每个类都有且必须有构造函数。如果用户没有自行编写构造函数,则 C++ 自动提供一个无参数的构造函数,称为默认构造函数。这个默认构造函数不做任何初始化工作。一旦用户编写了构造函数,则这个无参数的默认构造函数就消失了。