关于 400Gbps+ 场景的概括,参见:400Gbps 网络面临的挑战
首先定义规则:
- 画坐标系,横轴为到达时间,纵轴为服务(处理)时间。
- 每到达一个任务在横轴对应时间画一条垂直线。
- 每处理一个任务在纵轴对应时间画一条水平线。
- 任务到达时间是随机的(或差不多随机的)。
- 任务处理时间是固定的(几乎是均匀的)。
然后看图:
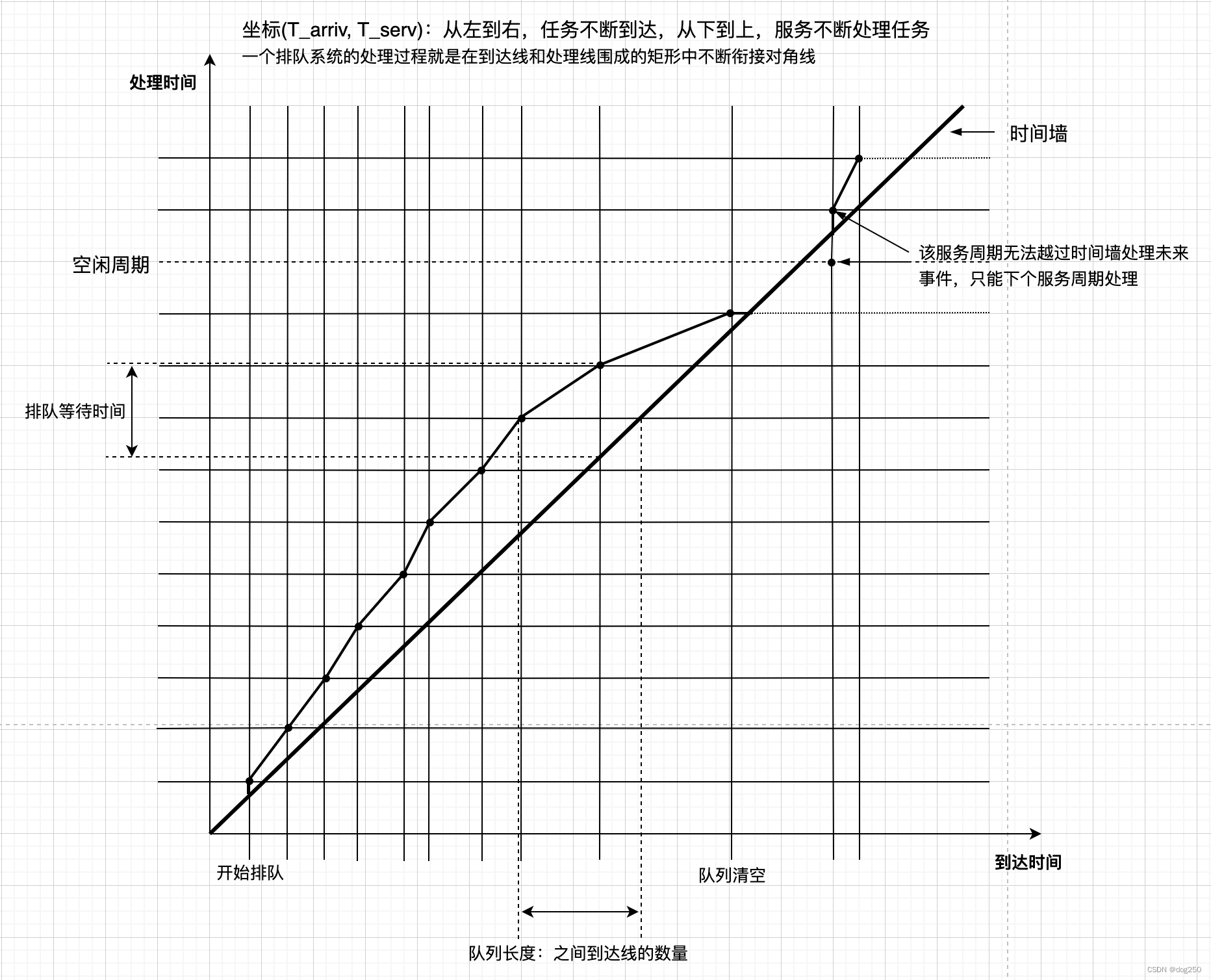
若说到达率和服务率相等,在足够久的相同一段时间,垂直线和水平线的数量是相等的,但表示到达的垂直线是实在累加的,而表示处理的水平线中有很多空闲的浪费,所谓逝去时间不可追回。
删掉空闲水平线后,垂直线数量将大于水平线数量,二者的差值就是平均队列长度。因此有:
- 到达率大于服务率,相同时间内垂直线多于水平线,算上删除的空闲水平线,队列长度趋向无穷。
- 到达率等于服务率,相同时间内垂直线等于水平线,算上删除的空闲水平线,队列长度趋向无穷。
- 到达率微小于服务率,相同时间内垂直线少于水平线,算上删除的空闲水平线,队列长度趋向无穷或有限但很大。
- 到达率远小于服务率,相同时间内垂直线少于水平线,算上删除的空闲水平线,队列长度趋向 0 的速度视二者比值决定。
这大致直观诠释了排队论的那些个公式。有下图做统一展示:
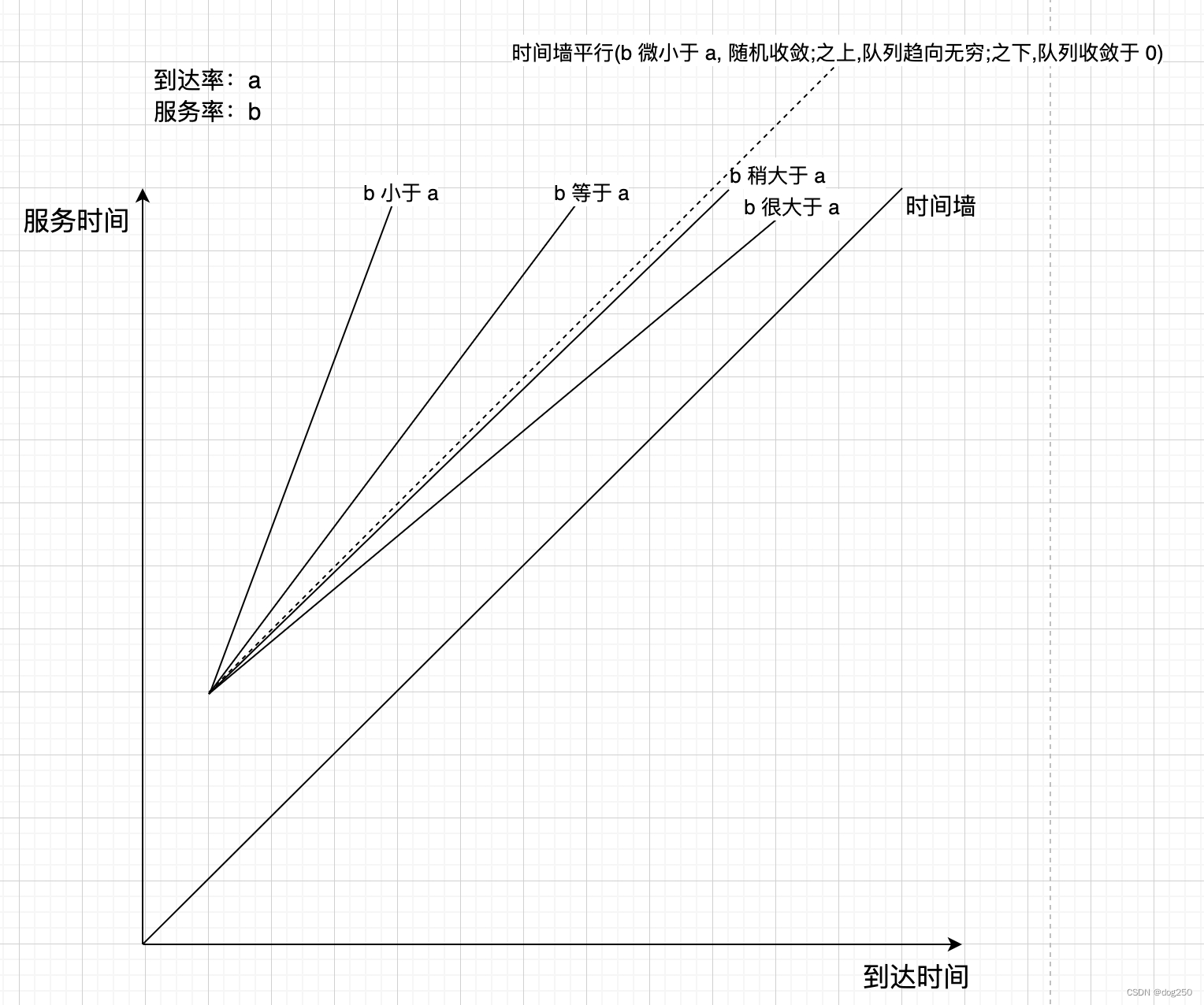
看这个链接:Towards 800G and 1600G Ethernet,网卡的发展似乎比 DDRx 快,几乎有追赶 CPU 内存带宽的趋势,当网卡速率与 CPU 读写内存的速率趋同甚至超越时,按照上图展示的排队率原理,a >= b,没得玩了。
回到 CPU 处理 TCP 的问题。
TCP 必须保序,故在单 CPU 串行处理比 “多 CPU 并行 + 同步” 的总效能更高。但 CPU 处理 TCP 逻辑时间约定值,以 Linux Kernel TCP 为例,即 tcp_v4_rcv 函数的指令时间(包括内存拷贝时间)约定值,该时间很难压缩到 500ns 以内。
假设 TCP 报文的到达与 CPU 的处理已完全校准,统一达到 100Gbps 的速率。
TCP 报文的到达虽非完全随机分布,但一定不是均匀的,只要两次到达时间稍微错过 1 个处理周期,依照上图解释,排队即将无穷增加,为清空队列,TCP 只能降速。
为实现初始假设,CPU 处理 100Gbps 到达率,需在 100ns 内完成 tcp_v4_rcv 调用(除 CPU 执行冗长的指令,还要加入内存操作,batch 只降低 overhead,但内存时间也相应越久,ZeroCopy 也不例外,稍好,但不完全),CPU 很难完成该任务,初始假设都难,匡论后续随机过程。
难道不能提升 CPU 和内存的能力?当然可以,但 CPU 主频已经接近极限,内存带宽已经上百 GB,还能提升多少呢?正如大家说,不如上专门硬件,FPGA,SmartNIC,… 可为什么非要猛件迎合 TCP 呢?难道不是 TCP 自己的问题吗?
假设 TCP 可以乱序接收,就可以并行多路径传输并行处理 TCP 报文了,1 个 CPU 处理 25Gbps 绰绰有余,20 个 CPU 不就可以处理 500Gbps 了吗?问题不在硬件,问题在 TCP。
再给个形象的类比,工地上工人往楼上接力扔砖。
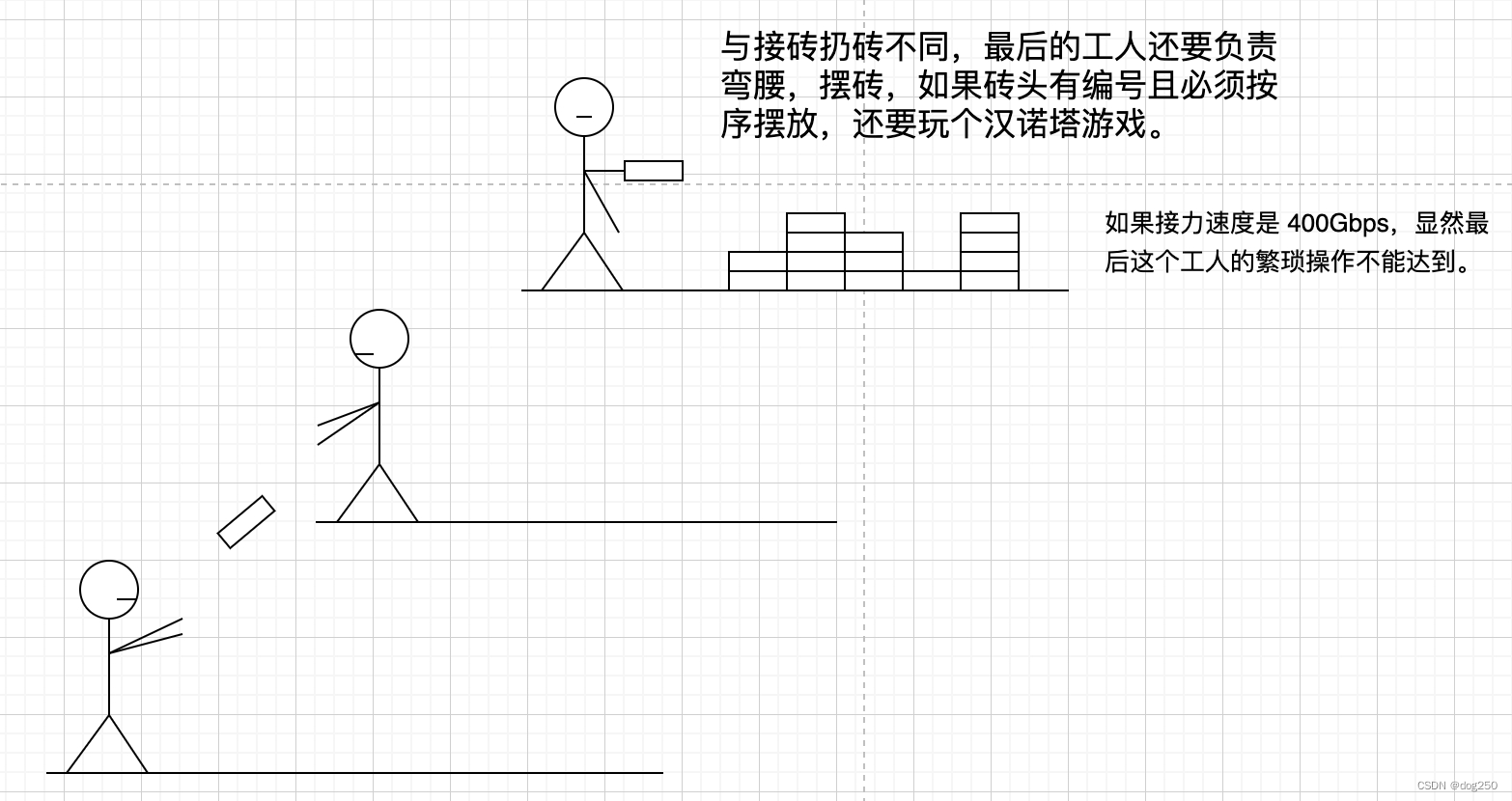
Linux Kernel TCP 就是如此这般扔砖接力,换个实现方式就好很多:
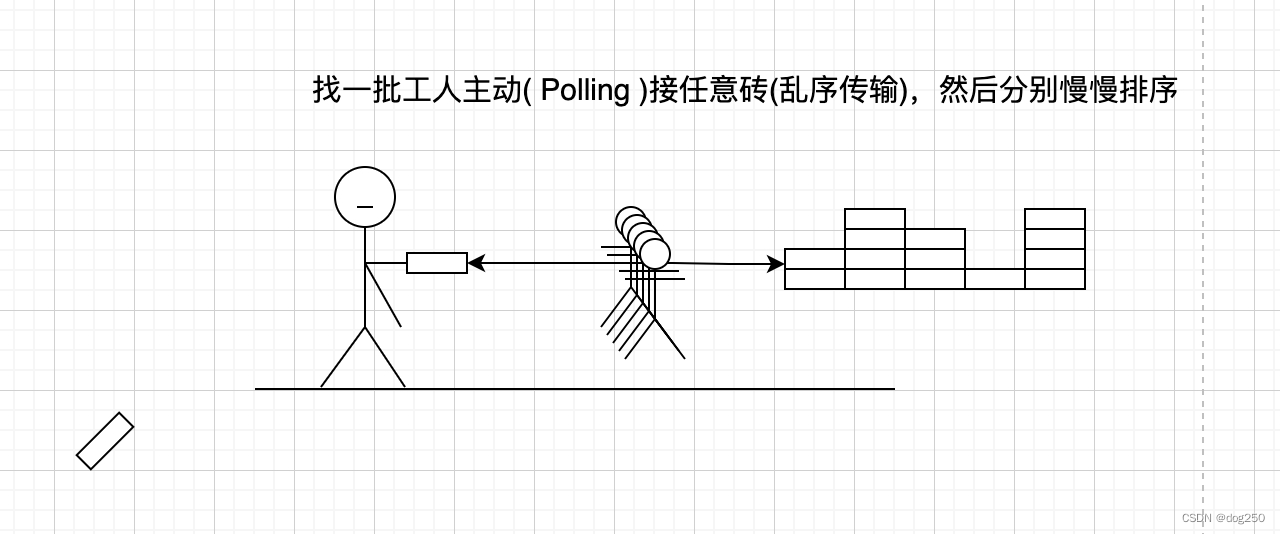
那么,以上就是乱序传输的好处,可以并行处理。然而 TCP 并不具备这能力。
这还不算拥塞控制的副作用,比如丢包,乱序带来的损耗,全在 TCP 保序约束。
放弃 TCP,人们一时半会儿不能接受,且不说新协议部署升级问题,人们从心理上也不能接受,但凡说了这话,大部分人都觉得此人在瞎咧咧,那就不再说,但 TCP 也不是什么都不能做:
- 调大 MTU,降低 packet overhead。
- 开启 TSO/LRO,卸载校验和计算,降低 packet overhead。
- 合入 tcp: defer skb freeing after socket lock is released,减少串行工作量。
- 合入 tcp: BIG TCP implementation,提高 batch 能力,降低 packet overhead。
- 开启 Busy Polling,主动接砖(如上图)替换 put user。
单流 TCP 挑战 100Gbps+ 是难成功的,但 100Gbps+ 的网络根本就不是让单流跑满的,那么似乎多线程多流 TCP 跑满 100Gbps+ 也算。但是还有更有趣的,那就是不用 TCP,It’s Time to Replace TCP in the Datacenter 这篇不错,读后感也写过:It’s Time to Replace TCP in the Datacenter 读后 本文接着写点感想。
浙江温州皮鞋湿,下雨进水不会胖。