微信开发中消息回复的代码
Ste·ga·no·graph·y / stegəˈnägrəfi / (noun): the practice of concealing messages or information within other nonsecret text or data.
文字/名词:在其他非秘密文本或数据中隐藏消息或信息的做法。
Synopsis: it’s possible to effectively conceal sensitive information inside language without raising eavesdropper suspicion using deep learning. This has important implications for secure communication.
简介:可以通过深度学习有效地隐藏语言内部的敏感信息,而不会引起窃听者的怀疑。 这对安全通信具有重要意义。
Edit 09/06/20: Check out the end of the article for a machine-generated summary! More to come in that direction soon. :)
编辑09/06/20: 查阅本文结尾处的机器生成摘要! 不久将有更多的朝着这个方向发展。 :)
Steganography has been used for ages to communicate information in a hidden manner. A natural question: how is this different from cryptography? Isn’t cryptography a very well-studied field in which two individuals aim to share information with each other without an eavesdropper being able to discover this information? Indeed, these two areas are very similar, but there’s an interesting property of steganography that takes information sharing to a whole different level: the information is shared without an eavesdropper even knowing that anything secret is being shared. What’s the use of, say, Shor’s algorithm (for breaking RSA encryption in polynomial time using a quantum computer) if you don’t even know what to decrypt?
隐写术已经使用了很长时间,以隐藏的方式传达信息。 一个自然的问题:这与密码学有何不同? 密码学不是一个经过精心研究的领域,在这个领域中,两个人旨在彼此共享信息,而窃听者却无法发现这些信息吗? 的确,这两个领域非常相似,但是隐秘术的一个有趣特性将信息共享带到了一个完全不同的水平:即使不知道任何秘密都在共享,信息也无需窃听者即可共享。 如果您甚至不知道要解密什么,Shor的算法(用于使用量子计算机在多项式时间内打破RSA加密)的用途是什么?
Steganography has long been associated with painting and visual art. Painters often hide signatures, self-portraits, and other secret messages within their works as an “inside joke”. One such example of this is Jackson Pollock’s “Mural”, wherein Pollock hid his entire name in plain sight in the curvatures of the work.
隐写术长期以来与绘画和视觉艺术有关。 画家经常在自己的作品中隐藏签名,自画像和其他秘密信息,以此作为“内部笑话”。 杰克逊·波洛克(Jackson Pollock)的“壁画”就是一个这样的例子,其中波洛克在作品的曲折中清晰地隐藏了他的整个名字。

Until recently, however, computational steganography methods for images (such as appending bits at the end of a .jpg file or applying mathematical functions to select RGB pixel values) have been easy to detect and uncover, and hand-crafted ones are difficult and not scalable.
但是,直到最近,图像的计算隐写方法(例如,在.jpg文件末尾附加位或应用数学函数来选择RGB像素值)一直很容易检测和发现,而手工制作的方法则很困难,而且不是很容易做到。可扩展的。
In 2017, Shumeet Baluja proposed the idea of using deep learning for image steganography in his paper “Hiding Images in Plain Sight: Deep Steganography” [1]. In this paper, a first neural network (the hiding network) takes in two images, a cover and a message. The aim of the hiding network is to create a third image, a container image, that is visually similar to the cover image and is able to be used by a second neural network (the revealing network) to reconstruct the message image via the revealed image (without any knowledge of either the original message or the original cover). The loss is defined by how similar the cover and container images are and how similar the message and revealed images are. The concept was expanded upon a few months later by Zhu et al. to allow for arbitrary data encoding into images [2]. The results were astounding: the network was able to create container images that looked very much like the cover yet allowed the revealing network to reconstruct the message very closely.
2017年,Shumeet Baluja在他的论文“将图像隐藏在普通视域中:深度隐写术 ”中提出了使用深度学习进行图像隐写术的想法[1]。 在本文中,第一个神经网络( 隐藏网络)接收两个图像,一个是封面 ,另一个是消息 。 隐藏网络的目的是创建第三张图像,即容器图像,该图像在视觉上类似于封面图像,并且可以被第二神经网络( 显示网络)用来通过显示的图像重建消息图像。 (不了解原始邮件或原始封面)。 损失由封面和容器图像的相似程度以及消息和显示的图像的相似程度定义。 Zhu等人在几个月后扩展了这一概念。 以允许将任意数据编码为图像[2]。 结果是惊人的:网络能够创建看起来非常像封面的容器图像,但允许显示网络非常紧密地重建消息。

While this result was very interesting, we felt that the utility of steganography specifically for images is limited.
尽管此结果非常有趣,但我们认为隐写术专门用于图像的用途有限。
The question arises: what are the limits for this approach in other domains of information?
随之而来的问题是:在其他信息领域中这种方法的局限性是什么?
More specifically, the aim is to apply this approach to the domain of human language in the form of text and audio, which could be a stepping stone to implementing this procedure for general information.
更具体地说,目的是将这种方法以文本和音频的形式应用于人类语言领域,这可能是为通用信息实施此过程的垫脚石。
用于文字和其他文本信息的深度隐写术 (Deep Steganography for written language and other textual information)
Text is harder to perform steganography with: images are dense while text is sparse; images aren’t affected much by small changes in pixel values while text is greatly affected by small changes in token values. While various methods for conducting text-based steganalysis exist, they face substantial challenges: (1) classical heuristic-based approaches are often easy to decode, because they leverage fixed, easily reversible rules, and (2) current approaches do not exploit any of the structural properties of the text, resulting in hidden messages that are not semantically correct or coherent to humans.
文本很难用以下方法进行隐写术:图像密集而文本稀疏; 图像不受像素值的微小变化的影响很大,而文本受令牌值的微小变化的影响很大。 尽管存在多种进行基于文本的隐写分析的方法,但它们都面临着严峻的挑战:(1)基于经典启发式的方法通常很容易解码,因为它们利用了固定且易于逆转的规则,并且(2)当前的方法不利用任何一种文本的结构属性,导致隐藏的消息在语义上不正确或与人类不一致。
Recent deep learning approaches [3, 4, 5, 6] rely on using generative models to hide the “secret” text in meaningless groupings of words. Here, we want to propose using a transformer-based approach to address both problems at once. We explore using a transformer to combine the desired secret text with some human-readable, coherent cover text in order to generate a new container text that both properly encodes the hidden message inside of it and is nearly identical to the cover text, retaining the cover text’s original semantic structure and legibility. In addition to the transformer used for encoding, we leverage a second transformer model to decode the container text and recover the hidden message.
最近的深度学习方法[3、4、5、6]依靠使用生成模型将“秘密”文本隐藏在无意义的单词组合中。 在这里,我们希望提出使用基于变压器的方法来立即解决这两个问题。 我们探索使用转换器将所需的秘密文本与一些人类可读的,连贯的封面文本结合在一起,以生成一个新的容器文本,该文本既可以正确编码其中的隐藏消息,又与封面文本几乎相同,从而保留了封面文本的原始语义结构和可读性。 除了用于编码的转换器之外,我们还利用第二个转换器模型来解码容器文本并恢复隐藏的消息。
Because transformers are big and bulky, we first tested our luck with a much simpler 1D-convolution character-based approach, CharCNN [7].
因为变压器又大又笨,所以我们首先使用一种更简单的基于1D卷积特征的方法CharCNN [7]测试了运气。
In this character-based approach, the idea is that a model would learn a statistical profile of character choices in a string of text and modify the characters in a way that sends a signal capturing the hidden message through character additions, substitutions, or removals.
在这种基于字符的方法中,想法是模型将学习文本字符串中字符选择的统计信息,并以发送信号的方式通过添加,替换或删除字符捕获隐藏消息来修改字符。
A trivial example in which the message is two bits is considered. To communicate the secret message, our function is the length of the container message modulo 4. More specifically, let l represent the number of characters in the container message. l ≡ 0 (mod 4) yields 00, l ≡ 1 (mod 4) yields 01, l ≡ 2 (mod 4) yields 10, and l ≡ 3 (mod 4) yields 11. The model would accordingly remove or add characters from the cover to communicate the secret message. In practice, we would ideally have our model be more robust, yielding much more complex secret messages through the container texts. This approach has given some recognizable results on both steganographic and reconstructive metrics.
考虑一个简单的例子,其中消息是两位。 为了传达秘密消息,我们的功能是容器消息的模数为4。更具体地说,让l表示容器消息中的字符数。 l 0(mod 4)产生00, l 1(mod 4)产生01, l 2(mod 4)产生10, l 3(mod 4)产生11。模型将相应地从中删除或添加字符传达秘密信息的封面。 实际上,理想情况下,我们希望模型更加健壮,并通过容器文本产生更复杂的秘密消息。 这种方法在隐写和重建指标上都给出了一些可识别的结果。
Cover: I can not believe my eyes, what I saw in the forest was far beyond the reaches of my imagination.
封面 :我简直不敢相信自己的眼睛,在森林里看到的东西远远超出了我的想象。
Secret: meet at river tomorrow at sunset.
秘密 :明天日落时在河边碰面。
Container: I mac now bleiave mye eey, waht I sa inn tee freost ws fara beymdo tee racheas of ym imaingaiton.
容器 :我现在要面对面的挑战,因为我是来自ym imaingaiton的fare beymdo tee racheas的旅馆。
Revealed Secret: eemt a th rivre tomowro tt snseht.
揭露的秘密 :让您流连忘返。
Surprisingly, this information is still somewhat decodable (even though it’s clear that the message has been modified).
令人惊讶的是,此信息仍然有些可解码(即使很明显该消息已被修改)。
An interesting (likely unsolved) information-theoretic question arises in this area: given an information domain (like images, text, etc.), how much secret information can a model hide in given cover information in the average case? We started to see that with larger secret message input sizes and a static cover message size, the model had an increasingly difficult time hiding the information and reconstructing the hidden message. How good it was at each depending on how we weighted the two tasks in the loss function.
在这个领域中出现了一个有趣的(可能尚未解决的)信息理论问题:给定一个信息域(例如图像,文本等),在给定的封面信息中,模型平均可以隐藏多少秘密信息? 我们开始发现,随着秘密消息输入大小的增加和静态掩护消息大小的增加,模型隐藏信息和重构隐藏消息的时间越来越困难。 每个指标的优劣取决于我们对损失函数中两个任务的加权方式。
Next, we decided to investigate a heftier model for performing steganography in text. The primary approach we propose to tackle the challenge of text-based steganography consists of leveraging two NMT (Neural Machine Translation) models: one transformer model to encode the hidden message and a second model to decode it. We hypothesize that this transformer-based approach can potentially succeed at encoding a secret text within a cover text to produce a container text that closely matches the semantic structure of the cover text. An additional nice thing about this is that no custom dataset is needed: any collection of sentences or phrases and random generation of secret messages will do.
接下来,我们决定研究一种用于在文本中执行隐写术的更高级模型。 我们提出的解决基于文本的隐写技术挑战的主要方法包括利用两种NMT(神经机器翻译)模型:一种用于对隐藏消息进行编码的转换器模型,另一种用于对隐藏消息进行解码的模型。 我们假设这种基于转换器的方法可能会成功地对封面文本中的秘密文本进行编码,以生成与封面文本的语义结构紧密匹配的容器文本。 与此相关的另一个好处是,不需要自定义数据集:任何句子或短语集合以及随机生成的秘密消息都可以。
What does “similarity” between cover and container in this case mean? We don’t have a simple metric anymore like edit distance or L2 norm between pixel values. In our new scheme, the sentence “Don’t eat, my friends!” and “Don’t eat my friends!” mean very different things, whereas “Don’t eat, my friends!” and “Please abstain from eating, ye for whom I truly care!” have similar meanings. For ascertaining a metric of similarity, we leverage BERT (Bidirectional Encoder Representations from Transformers [8]), a pre-trained language model that can represent a sentence as a real-valued vector (using the [SEP] token’s vector) where the cosine similarity between two vectors is a good indication of how similar the sentences are in meaning.
在这种情况下,盖子与容器之间的“相似性”是什么意思? 我们再也没有一个简单的指标,例如像素值之间的编辑距离或L2范数。 在我们的新方案中,句子“不要吃,我的朋友们!” 和“别吃我的朋友们!” 意思是完全不同的,而“别吃了,我的朋友们!” 和“我真正关心的人,请不要进食!” 具有相似的含义。 为确定的度量相似性,我们杠杆BERT(B idirectionalËncoder在T ransformersř对产权[8]),一个预训练的语言模型可以表示一个句子作为一个实值向量(使用[SEP]标记的矢量),两个向量之间的余弦相似度很好地表明了句子的含义如何相似。
The results presented in Neural Linguistic Steganography [6], the work most closely related to our own, indicate that state-of-the-art transformer-based language models such as GPT-3 can be leveraged to generate convincing cover texts to hide secret messages. In our implementation, our first NMT transformer model reads in the concatenated secret message (four digits in base 10) and cover text and proceeds to translate them into a container text. Our second transformer reads in the container text and translates it into a reconstruction of the original secret message. Again, the loss function we use consists of a linear combination of the similarity functions between the cover text and the container text (using BERT to produce Loss_Stego), along with the edit distance between the reconstructed secret message and the original secret message. The loss function is (somewhat humorously) formulated as
神经语言隐写术 [6](与我们的研究最相关)中的结果表明,可以利用基于变压器的最新语言模型(例如GPT-3)来生成令人信服的封面文字以隐藏秘密消息。 在我们的实现中,我们的第一个NMT转换器模型读取连接的秘密消息(以10为基数的四位数字)并覆盖文本,然后继续将其转换为容器文本。 我们的第二个转换器读取容器文本并将其转换为原始秘密消息的重构。 同样,我们使用的损失函数由封面文本和容器文本(使用BERT生成Loss_Stego)之间的相似度函数以及重构的秘密消息和原始秘密消息之间的编辑距离的线性组合组成。 损失函数(有点幽默)公式为

where c is the cover instance, c′ is the container instance, s is the secret message, and s′ is the reconstructed message. α and β in our loss function are parameters we can set or have change as a function of the epoch or the loss rate of change. We define the similarity between stegotext (or container text) and cover text with respect to meaning to be the cosine similarity of the embedding of both sequences generated by a pre-trained BERT base model.
其中c是封面实例, c '是容器实例, s是秘密消息, s '是重构消息。 损失函数中的α和β是我们可以根据时期或损失变化率设置或更改的参数。 我们将隐写文本(或容器文本)和封面文本之间的相似性定义为是预训练的BERT基本模型生成的两个序列的嵌入的余弦相似性。
We found that the model that we used, an LSTM seq2seq model with attention for the hiding network and revealing network, was not powerful enough to generate good containers and was faulty in reconstructing the secret message. The loss converged quickly and at a fairly high loss. We additionally hypothesize that a low loss is likely the result of a generative adversarial model for BERT: finding sentences that are meaningless to humans but have small cosine similarity in their embeddings against cover texts as evaluated by BERT. Below is one output example:
我们发现,我们使用的模型(一个关注隐藏网络和显示网络的LSTM seq2seq模型) 功能不强大,无法生成良好的容器,并且在重建秘密消息方面存在错误 。 损失Swift收敛,损失很高。 我们还假设,误码率低可能是BERT生成对抗模型的结果:找到对人类无意义的句子,但与BERT评估的掩盖文字相比,它们的嵌入余弦相似度小。 以下是一个输出示例:
Cover: celebrate the opportunity you have to eat this.
封面 :庆祝有机会吃这个的机会。
Secret: 8 4 4 4.
秘密 :8 4 4 4。
Container: blessing pedals ampoule mbi mbi jharkhand ampoule coring substantive substantive tranquil steadfast murdoch cleverness germane obeng.
容器 :祝福踏板安瓿mbi mbi贾坎德邦安瓿实质性实质性宁静坚定默多克聪明德意志。
Revealed Secret: 8 4 1 4.
揭秘秘密 :8 4 1 4。
Despite this weak example, we also feel that with a sufficiently powerful NMT model and enough compute, we would start to observe useful natural language steganography on textual and general information. This technique could potentially revolutionize communication where there exist adversarial eavesdroppers, especially in the quantum era of fast decryption of common cryptographic protocols. This implementation is left as future work to folks who have an abundance of compute. (Code for the seq2seq model is viewable in this Colab.)
尽管有这个薄弱的例子,我们也感到,有了足够强大的NMT模型和足够的计算能力,我们将开始在文本和一般信息上观察到有用的自然语言隐写术。 在存在对抗性窃听者的情况下,尤其是在快速解密通用密码协议的量子时代,该技术可能会彻底改变通信。 该实现留给有大量计算能力的人们作为未来的工作。 (可以在此Colab中查看seq2seq模型的代码。)
用于语音和其他音频信息的深度隐写术 (Deep Steganography for speech and other audio information)
While performing deep steganography for text may be a ways off, a similar approach for sonic information (sound files) is certainly within reach. The core differentiator for why text is so much more difficult to perform steganography with than images is because text is sparse: in a line of text, each word can be represented by a natural number, and there are typically no more than 100 words in a given sentence. However, images are dense: that is, an image is represented by a very large number of pixels, each having 16777216 possible values (for RGB images).
虽然对文本执行深度隐写术可能是一种方法,但对于声音信息(声音文件)的类似方法肯定可以实现。 为什么文本比图像更难以进行隐写术的主要区别在于,因为文本稀疏:在一行文本中,每个单词都可以用自然数表示,而一个单词中通常不超过100个单词给定句子。 但是,图像很密集 :也就是说,图像由非常多的像素表示,每个像素都有16777216个可能值(对于RGB图像)。
Sound waves are similarly dense, depending on how they’re represented. We’re going to look at two of the ways that sonic information can be represented: spectrograms and waveforms.
声波的密度类似,取决于它们的表示方式。 我们将研究两种表示声音信息的方式: 频谱图和波形 。
A spectrogram is a visual representation of audio. Specifically, the spectrum of frequencies of a signal as it varies with time is represented in the spectrogram by colors and intensities of a time series heatmap. Below is a spectrogram of myself saying, “this is a secret message: my secret message”. For the sake of visuals in this article, we focus on spectrograms.
频谱图是音频的视觉表示。 具体来说,信号随时间变化的频率频谱在频谱图中由时间序列热图的颜色和强度表示。 下面是我自己的频谱图,上面写着:“这是一条秘密信息:我的秘密信息”。 为了本文的视觉效果,我们将重点放在频谱图上。
A waveform is the shape of the graph of a sonic signal as a function of time. Waveforms can be visualized with oscilloscopes to be analyzed for properties such as amplitude, frequency, rise time, time interval, distortion, and others.
波形是声音信号随时间变化的图形形状。 可以使用示波器查看波形,以分析其属性,例如振幅 , 频率 , 上升时间 ,时间间隔, 失真等。

As was proposed by Hiding Images in Plain Sight: Deep Steganography [1], the spectrogram can be operated on as an image using its 2D feature map spectrogram, which can be linearly or logarithmically scaled. The secret message can be an image, text, or other audio data. There are three primary ways of extracting spectrograms from sound: 1) Short-Time Fourier Transform (STFT), with the filters distributed uniformly on the linear frequency axis; 2) Log STFT, same as 1) but with filters that are equally spaced on the logarithmic frequency axis, and 3) Random Matrix Transform (RMT); related to 1) and 2), but with a random matrix R in the place of the discrete Fourier transform matrix.
正如隐藏在普通视域中的图像所提出的:深层隐写术 [1] ,可以使用频谱图的2D特征图频谱图将其作为图像进行操作,该特征图可以进行线性或对数缩放。 秘密消息可以是图像,文本或其他音频数据。 从声音中提取频谱图的主要方法有三种:1)短时傅立叶变换(STFT),滤波器在线性频率轴上均匀分布; 2)对数STFT,与1)相同,但滤波器在对数频率轴上等距分布,以及3)随机矩阵变换(RMT); 与1)和2)有关,但是用随机矩阵R代替离散傅立叶变换矩阵。
Here, we can use a 2D U-Net architecture [9] to learn steganography with the spectrogram.
在这里,我们可以使用2D U-Net架构[9]来学习频谱图的隐写术。

We can also use a convolutional model to learn steganography with the raw audio waveform (STFT), as was proposed in July 2020 by Kreuk et al. in Hide and Speak: Towards Deep Neural Networks for Speech Steganography [10] with impressive results. In either case, the deep learning model training procedure is largely the same: a concealer network and revealer network must be trained in parallel in such a way that the concealer network is able to generate container audio data that is aurally similar to the cover audio it is given (in practice, this perturbed container audio has a tiny bit of “fuzzy” sound), which can then be used by the revealer network to reveal the secret audio it is also given.
正如Kreuk等人在2020年7月提出的,我们还可以使用卷积模型来学习带有原始音频波形(STFT)的隐写术。 “ 捉迷藏和说话:走向语音隐写术的深度神经网络” [10]中的结果令人印象深刻。 在这两种情况下,深度学习模型的训练过程都基本相同:遮盖器网络和显示器网络必须并行进行训练,以使该遮盖器网络能够生成与听觉上相似的容器音频数据。给出(实际上,这种受干扰的容器音频具有一点“模糊”声音),然后可以由揭示者网络使用它来揭示也给出的秘密音频。
End-to-end, a product created using this system can be used as illustrated after training the concealer and revealer networks:
端对端,使用此系统创建的产品可以在训练遮瑕膏和揭露者网络之后如图所示使用:
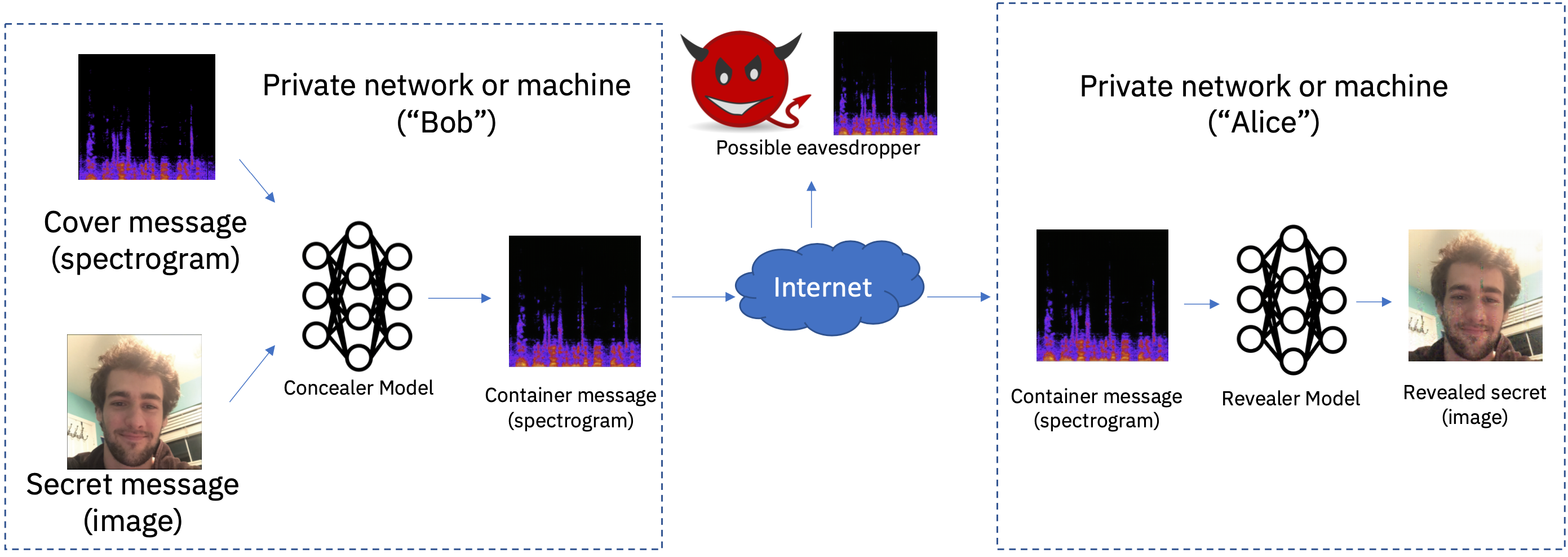
As shown, Bob is trying to hide an image of me inside a spectrogram. The concealer model receives the spectrogram and secret message, yielding a resulting modified spectrogram with small perturbations. This spectrogram is sent across the internet to Alice, who uses the revealer model to convert the container spectrogram into a reconstructed (slightly modified) secret image. A similar process is achieved with a convolutional architecture on the audio STFT waveform.
如图所示,Bob试图将我的图像隐藏在频谱图中。 隐藏器模型接收频谱图和秘密消息,从而产生具有较小扰动的最终修改后的频谱图。 该频谱图通过互联网发送给爱丽丝,爱丽丝使用揭示者模型将容器频谱图转换为重建的(略微修改的)秘密图像。 通过在音频STFT波形上使用卷积架构可以实现类似的过程。

结论…… (To conclude…)
Deep steganography has important implications for secure communication as well as watermarking and service accountability for information machine learning cloud providers. These are only preliminary, unpublished results and have not been incorporated into any sort of product yet, but they provide a hopeful look into the potential that deep steganography offers to keep our information safe in the future.
深度隐写术对于安全通信以及信息机器学习云提供商的水印和服务责任制具有重要意义。 这些只是初步的,尚未发布的结果,尚未被整合到任何产品中,但是它们为深度隐写术为保持我们的信息安全所提供的潜力提供了希望。
Shoutouts to Mario Srouji, Dian Ang Yap, Michele Catasta, Brad Efron, Ashish Kundu, Mustafa Canim, and Christopher Manning for their involvement and contributions!
向马里奥·斯鲁吉(Mario Srouji),滇安(Dian Ang Yap),米歇尔·卡斯塔斯塔(Michele Catasta),布拉德·埃夫隆(Brad Efron),阿什什·昆杜(Ashish Kundu),穆斯塔法·卡宁(Mustafa Canim)和克里斯托弗·曼宁(Christopher Manning)致以呐喊!
I’m on LinkedIn, Medium, and Twitter.
我在LinkedIn , Medium和Twitter上 。
机器生成的摘要 (Machine-Generated Summary)
As promised, here is the machine-generated summary, minimally edited (replacing [UNK] tokens here and there, capitalizing words, removing extra spaces…not cherry-picked other than paragraph selection!). This is another project I’m working on…more to come soon. The original text is 2400+ words.
如所承诺的,这是由机器生成的摘要,经过了最小程度的编辑(在此处和此处替换[UNK]标记,大写单词,删除多余的空格……除了段落选择以外,别无其他选择!)。 这是我正在研究的另一个项目,更多内容即将推出。 原始文本为2400多个字。
摘要(473字): (Summary (473 words):)
People have been using steganography for ages to communicate information in a hidden way. It has long been associated with painting and visual art. Baluja proposed the idea of using deep learning for image steganography in his paper. A first neural network takes in two images to create a third one that can be used by a second neural network to reveal the message via the revealed image. The concept was expanded upon by et a few months later to allow for arbitrary data encoding into images.
人们多年来一直使用隐写术以隐藏的方式传达信息。 长期以来,它与绘画和视觉艺术有关。 Baluja在他的论文中提出了将深度学习用于图像隐写术的想法。 第一个神经网络接收两个图像以创建第三个神经网络,第二个神经网络可以使用第三个神经网络通过显示的图像显示消息。 几个月后,这一概念得到了扩展,以允许将任意数据编码成图像。
For written language the idea is that a model would learn a statistical profile of character choices in a string of text and modify them in a way that sends a signal to the hidden message through character or character. The current approaches rely on using generative models to hide the hidden messages. The new approach uses a second model to combine the desired text with some coherent cover text to create a container text. L represents the number of characters in the container. The model would remove or add characters from the cover to communicate the secret. The approach has given some recognizable results but the information is still hidden.
对于书面语言,想法是,模型将学习文本字符串中字符选择的统计信息,并以通过字符或字符向隐藏消息发送信号的方式修改它们。 当前的方法依赖于使用生成模型来隐藏隐藏的消息。 新方法使用第二种模型将所需文本与一些连贯的封面文本结合起来以创建容器文本。 L表示容器中的字符数。 该模型将从封面上删除或添加角色以传达秘密。 该方法已经给出了一些可识别的结果,但是信息仍然是隐藏的。
The primary approach for performing a in-depth analysis of secret messages consists of two models: one reads in the hidden message and the second one translates it into a container text. The loss function consists of a linear combination of the similarity functions between the cover text and the container text to create a secret message. The model with attention for the hiding network was not powerful enough to generate good containers and was faulty in the secret. The low loss is probably the result of a generative adversarial model for finding sentences that have small similarity in their similarity. A sufficiently powerful and powerful model and enough people will start to observe useful natural language. The implementation is left as future work to people who have a lot of money.
对秘密消息进行深入分析的主要方法包括两个模型:一个模型读取隐藏的消息,第二个模型将其转换为容器文本。 损失函数由封面文本和容器文本之间的相似度函数的线性组合组成,以创建秘密消息。 注意隐藏网络的模型不够强大,无法生成良好的容器,并且秘密存在错误。 低损失可能是生成对抗性模型的结果,该模型用于寻找相似度较小的句子。 一个足够强大的模型和足够多的人将开始观察有用的自然语言。 该实现留给有很多钱的人将来的工作。
Text is more difficult to perform deep steganography for text than for images. Images are represented by a very large number of words. Waves are similarly represented. The deep learning model training procedure is largely the same: a concealer network and the revealer network. It is able to generate container audio data that is similar to the cover audio it is given. It can then be used by the network to reveal the secret audio. A product created using the system can be used as illustrated after training the concealer and when training the secret. A model is trying to hide an image of me inside a spectrogram concealer model. The model is sent across the internet to someone who uses the model to convert the container into a reconstructed spectrogram revealer secret.
与文本相比,对文本执行深度隐写术更困难。 图像由大量单词表示。 波被类似地表示。 深度学习模型训练过程大致相同:遮瑕网和揭密网。 它能够生成与给定的封面音频相似的容器音频数据。 然后网络可以使用它来显示秘密音频。 如图所示,使用该系统创建的产品可以在训练遮瑕膏之后和训练秘密时使用。 模型正在尝试将我的图像隐藏在频谱图遮瑕模型中。 该模型通过Internet发送给使用该模型将容器转换为重构的频谱图显示者秘密的人员。
Deep steganography offers to keep people’s information safe in the cloud.
深度隐写术可以确保人们的信息在云中安全。
[1] Baluja, S. (2017). Hiding images in plain sight: Deep steganography. In Advances in Neural Information Processing Systems (pp. 2069–2079).
[1] Baluja,S.(2017年)。 隐藏清晰可见的图像:隐写术 。 《 神经信息处理系统进展》 (第2069-2079页)。
[2] Zhu, J., Kaplan, R., Johnson, J., & Fei-Fei, L. (2018). Hidden: Hiding data with deep networks. In Proceedings of the European conference on computer vision (ECCV) (pp. 657–672).
[2] Zhu,J.,Kaplan,R.,Johnson,J.,&Fei-Fei,L.(2018)。 隐藏:使用深层网络隐藏数据 。 在欧洲计算机视觉会议(ECCV)会议录中 (第657-672页)。
[3] Yang, Z.L., Guo, X.Q., Chen, Z.M., Huang, Y.F., & Zhang, Y.J. (2018). RNN-stega: Linguistic steganography based on recurrent neural networks IEEE Transactions on Information Forensics and Security, 14(5), 1280–1295.
[3]杨ZL,郭晓琴,陈ZM,黄艳芳,张玉杰(2018)。 RNN-stega:基于递归神经网络的语言隐写术 IEEE Transactions on Information Forensics and Security,14 (5),1280-1295。
[4] Fang, T., Jaggi, M., & Argyraki, K. (2017). Generating steganographic text with LSTMs arXiv preprint arXiv:1705.10742.
[4] Fang,T.,Jaggi,M.和Argyraki,K.(2017)。 使用LSTM arXiv预印本arXiv:1705.10742 生成隐写文字 。
[5] Chang, C.Y., & Clark, S. (2010). Linguistic steganography using automatically generated paraphrases. In Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics (pp. 591–599).
[5] Chang,CY,&Clark,S.(2010)。 语言隐写术使用自动生成的释义 。 在人类语言技术中:计算语言学协会北美分会2010年年会 (第591-599页)。
[6] Ziegler, Z., Deng, Y., & Rush, A. (2019). Neural linguistic steganography arXiv preprint arXiv:1909.01496.
[6] Ziegler,Z.,Deng,Y.,&Rush,A.(2019)。 神经语言隐写术 arXiv预印本arXiv:1909.01496 。
[7] Zhang, X., Zhao, J., & LeCun, Y. (2015). Character-level convolutional networks for text classification. In Advances in neural information processing systems (pp. 649–657).
[7] Zhang,X.,Zhao,J.,&LeCun,Y.(2015)。 用于文本分类的字符级卷积网络 。 神经信息处理系统的进展 (第649–657页)。
[8] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
[8] Devlin,J.,Chang,MW,Lee,K.,&Toutanova,K.(2018)。 伯特:为理解语言而对深度双向转换器进行的预训练 。 arXiv预印本arXiv:1810.04805 。
[9] Ronneberger, O., Fischer, P., & Brox, T. (2015, October). U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention (pp. 234–241). Springer, Cham.
[9] Ronneberger,O.,Fischer,P.和Brox,T.(2015年10月)。 U-net:用于生物医学图像分割的卷积网络 。 在国际医学图像计算和计算机辅助干预会议上 (第234-241页)。 湛史普林格。
[10] Felix Kreuk, Yossi Adi, Bhiksha Raj, Rita Singh, & Joseph Keshet. (2020). Hide and Speak: Towards Deep Neural Networks for Speech Steganography.
[10] Felix Kreuk,Yossi Adi,Bhiksha Raj,Rita Singh和Joseph Keshet。 (2020)。 《捉迷藏和说话:走向用于语音隐写的深层神经网络》 。
翻译自: https://towardsdatascience.com/message-in-a-message-44b89090b3b8
微信开发中消息回复的代码
相关文章
本周AI热点回顾:GPT-3开始探索付费使用;这个视频「橡皮擦」让你瞬间消失;英伟达最强消费级显卡RTX 3090出炉

SpringBoot 实现合并表头导出数据 - EasyExcel应用

MindSpore基础知识【深度学习、基础】
ARM day5 (点灯实验 汇编C)

web安全php基础_php变量命名及其作用域

iphone12售价曝光 iphone12什么时候上市

iphone12上市时间已定
