一、数据类型
五大数据类型
String型:String 是redis中最基本的数据类型,二进制安全的,即它可以包含任何数据,如序列化的对象、jpg图片,大小上限是512M。
Hash型(存储消耗高于字符串): 键值对集合,适合存储对象,类似 Java的Map<String,Object>。
List型: 字符串链表,按插入顺序排序,可重复。
Set: Set 无顺序,不能重复。
SortedSet(zset): 不重复,有顺序。适合做排行榜,排序需要一个分数属性。
三个特殊类型
Geospatial: 经纬度。
Hyperloglog:基数,多用于统计次数。
Bitmap: 位存储,二进制位来进行记录,就只有0 和 1 两个状态!
二、redis常用命令
1.Key的常用命令
set key value #设置一个key值为value
get key #获得key值得value
keys * #查看所有键
exists key #判断某key否存在
move key db #从当前库移除
expire key #$给key设置过期时间(秒)
ttl key #查看还有多少秒过期(-1永不过期,-2已过期)
type key #查看key是什么类型
clear #清楚当前控制台
FLUSHALL #清空所有库的内容
2.String的常用命令
set name junsouth #添加一个key为'name' value为'junsouth'的数据
get name #查询key为'name'的value值
EXISTS name #判断当前key是否存在
EXPIRE name 15 #设置key为'name'的数据过期时间为15秒(seconds)。存在返回1,不存在返回0。
ttl name #查看当前key为'name'的剩余生命周期时间
type name #查看key为'name'的数据类型
GETRANGE name 0 4 #截取字符串,相当于java中的subString,下标从0开始,不会改变原有数据
set num 0 #插入一个初始值为0的数据。
incr num #指定key为'num'的数据自增1,返回结果。
get num #一般用来做文章浏览量、点赞数、收藏数等功能。
decr num #指定key为‘num’的数据自减1,返回结果。
INCRBY num 10 #指定key为‘num’的数据自增'参数(10)'',返回结果。
DECRBY num 3 #指定key为‘num’的数据自减'参数(3)'',返回结果。
setnx name2 dingdada2 #如果key为‘name2’不存在,新增数据,返回值1证明成功;如果key为‘name2’的已存在,失败返回0。
mset k1 v1 k2 v2 k3 v3 #插入多条数据。
mget k1 k2 k3 #查询key为‘k1’,‘k2’,‘k3’的数据。
MSETNX k1 v1 k4 v4 #msetnx是一个原子性的操作,在一定程度上保证了事务。失败返回0,成功返回1。
getset name1 junsouth #先get再set,先获取key,如果没有,set值进去,返回的是get的值3.List的常用命令
lpush myList v1 #给'myList'集合从左添加'v1'元素。
lpush myList v2 v3 v4 v5 #从左批量添加集合元素。
lrange myList 0 -1 #查询'myList'的所有元素值。
rpush myList rv0 #右插入,跟lpush相反。
lpop myList #从头部开始移除第一个元素。
rpop myList #从尾部开始移除第一个元素。
lindex myList 1 #获取指定下标位置集合的元素,下标从0开始计数。
lrem myList 1 v2 #移除集合list中的元素是v2的元素1个
lrem myList 3 v2 #移除集合list中元素为v2 的'3'个,这里的参数数量,如果实际中集合元素数量不达标,不报错,全部移除后返回成功移除后的数量值。
ltrim myList 1 2 #通过下标截取指定的长度,这个list已经被改变了,只剩下我们所指定截取后的元素。
lset myList 1 newV5 #更新list集合中下标为‘1’的元素为‘newV5’4.Set的常用命令
sadd mySet aa bb cc dd #添加set集合(可批量可单个,写法一致)。
smembers mySet #查看set中所有元素
sismember mySet da #判断某个值在不在set中,在返回1;不在返回0。
scard mySet #查看集合的长度,相当于size、length
srem mySet aa #移除set中指定的元素
sadd myset1 1 2 3 4 5
sadd myset2 3 4 5 6 7
sdiff myset1 myset2 #查询指定的set之间的差集,可以是多个set。
sinter myset1 myset2 #查询指定的set之间的交集,可以是多个set。
sunion myset1 myset2 #查询指定的set之间的并集,可以是多个set。5.Hash的常用命令
hset myHash key1 value1 key2 value2 #添加hash,可多个。
hget myhash key1 #获取hash中key是name的值。
hgetall myhash #获取hash中所有的值,包含key。
hdel myhash del key1 #删除指定hash中的key(可多个),key删除后对应的value也会被删除。
hlen myhash #获取指定hash的长度,相当于length、size。
hexists myhash key1 #判断key是否存在于指定的hash,存在返回1,不存在返回0。6.zSet的常用命令
zadd myZset 1 va 2 v2 3 v3 4 v4 5 v5 #添加zset值,可多个。
zrange myZset 0 -1 #查询所有的值。
zrangebyscore myZset -inf +inf #将zset的值根据key来从小到大排序并输出。
zrem myZset v2 #移除指定的元素,可多个7.经纬度的常用命令
geoadd(添加)、geopos(查看)、geodist(计算距离)操作。
geoadd city 118.8921 31.32751 nanjing 117.30794 31.79322 hefei 102.82147 24.88554 lasha #添加城市坐标。
zrange city 0 -1 #geo的查看方式和zset的命令是一致的。
geopos city nanjing #查看看指定城市的经纬度信息。
geodist city nanjing hefei #计算距离,默认返回单位是m。
geodist city nanjing hefei km #计算距离,km千米。
georadiusbymember city hefei 1500 km #查询 hefei 1500公里范围有哪些城市。
zrem city lasa #删除lasa元素。8.基数的常用命令
pfadd dataList1 1 2 3 4 5 6 7 #添加数据集。
pfcount dataList1 #统计数据集中的元素。
pfadd dataList2 4 5 6 7 8 9 10 #添加数据集。
pfcount dataList2 #统计数据集中的元素。
pfmerge newdata dataList1 dataList2 #将 dataList1 和 dataList2 两个数据集合并成一个新的newdata数据集,且自动去重。9.位存储的常用命令
Bitmap 位图,数据结构! 二进制位来进行记录,就只有0 和 1 两个状态!
setbit(添加)、getset(获取)、bitcount(统计)操作
setbit login 1 1 #添加周一已登陆 为1
setbit login 2 1 #添加周二已登陆 为1
setbit login 3 0 #添加周三未登陆 为0
getbit login 1 #获取周一是否登录
getbit login 3 #获取周三是否登陆
bitcount login #统计这周登陆的天数三、Redis事务
Rdeis的悲观锁: 一直监视着,没有执行当前步骤完成前,不让任何线程执行。 Redis的乐观锁: 只有更新数据的时候去判断一下,在此期间是否有人修改过被监视的这个数据,没有的话正常执行事务,反之执行失败!
1.悲观锁
正常执行事务
multi #开启事务
set key01 value01 #添加数据1
set key02 value02 #添加数据2
set key03 value03 #添加数据3
exec #执行事务
get key03 #获取数据成功,证明事务执行成功
放弃事务
multi #开启事务
set key01 value01 #添加数据1
set key02 value02 #添加数据2
set key03 value03 #添加数据3
discard #放弃事务
get key03 #获取数据成功,证明事务执行成功2.乐观锁
set money 100 #添加金钱100
set cost 0 #添加花费0
watch money #监控金钱
multi #开启事务
DECRBY money 30 #金钱-30
incrby cost 30 #花费+30
exec #执行事务,成功!这时候数据没有发生变动才可以成功。四、Redis的属性设置及淘汰策略
1.配置文件redis.conf(Windows为redis.windows.conf)
daemonize no # Redis 默认不是以守护进程的方式运行,可以通过该配置项修改,使用 yes 启用守护进程(Windows 不支持守护线程的配置为 no)
pidfile /var/run/redis.pid #当 Redis 以守护进程方式运行时,Redis 默认会把 pid 写入 /var/run/redis.pid 文件,可以通过 pidfile 指定
port 6379 #指定 Redis 监听端口,默认端口为 6379
bind 127.0.0.1 #绑定的主机地址。
timeout 300 #当客户端闲置多长秒后关闭连接,如果指定为0表示关闭该功能。
loglevel notice #指定日志记录级别,Redis 总共支持四个级别:debug、verbose、notice、warning,默认为 notice。
logfile stdout #日志记录方式,默认为标准输出,如果配置 Redis 为守护进程方式运行,而这里又配置为日志记录方式为标准输出,则日志将会发送给 /dev/null。
databases 16 #设置数据库的数量,默认数据库为0,可以使用SELECT 命令在连接上指定数据库id。
dbfilename dump.rdb #指定本地数据库文件名,默认值为 dump.rdb。
dir ./ #指定本地数据库存放目录
masterauth <master-password> #当 master 服务设置了密码保护时,slave 服务连接 master 的密码。
requirepass foobared #设置 Redis 连接密码,如果配置了连接密码,客户端在连接 Redis 时需要通过 AUTH <password> 命令提供密码,默认关闭。
maxclients 128 #设置同一时间最大客户端连接数,默认无限制(进程可打开的最大文件描述符数)。
maxmemory <bytes> #Redis 最大内存限制。达到最大内存后,会先清除已到期或即将到期的 Key,当此方法处理 后。仍到达最大内存设置,Redis 新的 vm 机制,把 Key 放内存,Value 存放 swap 区(冷数据磁盘)。
appendonly no #指定是否在每次更新操作后进行日志记录,Redis 在默认情况下是异步的把数据写入磁盘。
appendfilename appendonly.aof #指定更新日志文件名,默认为 appendonly.aof2.Redis淘汰策略
noeviction 只返回错误,不会删除任何key。该策略是Redis的默认淘汰策略,一般不会选用。
volatile-ttl 将设置了过期时间的key中即将过期(剩余存活时间最短)的key删除掉。
volatile-random 在设置了过期时间的key中,随机删除某个key。
allkeys-random 从所有key中随机删除某个key。
volatile-lru 基于LRU算法,从设置了过期时间的key中,删除掉最近最少使用的key。
allkeys-lru 基于LRU算法,从所有key中,删除掉最近最少使用的key。该策略是最常使用的策略。
volatile-lfu 基于LFU算法,从设置了过期时间的key中,删除掉最不经常使用(使用次数最少)的key(4.0及以上版本可用)。
allkeys-lfu 基于LFU算法,从所有key中,删除掉最不经常使用(使用次数最少)的key(4.0及以上版本可用)。3.修改属性
# 动态修改 maxmemory
config set maxmemory 10GB
# 查看 maxmemory
config get maxmemory
info memory | grep maxmemory
# 默认策略 是 noeviction,在生产环境建议修改。
# maxmemory-policy noeviction
# 获取当前内存淘汰策略
config get maxmemory-polic
# 在线设置数据淘汰策略 maxmemory-policy
config set maxmemory-policy volatile-lfu五、Redis持久化
RDB(Redis DataBase:内存快照):将某一时刻的内存数据,以二进制的方式写入磁盘。 AOF(Append Only File:增量日志):每执行一条写操作命令,就把该命令以追加的方式写入到一个文件里。 混合持久化方式:Redis4.0新增,Redis5.0默认方式,集成了AOF和RBD的优点,快照+日志。
1.RDB持久化(默认,性能高,数据完整度不高)
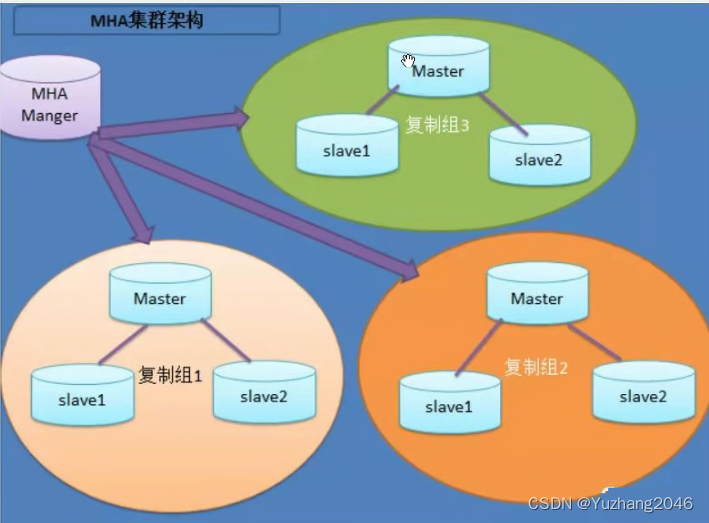
Redis单独fork一个子进程(主进程不参与IO操作)来持久化,将数据写入一个临时文件中,完成后替换旧的RDB文件。
在整个持久化过程中,主进程(为客户端提供服务的进程)不参与IO操作,这样能确保Redis服务的高性能,RDB持久化机制适合对数据完整性要求不高但追求高效恢复的使用场景。
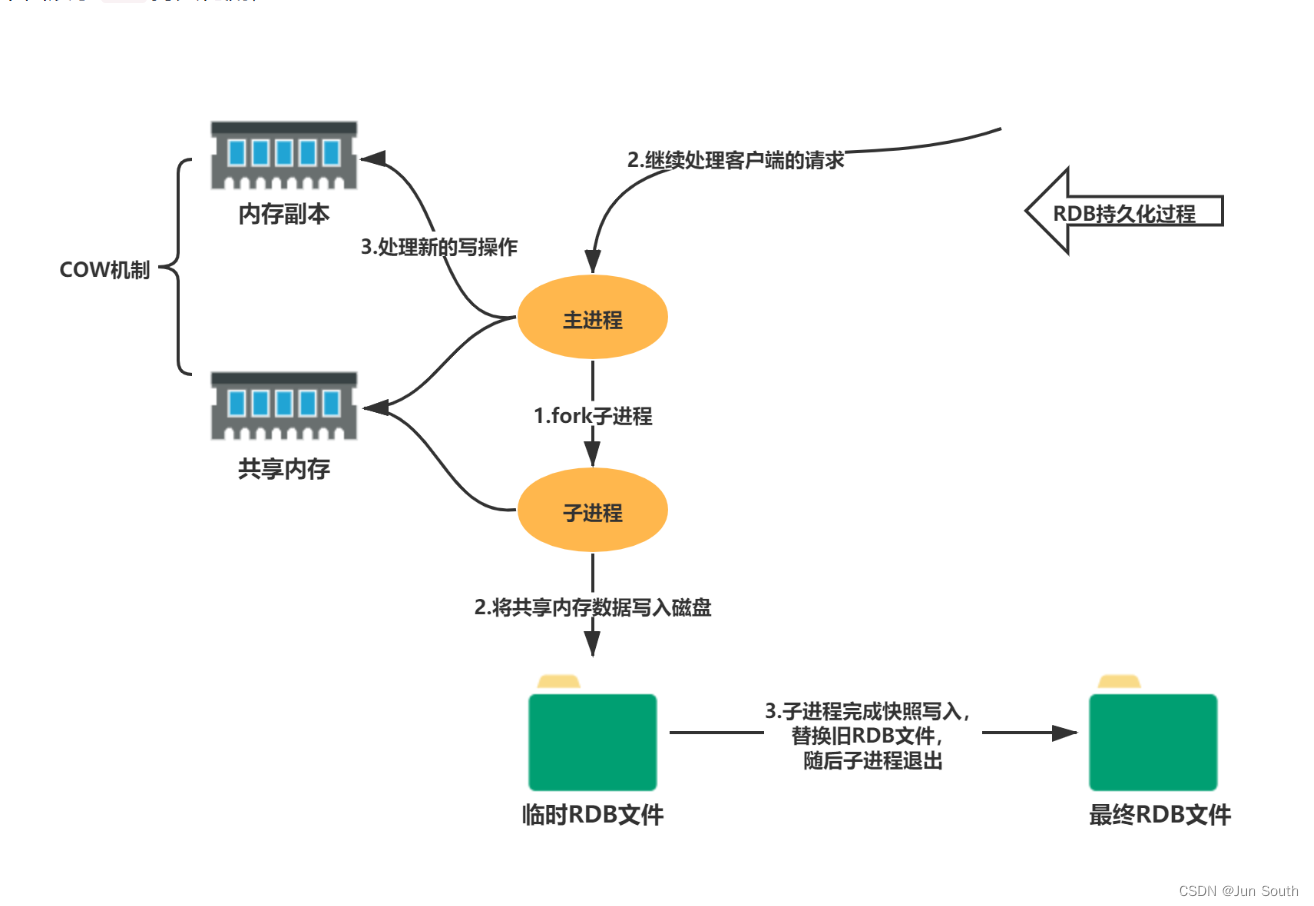
优点:
存储紧凑,节省内存空间;
恢复速度非常快;
适合全量备份、全量复制的场景,经常用于灾难恢复(对数据的完整性和一致性要求相对较低的场合)。
缺点:
容易丢失数据,容易丢失两次快照之间Redis服务器中变化的数据;
RDB通过fork子进程对内存快照进行全量备份,是一个重量级操作,频繁执行成本高;
fork子进程,虽然共享内存,但是如果备份时内存被修改,最大可能膨胀到2倍大小。
redis.config配置
# 关闭 RDB 持久化
# save ""
# 时间策略
save 900 1 #在900秒,1个以上key发生变化,则dump内存快照。
save 300 10 #在300秒,10个以上key发生变化,则dump内存快照。
save 60 10000 #在60秒,10000个以上key发生变化,则dump内存快照。
# 文件名称
dbfilename dump.rdb
# 文件保存路径
dir /home/work/app/redis/data/
# 如果持久化出错,主进程是否停止写入
stop-writes-on-bgsave-error yes
# 是否压缩
rdbcompression yes
# 导入时是否检查
rdbchecksum yes2.AOF持久化
AOF(Append Only File)把所有对内存进行修改的指令(写操作)以独立日志文件的方式进行记录,重启时通过执行AOF文件中的Redis命令来恢复数据。 配置文件中有三种刷新缓冲区的配置:同步频率配置appendfsync always每次Redis写操作,都写入AOF日志。这种配置也是非常耗性能,并发量高时Linux系统扛不住。appendfsync everysec每秒刷新一次缓冲区中的数据到AOF文件,这个Redis配置文件中默认的策略,兼容了性能和数据完整性的折中方案,这种配置,理论上丢失的数据在一秒钟左右。 appendfsync noRedis进程不会主动的去刷新缓冲区中的数据到AOF文件中,交给操作系统去判断,丢失数据的可能性非常大。
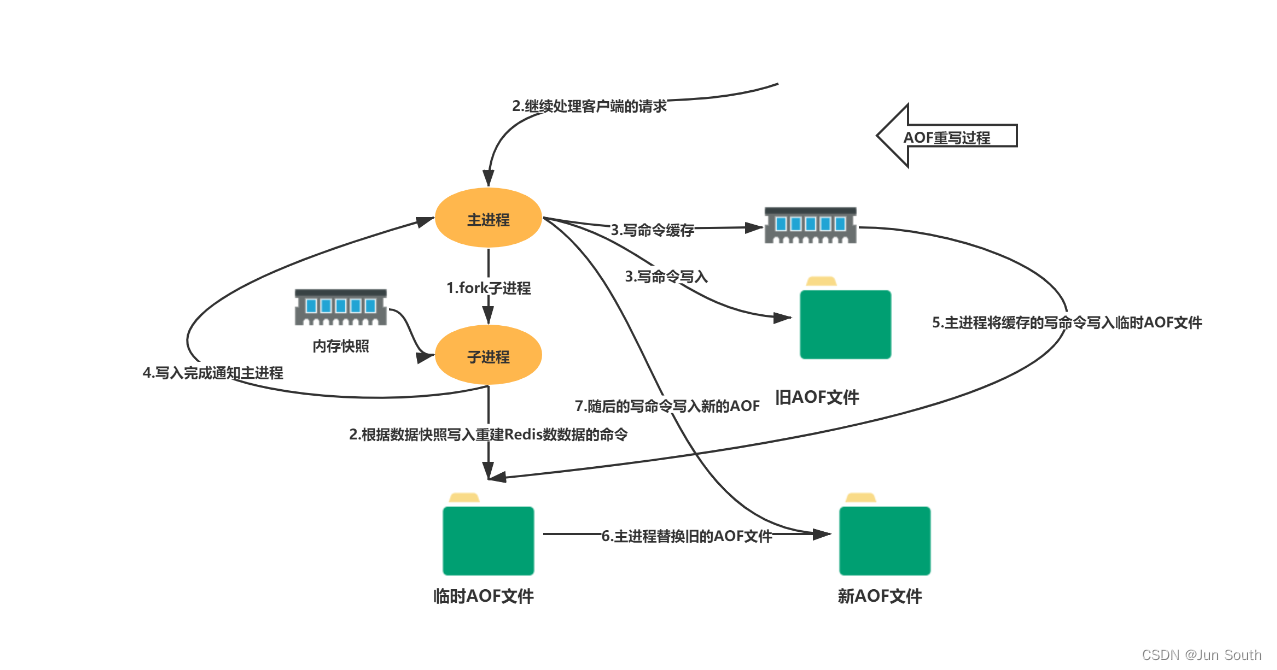
AOF重写:AOF属于日志追加的形式来存储Redis的写指令,这会导致大量冗余的指令存储,如同一个key被写了10000次,最后却被删除了,AOF持久化机制执行重写后,保存的只是恢复数据的最小指令集。 优点:数据的备份更加完整,丢失数据的概率更低,适合对数据完整性要求高的场景;日志文件可读,AOF可操作性更强,可通过操作日志文件进行修复。 缺点:AOF日志记录在长期运行中逐渐庞大,恢复起来非常耗时,需要定期对AOF日志进行瘦身处理(后续详述);恢复备份速度比慢;同步写操作频繁会带来性能压力
redis.config配置
# 是否开启aof
appendonly yes
# 文件名称
appendfilename "appendonly.aof"
# 同步方式
appendfsync always #每次有数据修改发生时都会写入AOF文件。
appendfsync everysec #每秒钟同步一次,该策略为AOF的缺省策略。
appendfsync no #从不同步,高效但是数据不会被持久化。
# aof重写期间是否同步
no-appendfsync-on-rewrite no
# 重写触发配置
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
# 加载aof时如果有错如何处理
aof-load-truncated yes
# 文件重写策略
aof-rewrite-incremental-fsync yes3.混合持久化(Redis4.0出现,Redis5.0默认开启)
首先由RDB定期完成内存快照的备份,然后再由AOF完成两次RDB之间的数据备份。这样就充分了利用了RDB 加载快,备份文件小等特点,也利用了AOF能尽可能不丢数据这个特性(进一步保证了数据一致性) AOF文件的前半部分是RDB格式的全量数据,后半部分是AOF格式的增量数据。
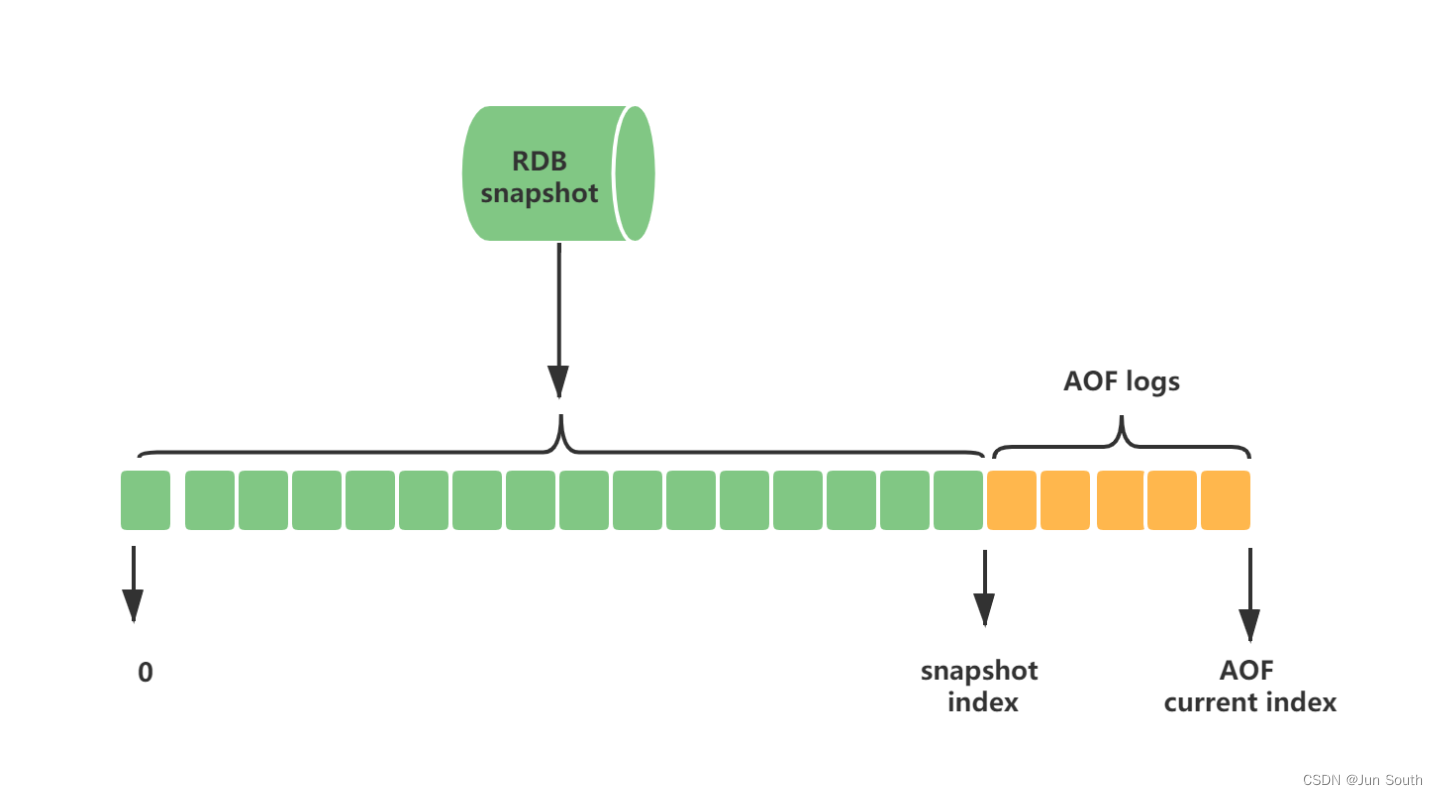
优点:混合持久化结合了RDB和AOF持久化的优点,开头为RDB的格式,使得Redis可以更快的启动,同时结合AOF的优点,有减低了大量数据丢失的风险。 缺点:AOF文件中添加了RDB格式的内容,使得AOF文件的可读性变得很差;兼容性差,如果开启混合持久化,那么此混合持久化AOF文件,不能用在Redis 4.0之前版本。
//查询是否开启混合持久化
config get aof-use-rdb-preamble
//设置混合持久化
config set aof-use-rdb-preamble yes五、Redis的集群
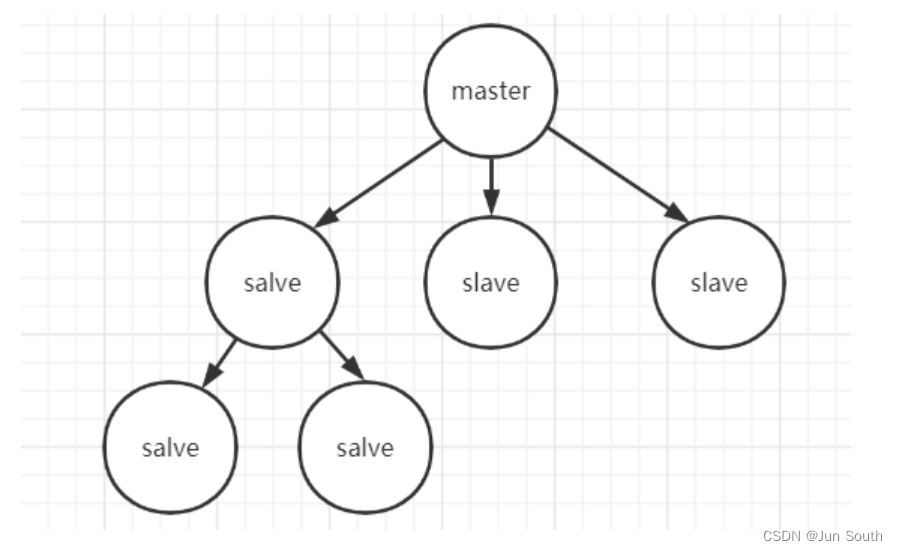
1.主从模式
优点: 主从结构具有读写分离,提高效率、数据备份,提供多个副本等优点。 不足: 最大的不足就是主从模式不具备自动容错和恢复功能,主节点故障,集群则无法进行工作。
主节点(master)redis.config的配置
# 包含文件(redis-base.conf,文件从redis安装目录中拷贝的)
include /data/soft/redis-sentinel/redis-base.conf
# bind 绑定地址修改,外网能访问
bind 0.0.0.0
# 关闭保护模式
protected-mode no
# 端口
port 17007
# 后台运行
daemonize yes
# pid文件
pidfile redis_17007.pid
# 日志文件
logfile "/data/log/redis-sentinel-log/redis-17007-log/redis-17007.log"
# 主认证密码
masterauth 123456
# 认证密码
requirepass 123456
# 最大内存10M,一般为机器内存的3/4
maxmemory 10mb
# 内存达到最大时策略,可选择其他策略
maxmemory-policy volatile-lru
# 目录
dir /data/soft/redis-sentinel/redis-17007/
# 快照文件
dbfilename dump-17007.rdb从节点(slave)redis.config的配置
# 从节点要跟随的主节点
replicaof 192.168.0.3 17007
# 主节点认证密码,如果设置了密码,就要设置
masterauth 1234562.哨兵模式(Redis2.6开始)
哨兵模式的作用: 监控所有服务器是否正常运行:通过发送命令返回监控服务器的运行状态,处理监控主服务器、从服务器外,哨兵之间也相互监控。 故障切换:当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换master。同时那台有问题的旧主也会变为新主的从。(1)每隔10s向master和 slave发送info命令。作用是获取当前数据库信息,比如发现新增从节点时,会建立连接,并加入到监控列表中,当主从数据库的角色发生变化进行信息更新。(2)每隔2s向主数据里和从数据库的_sentinel_:hello频道发送自己的信息。作用是将自己的监控数据和哨兵分享。每个哨兵会订阅数据库的_sentinel:hello频道,当其他哨兵收到消息后,会判断该哨兵是不是新的哨兵,如果是则将其加入哨兵列表,并建立连接。(3)每隔1s向所有主从节点和所有哨兵节点发送ping命令,作用是监控节点是否存活。
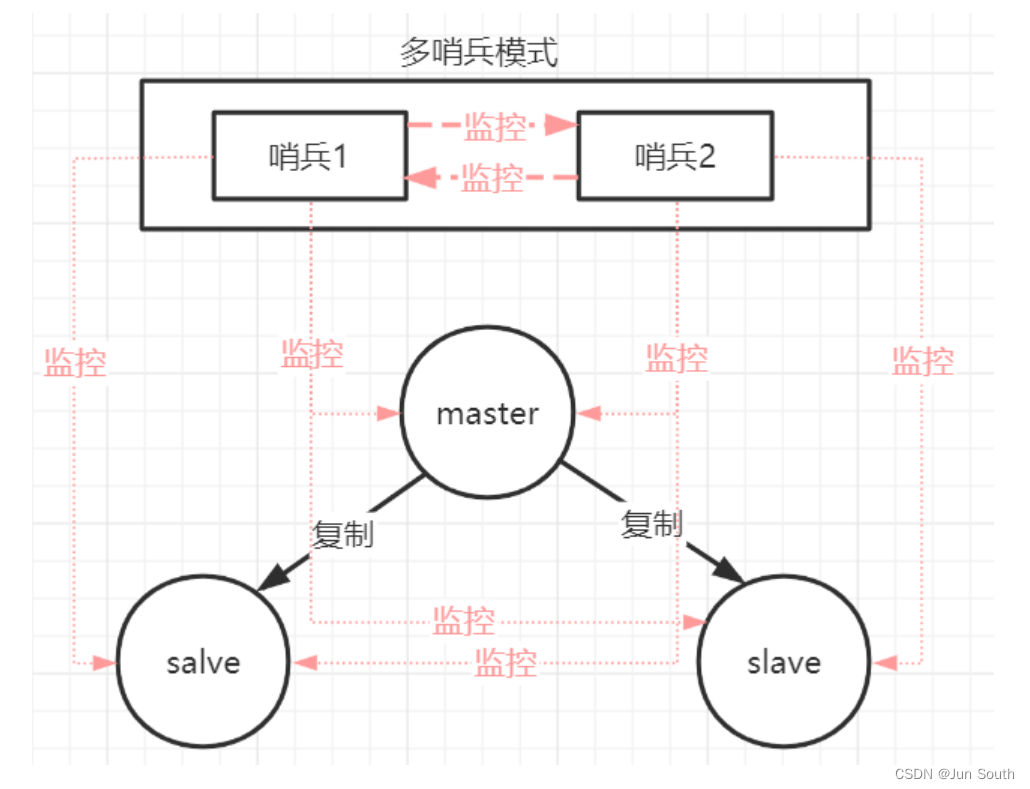
1.优点哨兵模式是基于主从模式的,解决可主从模式中master故障不可以自动切换故障的问题。 2.缺点1.中心化的集群实现方案:始终只有一个Redis主机来接收和处理写请求,写操作受单机瓶颈影响。2.集群里所有节点保存的都是全量数据,浪费内存空间,没有真正实现分布式存储。3.Redis主机宕机后,选举出了新的Redis主机前禁止写操作。 搭建哨兵(在已搭建主从的基础上修改sentinel.conf配置文件)
# 关闭指定 ip 访问
protected-mode no
# 守护进程运行
daemonize yes
# 配置日志文件
logfile /usr/local/redis/sentinel/sentinel.log
# 配置工作目录
dir /usr/local/redis/sentinel
# 配置监听 master ip 为127.0.0.1 端口 6379 2个哨兵发现master 挂了开始切换
sentinel monitor mymaster 127.0.0.1 6379 2
# 配置密码
sentinel auth-pass mymaster xxxx
# 判定 master 无响应的毫秒数
sentinel down-after-milliseconds mymaster 30000
# 并行同步的数量
sentinel parallel-syncs mymaster 1
# 主备切换超时时间
sentinel failover-timeout master-node 1800003.分布式 Redis Cluster(Redis3.0)
Redis Cluster集群采用了P2P的模式,完全去中心化。针对海量数据+高并发+高可用的场景。 1.多主多从,所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。 2.客户端与 Redis 节点直连,不需要中间代理层。客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。 3.每一个分区都是由一个Redis主机和多个从机组成,分片和分片之间是相互平行的。 4.每一个master节点负责维护一部分槽,以及槽所映射的键值数据;集群中每个节点都有全量的槽信息,通过槽每个node都知道具体数据存储到哪个node上。 搭建分布集群
# 守护进行模式启动
daemonize yes
# 设置数据库数量,默认数据库为0
databases 16
# 绑定地址,需要修改
bind 192.168.100.101
# 绑定端口,需要修改
port 6379
# pid文件存储位置,文件名需要修改
pidfile /opt/redis-cluster/redis_6379/pid/redis_6379.pid
# log文件存储位置,文件名需要修改
logfile /opt/redis-cluster/redis_6379/logs/redis_6379.log
# RDB快照备份文件名,文件名需要修改
dbfilename redis_6379.rdb
# 本地数据库存储目录,需要修改
dir /opt/redis-cluster/redis_6379
# 集群相关配置
# 是否以集群模式启动
cluster-enabled yes
# 集群节点回应最长时间,超过该时间被认为下线
cluster-node-timeout 15000
# 生成的集群节点配置文件名,文件名需要修改
cluster-config-file nodes_6379.conf1.用redis-trib.rb插件创建集群:
redis3.0创建命令:
./redis-trib.rb create --replicas 1 192.168.253.131:7001 192.168.253.131:7002 192.168.253.131:7003 192.168.253.131:7004 192.168.253.131:7005 192.168.253.131:7006
redis5.0创建命令:
./redis-cli --cluster create --cluster-replicas 1 192.168.253.131:7001 192.168.253.131:7002 192.168.253.131:7003 192.168.253.131:7004 192.168.253.131:7005 192.168.253.131:7006
2.CLUSTER MEET命令被用来连接不同的开启集群支持的 Redis 节点,以进入工作集群。
node1:6379> cluster meet 192.168.0.102 6379
node1:6379> cluster meet 192.168.0.103 6379
node1:6379> cluster meet 192.168.0.101 6380
node1:6379> cluster meet 192.168.0.102 6380
node1:6379> cluster meet 192.168.0.103 6380