说在前面的一点话~
我本职工作是做爬虫开发的,最近开始爬视频网站了。
大大小小也爬了好多网站,也破解了好多网站,常规的视频网站基本上都爬了,还有一些短视频app也…
看我有心情写几篇博客吧,哈哈哈
有一个专刊,当然专栏里博客数量也不多,就专门放我爬的视频网站吧
一、思路:
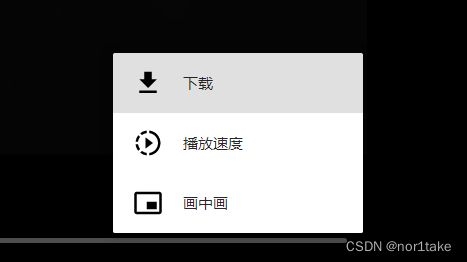
以微博视频VLOG为例,我爬的是热门推荐这部分(url就不贴了)
第一步:先看网页源代码中有有.mp4或其他视频格式结尾的链接(大多数情况是没有的)
第二步:抓包,查看XHR类型的请求返回的数据
第三步:加密破解
二、实战
我用的scrapy框架,就贴个spider文件就行了
item中的download_url就是视频真实地址,下载即可,下载方法可以看我上一篇西瓜视频中的下载方式
spider文件
import scrapy
import time
import json
import re
import requests
from urllib.parse import unquote
import datetime
from ..items import VideoUrlSpiderItemclass WeiboSpider(scrapy.Spider):name = 'weibo'def start_requests(self):"""重写start_requests方法,构造start_urls"""# 接口urlbase_url = 'https://weibo.com/video/aj/load?ajwvr=6&page={}&type=channel&hot_recommend_containerid=video_tag_10&__rnd={}' url = base_url.format(i+1, int(time.time()))# print(url)meta = {'tag': self.name}# 这里的请求应该在下载器中间件中设置headers,这个我后面再贴个代码(因为微博视频api请求头中没有cookie是获取不到数据的)yield scrapy.Request(url, callback=self.parse, meta=meta, dont_filter=True)def parse(self, response):"""解析url,获得相关数据"""list_page_json = json.loads(response.text)html = unquote(list_page_json['data'])video_url = re.findall(r'video&480=(.*?)"', html, re.S)title = re.findall(r'&title=(.*?)&', html, re.S)author = re.findall(r'" class="V_txt2">(.*?)</a>', html, re.S)for i in range(len(video_url)):item = VideoUrlSpiderItem()item['title'] = title[i]item['video_url'] = video_url[i]item['play_nums'] = player_numsitem['author'] = author[i]# print(item)yield scrapy.Request(url, callback=self.parse_download_url, meta={'item': item}, dont_filter=True)def parse_download_url(self, response):"""解析下载url"""item = response.meta['item']return item
middlewares文件
class UserAgentDownloadMiddleware(object):# user-agent 设置随机的请求头中间键USER_AGENTS = ['Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1','Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1','Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; AS; rv:11.0) like Gecko',]def process_request(self, request, spider):# random.choice()在列表中随机选择一个user_agent = random.choice(self.USER_AGENTS)request.headers['user-agent'] = user_agenttag = request.meta.get('tag')if tag == 'weibo':request.headers['cookie'] = 'XXXXXXX这里你从浏览器中复制COOkie就行'