本人也是小白初学者,所以教程很小白,有不对的地方请指正,谢谢。
抓取步骤
1.申请高德地图API
2.新建excel文件
3.获取网页源代码
4.分析代码,找到需要抓取的内容位置特点,抓取内容
5.将抓取到的内容插入到文件中,并保存excel
6.抓取代码中的图片地址和图片,并保存
ps:防止抓取的内容缺失报错,用try跳出内容缺失部分
**1.申请高德地图API
2.新建excel文件**
import xlwt #导入excel模块
workbook_info=xlwt.Workbook() #新建一个excel文件
sheet_info=workbook_info.add_sheet('info') #新建一个sheet并命名
3.获取网页源代码
import requests #导入用来获取网页模块
import json #导入用来获取网页中的json文件
city=["上海","江苏","浙江"]
for w in city:#keyword输入要抓取地址的关键字,city为城市(如果为单个城市的话,直接输入城市名,若要抓取多个城市,则用for循环,本例抓取多个城市)#offset为一页显示多少条记录,page为抓取页数,key是在高德开放平台申请的APIlink = "https://restapi.amap.com/v3/place/text?keywords=五金&city="+w+"&offset=20&page=1&key=(复制自己申请的API)" #设置User-Agent,伪装成浏览器进行访问,否则会403报错headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}#获取网页r = requests.get(link,headers=headers)#获取网页中的json文件decodejson = json.loads(r.text)print(decodejson)
4.分析代码,找到需要抓取的内容位置特点,抓取内容
根据上面代码导出的结果为:

我们需要获取的信息在"pois"下,"pois"为列表中多个字典格式,我们对"pois"下的内容进行索引,并获取内容,这步的思路主要是把每个地址索引到的信息转为列表,这样我们后面编辑到excel中直接索引这些列表就行了。
其中url中的地址为图片地址,稍后另外处理。
for i in decodejson['pois']:p=[] #新建一个空列表#分别用索引的方式获取内容pname=i['pname'] cityname=i['cityname']adname=i['adname']type1=i['type']name=i['name']address=i['address']#将每个索引到的内容插入到p空列表中p.append(pname) p.append(cityname)p.append(adname)p.append(type1)p.append(name)p.append(address) print(p)
上面代码的结果:
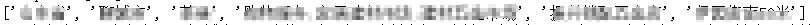
5.将抓取到的内容插入到文件中,并保存excel
在上面代码的基础上,我们对excel内容进行写入
for num in range(0,6):sheet_info.write(m,num,label=p[num]) #在我们新建的sheet中第m行,第num列,插入上面p列表中的第num个索引值m+=1 #每循环一次加一
workbook_info.save(r'D:\info.xls') #保存新建的workbook_info,存在D:\info.xls中,r是为了防止字符转译了
print(y)
这样我们获取的信息就已经生成excel表保存在电脑里了,可以按照保存路径查看哦
6.抓取代码中的图片地址和图片,并保存
接下来是将每个地址的图片下载下来,保存在文件夹里,为了后续能将图片直接对应导入excel中,因此我们以源文件的名字保存图片

思路:图片地址在photos列表中的字典里面,对pois索引photos后,获取url键的值
import urllib.request #导入访问链接模块
import re #导入正则模块
import os
for v in i["photos"]:for key,value in v.items(): #将字典中的键(url,provider,title)和值分别赋给key和value#如果键为我们要的url,则获取url的值if key=="url": url=value#判断该文件夹名是否存在,如果文件夹不存在,则新建文件夹,用来保存图片if os.path.isdir("D://test_pic") != True:os.makedirs("D://test_pic")#新建一个address.txt,用来写入每个urlwith open('address.txt','a') as f: #a是每个循环打开address.txt时,接着往下写入urlf.write(url) #写入urlf.write("\n") #\n换行符#为了后续能将图片直接对应导入excel中,我们用正则表达式获取源文件的名字#(.*)为要获取的内容(表示匹配多个字符),每个url都有showpic/,因此表示为在url中匹配多个字符+showpic/+多个字符url_1=re.search(r'(.*)showpic/(.*)',url) #由于存在部分链接是不为showpic/形式,因此我们要做一个判断,如果没有匹配到showpic/形式的链接,则图片名另外赋值为数字if url_1==None:pic=otherother+=1else:pic=url_1.group(2) #若匹配正常,则获取第二个(.*)作为文件名#将图片保存为D://test_pic/{num}.jpg,num为上面用正则匹配到的字符urllib.request.urlretrieve(url22,"D://test_pic/{num1}.jpg".format(num1=pic)) f.close() #将打开的文件关掉
这样图片就保存下来了
ps:防止抓取的内容缺失报错,用try跳出内容缺失部分
以获取电话为例,有些信息里面可能没有填写电话,这样代码运行到一半会报错,因此我们需要对电话信息进行处理,如果能抓取到电话则正常输出,如果抓取不到电话,则输出none
error=0 #设置一个变量
try:telephone1=i['tel'] #抓取电话信息
except:print('none') #电话信息抓取不到,则输出noneerror=1 #并对变量赋值
if error==1: #当变量变化时,说明电话抓取不到,则继续执行代码,不会报错continue
然后将抓取到的信息按上面的方法,插入到excel中,同样上面的图片也可以防止没有对应的图片地址报错,采用try的方法,对报错预先设置一个结果。
这样高德地图位置信息及图片抓取就都完成了,下面是完整代码:
import requests
import json
import xlwt
import os
import urllib.request
import re
city=["上海","江苏","浙江"]
workbook_info=xlwt.Workbook()
sheet_info=workbook_info.add_sheet('info')
other=0
m=0
for w in city:#keyword输入要抓取地址的关键字,city为城市(如果为单个城市的话,直接输入城市名,若要抓取多个城市,则用for循环,本例抓取多个城市)#offset为一页显示多少条记录,page为抓取页数,key是在高德开放平台申请的APIlink = "https://restapi.amap.com/v3/place/text?keywords=五金&city="+w+"&offset=20&page=1&key=192a0ac9aecac7c1eee7e9f9023e6a9d" #设置User-Agent,伪装成浏览器进行访问,否则会403报错headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}#获取网页r = requests.get(link,headers=headers)#获取网页中的json文件decodejson = json.loads(r.text)for i in decodejson['pois']:#分别用索引的方式获取内容pname=i['pname']cityname=i['cityname']adname=i['adname']type1=i['type']name=i['name']address=i['address']error=0 #设置一个变量try:telephone1=i['tel'] #抓取电话信息except:print('none') #电话信息抓取不到,则输出noneerror=1 #并对变量赋值if error==1: continue #当变量变化时,说明电话抓取不到,则继续执行代码,不会报错for v in i["photos"]:error1=0#将字典中的键(url,provider,title)和值分别赋给key和value#如果键为我们要的url,则获取url的值try:for key,value in v.items():if key=="url": url=valueexcept:print("none1")error1=1if error1==1:continue p=[]#将每个索引到的内容插入到p空列表中p.append(pname)p.append(cityname)p.append(adname)p.append(type1)p.append(name)p.append(address)p.append(telephone1)p.append(url) for num in range(0,8):#在我们新建的sheet中第m行,第num列,插入上面p列表中的第num个索引值sheet_info.write(m,num,label=p[num])m+=1#为了后续能将图片直接对应导入excel中,我们用正则表达式获取源文件的名字#(.*)为要获取的内容(表示匹配多个字符),每个url都有showpic/,因此表示为在url中匹配多个字符+showpic/+多个字符url_1=re.search(r'(.*)showpic/(.*)',url)#由于存在部分链接是不为showpic/形式,因此我们要做一个判断,如果没有匹配到showpic/形式的链接,则图片名另外赋值为数字if url_1==None:pic=otherother+=1else:pic=url_1.group(2) #若匹配正常,则获取第二个(.*)作为文件名#判断该文件夹名是否存在,如果文件夹不存在,则新建文件夹,用来保存图片if os.path.isdir("D://test_pic") != True:os.makedirs("D://test_pic")#新建一个address.txt,用来写入每个url#a是每个循环打开address.txt时,接着往下写入urlwith open('address.txt','a') as f:f.write(url) #写入urlf.write("\n") #\n换行符#将图片保存为D://test_pic/{num}.jpg,num为上面用正则匹配到的字符urllib.request.urlretrieve(url,"D://test_pic/{num1}.jpg".format(num1=pic))f.close() #将打开的文件关掉
workbook_info.save(r'D:\info.xls') #保存新建的workbook_info,存在D:\info.xls中,r是为了防止字符转译了