之前的文章集合:
一些可以参考文章集合1_xuejianxinokok的博客-CSDN博客
一些可以参考文章集合2_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合3_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合4_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合5_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合6_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合7_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合8_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合9_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合10_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合11_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合12_xuejianxinokok的博客-CSDN博客
20230703
Rust交叉编译——Windows To Linux_rust 交叉编译linux_L我是小学生的博客-CSDN博客0x00 开篇什么是交叉编译?可能有的同学不理解。我这里简单介绍下,所谓交叉编译,就是在一个平台上可以编译生成另一个平台的可执行文件。这节课主要介绍如何在Windows系统上编译生成Linux系统的可执行文件。0x01 准备工作我们跨平台编译,要准备如下一些前期工作。操作环境Windows 11VS2012(VS2019我也测试过)CLionRust 1.56.1CentOS 7添加Target这里我所用的Linux是64位的,所以我这里需要添加x86_64-unknown-lin_rust 交叉编译linuxhttps://blog.csdn.net/a1595901624/article/details/121956303
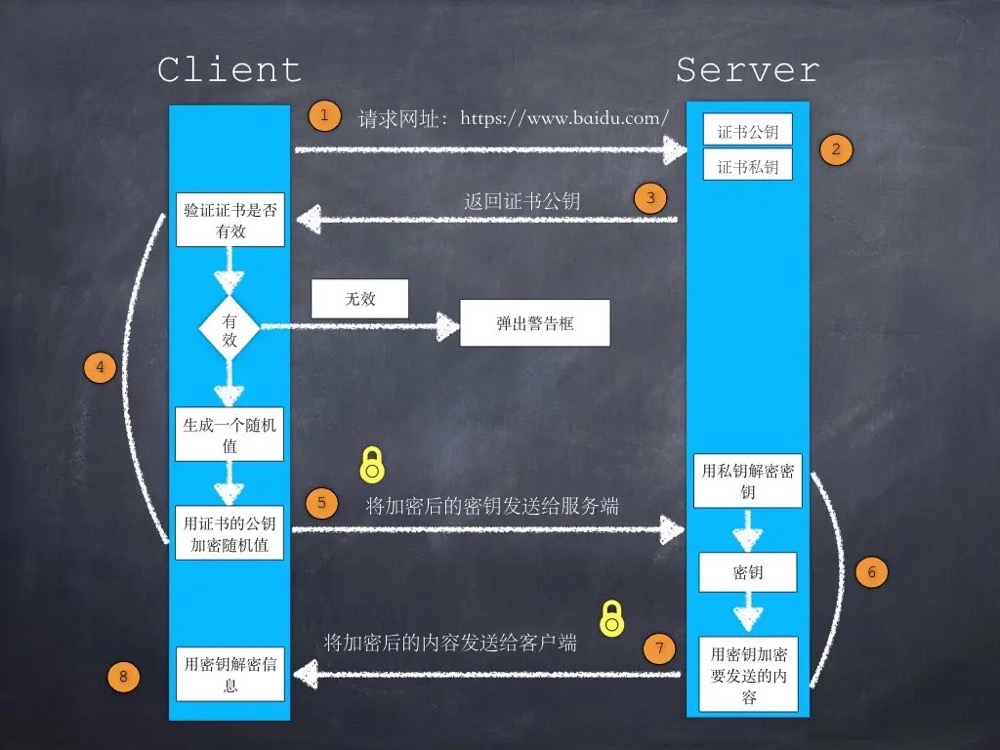
volatile 关键字并不是 Java 语言的特产,古老的 C 语言里也有,它最原始的意义就是禁用 CPU 缓存。
对如下共享变量:
// instance是volatile变量volatile Singlenton instance = new Singlenton();
复制代码
转换成汇编代码,如下:
0x01a3de1d: movb 5 0 x 0, 0 x 1104800(% esi);0x01a3de24: lock addl $ 0 x 0,(% esp);
可以看到 volatile 修饰的共享变量会多出第二行汇编变量,并且多了一个 LOCK 指令。LOCK 前缀的指令在多核处理器会引发两件事:
1)将当前处理器缓存行的数据写回到系统内存。
2)这个写回内存的操作会使在其他 CPU 里缓存了该内存地址的数据无效。
多线程情况下代码的重排序也会影响到程序最终结果。
深入理解并发编程艺术-内存模型篇_Java并发_波_InfoQ写作社区随着硬件技术的飞速发展,多核处理器已经成为计算设备的标配,这使得开发人员需要掌握并发编程的知识和技巧,以充分发挥多核处理器的潜力。然而并发编程并非易事,它涉及到许多复杂的概念和原理。为了更好地理解并发 https://xie.infoq.cn/article/4971eb19f3d5bbe529463f6ed
https://xie.infoq.cn/article/4971eb19f3d5bbe529463f6ed
20230630
Rust WebAssembly的全面分析与演示_笔记大全_设计学院![]() https://www.python100.com/html/76133.html
https://www.python100.com/html/76133.html
关于本书 - Rust语言圣经(Rust Course) https://course.rs/about-book.html
https://course.rs/about-book.html
Rust 语言真的好:连续七年成为全世界最受欢迎的语言、没有 GC 也无需手动内存管理、性能比肩 C++/C 还能直接调用它们的代码、安全性极高 - 总有公司说使用 Rust 后以前的大部分 bug 都将自动消失、全世界最好的包管理工具 Cargo 等等。
所有权
所有权是Rust最独特的特性,它让Rust无需GC(Garbage Collection)就可保证内存安全。Rust的核心特性就是所有权,所有程序在运行时都必须管理它们使用计算机内存的方式。有些语言有垃圾回收机制,在程序运行时会不断地寻找不再使用的内存。在其他语言中,程序员必须显式地分配和释放内存。
Rust采用了第三种方式,内存是通过一个所有权系统来管理的,其中包含一组编译器在编译时检查的规则。当程序运行时,所有权特性不会减慢程序的运行速度。
Rust的所有权,是一个跨时代的理念,是内存管理的第二次革命。
较低级的语言依赖程序员分配和释放内存,一不小心就会出现空指针、野指针破坏内存;较高级的语言使用垃圾回收的机制管理内存,在程序运行时不断地寻找不再使用的内存,虽然安全,却加重了程序的负担;Rust的所有权理念横空出世,通过所有权系统管理内存, 编译器在编译时会根据一系列的规则进行检查,在运行时,所有权系统的任何功能都不会减慢程序,把安全的内存管理推向了0开销的新时代。
所有权存在的原因
所有权解决的问题:跟踪代码的哪些部分正在使用heap 的哪些数据;最小化 heap 上的重复数据量;清理heap上未使用的数据以避免空间不足。一旦懂了所有权,就不需要经常去想stack或heap了,但是知道管理heap数据是所有权存在的原因,这有助于解释它为什么会这样工作。
所有权规则
- 每个值都有一个变量,这个变量是该值的所有者。
- 每个值同时只能有一个所有者。
- 当所有者超出作用域(scope)时,该值将被删除
String类型为了支持可变性,需要在heap上分配内存来保存编译时未知的文本内容:操作系统必须在运行时来请求内存,这步通过调用String::from来实现。当用完 String之后,需要使用某种方式将内存返回给操作系统。这步,在拥有GC的语言中,GC会跟踪并清理不再使用的内存。没有GC,就需要我们去识别内存何时不再使用,并调用代码将它返回。―如果忘了,那就浪费内存;如果提前做了,变量就会非法;如果做了两次,也是 Bug。必须一次分配对应一次释放。
Rust采用了不同的方式:对于某个值来说,当拥有它的变量走出作用范围时,内存会立即自动的交还给操作系统。Rust会在变量超出作用域时调用一个特殊的函数drop释放其内存。
理解Rust的所有权_rust 所有权_swanmy的博客-CSDN博客什么是所有权Rust的所有权,是一个跨时代的理念,是内存管理的第二次革命。较低级的语言依赖程序员分配和释放内存,一不小心就会出现空指针、野指针破坏内存;较高级的语言使用垃圾回收的机制管理内存,在程序运行时不断地寻找不再使用的内存,虽然安全,却加重了程序的负担;Rust的所有权理念横空出世,通过所有权系统管理内存, 编译器在编译时会根据一系列的规则进行检查,在运行时,所有权系统的任何功能都不会减..._rust 所有权https://blog.csdn.net/zhmh326/article/details/103991966
【Rust】所有权_fakerth的博客-CSDN博客Rust所有权https://blog.csdn.net/weixin_43912621/article/details/131430630
最好的service worker 教程
使用 Service Worker - Web API 接口参考 | MDN本文是关于使用 service worker 的教程,包括讲解 service worker 的基本架构、怎么注册 service worker、新的 service worker 的安装以及激活的过程、怎么更新 service worker 还有它的缓存控制和自定义响应,这一切都在一个简单的离线的应用程序中。 https://developer.mozilla.org/zh-CN/docs/Web/API/Service_Worker_API/Using_Service_Workers
https://developer.mozilla.org/zh-CN/docs/Web/API/Service_Worker_API/Using_Service_Workers
- 解决大型项目可维护性问题:TypeScript
- 新的运行环境:Deno
function workerSetup() {self.onmessage = (evt) => {const t = performance.now()// 模拟耗时任务,随机消耗时间 0~100mswhile(performance.now() - t < Math.random() * 100){}const { idx, val } = evt.data// 实际上只是算一下参数的平方self.postMessage({idx: idx,val: val * val})}
}
// 创建一个运行 workerSetup 函数的 worker
const createWorker = () => {const blob = new Blob([`(${workerSetup.toString()})()`])const url = URL.createObjectURL(blob)return new Worker(url)
}
// 模拟 1000 个任务
const tasks = Array(1000).fill(0).map((_, idx) => idx + 1)
const result = []
let rsCount = 0
const onMsg = (evt) => {result[evt.data.idx] = evt.data.valrsCount += 1// 所有任务完成时打印结果if (rsCount === tasks.length) {console.log('task:', tasks)console.log('result:', result)}
}// 模拟线程池
const workerPool = Array(10).fill(0).map(createWorker)
workerPool.forEach((worker, idx) => {worker.onmessage = onMsgworker.id = idx
})for (const idx in tasks) {// 随机分配任务const worker = workerPool[Math.floor(Math.random() * workerPool.length)]worker.postMessage({ idx, val: tasks[idx] })console.log(`Worker ${worker.id}, process task ${idx}`)
}Nodejs对前端的意义不言而喻,其实它最开始主要应用于前端工程化。JS 多线程并发 | 风痕的博客...![]() https://hughfenghen.github.io/fe-basic-course/js-concurrent.html#%E4%B8%BA%E4%BB%80%E4%B9%88%E9%9C%80%E8%A6%81%E5%B9%B6%E5%8F%91
https://hughfenghen.github.io/fe-basic-course/js-concurrent.html#%E4%B8%BA%E4%BB%80%E4%B9%88%E9%9C%80%E8%A6%81%E5%B9%B6%E5%8F%91
20230628
CPU向GPU发送的指令也是像流水线一样的——CPU往命令缓冲区中一个个放入命令,GPU则依次取出执行。在实际的渲染中,GPU的渲染速度往往超过了CPU提交命令的速度,这导致渲染中大部分时间都消耗在了CPU提交Draw Call上。有一种解决这种问题的方法是使用批处理(Batching),即把要渲染的模型合并在一起提交给GPU。
- Memory and DRAM
内存可以分为如下几类
- local memory: 每个线程的内存,通常是原始和中间数据,通过外部的DRAM实现
- shared memory: SM的组件,提供相同SM之内不同线程之间的低延时数据交换
- global memory: 所有SM共享的数据部分,由外部DRAM是实现
DRAM在Tesla架构是一个具有384个pin的data bus,并且被均分成六块,这样可以尽可能地降低延迟。
为什么需要统一的处理器设计?
在直接说明原因之前,文章先简要说明了顶点着色器的发展和介绍了顶点和片元着色器的功能。
然后切入正题,由于顶点管道高精度低延时的要求,这部分最先开始可编程化(我的理解是最开始就只能调用一个API,难以个性化),但随着发展对于片元着色器的可编程需求也逐渐产生,这就有了a need for greater programming generality。 而分离的着色器设计将增加设计的复杂度和GPU的面积和成本,因此有了统一设计的需求。
第二点原因是顶点和片元着色器硬件上的平衡问题,通常来说片元着色器要比顶点着色器多两到三个。但是在实际工作工程中,对于同样面积大小的区域,如果由大三角形组成,顶点着色器往往是空闲的,而片元着色器压力很大;如果由小三角形组成,那么结果相反。而DX10软件层面带来的复杂处理使得两个着色器比例选择更加困难,因此,为什么还要纠结于比例呢?NVIDIA对此进行了统一。

【GPU】目录与前言 - 知乎目录Tesla架构 Tesla架构(一):初识GPU架构 Tesla架构(二):血汗工厂 Tesla架构(三):通用计算及其“物流网”Fermi架构 Fermi架构(一):突破几何瓶颈 Fermi架构(二):一个三角形の异世界之旅 Fermi架构…![]() https://zhuanlan.zhihu.com/p/403345668
https://zhuanlan.zhihu.com/p/403345668
GPU硬件分析---Tesla 架构 - 知乎引言:Tesla架构可以认为是第一代真正开始用于并行运算的GPU架构,其硬件设计与细节奠定了当前并行运算架构的基本形态, 尽管最新的显卡架构Hopper(2022年3月发布,H100)的算力已经远超Tesla,但其运作模式、单元…![]() https://zhuanlan.zhihu.com/p/508862848
https://zhuanlan.zhihu.com/p/508862848
初识Tesla 架构-- NVIDIA Tesla: A Unified Graphics and Computing Architecture - 知乎本人背景: 非科班深度学习方向研究生在读,在做了一定的目标检测工作后,在想未来出路的时候,对CUDA编程有了一定兴趣。目前基于谭升_博客对CUDA进行学习,在学习过程中反复看到硬件架构的重要性,浅尝NVIDIA GPU…![]() https://zhuanlan.zhihu.com/p/514805159
https://zhuanlan.zhihu.com/p/514805159
猴子也能看懂的渲染管线(Render Pipeline) - 知乎CPU与GPU的区别GPU的架构与CPU有极大的不同,这主要归因于两者不同的使用场合。试想一下,GPU面对3D游戏中成千上万的三角面,如果仅仅是逐一单个处理计算,损失的效率是极其惊人的。 这可以类比汽车工业的发展,在…![]() https://zhuanlan.zhihu.com/p/137780634
https://zhuanlan.zhihu.com/p/137780634
计算机图形学七:纹理映射(Texture Mapping)及Mipmap技术 - 知乎纹理映射及Mipmap技术在本篇文章中,我们会具体的讨论如何利用纹理映射让场景拥有丰富的颜色信息,以及纹理贴图精度大小所带来的问题,怎么去解决,最后将会介绍Bump Mapping和Displacement Mapping 1 纹理映射(Te…![]() https://zhuanlan.zhihu.com/p/144332091 人工智能编程 | 谭升的博客C/C++ 《30天自制操作系统》 保护模式 IPL,BIOS 汇编和C GDT IDT 中断处理 中断 鼠标 内存管理 内存管理和叠加处理 定时器 计时器 MAC环境搭建 Mac环境搭建 MAC下的工具 FIFO 高分辨率 多任务I 多任务II 一个半成品 Python爬虫 1.0 Introduction 2.0 分析目标网站 3.0 三只虫 3.1 HTTP协议(一) 3.2 HTTP
https://zhuanlan.zhihu.com/p/144332091 人工智能编程 | 谭升的博客C/C++ 《30天自制操作系统》 保护模式 IPL,BIOS 汇编和C GDT IDT 中断处理 中断 鼠标 内存管理 内存管理和叠加处理 定时器 计时器 MAC环境搭建 Mac环境搭建 MAC下的工具 FIFO 高分辨率 多任务I 多任务II 一个半成品 Python爬虫 1.0 Introduction 2.0 分析目标网站 3.0 三只虫 3.1 HTTP协议(一) 3.2 HTTP![]() https://face2ai.com/program-blog/#GPU%E7%BC%96%E7%A8%8B%EF%BC%88CUDA%EF%BC%89
https://face2ai.com/program-blog/#GPU%E7%BC%96%E7%A8%8B%EF%BC%88CUDA%EF%BC%89





![[基于Python的微信公众号后台开发:1]配置对接阿里云服务器](https://img-blog.csdnimg.cn/img_convert/c7380a032cef414207942b1c0c04e947.png)